本文主要是介绍数据分析案例-2023年TOP100国外电影数据可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.导入数据
5.数据可视化
文末推荐与福利
1.项目背景
随着全球化的深入发展,电影作为一种文化表达和艺术形式,逐渐超越了国界,成为世界各地观众共同欣赏的对象。2023年TOP100国外电影榜单的发布,正是这一发展趋势的体现。为了更好地理解这一现象,我们决定对这100部电影进行数据可视化分析,以期揭示其背后的文化、市场和艺术特征。
近年来,电影产业的数字化和网络化带来了海量的数据资源,这为我们的研究提供了可能。通过数据挖掘和分析,我们可以了解哪些类型的电影更受欢迎,哪些地区或国家的电影在全球范围内有更大的影响力,以及观众的喜好和行为模式等。
电影不仅仅是一种娱乐方式,它还是一个反映社会现象、传达价值观和塑造文化认同的重要工具。通过研究TOP100国外电影,我们可以深入了解不同文化背景下的故事、主题和表达方式,从而增进国际间的文化交流和理解。
此外,电影市场的竞争也日益激烈。通过数据可视化,我们可以分析电影的票房、口碑和影响力之间的关系,为电影产业的决策者提供有价值的参考信息,以促进电影产业的健康和可持续发展。
总之,2023年TOP100国外电影数据可视化研究旨在利用现代数据分析技术,深入挖掘电影数据的价值,理解电影作为一种全球性文化的现象,增进国际文化交流,并为电影产业的未来发展提供决策支持。
