本文主要是介绍RFM模型的四种打标签方法你会几种?三十行代码教你深刻理解如何实现用户画像,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

如果想了解RFM模型的数据分析初学者去搜索,会发现无论是知乎大V还是百度都会有“清楚”的原理解释和过程实现,看懂了收藏了,但是当你自己去实际应用的时候会发现,我对着大V的文章跟着做这个看似简单的模型,为啥我用起来没效果呢?实际上不是你没学会或者没做对,而是对这个简单而又强大的细节没有理解。
这个模型是来自美国数据库营销研究所Arthur Hughes对客户数据库长期研究,他发现客户数据中有3个要素构成了数据分析最好的指标:最近一次消费 (Recency),消费频率 (Frequency),消费金额 (Monetary)。了解模型产生背景你就能知道两个重要的点,一是客户数据库;二是指标。如果你没意识到,那对于这个模型就会有下面两点没理解。
首先,对RFM模型的业务应用场景没理解。不是所有的数据都能应用这个模型,房子、车子、大家电或者耐用品,购买金额倒是高,但是购买频次能有几回?F指标是不是就失效了吧?中小超市或者线下店大部分没有数据库,收集的数据不仅不规范而且价值稀疏。所以只有大型公司或快消品或航空电信电商等具有客户频次和粘性的领域才有挖掘的价值。所以你的数据不对,自然效果不好。
第二,对指标打标签没理解。其实RFM指标很好计算,难就难在它的应用上,它同我之前讲的商品关联规则挖掘一样是偏向业务应用的,重要的是业务人员对指标标准的构建和结果的评估。这个模型是由指标构建的,自然是人为主观因素影响大。所以在计算好R、F、M后如何对结果进行打标签是直接影响模型应用效果的。常见的方式就是直接拿R、F、M与总体均值做比较,但是这是静态方法。也有人使用算法聚类结合RFM模型,但是到给类打标签的时候就一笔带过。
因此接下来,我会先讲解RFM模型的原理和过程,然后分别说明算法聚类细分、均值细分、打分细分、动态参数细分四种方式来给分类结果打标签。在下一篇文章中具体演示如何用PowerBI实现这四种方式的可视化展示。
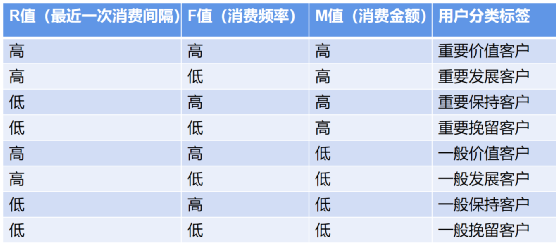
要是看过我的文章“数据分析模型,你会用多少种?建议你用这28种商业模型和方法武装自己”里列举过的RFM模型。它是通过R、F、M指标将三维空间划分为八个子空间,再对每个部分打上客户价值标签。如下图:
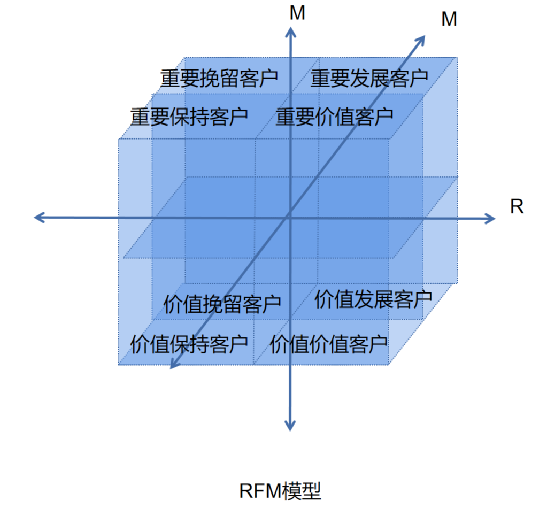
怎么实现上图的效果呢?这也是RFM模型的核心,即如何划分,如何给划分后的结果打标签。
先来看这三个指标:
R(Rencency):最近一次消费时间间隔,就是指顾客最近一次消费离现在有多久了,考察客户的黏性,R值越小的客户是粘性越高的客户。
F(Frequency):考察期内消费的频率,就是指顾客在考察期内消费了多少次数,考察客户的忠诚度,F值越高客户忠诚度越高。
M(Monetary):考察期内消费总金额,就是指顾客在考察期内消费了多少钱,考察客户的价值,金额越高客户价值越高。
明白上面这三个核心指标。接下就是实操了。这里我提供了一份数据集,有60398条记录。如果你需要可以关注同名公众号索取。它长下面这个样子:
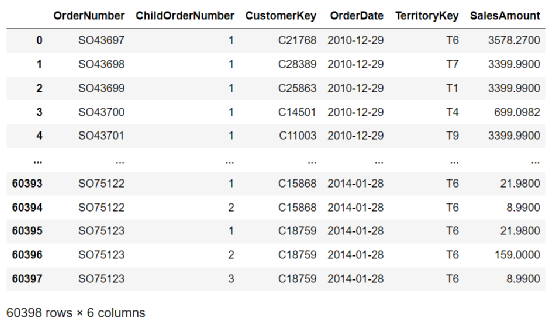
这是一份电商数据。可以看到总共有六个字段OrderNumber就是订单号;ChildOrderNumber就是子订单号,网上有很多案例都是处理好的只有三个字段的演示,实际上工作中真实数据需要很多处理,这里有子单号表名计算的时候还不能直接算RFM指标,需要进行根据订单号分组聚类的处理;CustomerKey是顾客ID;OrderDate是下单日期;TerritoryKey指顾客所属地理区域;SalesAmount指消费金额。
第一步,计算RFM值。下面的代码均为Python代码。
#导入计算库和数据集
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_excel(r"D:\InternetOrders.xlsx")
#因为每个订单有多行,所以需要先根据CustomerKey,OrderDate,OrderNumber分组对金额进行求和汇总,得到每个顾客每天购买总金额。这样数据中就没有重复数据。
