本文主要是介绍垃圾分类模型训练部署教程,基于MaixHub和MaixPy-k210,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
时间:2023-2-1
-
本文是图文演示内容,将给大家介绍 ,在MaixHub上训练模型,然后部署到Maix duino开发板上的流程。我这里用于演示的是垃圾分类任务,大家也可以按照该流程训练自己想要的模型。
-
通过MaixHub的迁移学习,在Maix-1系列开发板上部署一些简单的模型会很方便。
相比之下,自己使用其它平台训练的模型,例如tensorflow,在模型转换和适配的过程中很容易在一些奇怪的问题上卡住,如果没有比较深入的相关知识,可能比较难解决。(比如我之前就失败了) -
我也整理了一些资源链接,包括数据集、软件工具下载地址、技术参考文档、交流群。
在过程中遇到一些问题卡住,也挺正常,那就努力解决它们叭!
个人主页:清风莫追的主页
2024-1-25:
有些惊讶读到这篇文章的还挺多。之前说欢迎大家私聊交流,期间有不少小伙伴私信我问板子的一些问题,我答不上来,“交流”就变成了四处抱歉了,哈哈。
一晃一年过去,相关知识都忘得差不多了,仍希望这篇文章可以给茫然阶段的小伙伴带来一些参考,但遇到问题时,官方文档可能比我好用。
文章目录
- 我的准备
- 开始干活
- 在MaixHub训练模型
- 1、上传数据集
- 2、创建训练任务,进行训练
- 3、下载训练好的模型
- 在开发板上运行模型
- 1、烧录模型文件到板子
- 2、通过IDE运行模型
- 3、上传main.py文件到板子(直接板上运行)
- 结束
我的准备
- Maix duino开发板一块(含摄像头配件)
