本文主要是介绍Linux多个文件按列合并的多种场景操作方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
paste、awk、join
- paste
- 1.1. 列数相同
- 1.2. 列数不同
- 1.3. 合并列很多的情况
- awk
- join
- 3.1. 合并首列相同字段
- 3.2. 特殊字符分隔的一行同列
paste
可用范围:不考虑列值,可直接合并
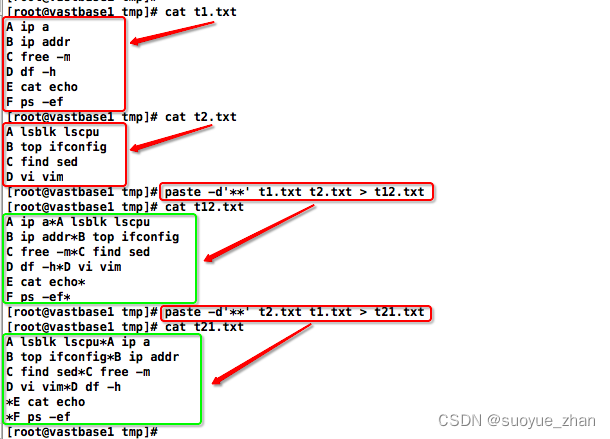
1.1. 列数相同
默认以tab分隔合并,-d参数可指定字符(空格也是字符)分隔合并

1.2. 列数不同
列数不同也会输出,若用-d参数带字符分隔也会带上分隔字符后输出
vi t1.txt
A ip a
B ip addr
C free -m
D df -h
E cat echo
F ps -efvi t2.txt
A lsblk lscpu
B top ifconfig
C find sed
G D vi vim
1.3. 合并列很多的情况
当合并的文件列数过多时,在合并处会出现“乱码”,此时需要手动处理一下

== ⚠:使用ctrl+v,ctrl+m打^M字符,否则无法识别 ==
# 修改合并后的文件,去掉^M字符
vi mergedcs.csv
:1,$ s/^M//g
awk
可用范围:文件存在重复字段,去重合并,需要指定列数【相当于合并后删除重复首列】
https://blog.csdn.net/qq_31573519/article/details/83002137
join
可用范围:文件存在重复字段,去重合并【相当于合并后删除重复首列】
== ⚠:join一次只能合并两个文件 ==
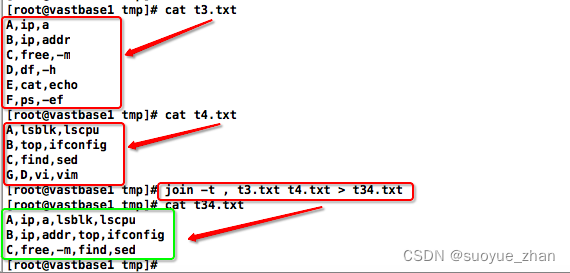
3.1. 合并首列相同字段
只合并存在相同字段的行,且相同字段为当前行的首字符(如下例中“D”行是匹配不到的)

3.2. 特殊字符分隔的一行同列
可用 -t 参数指定分隔的列字符进行合并
这篇关于Linux多个文件按列合并的多种场景操作方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








