本文主要是介绍mysql筛选出重复数据得第一条_sql根据某一个字段重复只取第一条数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
展开全部
代码如下:
select * from tbl_DPImg where ID in (select min(ID) from tbl_DPImg group by DPID)
处理后结果为:
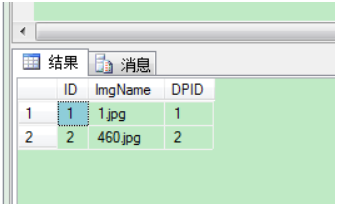
查找表中多余的重复记录,32313133353236313431303231363533e4b893e5b19e31333365666230重复记录是根据单个字段(teamId)来判断
select * from team where teamId in (select teamId from team group by teamId having count(teamId) > 1)
删除表中多余的重复记录,重复记录是根据单个字段(teamId)来判断,只留有rowid最小的记录
delete from team where
teamName in(select teamName from team group by teamName having count(teamName) > 1)
and teamId not in (select min(teamId) from team group by teamName having count(teamName)>1)
扩展资料
数据记录筛选:
sql="select * from 数据表 where字段名=字段值 order by字段名[desc]"(按某个字段值降序排列。默认升序ASC)
<这篇关于mysql筛选出重复数据得第一条_sql根据某一个字段重复只取第一条数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