2.数据集介绍
数据集来源与Kaggle,原始数据集为2023年国外最佳的前100部电影数据,共有如下变量:
| 列名 | 描述 |
|---|---|
| name | 电影的标题。 |
| rating | 给电影的评级。 |
| votes | 电影获得的票数。 |
| runtime | 电影的持续时间或运行时间。 |
| genre | 电影所属的流派。 |
| description | 电影的简要概述或描述。 |
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
导入第三方库和数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import warnings
warnings.filterwarnings('ignore')
sns.set_style('darkgrid')
plt.style.use('ggplot')df = pd.read_csv('moviesdataset_2023.csv')
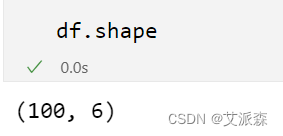
df.head()查看数据大小
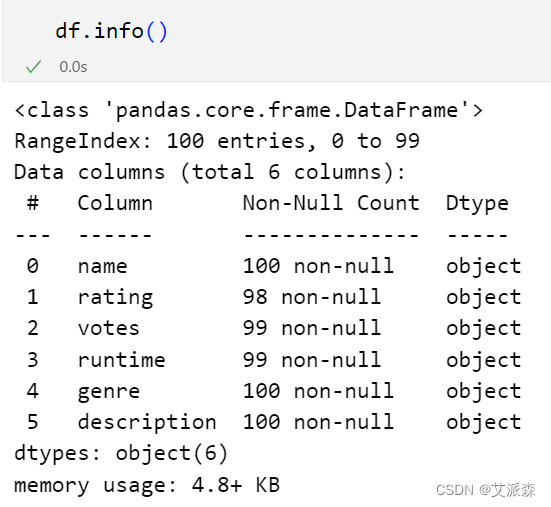
查看数据基本信息
