本文主要是介绍【算法与数据结构】1020、130、LeetCode飞地的数量 被围绕的区域,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、1020、飞地的数量
- 二、130、被围绕的区域
- 三、完整代码
所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。
一、1020、飞地的数量
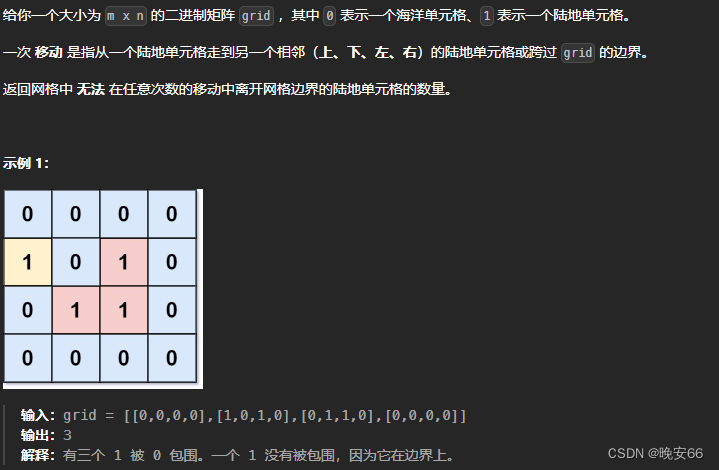

思路分析:博主认为题目很抽象,非常难理解。想了好久,要理解题目什么意思,必须理解“移动”这个概念。“移动”是指陆地可以移动,移动到连接的陆地单元或者跨过边界。例如示例1中的(1, 0)这块陆地可以移出边界,示例2中(2, 2)这块陆地,可以按照 ( 1 , 2 ) − > ( 0 , 2 ) − > ( 0 , 1 ) − > 边界外 (1, 2)->(0, 2)->(0, 1)->边界外 (1,2)−>(0,2)−>(0,1)−>边界外 的顺序离开网格边界。其他的陆地也类似,连接的陆地都可以移出边界。另一方面,从题目来理解更简单,要求飞地的数量。所谓飞地就是不和边界挨着的陆地,这也和任意次数“移动”出网格边界的定义一致。
飞地的数量我们一眼就能看出,不和边界挨着的就是飞地。反过来想,我们顺着边界找到所有连接的陆地,讲这些陆地全部删除,剩下的就都是飞地,然后统计数量即可。程序当中,删除的这一操作不必实际进行,我们将其标记为已遍历,只要坐标是陆地且没有被遍历过就是飞地。
程序如下:
// 1020、飞地的数量-深度优先搜索
class Solution {
private:int Area = 0;vector<vector<int>> delta_x_y = { {0, -1}, {0, 1}, {-1, 0}, {1, 0} }; // 上下左右四个方向的偏移量void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) { // 1、递归输入参数// 2、终止条件 访问过或者遇到海水,又或者越界if (x < 0 || x >= grid.size() || y < 0 || y >= grid[0].size() || visited[x][y] || grid[x][y] == 0) return; // 越界了,直接跳过visited[x][y] = true;//grid[x][y] = 0; // 可以省略// 3、单层递归逻辑for (int i = 0; i < 4; i++) {int nextx = x + delta_x_y[i][0];int nexty = y + delta_x_y[i][1]; dfs(grid, visited, nextx, nexty);}}
public:int numEnclaves(vector<vector<int>>& grid) {vector<vector<bool>> visited = vector<vector<bool>>(grid.size(), vector<bool>(grid[0].size(), false)); // 遍历过的坐标// 遍历最外面的一圈for (int i = 0; i < grid.size(); i++) { // 遍历两列dfs(grid, visited, i, 0);dfs(grid, visited, i, grid[0].size() - 1);}for (int j = 1; j < grid[0].size() - 1; j++) { // 遍历两行dfs(grid, visited, 0, j);dfs(grid, visited, grid.size() - 1, j);}for (int i = 1; i < grid.size() - 1; i++) { // 遍历行for (int j = 1; j < grid[0].size() - 1; j++) { // 遍历列if (grid[i][j] == 1 && !visited[i][j]) Area++; // 深度优先搜索,将连接的陆地都标记上true}}return Area;}
