只取专题

mysql筛选出重复数据得第一条_sql根据某一个字段重复只取第一条数据
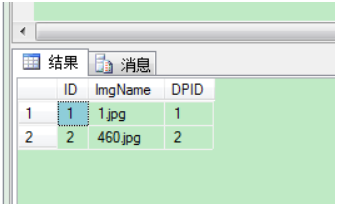
展开全部 代码如下: select * from tbl_DPImg where ID in (select min(ID) from tbl_DPImg group by DPID) 处理后结果为: 查找表中多余的重复记录,32313133353236313431303231363533e4b893e5b19e31333365666230重复记录是根据单个字段(teamId)来判断 sele

Swift3按顺序只取前五个最高分组成排行榜,sorted array of top 5 scores leaderboard
假设array有5个分数 let array = [98,88,33,22,10] 每次新输入的成绩,如果比最低分高,则取代数列中的某分值的位置 if(newValue!>array[4]){for i in (0..<5){if(newValue!>array[i]){for j in (i+1..<5).reversed(){array[j] = array[j-1]}array[i]

取得数据表中前N条记录,某列重复的话只取第一条记录
项目需要筛选出不重复数据,以前没有做过,第一反应就是利用distinct处理,但是弄了好久也没搞出来,大家有知道的望告知下。 这次筛选没有使用distinct ,是利用group by ,利用id为唯一标示符(自增长),对按user进行排列,然后取重复项最小id(非重复项直接取唯一id),并以此id为条件查询,从而去除重复的数据。 数据格式为: 使用语句如下:
postgreSql的监控记录表里多条不同时间的数据,只取最新的数据,并分组统计
目录 1. 背景2. 需求:3. 构建数据3.1 创建表结构:3.2 造数据 4. 需求实现4.1 需求1的SQL语句4.2 需求2的SQL语句 1. 背景 比如气象台的气温监控,每半小时上报一条数据,有很多个地方的气温监控,这样数据表里就会有很多地方的不同时间的气温数据 2. 需求: 每次查询只查最新的气温数据按照不同的温度区间来分组查出,比如:高温有多少地方,正常有多少

MySQL之表中重复字段只取第一个值
有时在我们的SQL表中包含很多同名的数据,这样可以将多维度的数据保存的一个表中,但是对于查询会带来一些麻烦。 如上图,如果我们只想取每个学校的第一条数据:我们可以使用DISTINCT去重 SQL: select DISTINCT history.school From history 这样查询到的是第一个学校名,仅是学校名,想保留该行全部,见 MySQL之保留重复数据第一行

面试题-redis-为什么Redis只取16384个槽
计算公式 HASH_SLOT = RCR16(key) mod 16384 (1)如果槽位为65536(2^16),发送心跳信息的消息头达8k,发送的心跳包过于庞大。 在消息头中最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为65536时,这块的大小是: 65536÷8÷1024=8kb 在消息头中最占空间的是myslots[CLUSTER_SLOTS/8