本文主要是介绍基于卷积神经网络对空气质量指数(aqi)分析与预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、课题背景和意义
1.1课题背景
空气质量对人类健康和环境保护具有重要意义。为了评估和监测空气质量,许多地区使用空气质量指数(AQI)作为衡量标准。AQI是一种综合指标,通过综合考虑多个空气污染物的浓度和健康影响,将空气质量归类为不同的级别,从而提供公众对空气质量状况的直观了解。
AQI的计算通常依赖于大量的观测数据和复杂的数学模型。传统的AQI计算方法往往需要大量的人力和时间,并且对于实时预测和长期趋势分析的需求无法满足。因此,开发一种准确、高效的AQI预测模型对于改善空气质量管理和提供准确的预测信息至关重要。
深度学习技术在近年来在各个领域都取得了显著的突破,特别是在计算机视觉和自然语言处理等领域。其中,卷积神经网络(CNN)作为一种强大的深度学习模型,在图像处理和序列数据分析等任务中表现出色。鉴于空气质量数据具有时序性和空间相关性,将CNN应用于AQI预测是一种有前景的方法。
1.2国内外研究现状
中国作为全球最大的污染物排放国之一,对空气质量的研究一直备受关注。在国内,许多研究致力于基于统计方法、机器学习和深度学习等技术开发AQI预测模型。例如,有研究采用支持向量回归(SVR)和随机森林(RF)等机器学习方法进行AQI预测,并取得了一定的准确性和预测效果。此外,一些研究还将AQI预测与气象数据、地理信息等因素相结合,以提高预测模型的精度和稳定性。国内研究还注重对AQI变化规律的探索和分析。一些研究通过时空数据分析,揭示了不同城市、不同季节和不同污染物之间的关联性。此外,一些研究还探索了AQI与人体健康的关系,例如空气质量对呼吸系统疾病和心血管疾病的影响等。
国外的研究也广泛涉及到AQI分析与预测。在国外,一些研究着重于应用机器学习和深度学习技术进行AQI预测,并取得了较好的结果。例如,使用支持向量机(SVM)、随机森林(RF)和神经网络等方法进行AQI预测的研究,对不同地区和不同时间尺度的AQI变化进行了深入分析。
2、数据分析技术
2.1numpy
NumPy(Numerical Python)是一个功能强大的开源数值计算库,专为处理多维数组和执行数值计算而设计。它是Python科学计算生态系统的核心组成部分,广泛应用于数据分析、机器学习、图像处理等领域。它的核心数据结构是ndarray(N-dimensional array),它是一种高效、灵活的多维数组对象。ndarray在内存中以连续的块存储数据,这使得NumPy可以高效地处理大规模的数据集。ndarray不仅支持整数、浮点数和布尔类型的元素,还可以存储复杂的数据类型。NumPy提供了丰富的数学函数和运算符,使得用户可以进行各种数值计算操作。NumPy还提供了强大的索引和切片功能,使得用户可以方便地访问和操作ndarray中的元素。用户可以使用整数索引、布尔索引和切片来选择特定的数据子集。这种灵活的索引机制为数据筛选、处理和分析提供了便利。
NumPy在空气质量数据的处理和分析中发挥着重要的作用。它提供了高效的数组操作和数值计算功能,可以帮助研究人员对空气质量数据进行处理、分析和可视化,从而更好地理解和应用这些数据。
2.2pandas
Pandas提供了两种主要的数据结构:Series和DataFrame。Series是一种一维标记数组,类似于带有索引的数组或列表,它可以存储任意类型的数据。DataFrame是一个二维标记数据结构,类似于关系型数据库中的表格,它由多个列组成,每个列可以是不同的数据类型。DataFrame提供了丰富的功能,可以灵活地进行数据选择、过滤、排序和聚合操作。Pandas具有广泛的数据处理和操作功能。它可以轻松地加载和保存各种数据源的数据,包括CSV文件、Excel文件、数据库查询结果等。Pandas还提供了灵活而强大的数据分析工具。它Pandas与其他数据科学和机器学习库(如NumPy、Matplotlib和Scikit-learn)紧密集成,可以无缝地与它们进行交互。它可以与NumPy进行高效的数组操作,与Matplotlib一起绘制各种类型的图表,与Scikit-learn一起构建和评估机器学习模型。
Pandas在空气质量数据处理和分析中的重要作用。它提供了数据加载、数据清洗、特征选择、数据归一化和数据集划分等功能,为后续的模型训练和评估提供了数据准备和预处理的基础。同时,Pandas提供了丰富的数据操作和分析工具,如数据选择、过滤、排序和聚合等,可以帮助用户快速获取数据摘要、进行统计计算和生成可视化图表,为空气质量数据的分析和洞察提供支持。