};
复杂度分析:
- 时间复杂度: O ( m × n ) O(m \times n) O(m×n),其中 m m m和 n n n分别是岛屿数组的行数和列数。
- 空间复杂度: O ( m × n ) O(m \times n) O(m×n),主要是栈的调用,最坏情况下,网格全是陆地,深度优先搜索的深度达到 m × n m \times n m×n。
二、130、被围绕的区域
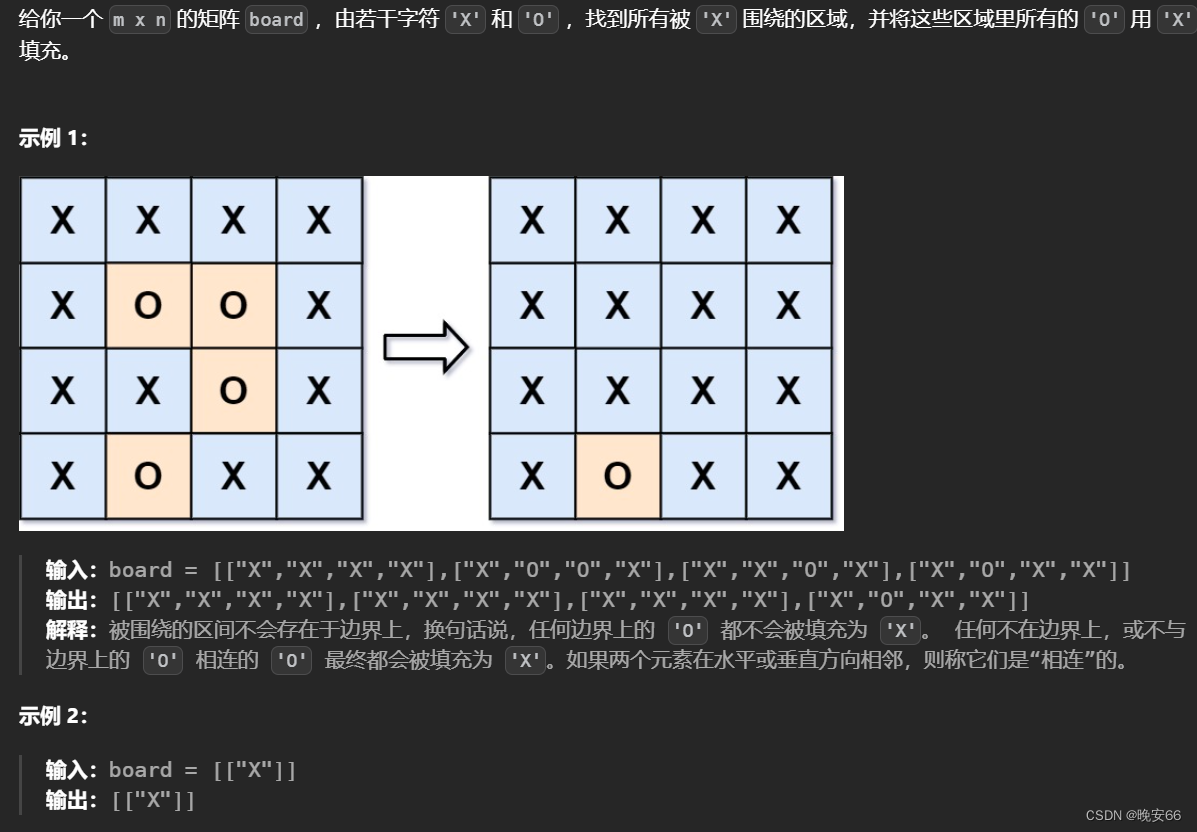

思路分析:本题需要求将飞地改成‘X’。那么一个思路就是沿着网格边界搜索一遍,找到所有的‘O’并标记,表示这些‘O’不是飞地。然后,再将网格数组中的所有未标记过的‘O’改成‘X’即可。按照这样的思路需要一个额外的visited数组来标记‘O’,造成额外开销。实际上我们只需要区别标记过的‘O’(挨着边界的陆地)和未标记的‘O’(飞地),将标记过的‘O’改成其他字符即可(例如‘A’或者‘B’或者其他任意一个字符)。
程序当中,先沿着边界遍历挨着边界的陆地,都改成‘A’。然后遍历边界以外的网格点,碰见‘O’就必然是飞地,将其改成‘X’。最后再将‘A’变回‘O’。
程序如下:
// 130、被围绕的区域-深度优先搜索
class Solution2 {
private:vector<vector<int>> delta_x_y = { {0, -1}, {0, 1}, {-1, 0}, {1, 0} }; // 上下左右四个方向的偏移量void dfs(vector<vector<char>>& board, int x, int y) { // 1、递归输入参数// 2、终止条件 遇到海水或者越界,遇到遍历过的陆地if (x < 0 || x >= board.size() || y < 0 || y >= board[0].size() || board[x][y] == 'X' || board[x][y] == 'A') return;board[x][y] = 'A';// 3、单层递归逻辑for (int i = 0; i < 4; i++) {int nextx = x + delta_x_y[i][0];int nexty = y + delta_x_y[i][1];dfs(board, nextx, nexty);}}
public:void solve(vector<vector<char>>& board) {vector<vector<bool>> visited = vector<vector<bool>>(board.size(), vector<bool>(board[0].size(), false)); // 遍历过的坐标// 遍历最外面的一圈,找到挨着边界的陆地for (int i = 0; i < board.size(); i++) { // 遍历外圈的两列if (board[i][0] == 'O') dfs(board, i, 0);if (board[i][board[0].size() - 1] == 'O') dfs(board, i, board[0].size() - 1);}for (int j = 1; j < board[0].size() - 1; j++) { // 遍历外圈的两行if (board[0][j] == 'O') dfs(board, 0, j);if (board[board.size() - 1][j] == 'O') dfs(board, board.size() - 1, j);}// 遍历除边界以外的格点for (int i = 0; i < board.size(); i++) { // 遍历行for (int j = 0; j < board[0].size(); j++) { // 遍历列if (board[i][j] == 'O') board[i][j] = 'X'; // 删除飞地if (board[i][j] == 'A') board[i][j] = 'O'; // 还原'O'}}}
