本文主要是介绍【糖尿病视网膜病变分级-显著优于最先进的方法】DiffMIC:局部和全局分析 + 扩散模型医学图像分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DiffMIC:基于扩散模型的医学图像分类方法
- DiffMIC的核心思想
- 糖尿病视网膜病变分级
- 网络结构
- 去噪扩散模型:提升特征清晰度
- 双粒度条件引导(DCG):融合局部和全局分析
- 条件特定的最大均值差异(MMD)正则化:增强局部及全局特征学习和一致性
- 训练推理
- 总损失函数
- 训练细节
- 推理阶段
DiffMIC的核心思想
论文链接:https://arxiv.org/pdf/2303.10610.pdf
代码链接:https://github.com/scott-yjyang/DiffMIC
-
问题1:在医学图像分类中,我们需要超精确地识别和区分图像中的病变区域和正常组织。
-
解法:DiffMIC 采用了双粒度条件引导(DCG)。
-
之所以用双粒度条件引导(DCG)解法,是因为医学图像具有高度的局部细节特征,这些特征对于准确的诊断至关重要,同时整体图像的上下文信息也不可忽视。
-
问题2:需要一种方法来提高模型在含噪图像中的分类精确度。
-
解法:DiffMIC 结合了去噪扩散模型。
-
之所以用去噪扩散模型解法,是因为医学图像中常常含有由成像设备或患者状况变化引入的噪声,这会干扰模型的判断。
-
问题3:在高维特征空间中,需要一种方法来保证模型学习到的特征能够反映真实的数据分布。
-
解法:DiffMIC 引入了最大均值差异(MMD)正则化。
-
之所以用最大均值差异(MMD)正则化解法,是因为这可以最小化模型学习到的特征分布与真实数据分布之间的差异,从而提高分类的准确性。
DiffMIC 问题与解法:
- 精细提取局部细节特征、整体图像的上下文信息 - 双粒度条件
- 成像噪声 - 扩散模型
- 特征分布与真实数据分布的一致性 - 最大均值差异正则化。
关键方法:去噪引导的特征提纯。
未明确定义的步骤是如何在去噪的过程中保留对分类决策至关重要的局部细节信息,同时也捕获全局上下文信息,这一点在 DiffMIC 中通过双粒度条件引导策略实现。
它不仅去除了噪声,还强化了模型对于图像中病变与非病变区域的区分能力。
评估:
-
在包括胎盘成熟度分级、皮肤病变分类和 眼底图糖尿病视网膜病变分级 在内的三项 2D 医学图像分类任务上评估了 DiffMIC 的有效性。
-
实验结果表明,这种基于扩散的分类方法在所有三项任务上都显著超过了最先进的方法。
DiffMIC的核心思想是在普通的去噪扩散概率模型(DDPM)之上引入双粒度条件引导,并施加条件特定的最大均值差异(MMD)正则化,以改善分类性能。
-
去噪扩散概率模型(DDPM):DDPM 是一种深度学习模型,主要用于生成或改进图像。它通过逐步添加和去除噪声,来改变图像的特征。简单来说,就是先让图像变得模糊(加噪声),然后再慢慢清晰化(去噪声),在这个过程中学习图像的特征。
-
双粒度条件引导:这是 DiffMIC 特有的技术。它考虑了图像的两个层面:全局和局部。全局引导关注整个图像,而局部引导关注图像中的特定区域(如病变部位)。这种双重关注帮助模型更全面地理解图像。
-
最大均值差异(MMD)正则化:MMD 是一种统计方法,用于衡量两个不同数据分布之间的差异。在 DiffMIC 中,使用 MMD 正则化来确保模型在学习时,不仅仅是复制训练数据,而是能够捕捉到更深层次的、有区分性的特征。