2.2数据可视化库Matplotlib
Matplotlib是一个强大的Python数据可视化库,被广泛应用于科学研究、数据分析和数据可视化领域。它的设计灵感来自于Matlab,并且提供了类似于Matlab的绘图接口,使用户可以轻松地创建各种类型的图表和图形。
Matplotlib的优势是其高度的灵活性。它支持各种图表类型,包括线图、散点图、柱状图、饼图、等高线图等,满足了不同领域和需求的数据可视化需求。用户可以根据具体的需求自定义图表的样式、颜色、标签、标题等,以及添加图例、注释和标记,使图表更具可读性和信息表达能力。
Matplotlib的优势之二是其广泛性和兼容性。它可以与众多科学计算库和数据处理工具(如NumPy、Pandas和SciPy)无缝集成,能够直接操作这些库的数据结构,方便地将数据转换为图形展示。同时,Matplotlib还支持多种输出格式,包括图像文件(如PNG、JPEG、PDF)、矢量图形文件(如SVG、EPS)和交互式图形界面等,满足不同场景和需求的输出要求。
Matplotlib还提供了丰富的图表定制和交互功能。用户可以使用绘图对象、轴对象和图形对象等API进行细粒度的控制,调整图表的布局、比例尺和轴标签等。此外,Matplotlib还支持交互式功能,用户可以使用鼠标和键盘进行缩放、平移和数据点选择等操作,以便更深入地探索数据。
Matplotlib在空气质量数据的处理和分析中提供了丰富的绘图功能,能够将数据可视化,帮助研究人员更好地理解和分析数据。通过Matplotlib的应用,研究人员可以从空气质量数据中获取更深入的洞察力,并对数据进行预处理、模型评估和结果解释等方面的工作。
2.3深度学习框架TensorFlow
TensorFlow使用计算图来表示机器学习模型,其中节点表示操作,边表示数据流。这种图形表示可以将复杂的计算过程可视化,并提供灵活性和可扩展性。
TensorFlow支持自动求导,可以自动计算模型的梯度。这对于优化模型参数和进行反向传播训练是非常关键的。TensorFlow使用计算图和底层优化技术,如张量操作和并行计算,以实现高效的数值计算。它支持在多个GPU和分布式环境下进行训练和推理,提供了快速而可扩展的计算能力。TensorFlow可以在多种硬件平台上运行,包括CPU、GPU和专用的Tensor Processing Unit(TPU)。它还提供了多个编程接口,如Python、C++和Java,以满足不同开发者的需求。
在该项目中,通过TensorFlow的高级API(如Keras),可以快速搭建模型,并配置层、激活函数和优化器等。通过使用TensorFlow的自动求导功能,可以自动计算梯度并更新模型的参数,使其逐步优化。,通过使用TensorFlow的evaluate函数,可以计算模型在测试集上的损失值和其他评价指标,以衡量模型的预测能力。通过TensorFlow的predict函数,可以对新数据进行预测和推理。在该项目中,使用训练好的模型对未来三天的AQI进行预测,并输出预测结果。
3、方法原理
3.1处理过程
1、数据读取与填充缺失值: 使用Pandas库的read_csv函数读取CSV文件,并将数据存储在名为data的DataFrame中。然后,使用fillna方法将缺失值用该列的均值进行填充。这样可以确保数据集中的缺失值不会影响模型的训练和预测过程。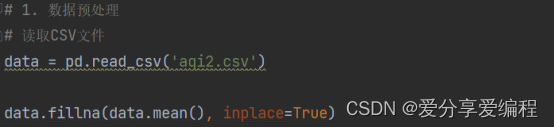
2、特征提取与目标变量分离: 从数据中提取输入特征和目标变量。在这个项目中,输入特征是['PM2.5', 'PM10', 'CO', 'No2', 'So2', 'O3']这六个列的值,目标变量是'AQI'列的值。通过将数据存储在NumPy数组X和y中,我们可以将它们用于后续的数据处理和模型训练。
3、使用train_test_split函数将数据集划分为训练集和测试集。在这个项目中,将70%的数据作为训练集,30%的数据作为测试集。通过这种划分,可以在模型训练过程中使用训练集进行参数优化,然后在测试集上评估模型的性能。
![]()
4、特征缩放: 使用StandardScaler类对输入特征进行特征缩放,使其具有零均值和单位方差。这有助于提高模型的收敛速度和稳定性。首先,创建一个StandardScaler对象,然后使用fit_transform方法对训练集进行拟合和转换,使用transform方法对测试集进行转换。