# 数据类型转换
df['rating'] = pd.to_numeric(df['rating'], errors='coerce')
df['votes'] = pd.to_numeric(df['votes'].str.replace(',', ''), errors='coerce')
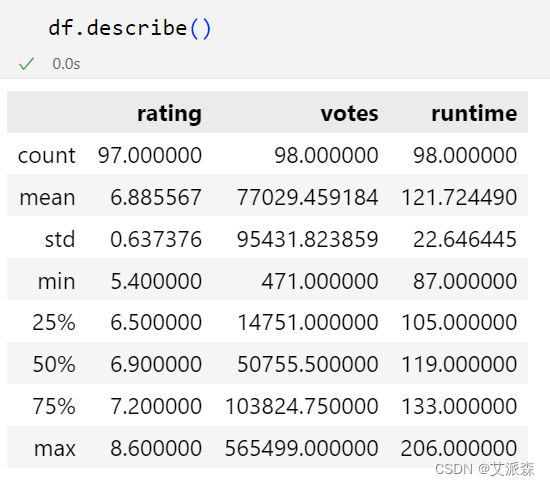
df['runtime'] = pd.to_numeric(df['runtime'].str.replace(' min', ''), errors='coerce')查看描述性统计
5.数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 6))
sns.histplot(df['rating'].dropna(), bins=10, kde=True, color='skyblue')
plt.title('Distribution of Ratings')
plt.xlabel('Rating')
plt.ylabel('Frequency')
plt.show()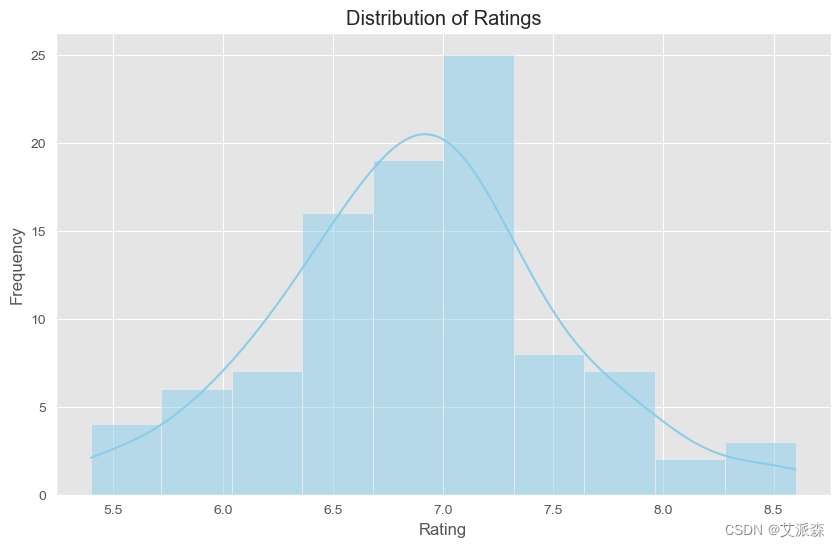
plt.figure(figsize=(10, 6))
sns.scatterplot(x='rating', y='votes', data=df, color='coral')