DiffMIC 的核心思想是利用 DDPM 模型来学习图像的特征,同时通过双粒度条件引导和 MMD 正则化提升其对医学图像中重要特征的理解和分类性能。
在处理复杂和多样化的医学图像时尤其有效,因为这些图像中往往包含许多细微的、重要的特征。
糖尿病视网膜病变分级
假设我们有一张眼底图,用于诊断糖尿病视网膜病变的严重程度。
-
应用去噪扩散概率模型(DDPM):
- 添加噪声:DDPM 首先将这张眼底图像通过一系列步骤增加噪声,使其逐渐变得模糊,过程中逐步捕获图像特征。
- 去噪过程:然后,通过逆向步骤逐步去除噪声,恢复图像的清晰度。在这个过程中,模型学习到图像的重要特征,如血管、出血点和黄斑区的细节。
-
双粒度条件引导:
- 全局引导:DiffMIC 考虑整张眼底图像,以理解视网膜的整体情况,包括血管分布和整体视网膜健康状态。
- 局部引导:同时,DiffMIC 专注于图像中的特定区域,如出血点或异常血管,这些是糖尿病视网膜病变的关键指标。
-
最大均值差异(MMD)正则化:
- DiffMIC 通过 MMD 正则化确保模型在学习时不仅仅复制训练数据中的特征,而是能够深入理解糖尿病视网膜病变特征与正常眼底之间的差异。
结果:
- DiffMIC 通过这个综合的方法,能够准确地判断糖尿病视网膜病变的程度,例如,它能区分无病变、轻度、中度和重度糖尿病视网膜病变。
- 双粒度引导使得模型对于整个眼底的全局状况和视网膜特定区域的细节都有深刻的理解,从而提高了诊断的准确性和可靠性。
- MMD 正则化提供了更深层次的特征洞察力,使模型能够更好地区分各个病变等级的微妙差别。
论文实验:
- APTOS2019:包含3662张眼底图像,用于分类糖尿病视网膜病变,共分为五个类别
- HAM10000和APTOS2019按照7:3比例分为训练集和测试集
- 使用准确率和F1分数作为评估指标
- 图像预处理包括中心裁剪、调整为224×224分辨率、随机翻转和旋转
- 使用批大小为32的Adam优化器进行端到端训练
- 从每张图像中提取六个32×32的ROI补丁
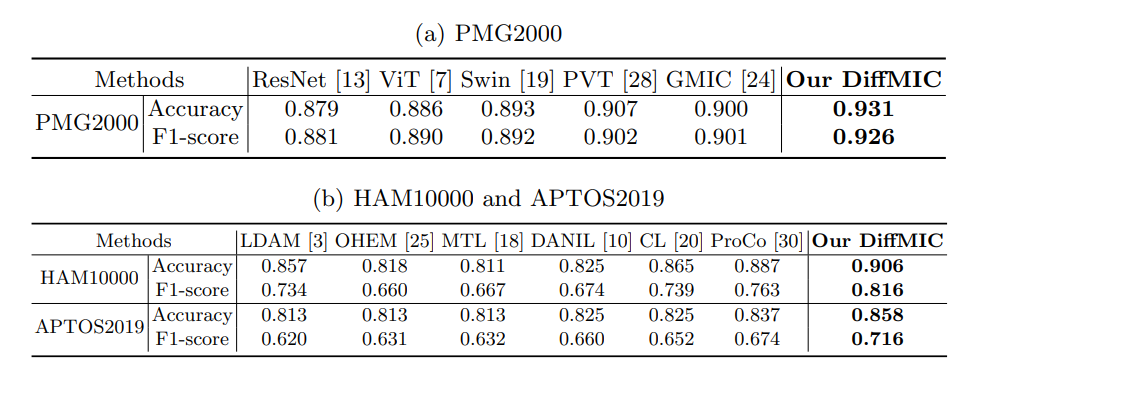
这个表格,说明 DiffMIC 显著优于最先进的方法。
网络结构

这张图 DiffMIC(一种用于医学图像分类的深度学习框架)的总体结构,包括训练阶段和推理阶段,以及双粒度条件引导(DCG)模型的细节。
训练阶段(图的上半部分 a)
-
图像输入:首先,输入的医学图像 ( x ) 通过图像编码器获得特征嵌入 ρ ( x ) \rho(x) ρ(x)。
-
双粒度条件引导(DCG)模型:利用 DCG 模型从图像中提取两种类型的信息:
- 全局信息 y ^ g \hat{y}_g y^g:关注整个图像的特征,如图中的全局编码器 τ g \tau_g τg 所示。
- 局部信息 y ^ l \hat{y}_l y^l:关注图像中特定区域的特征,如通过注意力机制确定的 ROI(感兴趣区域)。
-
扩散过程:在扩散过程中,模型加入噪声来模拟图像特征的变化,产生不同时间步长 t t t 的噪声变量 y t y_t yt。
-
噪声预测和正则化:使用去噪 U-Net ϵ θ \epsilon_\theta ϵθ 和 MMD 正则化来预测并调整每个时间步长的噪声变量,最终生成 y 0 y_0 y0。
推理阶段(图的下半部分 b)
-
扩散反转:在推理阶段,DiffMIC 通过逆向扩散过程从随机噪声 y T y_T yT 逐步重建出图像特征 y 0 y_0 y0,过程中利用了训练阶段学习到的信息。