};
复杂度分析:
- 时间复杂度: O ( m × n ) O(m \times n) O(m×n),其中 m m m和 n n n分别是网格数组的行数和列数。
- 空间复杂度: O ( m × n ) O(m \times n) O(m×n),主要是栈的调用。最坏情况下,网格全是‘O’,深度优先搜索的深度达到 m × n m \times n m×n。
三、完整代码
# include <iostream>
# include <vector>
# include <string>
using namespace std;// 1020、飞地的数量-深度优先搜索
class Solution {
private:int Area = 0;vector<vector<int>> delta_x_y = { {0, -1}, {0, 1}, {-1, 0}, {1, 0} }; // 上下左右四个方向的偏移量void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) { // 1、递归输入参数// 2、终止条件 访问过或者遇到海水,又或者越界if (x < 0 || x >= grid.size() || y < 0 || y >= grid[0].size() || visited[x][y] || grid[x][y] == 0) return; // 越界了,直接跳过visited[x][y] = true;//grid[x][y] = 0; // 可以省略// 3、单层递归逻辑for (int i = 0; i < 4; i++) {int nextx = x + delta_x_y[i][0];int nexty = y + delta_x_y[i][1]; dfs(grid, visited, nextx, nexty);}}
public:int numEnclaves(vector<vector<int>>& grid) {vector<vector<bool>> visited = vector<vector<bool>>(grid.size(), vector<bool>(grid[0].size(), false)); // 遍历过的坐标// 遍历最外面的一圈for (int i = 0; i < grid.size(); i++) { // 遍历外圈的两列dfs(grid, visited, i, 0);dfs(grid, visited, i, grid[0].size() - 1);}for (int j = 1; j < grid[0].size() - 1; j++) { // 遍历外圈的两行dfs(grid, visited, 0, j);dfs(grid, visited, grid.size() - 1, j);}for (int i = 1; i < grid.size() - 1; i++) { // 遍历行for (int j = 1; j < grid[0].size() - 1; j++) { // 遍历列if (grid[i][j] == 1 && !visited[i][j]) Area++; // 深度优先搜索,将连接的陆地都标记上true}}return Area;}
};// 130、被围绕的区域-深度优先搜索
class Solution2 {
private:vector<vector<int>> delta_x_y = { {0, -1}, {0, 1}, {-1, 0}, {1, 0} }; // 上下左右四个方向的偏移量void dfs(vector<vector<char>>& board, int x, int y) { // 1、递归输入参数// 2、终止条件 遇到海水或者越界,遇到遍历过的陆地if (x < 0 || x >= board.size() || y < 0 || y >= board[0].size() || board[x][y] == 'X' || board[x][y] == 'A') return;board[x][y] = 'A';// 3、单层递归逻辑for (int i = 0; i < 4; i++) {int nextx = x + delta_x_y[i][0];int nexty = y + delta_x_y[i][1];dfs(board, nextx, nexty);}}