df_uniqueorder = df.groupby(["CustomerKey","OrderDate","OrderNumber"]).agg({'SalesAmount':'sum'}).reset_index()
df_uniqueorder.head(5)
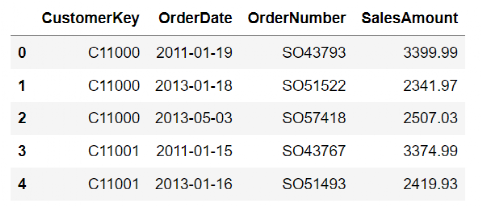
通过pandas的groupby功能同时计算R、F、M指标。
df_rfm = df_uniqueorder.groupby("CustomerKey").agg({'OrderDate':'max','CustomerKey':'count','SalesAmount':'sum'})
df_rfm = df_rfm.rename(columns ={'OrderDate':'Recentdate','CustomerKey':'F','SalesAmount':'M'})
这段代码意思是以顾客ID为分组依据,分别对订单日期求最大值(日期最大不就是最近的消费日期吗?)、对顾客ID进行计数(对顾客出现次数计数不就是消费频次吗?虽然上面说考察期,但往往使用的时候都是把自顾客第一次消费到考察日期内所有订单都算在内,所以可以直接对所有订单计数)、对消费金额求和(这个好理解,就是看顾客总的消费金额)。这样不就轻轻松松把三个指标都算出来了。然后通过rename函数对计算后的指标重命名。
不过这里还有一个问题。虽然找出了最近的消费日期,但是R指的是最近日期离考察日期的间隔。考察日期我定为“2014-02-28”,因为所有订单最近日期是“2014-01-28”,电商用户一个月购买一次是合理的。所以还需加一步计算R值。
df_rfm["R"] = pd.to_datetime("2014-02-28") - df_rfm["Recentdate"]
df_rfm["R"] = df_rfm["R"].astype('str').str.split(" ",expand=True)
df_rfm["R"] = df_rfm["R"].astype("int")
df_rfm.drop(columns='Recentdate',inplace=True)
上面代码先是计算每个订单日期与"2014-02-28"差值,也就是R值;因为pandas计算日期差后会带上日期单位,类似“103 days"的格式,而且是日期格式,所以这里通过str转换成字符串,再分割提取数字,再把格式转换为整数,最后再把原来的日期列去掉。我们就计算好了全部指标。
还有一个问题是,实际应用中我们不仅想知道哪个客户是什么类型客户,可能也想知道哪个地区的客户类型都是什么(这是实际应用场景中经常出现的),所以这里把上面这张表计算过程中丢掉的地理区域再连接回来。方便我们后续使用。
Terrority = df[["CustomerKey","TerritoryKey"]].groupby("CustomerKey").agg("max").reset_index()
RFM = df_rfm.merge(Terrority,on="CustomerKey",how="left")
最终得到了全部数据如下。
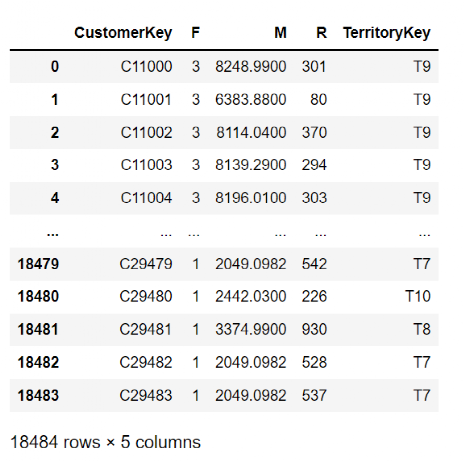
第二步,对R、F、M指标划分,打上标签。重点来了,如何打标签呢?下面有四种方法。
第一种,均值RFM模型
这是你最常看到的打标签方式,将每个用户的R、F、M值同总体均值进行比较,比均值高的就为“高”,低的就标明“低”,然后通过三个指标的高低来打标签。像下面这样。
具体的就是通过下面代码实现。
#把RFM表原始数据复制一份,因为后面其他方法也要使用,避免混淆
RFM_Average = RFM.copy()
#对每个指标与总体均值进行高低判断
RFM_Average["IFR"] = RFM_Average["R"].apply(lambda x: "高" if x > RFM_Average["R"].mean() else "低")
RFM_Average["IFF"] = RFM_Average["F"].apply(lambda x: "高" if x > RFM_Average["F"].mean() else "低")
RFM_Average["IFM"] = RFM_Average["M"].apply(lambda x: "高" if x > RFM_Average["M"].mean() else "低")
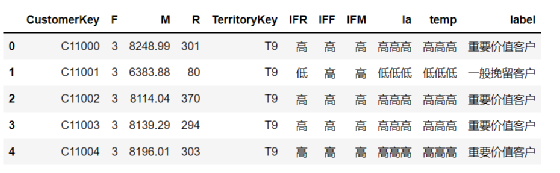
