本文主要是介绍Docker基础篇(四) 容器数据卷 容器间传递共享(--volumes-from),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
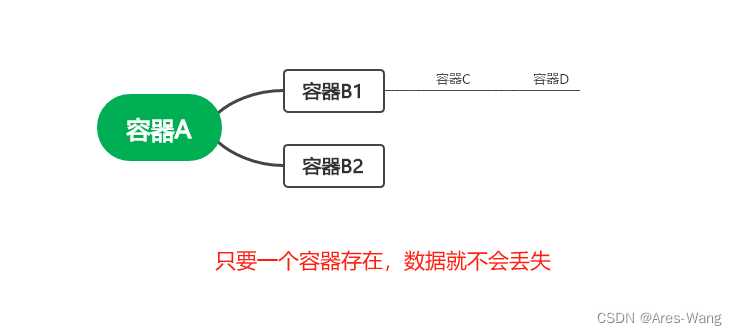
容器间传递共享
当前没有运行的容器

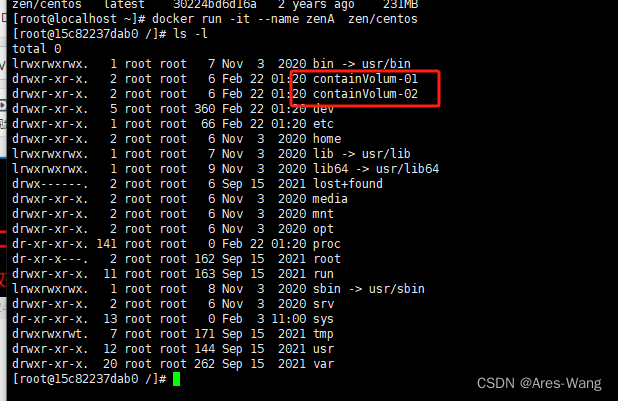
两个数据卷:
containVolum-01
containVolum-02
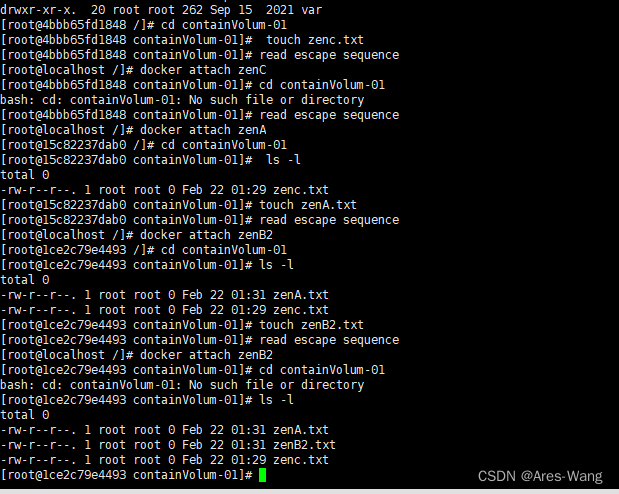
docker run -it --name zenA zen/centos
上面生成了容器 zenA
ctrl + P + Q
docker run -it --name zenB1 --volumes-from zenA zen/centos
ctrl + P + Q
docker run -it --name zenB2 --volumes-from zenA zen/centos
ctrl + P + Q
docker run -it --name zenC --volumes-from zenB1 zen/centos
ctr + P + Q
docker ps
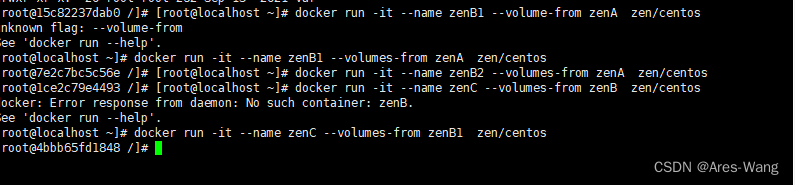

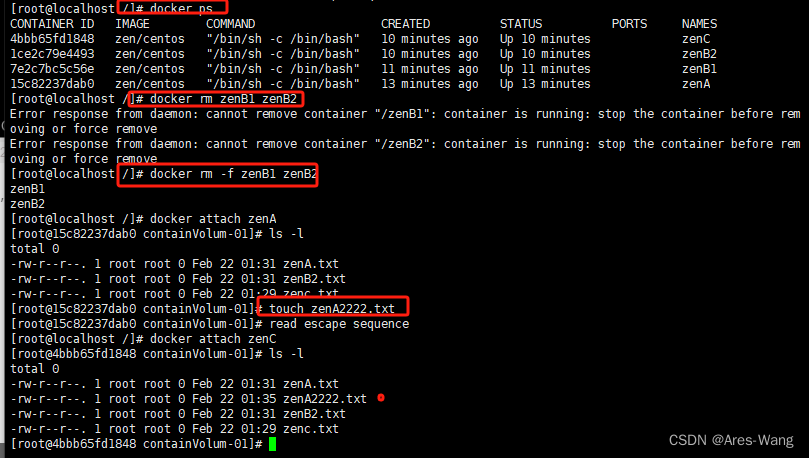
哪怕zenB1,zenB2 容器都删除了zenB1,zenB2 数据卷数据还不会丢失,数据zenC还是传递到zenA
这篇关于Docker基础篇(四) 容器数据卷 容器间传递共享(--volumes-from)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