plt.title('Relationship between Rating and Votes')
plt.xlabel('Rating')
plt.ylabel('Votes')
plt.show()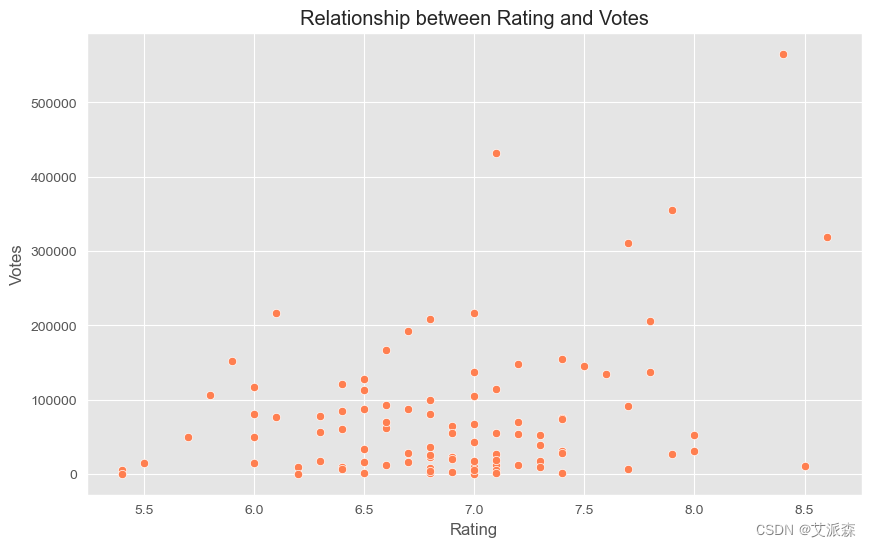
genres_count = df['genre'].explode().value_counts()
plt.figure(figsize=(12, 8))
genres_count.plot(kind='bar', color='salmon')
plt.title('Movie Genres Count')
plt.xlabel('Genres')
plt.ylabel('Count')
plt.xticks(rotation=45, ha='right')
plt.show()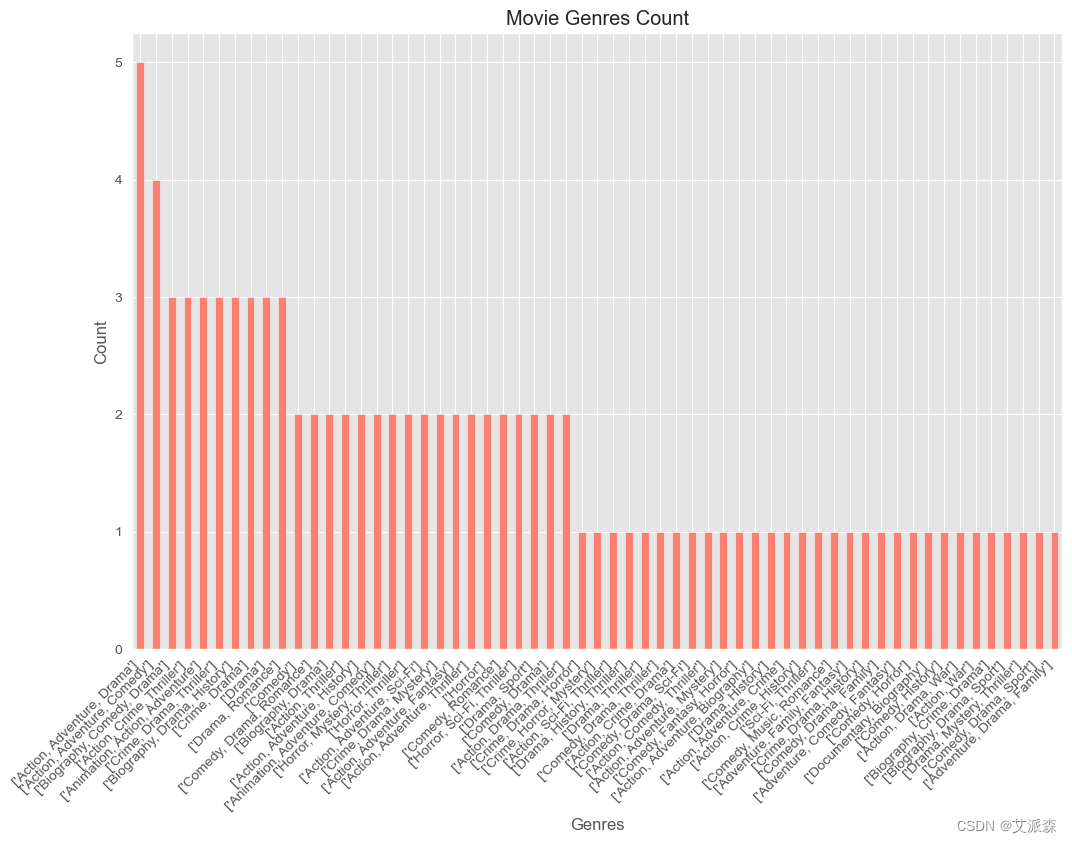
plt.figure(figsize=(10, 6))
sns.histplot(df['runtime'].dropna(), bins=15, kde=True, color='lightgreen')
plt.title('Distribution of Runtime')
plt.xlabel('Runtime (minutes)')
plt.ylabel('Frequency')