-
最终预测:经过多个时间步长的逆扩散过程后,模型生成最终的图像分类预测。
双粒度条件引导(DCG)模型(图的右侧部分 c):
-
全局流 τ g \tau_g τg:处理整个图像,通过 1x1 卷积生成显著性图。
-
局部流 τ l \tau_l τl:专注于显著性图中的特定区域,使用注意力机制提取特征。
-
特征融合:将全局和局部特征通过一个全连接层 f c fc fc 融合,以便进行分类。
去噪扩散模型:提升特征清晰度
p θ ( y 0 ⋅ T − 1 ∣ y T , ρ ( x ) ) = ∏ t = 1 T p θ ( y t − 1 ∣ y t , ρ ( x ) ) , a n d p θ ( y T ) = N ( y ^ g + y ^ l 2 , I ) \begin{aligned}p_\theta(y_{0\cdot T-1}|y_T,\rho(x))&=\prod_{t=1}^Tp_\theta(y_{t-1}|y_t,\rho(x)),\quad\mathrm{and}\quad p_\theta(y_T)=\mathcal{N}(\frac{\hat{y}_g+\hat{y}_l}2,\mathbb{I})\end{aligned} pθ(y0⋅T−1∣yT,ρ(x))=t=1∏Tpθ(yt−1∣yt,ρ(x)),andpθ(yT)=N(2y^g+y^l,I)
-
公式的第一部分 p θ ( y 0 ) p_\theta(y_0) pθ(y0) {:}是一个总的表示方式,它说明我们的目标是估计原始图像 y 0 y_0 y0 的概率分布。
y 0 y_0 y0 表示没有噪声的、干净的图像特征。
-
公式的第二部分 p θ ( y 0 ⋅ T − 1 ∣ y T , ρ ( x ) ) p_\theta(y_{0\cdot T-1}|y_T,\rho(x)) pθ(y0⋅T−1∣yT,ρ(x)) 描述了一个连乘过程,这个连乘表示的是每个步骤 (t) 的逆向扩散过程。
简单来说,它表示的是如何从最后一个噪声步骤 y T y_T yT 逐步推断回第一个步骤 y 0 y_0 y0 的过程。
在这个过程中,我们使用了图像的编码特征 ρ ( x ) \rho(x) ρ(x)。
- 每个步骤 (t) 中的 p θ ( y t − 1 ∣ y t , ρ ( x ) ) p_\theta(y_{t-1}|y_t,\rho(x)) pθ(yt−1∣yt,ρ(x)) 代表在给定当前噪声图像 y t y_t yt 和图像特征 ρ ( x ) \rho(x) ρ(x) 的情况下,我们如何预测上一个步骤的图像 y t − 1 y_{t-1} yt−1。
-
公式的第三部分 p θ ( y T ) = N ( y ^ g + y ^ l 2 , I ) p_\theta(y_T)=\mathcal{N}(\frac{\hat{y}_g+\hat{y}_l}2,\mathbb{I}) pθ(yT)=N(2y^g+y^l,I) 描述了扩散过程的起始点,即最噪声的图像 y T y_T yT 的概率分布。
这个分布是高斯分布(正态分布),其均值是全局先验 y ^ g \hat{y}_g y^g 和局部先验 y ^ l \hat{y}_l y^l 的平均值,而协方差是单位矩阵 I \mathbb{I} I`。
- 这意味着在扩散过程的开始,我们假设最噪声的图像是由全局和局部信息混合后加上随机噪声生成的。
扩散模型为什么生成和复原就能有助于模型更清晰地区分不同的类别?