public:void solve(vector<vector<char>>& board) {vector<vector<bool>> visited = vector<vector<bool>>(board.size(), vector<bool>(board[0].size(), false)); // 遍历过的坐标// 遍历最外面的一圈,找到挨着边界的陆地for (int i = 0; i < board.size(); i++) { // 遍历外圈的两列if (board[i][0] == 'O') dfs(board, i, 0);if (board[i][board[0].size() - 1] == 'O') dfs(board, i, board[0].size() - 1);}for (int j = 1; j < board[0].size() - 1; j++) { // 遍历外圈的两行if (board[0][j] == 'O') dfs(board, 0, j);if (board[board.size() - 1][j] == 'O') dfs(board, board.size() - 1, j);}// 遍历除边界以外的格点for (int i = 0; i < board.size(); i++) { // 遍历行for (int j = 0; j < board[0].size(); j++) { // 遍历列if (board[i][j] == 'O') board[i][j] = 'X'; // 删除飞地if (board[i][j] == 'A') board[i][j] = 'O'; // 还原'O'}}}
};void my_print(vector<vector<char>> board, string message) {cout << message << endl;for (vector<vector<char>>::iterator it = board.begin(); it != board.end(); it++) {for (vector<char>::iterator jt = (*it).begin(); jt != (*it).end(); jt++) {cout << *jt << " ";}cout << endl;}
}int main() {// // 1020、飞地的数量-深度优先搜索-测试案例//vector<vector<int>> grid = { {0, 0, 0, 0}, { 1, 0, 1, 0 }, { 0, 1, 1, 0 }, { 0, 0, 0, 0 } };//Solution s1;//int result = s1.numEnclaves(grid);//cout << result << endl;// 130、被围绕的区域-深度优先搜索-测试案例vector<vector<char>> board = { {'X', 'X', 'X', 'X'}, {'X', 'O', 'O', 'X'}, {'X', 'X', 'O', 'X'}, {'X', 'O', 'X', 'X'} };my_print(board, "替换前:");Solution2 s1;s1.solve(board);my_print(board, "替换后:");system("pause");return 0;
}
end
这篇关于【算法与数据结构】1020、130、LeetCode飞地的数量 被围绕的区域的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