plt.show()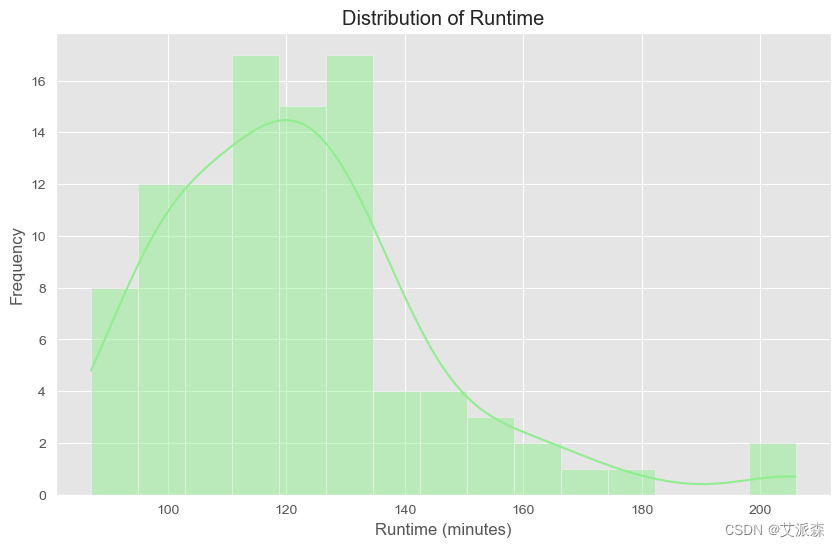
plt.figure(figsize=(12, 8))
sns.pairplot(df[['rating', 'votes', 'runtime']])
plt.suptitle('Pair Plot for Numerical Columns', y=1.02)
plt.show()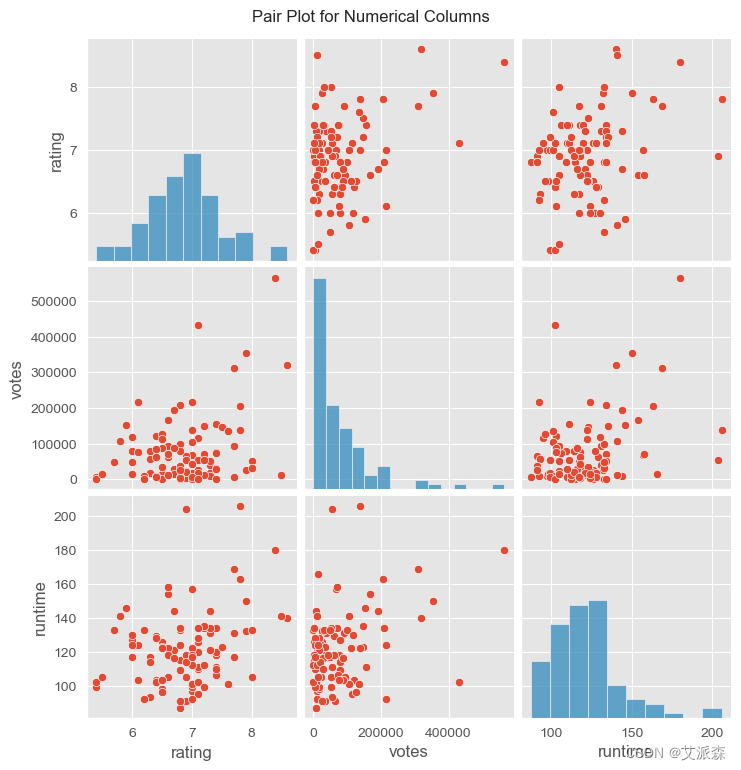
plt.figure(figsize=(14, 8))
sns.countplot(y='genre', data=df, order=df['genre'].explode().value_counts().index, palette='viridis')
plt.title('Count of Movies in Each Genre')
plt.xlabel('Count')
plt.ylabel('Genres')
plt.show()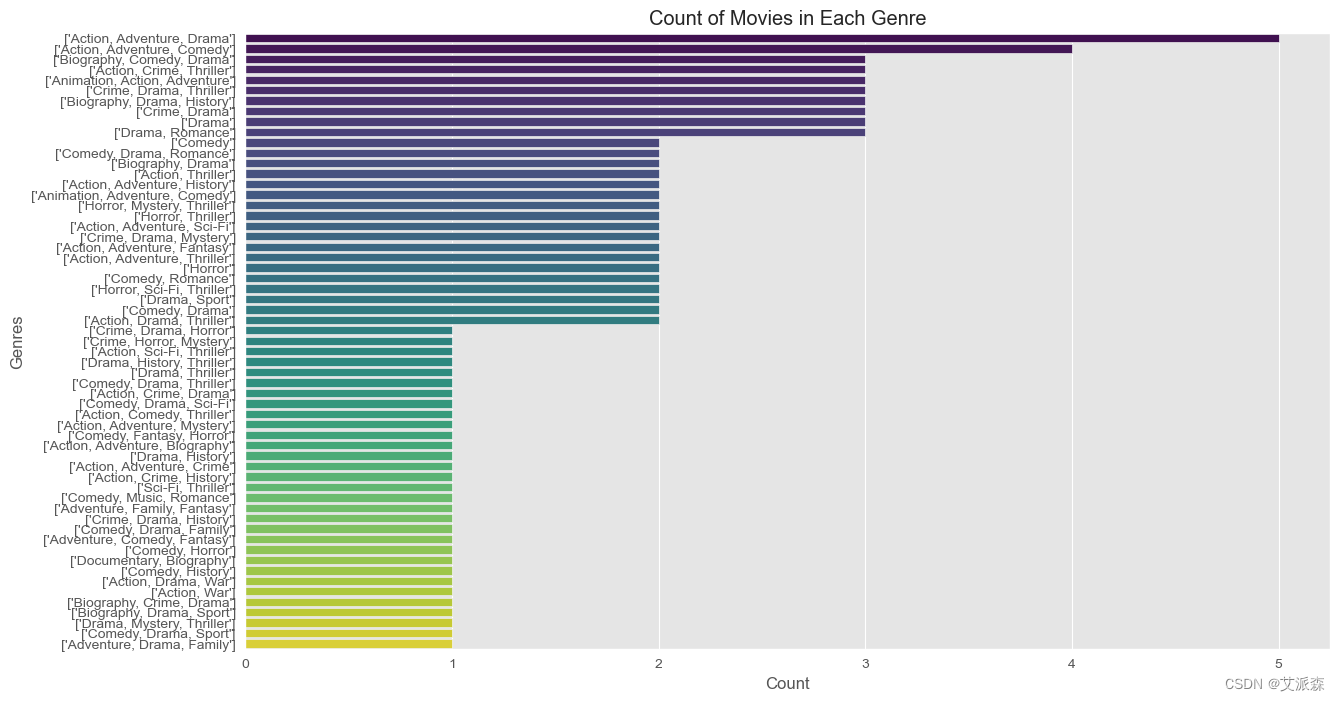
# 相关系数热力图
plt.figure(figsize=(10, 8))
correlation_matrix = df[['rating', 'votes', 'runtime']].corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', linewidths=.5)