RFM_Average.head(5)

下面再做最后的处理。
#下面这个函数对每个顾客的综合指标进行判断
def iflabel(x):if x == "高高高":return "重要价值客户"elif x == "高低高":return "重要发展客户"elif x == "高高低":return "一般价值客户"elif x == "高低低":return "一般发展客户"elif x == "低高高":return "重要保持客户"elif x == "低低高":return "重要挽留客户"elif x == "低高低":return "一般保持客户"elif x == "低低低":return "一般挽留客户"
#将三个指标合并起来,生成临时列temp,表示RFM综合指标
RFM_Average["temp"] = RFM_Average["IFR"] +RFM_Average["IFR"]+RFM_Average["IFR"]
#对综合指标判断
RFM_Average["label"] = RFM_Average["temp"].apply(lambda x: iflabel(x))
RFM_Average.head(5)
看!RFM模型计算就完成啦!
然而,实际应用中不止使用均值作为判断标准。还有的只有聚类的方式。
第二种方法,聚类RFM模型
聚类RFM模型,具体的步骤是先用聚类的算法(这里用K-均值聚类法)对指标进行聚类,得到m类客户(这里我选择分8类);再将每类客户的R、F、M平均值和总R、F、M平均值作比较,大于(等于)平均值为“高”、小于平均值为“低”;最后对这m类的R、F、M高低综合判断用户属于什么类型客户,打上标签。下面就是使用机器学习库Sklearn中的KMeans算法包实现的聚类代码。
#把RFM表原始数据复制一份,因为后面其他方法也要使用,避免混淆
RFM_Cluster = RFM.copy()
#获取DataFrame格式的RFM中R、F、M三列数据的值,因为该算法接收的是数组
Cluster = RFM[["R","F","M"]].values #调用KMeans包,指定聚为8类,对数据开始聚类
kmeans = KMeans(n_clusters=8, random_state=0).fit(Cluster) #聚类好之后把获得的类标签传递给原表
RFM_Cluster["label"] = kmeans.labels_
RFM_Cluster.head()
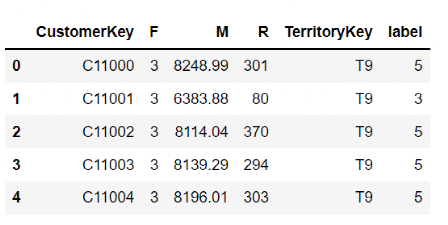
上面就是聚类算法得到的8个类别,分别于1-8数值表示。但是这样不知道哪个类别是高价值客户哪个类别是一般客户。也没法直接像第一种方法那样比较。所以这里的处理是分组取平均值,再把每一类平均值同总体均值作比较。
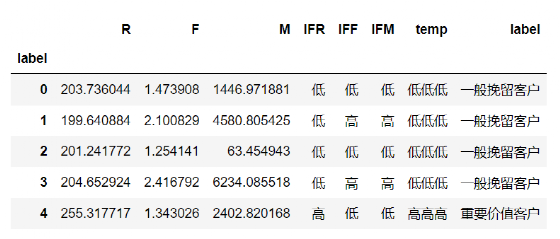
#先求每一类的R、F、M均值
RFM_Cluster8 = RFM_Cluster[["label","R","F","M"]].groupby("label").agg("mean")#再将每一类的R、F、M均值于总体作比较
RFM_Cluster8["IFR"] = RFM_Cluster8["R"].apply(lambda x: "高" if x > RFM_Cluster8["R"].mean() else "低")
RFM_Cluster8["IFF"] = RFM_Cluster8["F"].apply(lambda x: "高" if x > RFM_Cluster8["F"].mean() else "低")
RFM_Cluster8["IFM"] = RFM_Cluster8["M"].apply(lambda x: "高" if x > RFM_Cluster8["M"].mean() else "低")#方法和上面一样,#将三个指标合并起来,生成临时列temp,表示RFM综合指标
RFM_Cluster8["temp"] = RFM_Cluster8["IFR"] +RFM_Cluster8["IFR"]+RFM_Cluster8["IFR"]
RFM_Cluster8["label"] = RFM_Cluster8["temp"].apply(lambda x: iflabel(x))
RFM_Cluster8.head()
最后再与原表连接得到顾客ID等信息。最终又得到顾客标签啦!
