本文主要是介绍库、表、超级表是什么?怎么用?60后大叔抽丝剥茧讲清TDengine的数据建模,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
视频教程第二弹,快速理清TDengine中的抽象概念,并学会规划生产场景中的数据模型。
点击链接,获取视频教程。
欢迎来到物联网的数据世界
在典型的物联网场景中,一般有多种不同类型的采集设备,采集多种不同的物理量,同一种采集设备类型,往往有多个设备分布在不同的地点,系统需对各种采集的数据汇总,进行计算和分析对于同一类设备,其采集的数据都是很规则的。
本文我们以智能电表(采集量为电流、电压)为例,探讨如何在TDengine中建库、建超级表、建表。
假设每个智能电表采集电流、电压两个量,其采集的数据如下图所示。
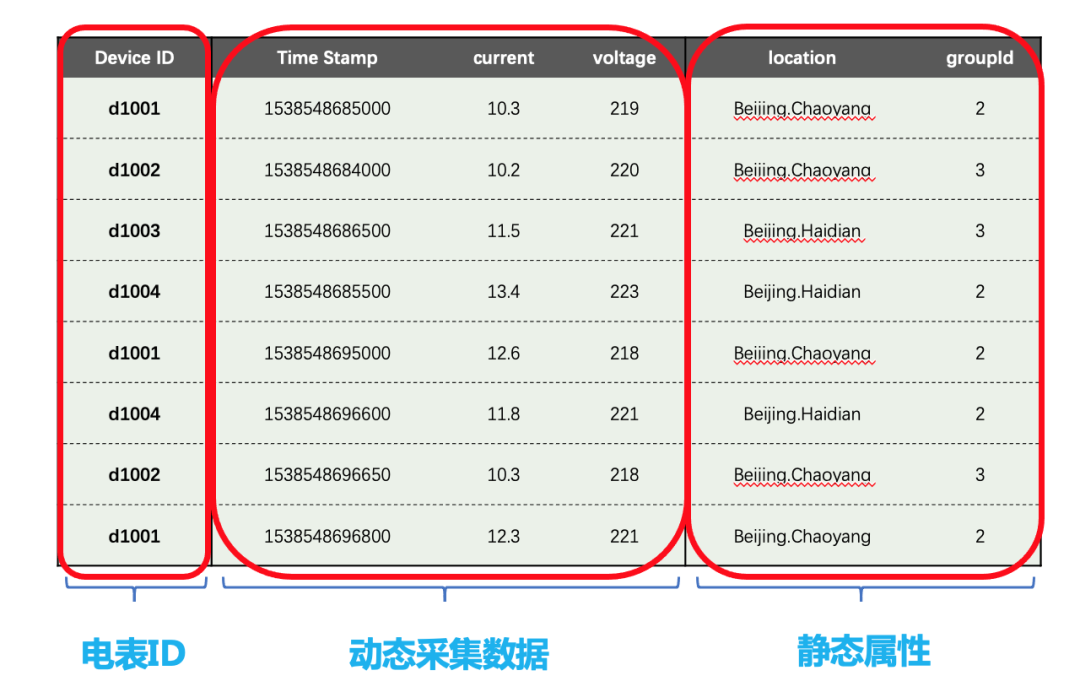
每一条记录都有设备ID,时间戳,采集的物理量(如上图中的电流、电压),还有与每个设备相关的静态标签(如上图中的位置Location和分组groupId)。每个设备是受外界的触发,或按照设定的周期采集数据。采集的数据点是时序的,是一个数据流。
那么TDengine如何抽象这些物联网数据呢?
