本文主要是介绍从扩散模型基础到DIT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Diffusion model 扩散模型如何工作?
输入随机噪声和文本内容,通过多次预测并去除图片中的噪声后,最终生成清晰的图像。
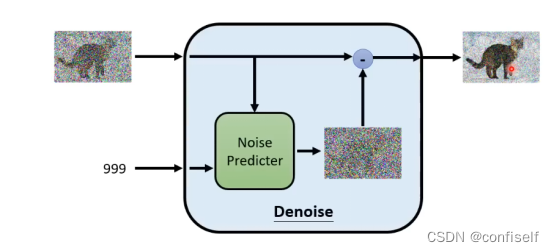
以上左边这张图,刚开始是随机噪声,999为时间序列。
为什么不直接预测下一张图片呢?
预测噪声还是简单一点。
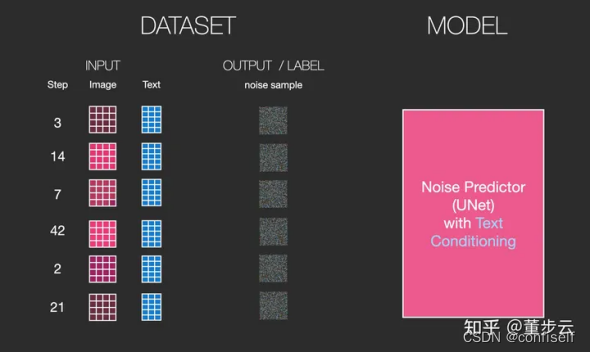
如何训练 Noise Predicter呢?
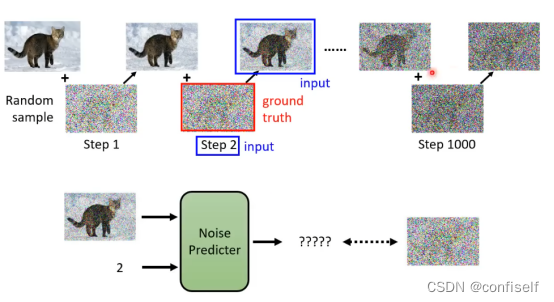
具体的方法是自己去按步骤加噪音,这样就构建了训练样本。预测目标就是我们加的噪声。
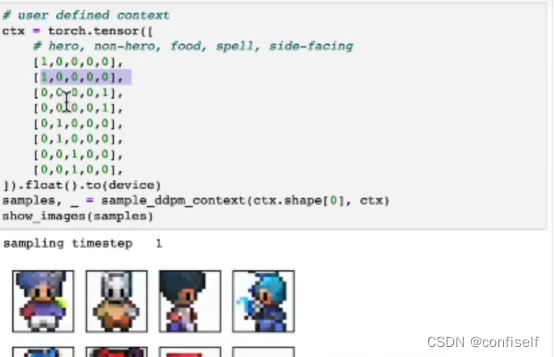
如何加入文字?
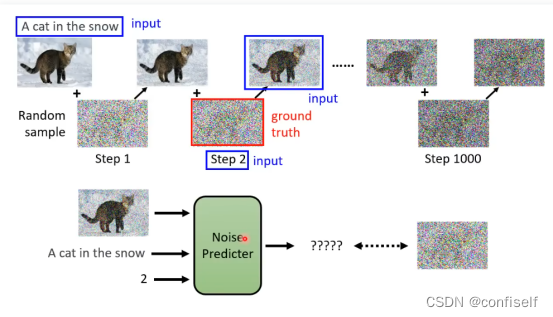
可以看出,增加文字输入即可
DDPM原理

当然具体的噪声loss计算,以及去噪公式稍微麻烦一点,并不是直接加减。
左图中为噪声的均方误差loss计算。
图中XT为T时刻的有噪图片,Xt-1为去噪后的图片。
UNET噪声预测器
对于Stable Diffusion等主流的扩散模型,噪声预测部分都是使用UNET。图示结构如下,可以看出输入含噪声图片,输出噪声

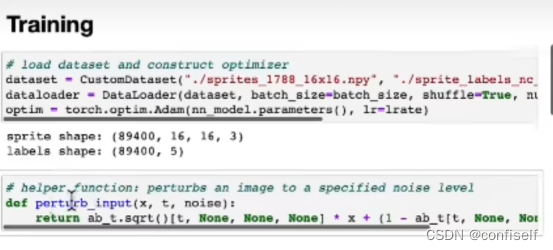
训练代码如下:

这里nn_model即为UNET网络,支持图片,时间和文本上下文嵌入等相关信息。参考代码如下:



训练代码


预测代码
DDIM
比DDPM快10倍,采样步数到500步以上DDPM更好,否则DDIM更好。
Stable Diffusion
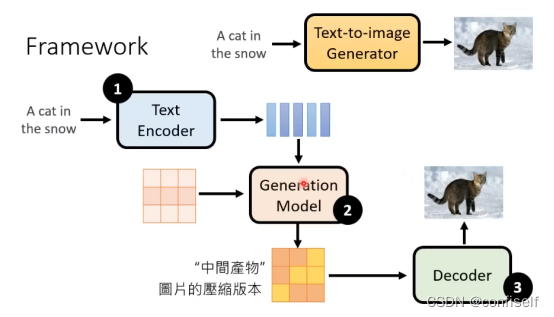
其他模型结构如下,很类似。
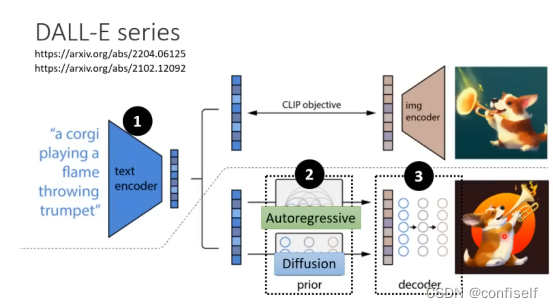
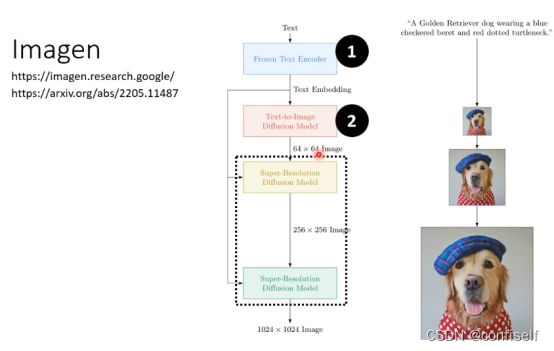
引入VAE(变分自编码器)
为了加快图像生成过程,Stable Diffusion 并不是在像素图像本身上运行扩散过程,而是在图像的压缩版本上运行。该论文称其为“Departure to Latent Space”。
https://arxiv.org/abs/2112.10752
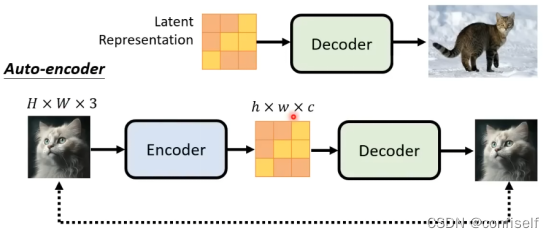
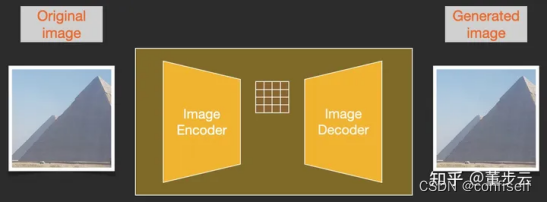
这种压缩(以及后来的解压缩/绘画)是通过自动编码器完成的。自动编码器将图像压缩到潜空间(Latents),然后使用解码器凭借这些压缩后的数据重建。
实际使用过程中直接调用已经训练好的VAE做编码和解码即可。原理如下:
参考:Stable Diffusion|图解稳定扩散原理 - 知乎
模型细节如下:
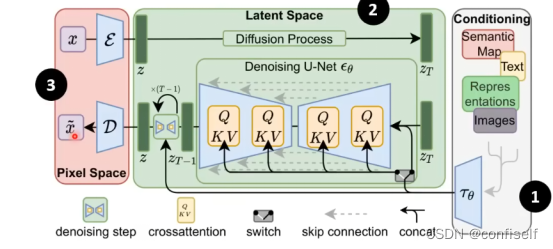
注意这里的文本也是做了编码为向量。
DIT(Scalable diffusion models with transformers)
基于transformers的可扩展的扩散模型
DIT利用transformer替换了unet.
有什么好处? 更高的Gflops(网络复杂度),具备更好的扩展性scaling(tokens扩展,网络深度扩展,增加参数量就能有更好的性能),有较低的t FID of 2.27 (即预测效果)
transformer统一了NLP和视觉领域,SORA正是基于此论文完成主体部分。
什么是FID
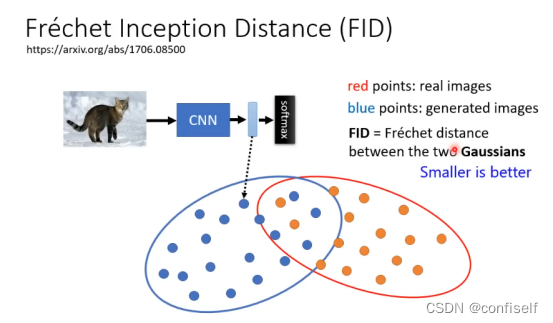
即衡量两张图片之间的相似性。
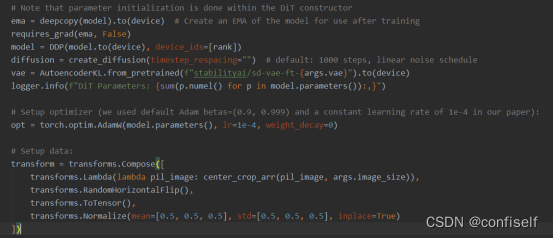
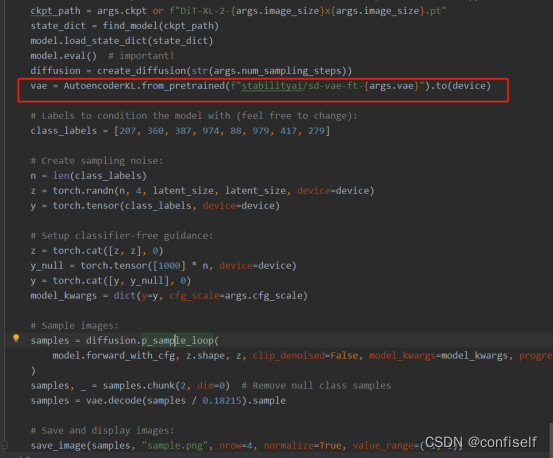
从它的训练和预测代码中,我们看到也使用了训练好的VAE模型。
训练时调用encoder
预测时调用decoder
SORA
在上一篇文章中已经介绍过
这篇关于从扩散模型基础到DIT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