5、数据形状调整: 将输入特征的形状调整为适应卷积层的输入要求。通过在输入数据的维度中添加一个维度,将其从(样本数, 特征数)调整为(样本数, 特征数, 1)的形式。
6、模型选择和训练: 在该项目中,使用了一个基于卷积神经网络的模型进行空气质量指数(AQI)的预测。在Net类中,通过使用Sequential模型构建了一个卷积神经网络模型。模型的架构包括两个卷积层(每个卷积层后跟一个最大池化层),一个展平层和两个全连接层。最后一层是一个单一神经元,用于输出预测的AQI值。 模型训练和评估: 7、在模型训练阶段,使用训练集的输入特征和目标变量调用fit方法来拟合模型。训练过程中,设置了批量大小(batch_size)和训练轮数(epochs)。训练完成后,可以使用测试集数据对模型进行评估,计算模型在测试集上的损失值。
模型训练和评估: 7、在模型训练阶段,使用训练集的输入特征和目标变量调用fit方法来拟合模型。训练过程中,设置了批量大小(batch_size)和训练轮数(epochs)。训练完成后,可以使用测试集数据对模型进行评估,计算模型在测试集上的损失值。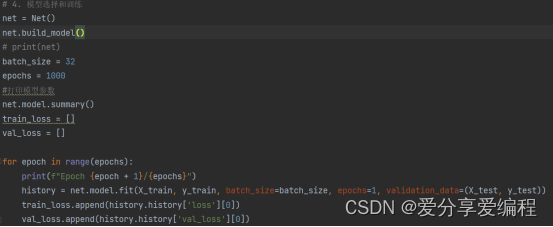 预测未来数据: 在8、该项目中,使用已训练好的模型对未来三天的空气质量指数进行预测。首先,创建一个包含未来三天数据的DataFrame,并使用之前拟合的StandardScaler对象对数据进行缩放。然后,调整数据形状以适应模型输入要求,并使用predict方法对数据进行预测。
预测未来数据: 在8、该项目中,使用已训练好的模型对未来三天的空气质量指数进行预测。首先,创建一个包含未来三天数据的DataFrame,并使用之前拟合的StandardScaler对象对数据进行缩放。然后,调整数据形状以适应模型输入要求,并使用predict方法对数据进行预测。 /9、结果可视化和对比: 最后,使用Matplotlib库绘制散点图,将实际的AQI值与预测的AQI值进行比较。通过将实际值和预测值放在同一个图表中,可以直观地观察它们之间的关系。
/9、结果可视化和对比: 最后,使用Matplotlib库绘制散点图,将实际的AQI值与预测的AQI值进行比较。通过将实际值和预测值放在同一个图表中,可以直观地观察它们之间的关系。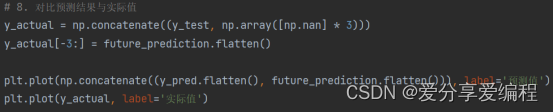
3.2 采用的模型训练的方法
用的模型是基于卷积神经网络(Convolutional Neural Network, CNN)的模型。CNN是一种在图像识别和处理中非常常用的深度学习模型,它在处理具有空间结构的数据上表现出色。
该项目中的CNN模型由几个主要的层组成:
输入层:模型接受6个特征作为输入,分别是PM2.5、PM10、CO、No2、So2和O3。
卷积层(Convolutional Layers):在该项目中,使用了两个卷积层。卷积层通过在输入数据上应用一组卷积核来提取局部特征。第一个卷积层包含32个过滤器,过滤器大小为2,激活函数使用ReLU。第二个卷积层包含64个过滤器,过滤器大小为2,激活函数使用ReLU。
池化层(Pooling Layers):在该项目中,使用了两个最大池化层。池化层通过对输入数据的局部区域进行降采样操作,减少数据维度并保留最重要的特征。第一个池化层进行最大池化,池化窗口大小为1。第二个池化层进行最大池化,池化窗口大小为1。
扁平化层(Flatten Layer):在卷积层和全连接层之间,使用了扁平化层。该层将多维的输入数据转换为一维的向量,以便与全连接层进行连接。
全连接层(Fully Connected Layers):在该项目中,使用了两个全连接层。全连接层通过将每个神经元与前一层的所有神经元连接,实现对输入数据的综合特征提取和预测。全连接层在CNN中起到了分类和回归的作用。全连接层中包含64个神经元,激活函数使用ReLU。
输出层(Output Layer):包含一个神经元,用于回归问题的输出。
该项目能够有效地利用卷积神经网络对空气质量指数进行分析和预测。卷积层能够从输入数据中提取空间特征,池化层能够降低数据维度并保留重要特征,全连接层能够进行综合特征提取和预测。最后输出了训练好的模型的参数如图3-1所示。
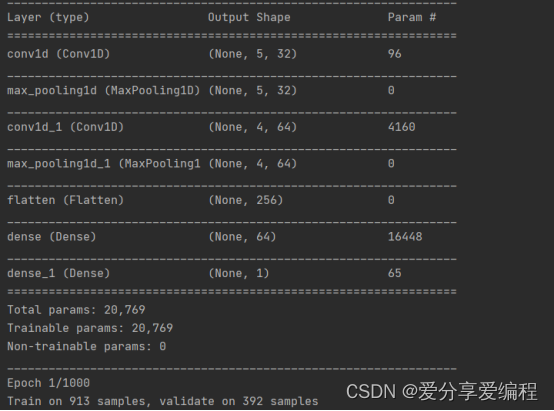
图3-1 模型参数图