RFM_Cluster = RFM_Cluster.merge(RFM_Cluster8,on="label",how="left")
RFM_Cluster = RFM_Cluster[["CustomerKey","F","M","R","TerritoryKey","label","IFR","IFF","IFM","temp","标签"]]
RFM_Cluster
第三种方法,打分均值RFM
这种就比较麻烦一点。需要对对每个顾客的每个指标进行分段打分,分值为1-5,间隔越近、频率越高、金额越大,分值就越大,客户价值就越好。具体打分规则如下:
R、F、M每个分数等级为5分
对R打分:
5分:60天以内
4分:60天到90天
3分:90天到120天
2分:120天到150天
1分:150天以上
对F打分:
5分:10单以上
4分:7到10单
3分:3到7单
2分:1到3单
1分:1单
对M打分:
5分:5000元以上
4分:5000元
3分:2000元
2分:1000元
1分:500元
这里的分段标准实际上是根据业务人员自己定的,实际取什么段最好还可以再结合业务定。对应的写了三个函数判断规则。
def Rscre(x):if x <=60:return 5elif x <=90:return 4elif x <=120:return 3elif x <=150:return 2else:return 1
def Fscre(x):if x >=10:return 5elif x >=7:return 4elif x >=3:return 3elif x >1:return 2else:return 1
def Mscre(x):if x >=5000:return 5elif x >=2000:return 4elif x >=1000:return 3elif x >500:return 2else:return 1
#应用上面的函数进行打分
RFM_Score["R1"] = RFM_Score["R"].apply(lambda x: Rscre(x))
RFM_Score["F1"] = RFM_Score["F"].apply(lambda x: Fscre(x))
RFM_Score["M1"] = RFM_Score["M"].apply(lambda x: Mscre(x))
RFM_Score.head(5)
最后再一次进行判断,方法和上面一样。
RFM_Score["IFR"] = RFM_Score["R1"].apply(lambda x: "高" if x > RFM_Score["R1"].mean() else "低")
RFM_Score["IFF"] = RFM_Score["F1"].apply(lambda x: "高" if x > RFM_Score["F1"].mean() else "低")
RFM_Score["IFM"] = RFM_Score["M1"].apply(lambda x: "高" if x > RFM_Score["M1"].mean() else "低")
RFM_Score["temp"] = RFM_Score["IFR"] +RFM_Score["IFR"]+RFM_Score["IFR"]
RFM_Score["label"] = RFM_Score["temp"].apply(lambda x: iflabel(x))
RFM_Score.head()
又一次得到了顾客分类标签。
第四种方法,动态参数RFM
实际上这种方式的计算过程跟均值RFM一样。但是不同的是,在这里不用均值作为划分高低的标准,而是由业务人员在对R、F、M指标解释的时候根据经验确定划分标准就像打分均值RFM一样,打分的标准也是主观判断的。这样实际比只有算法计算出来的静态结果更加有效。
通过PowerBI或Tableau等BI工具就可以实现这样效果,在Python中暂时无法实现直观的实时的动态参数可视化。
以上就是RFM模型全部四种打标签的方法了。需要注意的是这四种方法得到的用户分类标签是不一样的哦。如果需要完整代码,请公众号私戳我。
最后欢迎大家关注我,我是拾陆,搜索公众号“二八Data”,更多技术干货持续奉献。


这篇关于RFM模型的四种打标签方法你会几种?三十行代码教你深刻理解如何实现用户画像的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