- Type-c数据集一根
- 垃圾的图片数据集
- 分四类垃圾:厨余垃圾、有害垃圾、可回收垃圾、其它垃圾。每类垃圾分一个文件夹,文件夹中就是该类垃圾的图片。
- MaixPy IDE(软件)
- 编辑用来调用模型的代码
- kflash_gui(软件)
- 将模型文件烧录(下载)到开发板上
数据集:有许多地方可以下载,例如:
- 中文生活垃圾分类数据集-modelscope
- 百度飞桨-AIStudio
软件工具:
- kflash_gui:下载教程,下载地址-github
- MaixPy IDE:MaixPy安装教程
参考文档:
- MaixPy参考文档
- 了解MaixPy建议阅读其中的”入门必看指南“;或者,在你遇到问题时可以在该文档中进行搜索,大部分可以找到。
MaxPy交流群:
- 群号:696014576
好的,接下来让我们开始叭。
开始干活
在MaixHub训练模型
首先,让我们在浏览器打开MaixHub的网站:MaixHub,任务分为三步:
- 上传数据集
- 创建训练任务,进行训练
- 下载训练好的模型
1、上传数据集
打开MaixHub网站后,点击模型训练
然后创建一个新的数据集
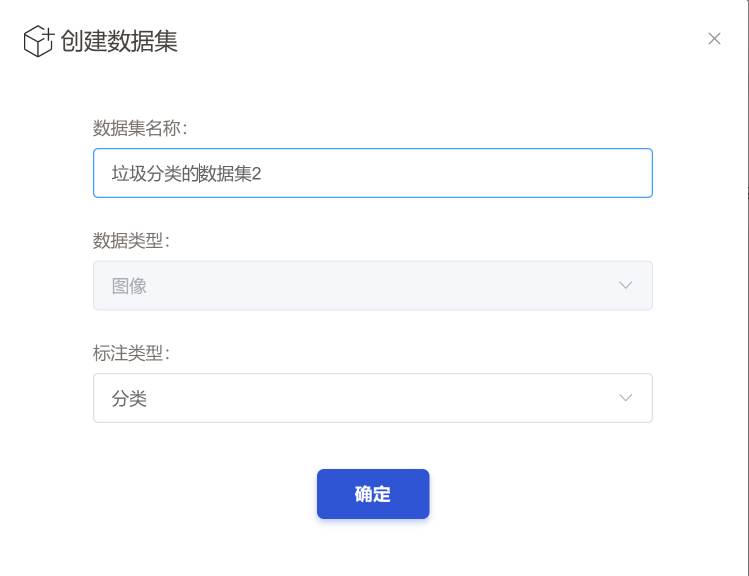
为数据集起个朴素的名字,选择标注类型
- 分类:判断一张图片的类别。
- 检测:比分类更进一步,从图片找到特定物体,得到物体的位置(坐标)和类别
这里我们选择的是分类;检测任务的训练数据标注会比较麻烦。
然后点击进入我们刚刚创建的数据集,现在它里面还什么都没有
接着添加标签,依次输入添加本次任务中所有的标签。
- 我这里是把垃圾分成四类,所以标签有food、harmful、other、recyclable,分别代表厨余垃圾、有害垃圾 、其它垃圾、可回收垃圾。