-
逐步提取特征:在扩散模型中,生成和复原的过程允许模型逐步从数据中提取出重要的特征。生成阶段(正向过程)模仿了数据如何被噪声逐渐“破坏”,而复原阶段(反向过程)则试图从噪声中恢复出有意义的结构。这种逐步的过程迫使模型专注于数据的本质特征,而不是噪声或偶然的模式。
-
学习数据的内在结构:在生成阶段,模型学会了数据的内在结构和噪声之间的区别。它必须识别哪些变化是由于噪声引起的,哪些是数据本身的特性。这种区别对于复原过程至关重要。
-
去噪作为训练信号:在复原阶段,模型使用其对噪声的理解来预测并去除噪声,这一过程实际上强化了模型对于数据真实分布的学习。模型必须从噪声中恢复出有用的信号,这是一个高度非线性和复杂的任务,迫使模型学习如何区分不同的类别。
-
反向过程的优化:通过优化反向过程,模型学习如何从随机或噪声数据逐步恢复出清晰的数据特征。这个过程自然地导向了数据的真实类别,因为模型必须理解类别之间的边界以成功地恢复出原始数据。
-
数据的多尺度理解:扩散模型的生成和复原过程允许模型在多个尺度上观察数据,从宏观的全局特征到微观的局部细节。这种多尺度理解增强了模型对数据不同层次结构的认识,有助于区分复杂的类别。
扩散模型通过其生成和复原的动态过程,迫使模型学习如何从数据中分离出信号和噪声,并优化这一过程以发现区分类别所需的关键特征。
这种对数据深入的学习和理解最终使得模型能够更清晰地区分不同的类别。
虽然传统的扩散模型主要用于生成任务,DiffMIC 将这一技术专门化和调整,使其适用于医学图像的分类任务。
-
双粒度条件引导(DCG):DiffMIC通过在每个扩散步骤中引入全局和局部信息来增强扩散模型。全局信息关注整个图像,而局部信息专注于图像中的关键区域(例如病变或特定组织)。这种双粒度策略使模型能够捕捉到对分类至关重要的细微差别。
-
训练过程的定制:在传统的扩散模型中,目标通常是生成新的图像样本。DiffMIC调整了模型的训练过程,使其不仅学习数据的生成过程,而且还学习在去噪的逆过程中如何区分不同的类别,这是分类任务所必需的。
-
最大均值差异(MMD)正则化:DiffMIC利用MMD正则化来保证在嵌入空间中,模型学习到的特征分布与真实数据分布尽可能相似。这有助于模型区分不同类别的图像,并提高分类准确度。
-
端到端训练:DiffMIC执行从原始图像输入到最终分类输出的端到端训练。这样的训练流程使得模型可以直接从图像数据中学习到如何执行分类任务,而不是仅仅学习生成图像的特征。
-
损失函数的设计:DiffMIC通过设计合适的损失函数来指导模型训练。该损失函数不仅包含传统的重建损失(确保去噪的效果),还包括专门针对分类任务的组件,例如交叉熵损失,来直接优化分类性能。
通过这些调整,DiffMIC转化了原本用于生成任务的扩散模型,使其专门用于解决医学图像分类的问题,在保留有意义的诊断信息的同时去除不相关的噪声。
双粒度条件引导(DCG):融合局部和全局分析
y t = α ˉ t y 0 + 1 − α ˉ t ϵ + ( 1 − α ˉ t ) ( y ^ g + y ^ l ) y_t=\sqrt{\bar{\alpha}_t}y_0+\sqrt{1-\bar{\alpha}_t}\epsilon+(1-\sqrt{\bar{\alpha}_t})(\hat{y}_g+\hat{y}_l) yt=αˉty0+1−αˉtϵ+(1−αˉt)(y^g+y^l)