plt.title('Correlation Heatmap')
plt.show()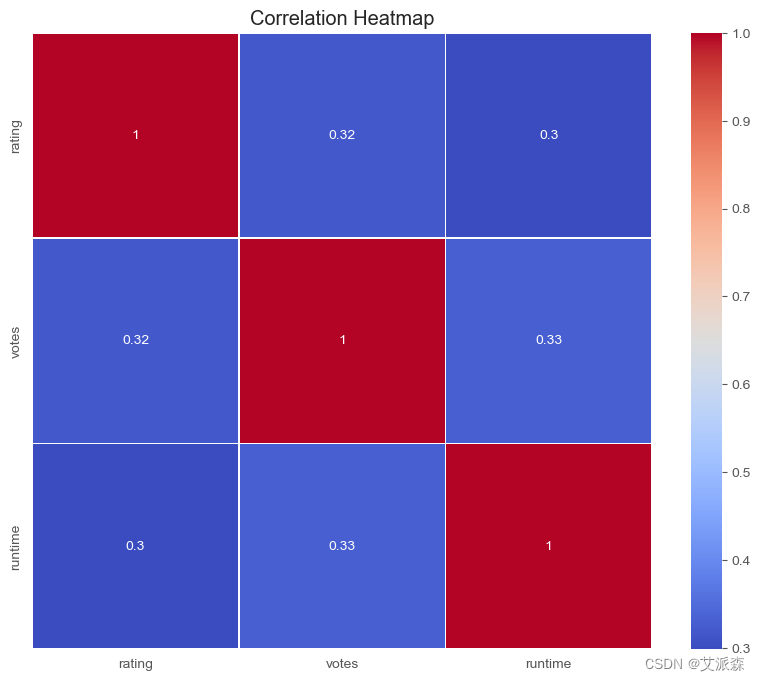
plt.figure(figsize=(14, 8))
sns.boxplot(x='runtime', y='genre', data=df, palette='Set2')
plt.title('Box Plot of Runtime Across Genres')
plt.xlabel('Runtime (minutes)')
plt.ylabel('Genres')
plt.show()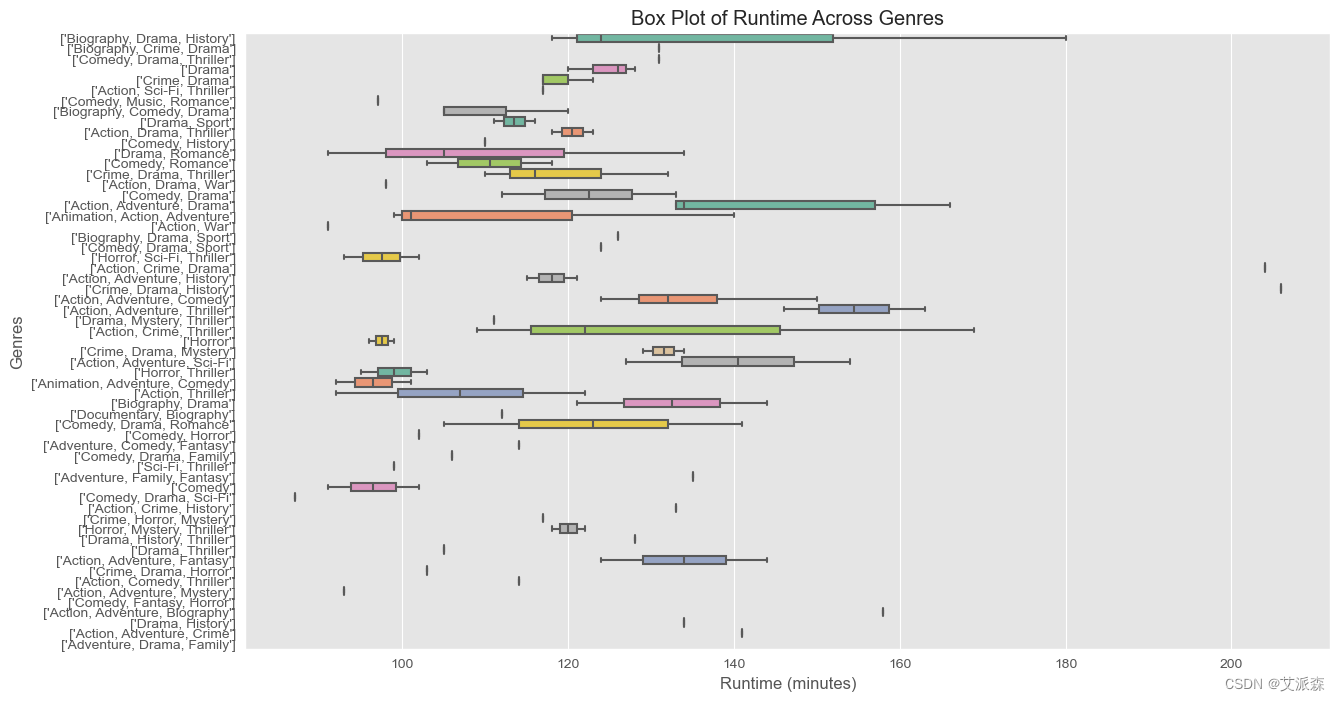
# 电影描述词云图
from wordcloud import WordCloud
# 将所有描述组合成一个字符串
all_descriptions = ' '.join(df['description'])
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(all_descriptions)
plt.figure(figsize=(12, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Word Cloud for Movie Descriptions')
