按列专题

NumPy(五):数组统计【平均值:mean()、最大值:max()、最小值:min()、标准差:std()、方差:var()、中位数:median()】【axis=0:按列运算;axis=0:按列】
统计运算 np.max()np.min()np.median()np.mean()np.std()np.var()np.argmax(axis=) — 最大元素对应的下标np.argmin(axis=) — 最小元素对应的下标 NumPy提供了一个N维数组类型ndarray,它描述了 相同类型 的“items”的集合。(NumPy provides an N-dimensional array

NumPy(六):数组堆叠:【vstack:垂直(按列顺序)堆叠数组】【hstack:水平(按列顺序)堆叠数组】【stack:axis=0/1/2】
首先生成一些数, import numpy as npa = np.arange(1, 7).reshape((2, 3))b = np.arange(7, 13).reshape((2, 3))c = np.arange(13, 19).reshape((2, 3))print('a = \n', a)print('b = \n', b)print('c = \n', c) 即下
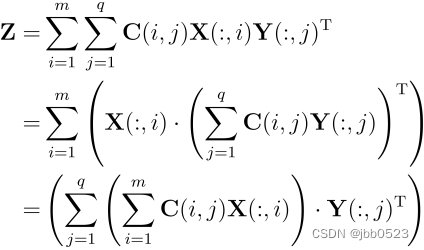
矩阵按列相乘运算的并行化实现方法
这两天一直在琢磨如下矩阵计算问题。 已知d×m矩阵X和h×q矩阵Y,求如下矩阵: 其中X(:,i), Y(:,j)分别表示矩阵X, Y的第i列和第j列,易知Z为d×h矩阵。 如果直接串行计算矩阵Z,两个循环共有m×q,则会很慢,能不能并行化呢? 实际上是可以的,为便于理解,我们先把Z写成如下形式: 对于矩阵Z中的第(

如何将两个列表按列或合并在一起,并保存为csv文件
每天进步亿点点之20210306 在深度学习处理列表列表合并时,一个是数据列表,一个是标签列表;在行或列上具有相同维度。 要想同一个样本的数据和标签显示在同一行或列,可以利用for循环函数对每一行或每一列数据后加上一个标签数据。具体操作如下: 1.先看看我的数据类型及标签类型: 数据类型: 这是我对图像提取的全连接层特征:共有662个数据,一个数据维度为1000 标签类型: 标签共分为两

continue 语句,iteritems()itertuples()对dataframe进行遍历,df按列批量统计
1.continue 语句是一个删除的效果,他的存在是为了删除满足循环条件下的某些不需要的成分: for letter in 'Python': # 第一个实例if letter == 'h':continueprint '当前字母 :', letter 当前字母 : P当前字母 : y当前字母 : t当前字母 : o当前字母 : n 2.对dataframe进行遍历 i

Spark SQL用UDF实现按列特征重分区 repatition
转:https://cloud.tencent.com/developer/article/1371921 解决问题之前,要先了解一下Spark 原理,要想进行相同数据归类到相同分区,肯定要有产生shuffle步骤。 比如,F到G这个shuffle过程,那么如何决定数据到哪个分区去的呢?这就有一个分区器的概念,默认是hash分区器。 假如,我们能在分区这个地方着手的话肯定能实现我们的目标
基于Python实现矩阵数据的按列求和计算
下午在功能开发的时候遇上一个小功能点的实现过程中需要对矩阵数据按列求和计算,输出一维的列表数据,有点像是神经网络模型里面的Flatten一样,这里实现是很简单的,在实现的时候我突然涌现出来了一个有趣的想法,除了我自己的实现方式以外还有哪些实现方式呢?那种方式最简洁呢? 抱着这样的想法,我构想了一下然后一共想到了4种实现方式,这里一并给出来,如下: #!usr/bin/env python
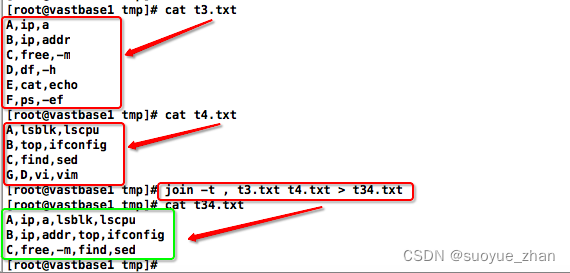
Linux多个文件按列合并的多种场景操作方式
paste、awk、join paste1.1. 列数相同1.2. 列数不同1.3. 合并列很多的情况 awkjoin3.1. 合并首列相同字段3.2. 特殊字符分隔的一行同列 paste 可用范围:不考虑列值,可直接合并 1.1. 列数相同 默认以tab分隔合并,-d参数可指定字符(空格也是字符)分隔合并 1.2. 列数不同 列数不同也会输出,若用-d参数带字符