ϵ θ ( ρ ( x ) , y t , y ^ g , y ^ l , t ) = D ( E ( f ( [ y t , y ^ g , y ^ l ] ) , ρ ( x ) , t ) , t ) \epsilon_\theta(\rho(x),y_t,\hat{y}_g,\hat{y}_l,t)=D(E(f([y_t,\hat{y}_g,\hat{y}_l]),\rho(x),t),t) ϵθ(ρ(x),yt,y^g,y^l,t)=D(E(f([yt,y^g,y^l]),ρ(x),t),t)
L ϵ = ∣ ∣ ϵ − ϵ θ ( ρ ( x ) , y t , y ^ g , y ^ l , t ) ∣ ∣ 2 \mathcal{L}_\epsilon=||\epsilon-\epsilon_\theta(\rho(x),y_t,\hat{y}_g,\hat{y}_l,t)||^2 Lϵ=∣∣ϵ−ϵθ(ρ(x),yt,y^g,y^l,t)∣∣2
比如你在一个有雾的早晨开车。
雾(噪声)使得你难以看清路标(图像中的重要特征)。
你需要通过雾看到路标来决定你的行驶方向(图像分类)。
这里有两种工具可以帮助你:
-
(全局先验):它可以帮助你看到远处的路标,给你一个整体的方向感。
-
(局部先验):当你想要看清楚一个特定的、远处的路标细节时,你会使用这个。
在 DiffMIC 模型中,这两种“视镜”就像是它的“双粒度条件引导”:
- 全局引导 类似于远视镜,让模型看到整张图像的大局。
- 局部引导 类似于望远镜,让模型关注图像中特定的重要区域,比如病变或组织的细节。
当我们训练 DiffMIC 模型时(相当于调整视镜以便在雾中更清楚地看到),我们会通过一个过程,其中我们先故意增加图像的“雾”(加噪声),然后再一步步清除这些“雾”(去噪声)。
这个过程使得模型学会如何在复杂和模糊的条件下,识别图像中的重要信息。
去噪模型 就像是你的大脑,它学习如何结合远视镜和望远镜的信息,以帮助你在雾中导航。
在 DiffMIC 中,这部分工作由一个叫做 U-Net 的神经网络完成,它试图预测在去除“雾”(噪声)后图像的真实样子。
-
第一个公式 y t = α ˉ t y 0 + 1 − α ˉ t ϵ + ( 1 − α ˉ t ) ( y ^ g + y ^ l ) y_t = \sqrt{\bar{\alpha}_t}y_0 + \sqrt{1-\bar{\alpha}_t}\epsilon + (1-\sqrt{\bar{\alpha}_t})(\hat{y}_g+\hat{y}_l) yt=αˉty0+1−αˉtϵ+(1−αˉt)(y^g+y^l) 描述了如何混合噪声到图像中。
-
第二个公式 ϵ θ ( ρ ( x ) , y t , y ^ g , y ^ l , t ) \epsilon_\theta(\rho(x),y_t,\hat{y}_g,\hat{y}_l,t) ϵθ(ρ(x),yt,y^g,y^l,t) 描述了 U-Net 如何估计和去除这个噪声。
-
第三个公式 L ϵ \mathcal{L}_\epsilon Lϵ 是一个衡量标准,用来判断去噪后的图像与原始图像的相似度。这帮助模型学习减少预测噪声和实际噪声之间的差异。
最终,DiffMIC 模型的目标是在任何条件下(即使在噪声很多或图像很模糊的情况下)都能准确地分类医学图像,就像你在雾中驾车时能够准确地找到正确方向一样。
条件特定的最大均值差异(MMD)正则化:增强局部及全局特征学习和一致性