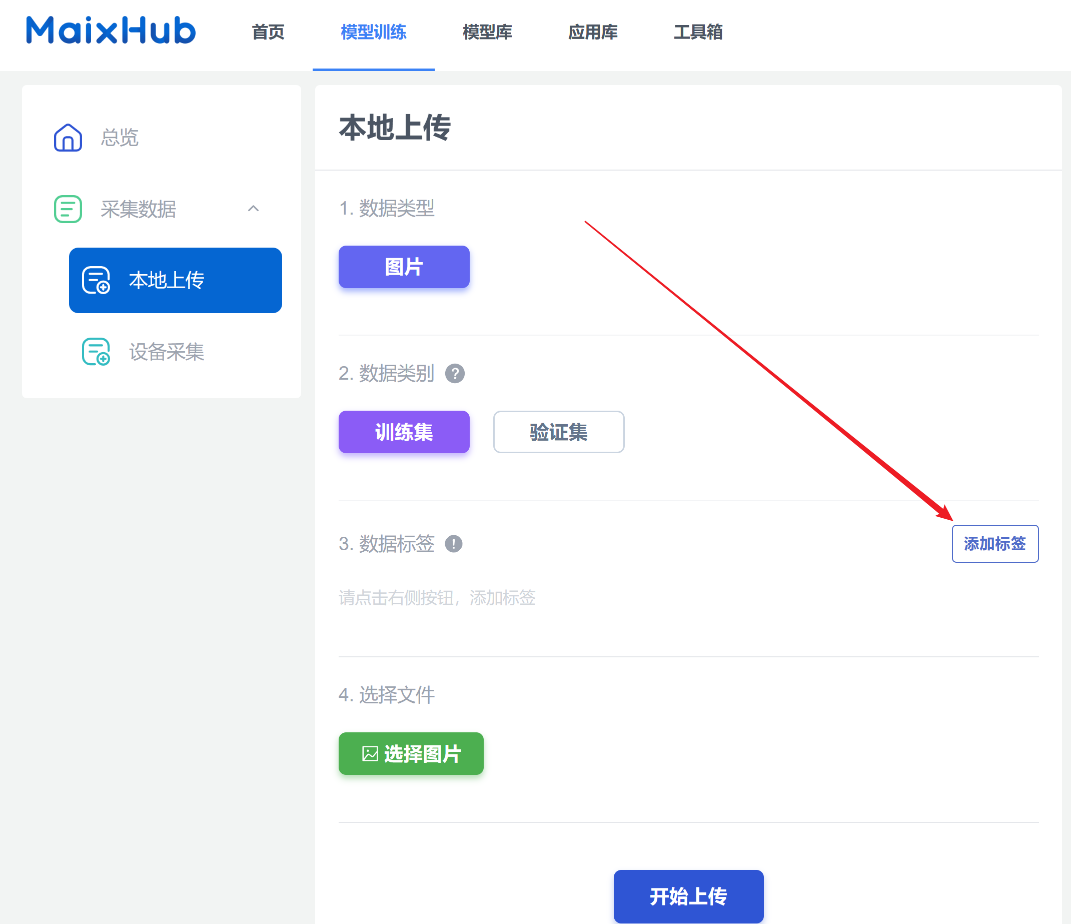
然后点击一个标签,比如food,接着选择图片,以上传类别为food的图片。
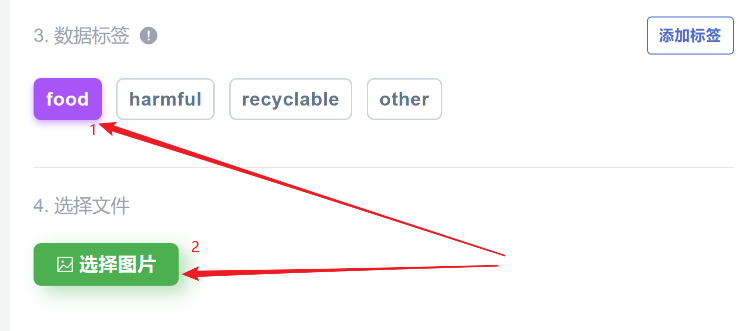
选中所有food类别的图片,然后点击打开,就可以批量一次性上传所有该类别的图片。

图片会要加载小一会儿,加载完成后开始上传。
一定要点击“开始上传”!仅仅加载完是没有用的。
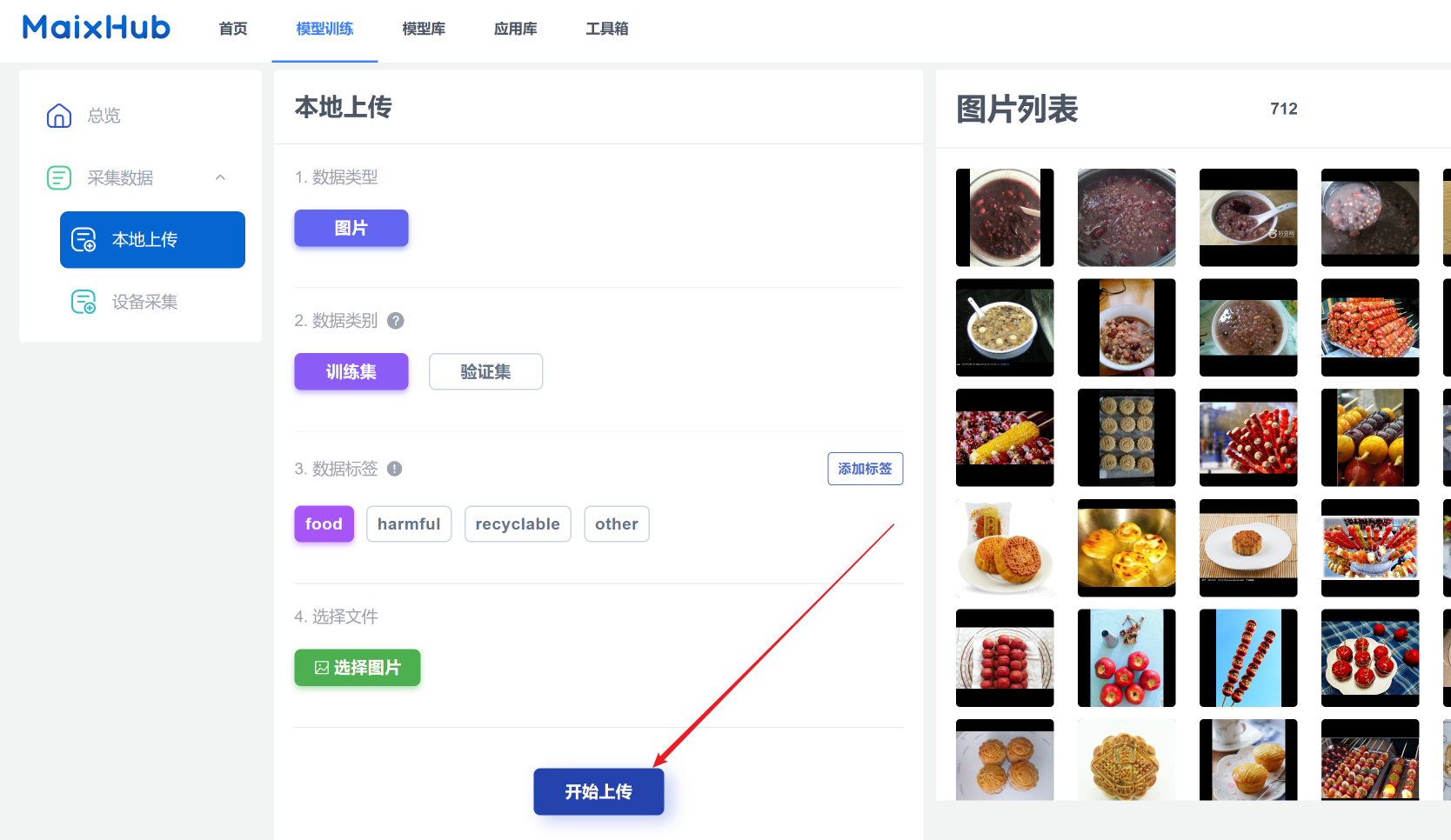
至此,我们就已经成功上传了其中一个类别的图片啦!按照上面的方式,我们可以继续上传其余每个类别的图片。
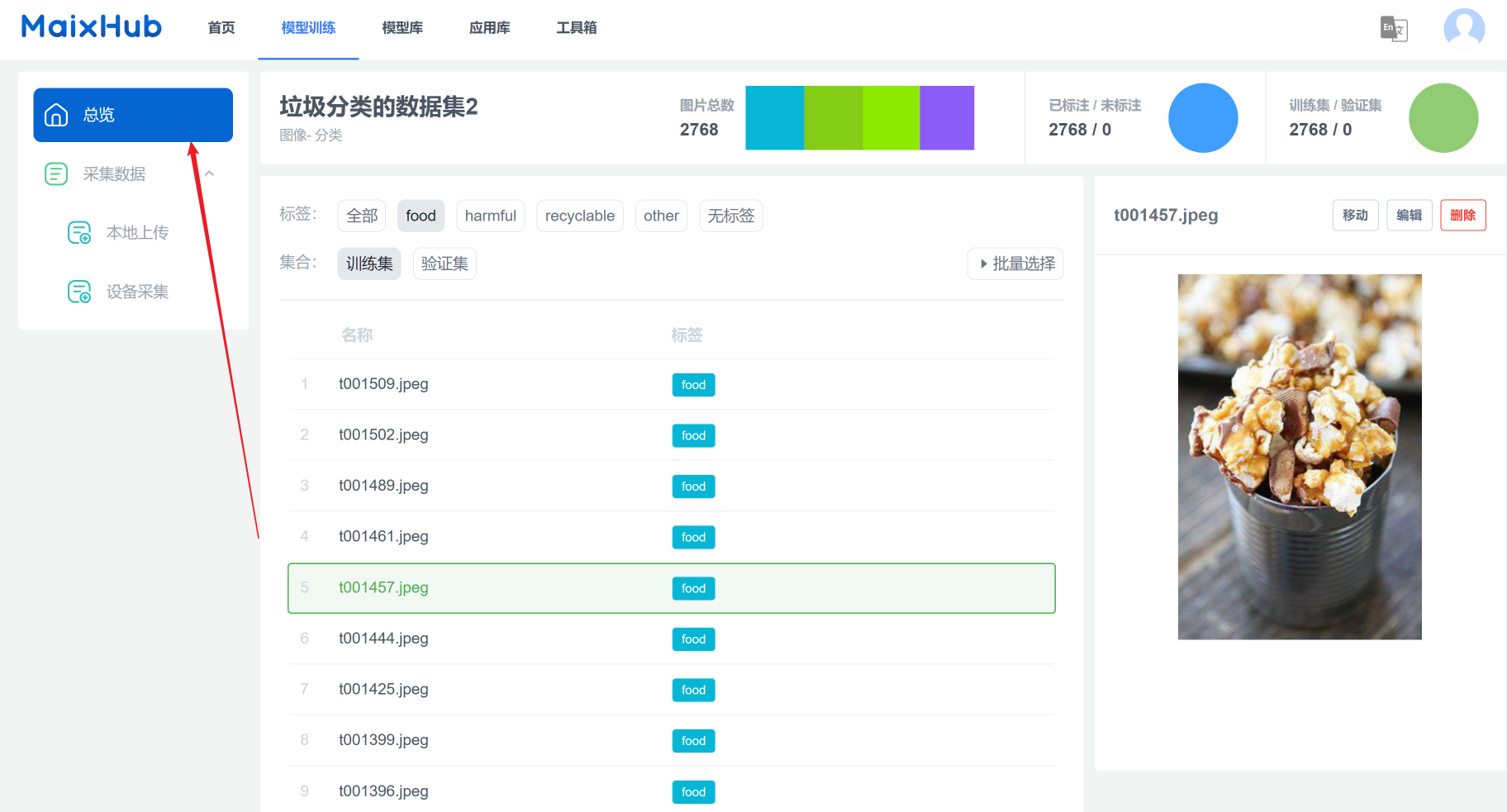