这里,需要提到TDengine的关键创新点——一个采集点一张表。同一类型的采集点用一个超级表来描述,也就是一个表结构Schema和静态标签Schema 。就上图来说,电表ID作为子表名(d1001, d1002, d1003, d1004等),动态采集的物理量作为各字段,静态属性(Location和groupId)作为子表标签。利用超级表作为模板,生成子表 – 对应各采集点,有了超级表,极大地方便了同类采集点的数据检索、查询、聚合。
这种设计有几大优点:
-
能保证一个采集点的数据在存储介质上是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
-
由于不同采集设备产生数据的过程完全独立,每个设备的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
-
对于一个数据采集点而言,其产生的数据是时序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
如果采用传统的方式,将多个设备的数据写入一张表,由于网络延时不可控,不同设备的数据到达服务器的时序是无法保证的,写入操作是要有锁保护的,而且一个设备的数据是难以保证连续存储在一起的。采用一个数据采集点一张表的方式,能最大程度的保证单个数据采集点的插入和查询的性能是最优的。
数据建模的基本方法
TDengine采用关系型数据模型,需要建库、建表。因此对于一个具体的应用场景,需要考虑库的设计,超级表和普通表的设计。
CREATE DATABASE dbnameUSE dbnameCREATE TABLE stbname (ts timestamp, other fields…) tags ( tag fields)CREATE TABLE tbname using stbname tags(具体标签值)INSERT INTO tbname VALUES(now, values…)
创建库
不同类型的数据采集点往往具有不同的数据特征,包括数据采集频率的高低,数据保留时间的长短,副本的数目,数据块的大小等。为让各种场景下TDengine都能最大效率的工作,建议将不同数据特征的表创建在不同的库里,因为每个库可以配置不同的存储策略。
创建一个库时,除SQL标准的选项外,应用还可以指定保留时长、副本数、内存块个数、时间精度、文件块里最大最小记录条数、是否压缩、一个数据文件覆盖的天数等多种参数。比如建议为数据特征相同的表创建一个库,每个库可以配置不同的存储策略。
CREATE DATABASE power KEEP 365;上述将创建一个名为power的库,这个库的数据将保留365天。更多参数及语法见:
https://www.taosdata.com/cn/documentation20/taos-sql/创建库之后,需要使用SQL命令USE将当前库切换过来,例如:
USE power;将当前操作库换为power。还可使用“库名.表名”来指定操作的库、表的名字。
引入超级表
一个数据采集点一张表, 意味着1000万智能电表对应1000万张表,一个物联网系统,往往存在海量同类型的数据采集点。如何对这么多张表进行操作就是一个巨大的挑战。为方便对同类型多表的操作,TDengine引入超级表。
创建超级表时,需提供:表名、表结构Schema、标签Schema。
CREATE TABLE meters (ts timestamp, current float, voltage int) TAGS (location binary(64), groupdId int);超级表的列分两部分:动态部分,静态部分。
动态部分是采集的数据,第一列为时间戳(ts),其他列为采集的物理量(current, voltage)。
静态部分指采集点的静态属性,一般作为标签。如采集点的地理位置、设备型号、设备组、管理员ID等。
标签可以事后增加、删除、修改。
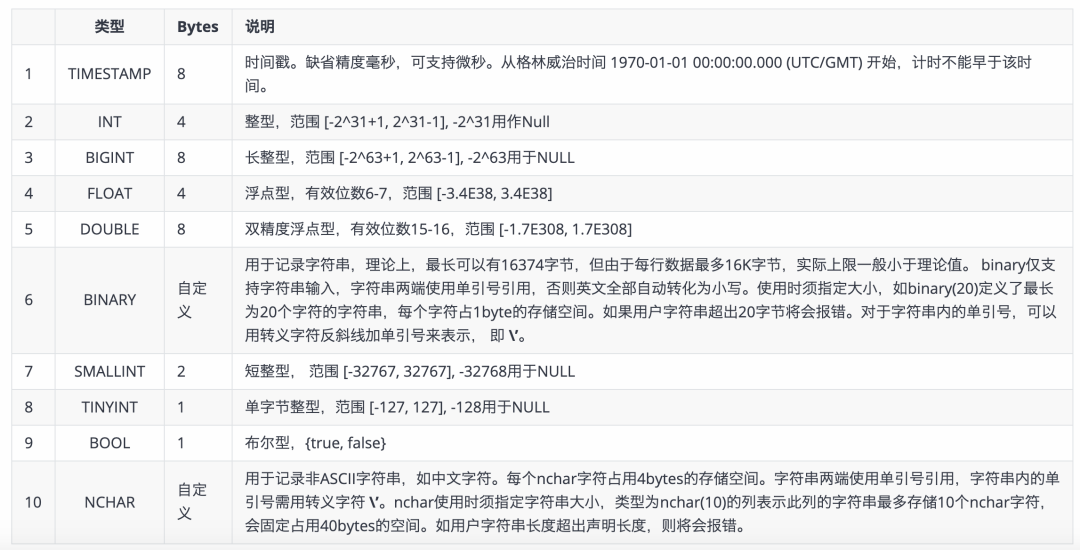
TDengine支持以下数据类型。
深入理解超级表
同时采集同表:一张超级表里,包含的采集物理量必须是同时采集的,也就是说时间戳都是相同的。
对一个类型的设备,可能存在多组物理量,每组物理量并不是同时采集的,则需要为每组物理量单独建一个超级表。因此一个类型的设备,可能需要建立多个超级表。
系统有N个不同类型的设备,就需要建立至少N个超级表。
一个系统可以有多个DB库,一个DB库里可以有一到多个超级表。
创建表/子表
TDengine对每个数据采集点需要独立建表;因为源于超级表(meters)创建而成,也称子表(d1001);创建时,需要使用超级表做模板,同时指定标签的具体值;一个超级表,可包含若干子表,子表数量没有限制。