L M M D g ( n ∣ ∣ m ) = K ( n , n ′ ) − 2 K ( m , n ) + K ( m , m ′ ) , with n = ϵ , m = ϵ θ ( ρ ( x ) , α ˉ t y 0 + 1 − α ˉ t ϵ + ( 1 − α ˉ t ) y ^ g , y ^ g , t ) \begin{aligned}\mathcal{L}_{MMD}^g(n||m)&=\mathbb{K}(n,n^{'})-2\mathbb{K}(m,n)+\mathbb{K}(m,m^{'}),\\\text{with }&n=\epsilon,m=\epsilon_\theta(\rho(x),\sqrt{\bar{\alpha}_t}y_0+\sqrt{1-\bar{\alpha}_t}\epsilon+(1-\sqrt{\bar{\alpha}_t})\hat{y}_g,\hat{y}_g,t)\end{aligned} LMMDg(n∣∣m)with =K(n,n′)−2K(m,n)+K(m,m′),n=ϵ,m=ϵθ(ρ(x),αˉty0+1−αˉtϵ+(1−αˉt)y^g,y^g,t)
在 DiffMIC 模型中,这个过程是模型在学习如何将图像数据的分布调整得,更接近理想的分布(如医学图像中健康与病变组织的正确分类)。
通过最小化 MMD 正则化损失,模型能更好地学习区分不同类别的图像。
你正在做食物配对,比如决定哪种葡萄酒最适合搭配某种奶酪。
你的目标是找到两种食物间的最佳匹配,使得它们的味道能够很好地融合。
- MMD的作用:
- 最大均值差异(MMD)就像是一种“口味检测器”,它可以帮助你判断两种食物味道的相似性。
- 如果MMD值低,说明两种味道很接近;如果MMD值高,说明它们味道相差很远。
- MMD正则化的引入:
- 在 DiffMIC 模型中,我们不仅想要模型能够识别图像中的对象,还希望它能理解这些对象之间的关系。
- 就像你不仅要知道葡萄酒和奶酪是什么,还要理解它们的搭配是否合理。
- MMD正则化的计算:
- 在模型学习的过程中,我们使用 MMD 正则化来评估模型生成的噪声(想象成不同的口味尝试)与我们希望的目标分布(理想的口味组合)之间的匹配度。
- MMD正则化帮助模型更好地学习如何从噪声中提取有用的信息,就像帮助你更好地理解不同的食物搭配。
- MMD的条件特定作用:
- 在模型中,我们对全局先验(整体风味)和局部先验(特定口味点)都应用了MMD正则化
- 确保模型不仅能分辨出图像中的对象,还能理解它们之间的复杂关系。
训练推理
总损失函数
总损失 L d i f f \mathcal{L}_{diff} Ldiff 是,由噪声估计损失 L ϵ \mathcal{L}_\epsilon Lϵ 和 MMD 正则化损失 L M M D g + L M M D l \mathcal{L}_{MMD}^g + \mathcal{L}_{MMD}^l LMMDg+LMMDl 组成:
- L d i f f = L ϵ + λ ( L M M D g + L M M D l ) \mathcal{L}_{diff} = \mathcal{L}_{\epsilon} + \lambda(\mathcal{L}_{MMD}^g + \mathcal{L}_{MMD}^l) Ldiff=Lϵ+λ(LMMDg+LMMDl)
其中 λ \lambda λ 是平衡超参数,经验性地设为 0.5。
训练细节
采用标准的 DDPM 训练过程
- 比如学习如何制作复杂的咖啡。
- DDPM就像是一个训练计划,告诉你应该如何逐步学习咖啡的不同制作阶段。
时间步长 ( t ) (t) (t) 从 ( [ 1 , T ] ) ([1, T]) ([1,T]) 的均匀分布中选取
- 这就像是你在制作咖啡时的不同步骤。
- 你可能会从磨豆开始(步骤 1),一直到最后倒入杯中(步骤 T)