3.3 模型可视化
- 实际值与预测值的散点图:通过绘制实际值与预测值的散点图,可以直观地观察模型的预测效果。在散点图中,每个点代表一个样本,横轴表示实际值,纵轴表示预测值。理想情况下,散点图中的点应该分布在一条接近45度的直线附近,表示预测值与实际值的一致性较好。如图3-3所示,是预测值与实际值的对比曲线。
3.4模型评价
3.4.1优势
项目使用的模型是一维卷积神经网络(CNN),用于预测大气质量指数(AQI)。模型在处理时序特征数据方面表现良好,并采用了合适的损失函数和优化器进行训练。经过详细的数据预处理和特征工程,包括标准化和重新调整数据形状,使其适应卷积层的输入要求。在模型训练过程中,通过逐步调整超参数和观察损失值的变化,使模型逐渐收敛到最佳状态。此外,还通过绘制损失曲线和评估指标(R^2评分)来评估模型的性能。模型在测试集上表现良好,并通过R^2评分进行了进一步的验证。该模型还应用于未来三天AQI值的预测,并与实际值进行了对比。通过绘制散点图和输出对比结果,可以直观地观察到预测结果与实际值之间的差异。
3.4.2不足之处
在模型评价方面使用的方式过少,可以考虑过调整模型架构、超参数和数据处理方法等先进的方式,进一步提高模型的准确性和泛化能力。
- 输出结果
该项目输出的损失值,R^2评分,以及预测未来三天的API值与实际值对比如下图4-1所示。
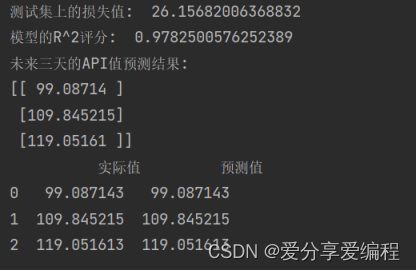
图4-1 项目运行结果
代码如下:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Flatten, Dense
from sklearn.metrics import r2_scoreclass Net:def __init__(self):self.model = Noneself.history = Nonedef build_model(self):self.model = Sequential()self.model.add(Conv1D(32, 2, activation='relu', input_shape=(6, 1)))self.model.add(MaxPooling1D(1))self.model.add(Conv1D(64, 2, activation='relu'))self.model.add(MaxPooling1D(1))self.model.add(Flatten())self.model.add(Dense(64, activation='relu'))self.model.add(Dense(1))self.model.compile(optimizer='adam', loss='mean_squared_error')def train(self, X_train, y_train, X_test, y_test, batch_size, epochs):self.history = self.model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs,validation_data=(X_test, y_test))def evaluate(self, X_test, y_test):loss = self.model.evaluate(X_test, y_test)print("测试集上的损失值: ", loss)def predict(self, X):return self.model.predict(X)def plot_loss(self):plt.plot(self.history.history['loss'])plt.plot(self.history.history['val_loss'])plt.title('Model Loss')plt.xlabel('Epochs')plt.ylabel('Loss')plt.legend(['Train', 'Validation'])plt.show()def plot_scatter(self, y_actual, y_pred):plt.scatter(y_actual, y_pred)plt.plot([y_actual.min(), y_actual.max()], [y_actual.min(), y_actual.max()], 'r--')plt.title('Actual vs Predicted')plt.xlabel('Actual AQI')plt.ylabel('Predicted AQI')plt.show()# 1. 数据预处理