plt.show()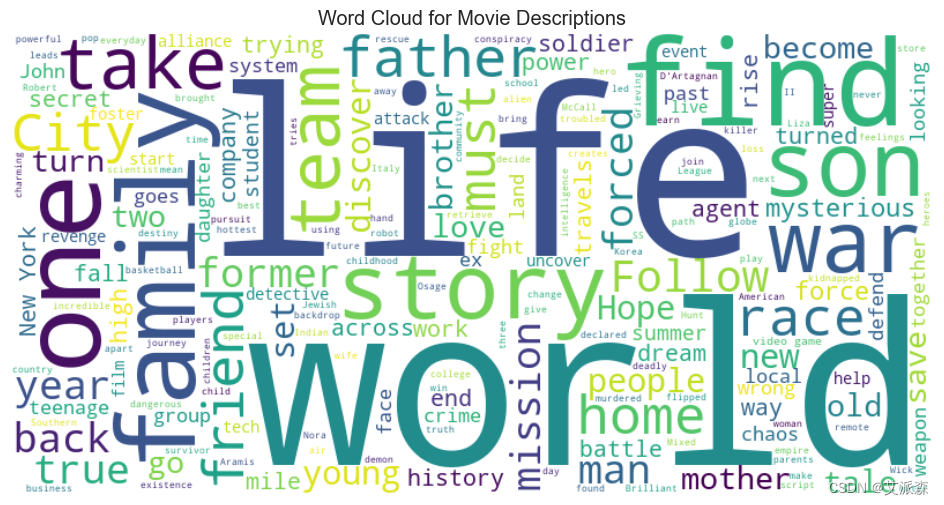
average_rating_by_genre = df.groupby('genre')['rating'].mean().sort_values(ascending=False)
plt.figure(figsize=(14, 8))
sns.barplot(x=average_rating_by_genre.values, y=average_rating_by_genre.index, palette='coolwarm')
plt.title('Average Rating Across Genres')
plt.xlabel('Average Rating')
plt.ylabel('Genres')
plt.show()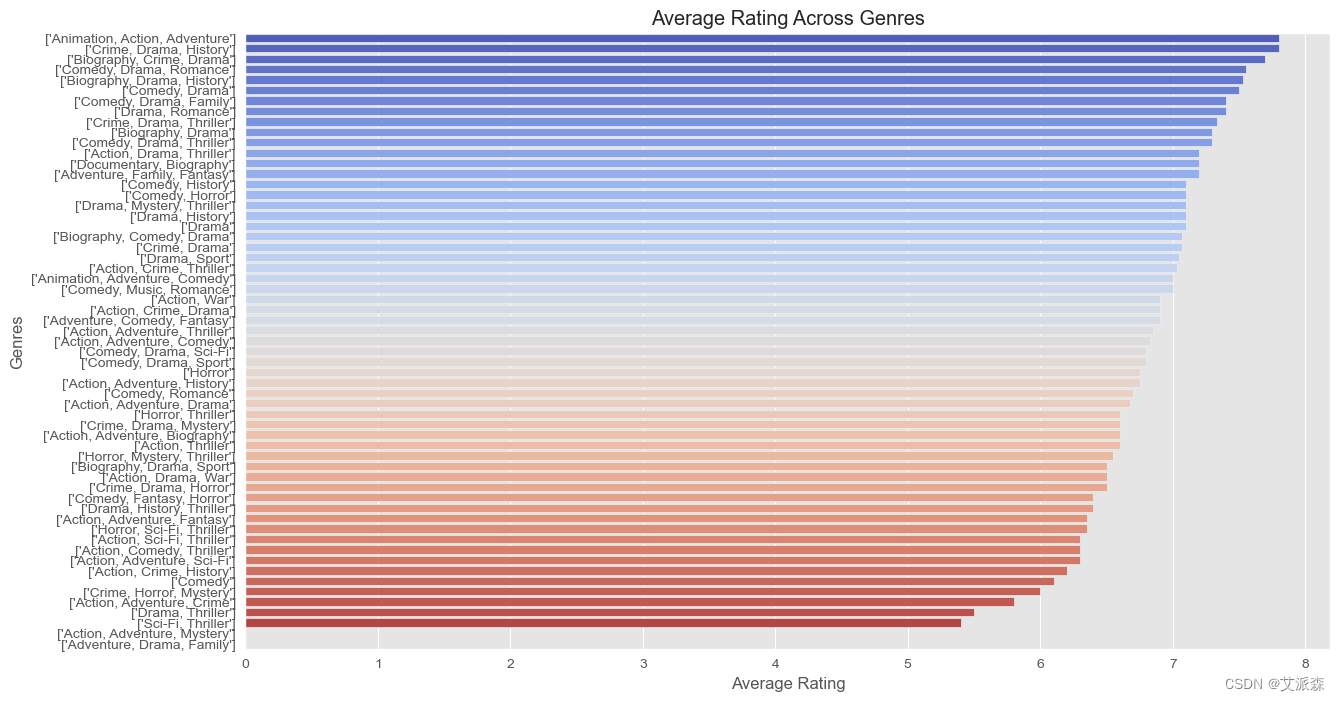
文末推荐与福利
《Excel函数与公式应用大全》免费包邮送出3本!

内容简介:
本书以 Excel 2021 为蓝本,全面系统地介绍了 Excel 365 & Excel 2021 函数与公式的技术原理、应用技巧与实战案例。内容包括函数与公式基础,文本处理、查找引用、统计求和、Web 类函数、宏表函数、自定义函数、数据库函数等常用函数的应用,以及数组公式、动态数组、多维引用等。
本书采用循序渐进的方式,由易到难地介绍各个知识点,适合各个水平的 Excel 用户,既可作为初学者的入门指南,又可作为中、高级用户的参考手册。
编辑推荐:
经典:Excel Home团队策划,多位微软全球MVP通力打造。
升级:上一版长期雄踞Excel函数类图书销量前列,《Excel 2019函数与公式应用大全》重磅升级版。
全面:详尽而又系统地介绍了Excel函数与公式的核心技术。
实战 精选Excel Home的海量案例,零距离接触Excel专家级使用方法。
深入:对一些常常困扰学习者的功能深入揭示背后的原理,让读者知其然,还能知其所以然。
揭秘:独家讲授Excel多项绝密应用,披露Excel专家多年研究成果!
资源:提供视频教学资源及书中相关案例文件,供读者参考练习、快速上手。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2024-2-23 20:00:00
当当:http://product.dangdang.com/29678919.html
京东:https://item.jd.com/14360776.html
名单公布时间:2024-2-23 21:00:00
资料获取,更多粉丝福利,关注下方公众号获取

这篇关于数据分析案例-2023年TOP100国外电影数据可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