噪声以 β 1 = 1 × 1 0 − 4 \beta_1 = 1 \times 10^{-4} β1=1×10−4 和 β T = 0.02 \beta_T = 0.02 βT=0.02 线性安排。
- 想象你在咖啡中加入糖。
- 开始时只加一点点糖 ( β 1 ) (\beta_1) (β1),但随着时间的推移,你逐渐增加糖的量,直到达到你想要的甜度 ( β T ) (\beta_T) (βT)。
作为图像编码器 ρ ( ⋅ ) \rho(\cdot) ρ(⋅),采用了 ResNet18。
- ResNet18 是一个高级的食材处理机,帮助你快速准确地准备咖啡的原材料。
将 y t , y ^ g , y ^ l y_t, \hat{y}_g, \hat{y}_l yt,y^g,y^l 连接起来
- 将咖啡、糖和奶油混合在一起,以便制作一杯拿铁。
并通过一个输出维度为 6144 的线性层获得潜在空间中的融合向量。
- 这个线性层就像是一个高效的搅拌器,它确保所有成分都充分混合,并且保持一致的质量和风味。
为了在时间步上条件响应嵌入,执行融合向量和时间步嵌入之间的哈达玛积。
- 根据制作咖啡的不同阶段(如煮沸、倒入等)调整搅拌器的速度和方式。
然后,通过执行图像特征嵌入和响应嵌入之间的另一个哈达玛积来集成它们。
- 在制作咖啡的过程中,根据咖啡豆的种类和磨豆的细致程度来调整水温和冲泡时间。
输出向量通过两个连续的全连接层,每个后面都跟着一个时间步嵌入的哈达玛积。
- 在咖啡制作的最后阶段,检查和调整咖啡的味道,确保它达到了理想的口感和风味。
最后,使用一个全连接层来预测具有类别输出维度的噪声。
- 品尝咖啡并判断它属于哪种类型(如浓缩咖啡、美式咖啡等)。
所有全连接层都伴随着一个批量归一化层和一个 Softplus 非线性函数,输出层除外。
对于 DCG 模型 τ D \tau_D τD,其全局和局部流的骨干是 ResNet。
- DCG 模型是专门学习制作特定类型咖啡(如卡布奇诺或拿铁)的专门课程。
采用标准的交叉熵损失作为 DCG 模型的目标。
在 DCG 模型预训练 10 个时期后,联合训练去噪扩散模型和 DCG 模型,从而实现端到端的医学图像分类 DiffMIC。
- 将去噪扩散模型和 DCG 模型联合训练就像是一个咖啡师同时学习如何制作多种不同类型的咖啡,并确保每种咖啡都达到最高质量。
- 在这个过程中,咖啡师不仅要学会如何分别制作每种咖啡,还要了解它们之间的相互影响,并调整烹饪技巧以优化最终结果。
推理阶段
给定输入图像 (x),首先将其输入到 DCG 模型中以获得双重先验 y ^ g , y ^ l \hat{y}_g, \hat{y}_l y^g,y^l。
- 首先准备好所有必要的食材(双重先验 y ^ g , y ^ l \hat{y}_g, \hat{y}_l y^g,y^l)
然后,遵循 DDPM 的流程,最终预测 y ^ 0 \hat{y}_0 y^0 是从随机预测 y T y_T yT 使用经过双重先验 y ^ g , y ^ l \hat{y}_g, \hat{y}_l y^g,y^l 和图像特征嵌入 ρ ( x ) \rho(x) ρ(x) 条件化的训练过的 UNet 迭代去噪得到的。
- 然后按照学到的步骤(DDPM流程)烹饪咖啡,最后将半成品(随机预测 (y_T))转化为一杯完美的咖啡(清晰的图像 (\hat{y}_0))。
这篇关于【糖尿病视网膜病变分级-显著优于最先进的方法】DiffMIC:局部和全局分析 + 扩散模型医学图像分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