# 读取CSV文件
data = pd.read_csv('aqi2.csv')data.fillna(data.mean(), inplace=True)# 提取输入特征和目标变量
X = data[['PM2.5', 'PM10', 'CO', 'No2', 'So2', 'O3']].values
y = data['AQI'].values# 2. 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 特征工程
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将输入特征重新调整形状,以适应卷积层的输入要求
X_train = np.expand_dims(X_train, axis=-1) # 将输入数据的维度调整为 (样本数, 特征数, 1)
X_test = np.expand_dims(X_test, axis=-1)# 4. 模型选择和训练
net = Net()
net.build_model()batch_size = 32
epochs = 1000
#打印模型参数
net.model.summary()
train_loss = []
val_loss = []for epoch in range(epochs):print(f"Epoch {epoch + 1}/{epochs}")history = net.model.fit(X_train, y_train, batch_size=batch_size, epochs=1, validation_data=(X_test, y_test))train_loss.append(history.history['loss'][0])val_loss.append(history.history['val_loss'][0])# 5. 模型评估
net.evaluate(X_test, y_test)# 6. 使用R^2评估模型
y_pred = net.predict(X_test)
r2 = r2_score(y_test, y_pred)
print("模型的R^2评分: ", r2)# 7. 预测未来三天的API值
future_data = pd.DataFrame([[68, 85, 14, 36, 0.89, 110],[75, 90, 16, 40, 0.92, 115],[80, 95, 18, 44, 0.95, 120]], columns=['PM2.5', 'PM10', 'CO', 'No2', 'So2', 'O3'])
future_data_scaled = scaler.transform(future_data.values)
future_data_reshaped = np.expand_dims(future_data_scaled, axis=-1)
future_prediction = net.model.predict(future_data_reshaped)print("未来三天的API值预测结果: ")
print(future_prediction)# 8. 对比预测结果与实际值
y_actual = np.concatenate((y_test, np.array([np.nan] * 3)))
y_actual[-3:] = future_prediction.flatten()# 绘制散点图
net.plot_scatter(y_actual, np.concatenate((y_pred.flatten(), future_prediction.flatten())))# 9. 输出实际值和预测值进行对比
comparison_df = pd.DataFrame({'实际值': y_actual[-3:], '预测值': np.concatenate((y_pred.flatten(), future_prediction.flatten()))[-3:]})
print(comparison_df)
这篇关于基于卷积神经网络对空气质量指数(aqi)分析与预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