CREATE TABLE d1001 USING meters TAGS ("Beijing.Chaoyang", 2);d1001是子表名,meters是超级表名,紧跟Location的标签值”Beijing.Chaoyang",groupId的标签值2。在创建表/子表时,需指定标签值,事后也可修改;建议将数据采集点的全局唯一ID作为子表名(如设备序列号)。
子表自动建表
在某些特殊场景中,用户在写数据时,并不确定某个子表是否存在。此时,可使用自动建表语法来创建不存在的表,若该表已存在则不会建立新表。
INSERT INTO d1001 USING meters TAGS ("Beijng.Chaoyang", 2) VALUES (now, 10.2, 219);上述SQL语句将记录(now, 10.2, 219) 插入进表d1001,如果表d1001还未创建,则使用超级表meters做模板自动创建,同时打上标签值“Beijing.Chaoyang", 2。
多列模型 vs 单列模型
TDengine既支持多列模型,也支持单列模型。
-
多列模型:只要物理量是同一数据采集点同时采集的,这些量就可以作为不同列放在一张超级表里。
-
单列模型:每个物理量都单独建表。比如电流、电压两个量,就建两张超级表。
我们建议:尽可能采用多列模型,因为插入效率以及存储效率更高;对于有些场景,一个采集点的物理量的种类经常变化,这时可采用单列模型。
新能源汽车示例
场景及建模分析
-
某车企拟对其生产、销售的新能源汽车进行追踪分析;
-
每辆车配置了远程采集终端,采集车辆状态信息:位置(经纬度)、车速、电池温度、电池电流、环境温度、轮胎胎压;
-
后台统计分析需要按:车型、销售区域、销售员、电池包容量、电机功率进行分类聚合;
-
6个采集量中前4个为同时采集,将其放入一张超级表 – vehicle_main, 其余2个测点,温度与胎压采集的频率完全不一样,分别创建2个超级表 – vehicle_temp, vehicle_tire;
-
每辆车有唯一编码VIN,采用该编码与超级表的表名前缀作为唯一表名。
SQL语句示例
CREATE DATABASE nev KEEP 3650;USE nev;CREATE TABLE vehicle_main (ts timestamp, longitude double, latitude double, vspeed int, btemp int, bcurrent int) TAGS (vin binary(30), model binary(20), szone binary(30), sales int, bcapacity float, mpower float);CREATE TABLE vmTS8392EGV062192009 USING vehicle_main TAGS ("TS8392EGV062192009", "GTS7180", "Beijing.haidian", "10060089", 86.0, 125.5);
CREATE TABLE vehicle_temp (ts timestamp, vtemp int) TAGS (vin binary(30));CREATE TABLE vtpTS8392EGV062192009 USING vehicle_vtemp TAGS ("TS8392EGV062192009");CREATE TABLE vehicle_tire (ts timestamp, vpressure int) TAGS (vin binary(30));CREATE TABLE vtrTS8392EGV062192009 USING vehicle_vtire TAGS ("TS8392EGV062192009");//查询指定车辆最近10天的运行轨迹SELECT ts, longtitude, latitude FROM vtrTS8392EGV062192009 where ts >now -10d//按车型查询平均车速、平均动力电池温度、平均放电电流SELECT AVG(vspeed), AVG(btemp), AVG(bcurrent) FROM vehicle_main GROUP BY model
相信到这里,你已经完全理清了TDengine中库、表、超级表的概念,可以上手操作了!
关注公众号TDengine,后台回复“1203”,获取本教程对应PPT。
这篇关于库、表、超级表是什么?怎么用?60后大叔抽丝剥茧讲清TDengine的数据建模的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