将Excel工作表按列拆分成多个Excel文件小工具
功能描述 可以将一个EXCEL表按照指定的字段将每条数据都生成为一个单独的Excel文件,可以用于工资条拆分等操作。 一、工作准备 首先下载拆分Excel的小工具(下载地址放在了文章的最后) 准备好要拆分的Excel文件。 二、开始操作 1、将软件与要拆分的Excel文件放到统一个文件夹下 2、下面这个是文件格式,示例是按照A列进
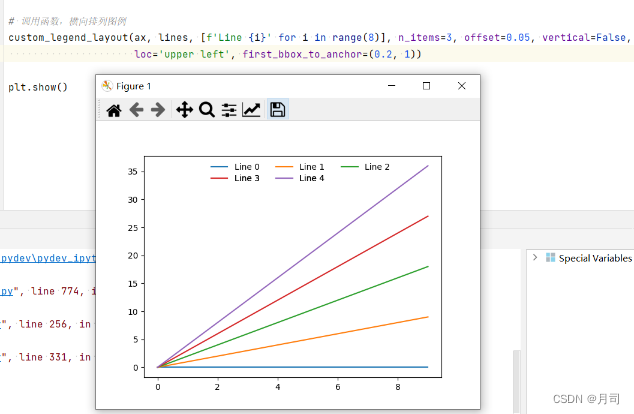
motplotlib图例案例1:通过多个legend完全控制图例显示顺序(指定按行排序 or 按列排序)
这个方法的核心,是手动的获得图中的handlers和labels,然后对它们进行切分和提取,最后分为几个legend进行显示。代码如下: 后来对下面的代码进行修改,通过handlers, labels = get_legend_handles_labels(axs=[axis])自动的获得handler。不再需要诸如handlers = [ax.scatter(range(10), [i *
python二维list按列进行乱序,数组,按列排序
因为python的numpy库可以按行进行乱序所以我们的思路是,先把二维list转置,然后在按行乱序,最后再转置,这样就得到我们的结果。 import numpy as nplabels=[[9,1,3,5],[4,5,6,8],[3,4,5,7],[9,3,2,6]]labels = np.vstack(labels).T # 转置labels=labels[[1,2,3,0],:] #

