本文主要是介绍08MARL深度强化学习 independent learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 1、Independent Value-based Learning
- 2、Independent Policy Gradient Methods
前言
记录independent learning算法的基础概念,使用一些RL算法训练多智能体
1、Independent Value-based Learning
基于值的独立学习算法:每个智能体根据自身的观测与动作学习价值函数,以IDQN为例,每个智能体根据自身的观测历史学习Q函数,智能体i的损失函数为:
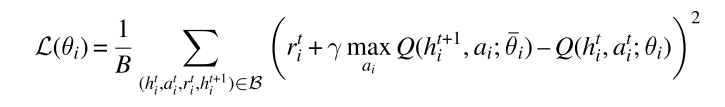
总的损失函数就是将所有智能体的损失函数进行求和,优化过程为最小化总损失函数与每个智能体的损失函数

**replay buffer局限:**代表经验收集与再采样的过程,而在IDQN中存在一定问题,因为在多智能体环境中,每个智能体不仅被他们自身的观测与动作所决定,同时受到其他智能体的影响,因此每个智能体的观测与动作会依赖于其他智能体的策略,当采用经验回收池时,假设了经验随着时间具有相关性,而在多智能体环境中,这种相关性会快速过时
**举例解释:**在两个智能体学习围棋的任务中,智能体1采取了特定的策略,短期有较好的收益而长期属于弱策略,智能体2没有采用特定的策略,在刚开始的阶段智能体1会获得奖励而在经验池中存放数据,而随着时间的进行,这些数据在后期并不能带来收益,导致智能体1会持续学习弱策略
解决方法:
小的经验回收池:小的经验回收池使得快速达到容量,因此会移除老的数据,能够降低回收池中经验过时的问题
重要性采样权重(Importance Sampling Weights):经验池储存策略与经验,通过重要性采样的权重校正选择动作的概率
fingerprints of agent policies:拓展每个智能体的观测,使得智能体能够考虑其他智能体的策略的变化
2、Independent Policy Gradient Methods
独立策略梯度方法:通过智能体自身的动作以及奖励计算梯度,并不考虑其他智能体的动作与策略,计算期望回报相对于自身策略的梯度,每个episode通过以下公式更新: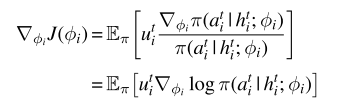
算法流程如下:

在多智能体环境设定中,on policy相比于off policy具有一定的优势,是因为on policy能够学习最新的经验得到策略,这样智能体会随着其他的智能体策略的改变而得到新的经验,能够不断适应变化的环境,因此在多智能体环境设定中,on policy算法能够持续更新,更加重要
A2C算法:
具有并行环境的A2C算法能够应用到多智能体环境当中,多智能体在多个并行环境当中经过多轮episode具有更高维度的观测,并且动作与奖励等都具有更高的维度,算法流程如下

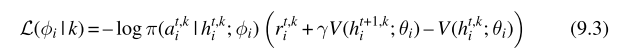
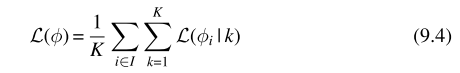
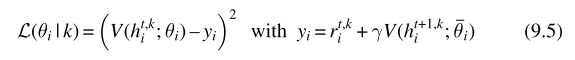
这篇关于08MARL深度强化学习 independent learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