python按列写入数据到excel
要将数据按列写入 Excel,可以使用 Python 的 openpyxl 库。 首先,需要安装 openpyxl 库。可以使用以下命令在终端或命令提示符中安装: pip install openpyxl 然后,可以按照以下步骤编写代码: 1.导入 openpyxl 库: import openpyxl 2.创建一个新的 Excel 工作簿: workbook = openpyx
对DataFrame数据按列处理
对DataFrame数据按列处理 获取列名使用.columns()函数。 import pandas as pddf=pd.DataFrame({'id':[1,2,3,4,5],'a':[1, 3, 5, 7,9],'b':[2 , 4 , 6, 8, 19], 'c': [4, 6, 9, 12, 20],'d':['yes','yes','no','no','yes']}) df
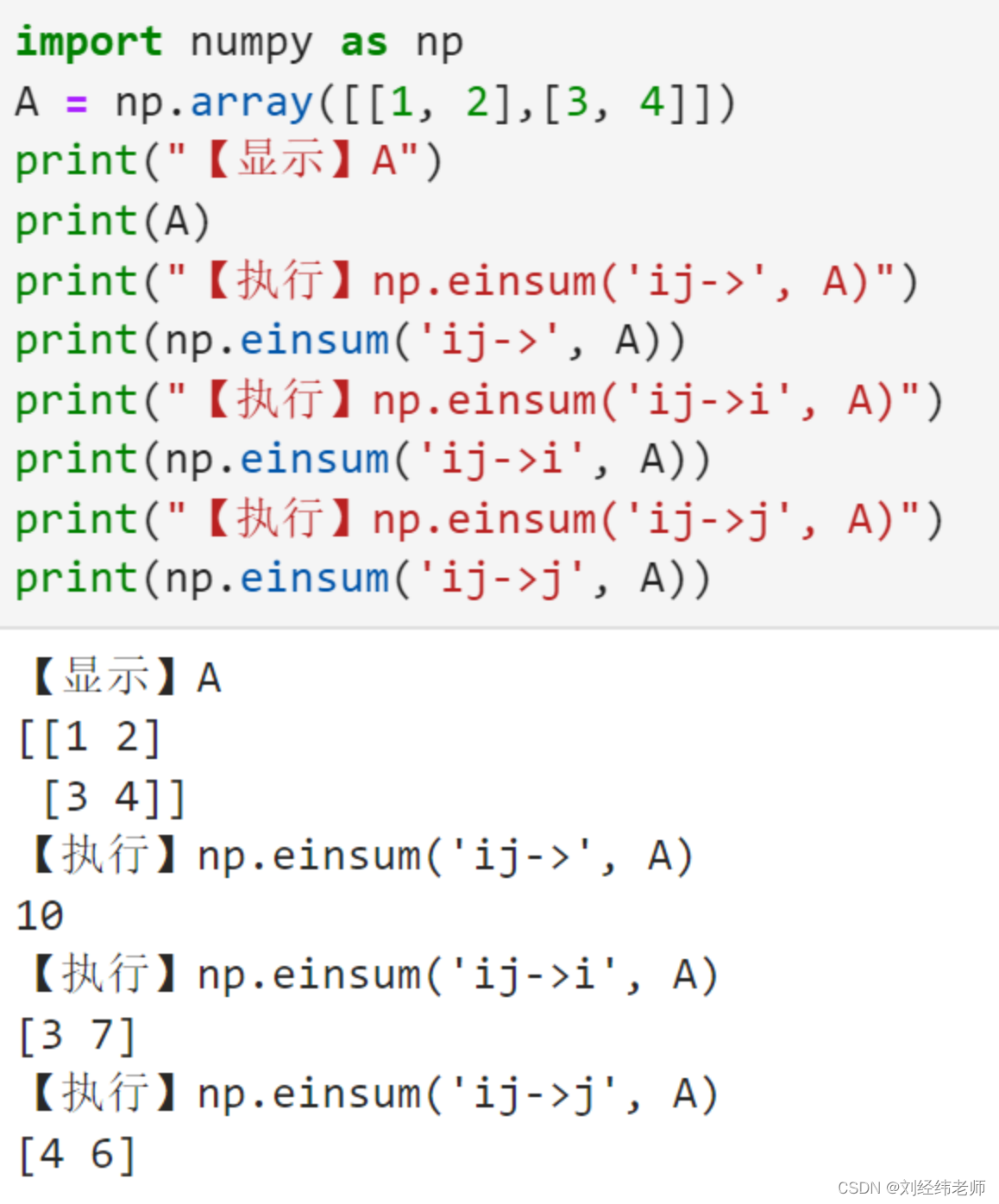
矩阵元素求和:按行、按列、所有元素np.einsum()
【小白从小学Python、C、Java】 【计算机等考+500强证书+考研】 【Python-数据分析】 矩阵元素求和: 按行、按列、所有元素 np.einsum() [太阳]选择题 下列说法正确的是: import numpy as np A = np.array([[1, 2],[3, 4]]) print("【显示】A") print(A) print("【执行】np.

大数据什锦_ORCPARQUET_按列存储_Columnar VS Row-based
文章目录 概述Columnar VS Row-basedORC和PARQUETORCParquet 实验准备创建数据库创建表和加载数据比较表的大小 存储格式+压缩ORCPARQUET 概述 本文通过使用Hadoop的数据仓库工具Hive中的不同存储格式,比较按行存储和按列存储的不同。按列存储使用的是企业中最长见的ORC和PARQUET。 这里不讲解对于Hive的使用。 Co