上传完所有类别的图片后,来到总览,可以大致浏览我们刚刚上传的图片。
接下来,就要用这些图片来训练用于垃圾分类的模型了!
2、创建训练任务,进行训练
前面我们已经上传好了模型训练所需要的数据,接下来的任务就是用这些数据来训练一个模型。
来到模型训练,项目,我们创建一个新项目。
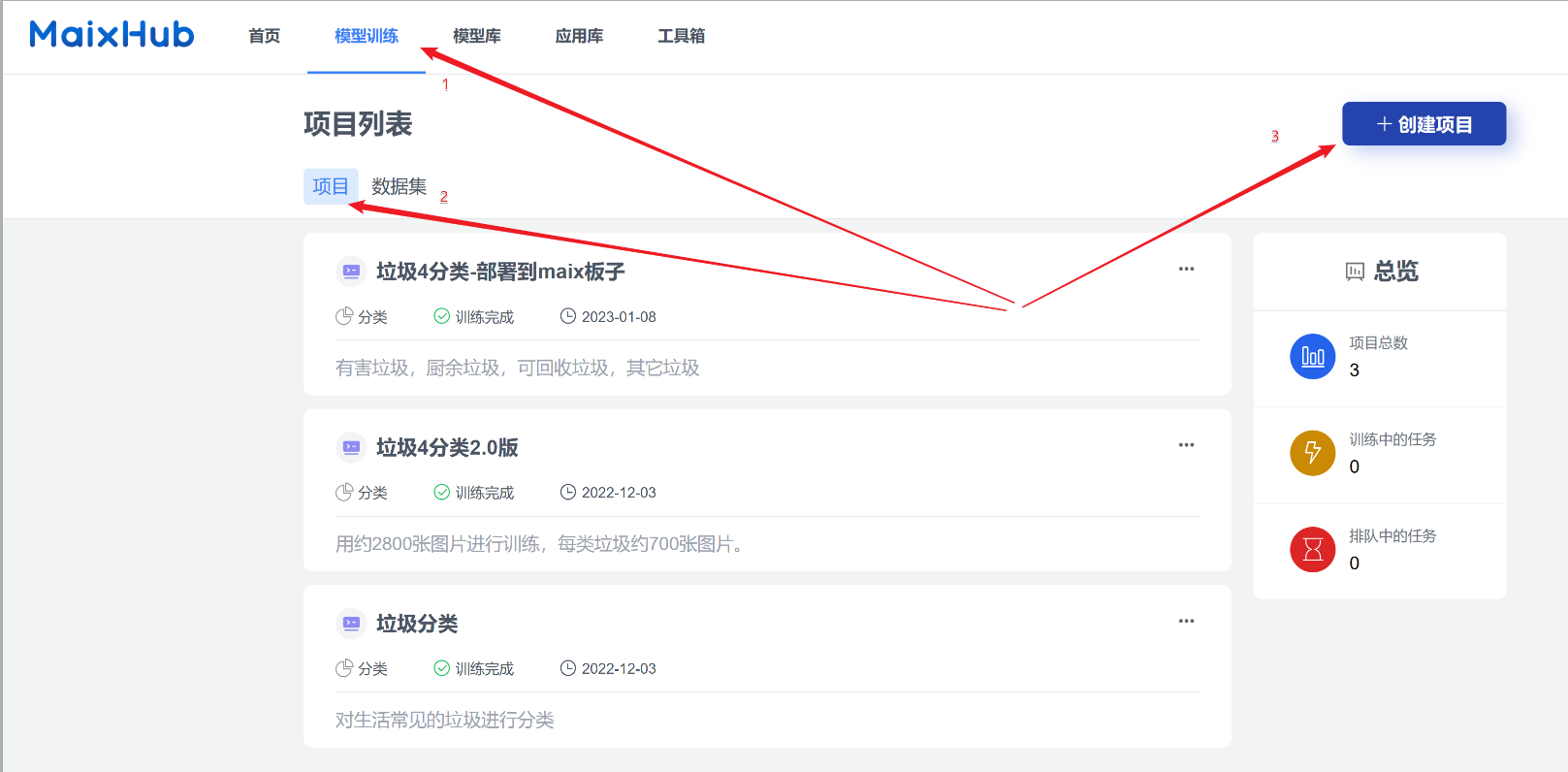
填写项目信息。
- 名称:随便编个
- 项目类型:需要与我们创建数据集时的类型保持一致,这里我选择图像分类
- 项目描述:给自己看的,随便写写。
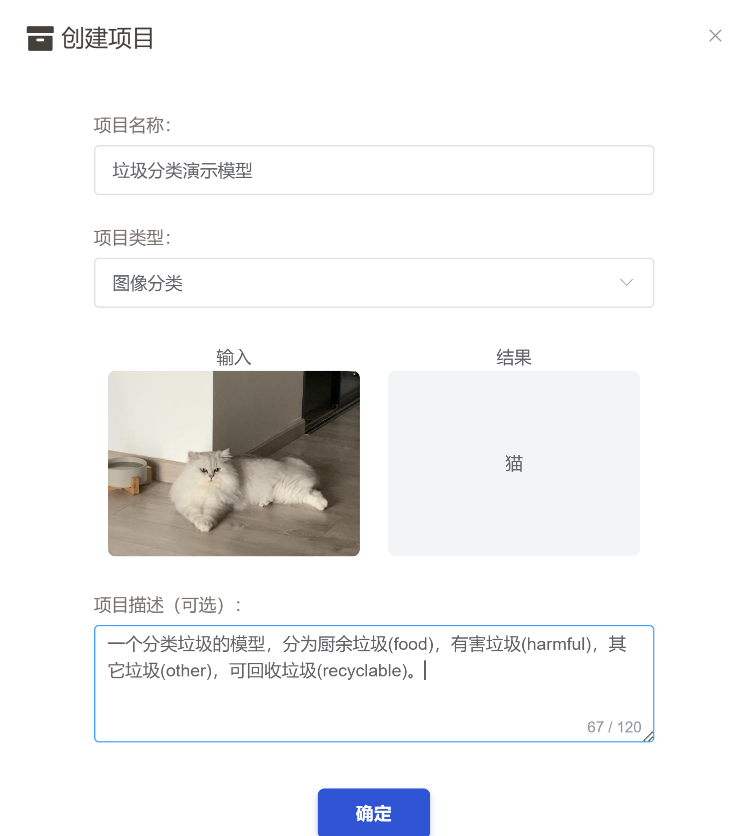
创建完成后我们就会进入这个项目,选择我们刚刚上传的数据集。
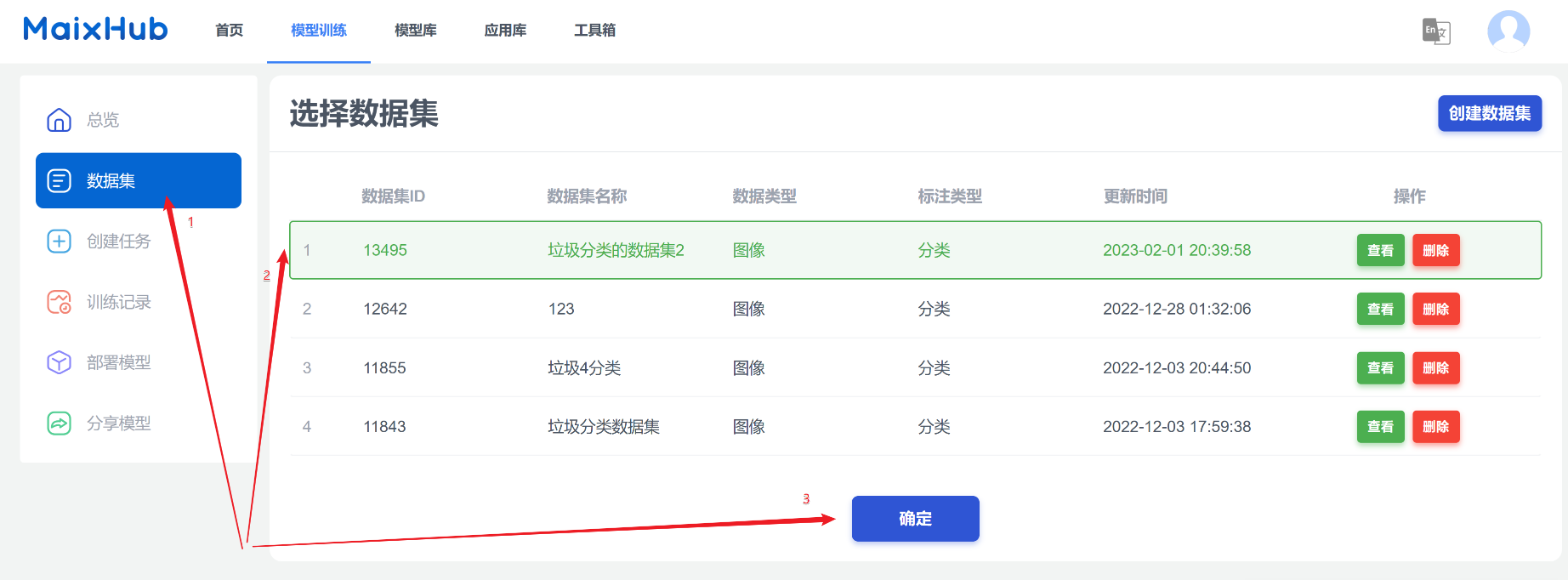
下一步是训练配置。配置通常很重要,但我们大部分使用默认的就行,深入了解这些配置的意义可能需要学习一些深度学习方面的知识。
- 随机处理:可以全勾上;增强你的模型抗环境条件干扰的能力。
- 部署平台:根据你的开发板来选就好,你可以在MaixPy的文档了解到一些板子相关的信息。
- 如果选择tfjs,你的模型将可以很方便地在手机或电脑的浏览器中运行,体验模型的效果。
- 数据均衡:如果你上传数据集中,不同类别之间的图片数量差距比较大,就需要开。像我每类都是700张左右,不开也没关系。
然后滑到网页最下面,点击创建训练任务。

小小地等待一会儿,就可以看到它开始训练啦!
训练可能会花费10来分钟的时间(与训练配置中的迭代次数成正比)。即使你关闭网页,MaixHub的后台仍然会继续帮你完成训练,你可以在训练记录查看你正在训练、或已经训练好的模型。
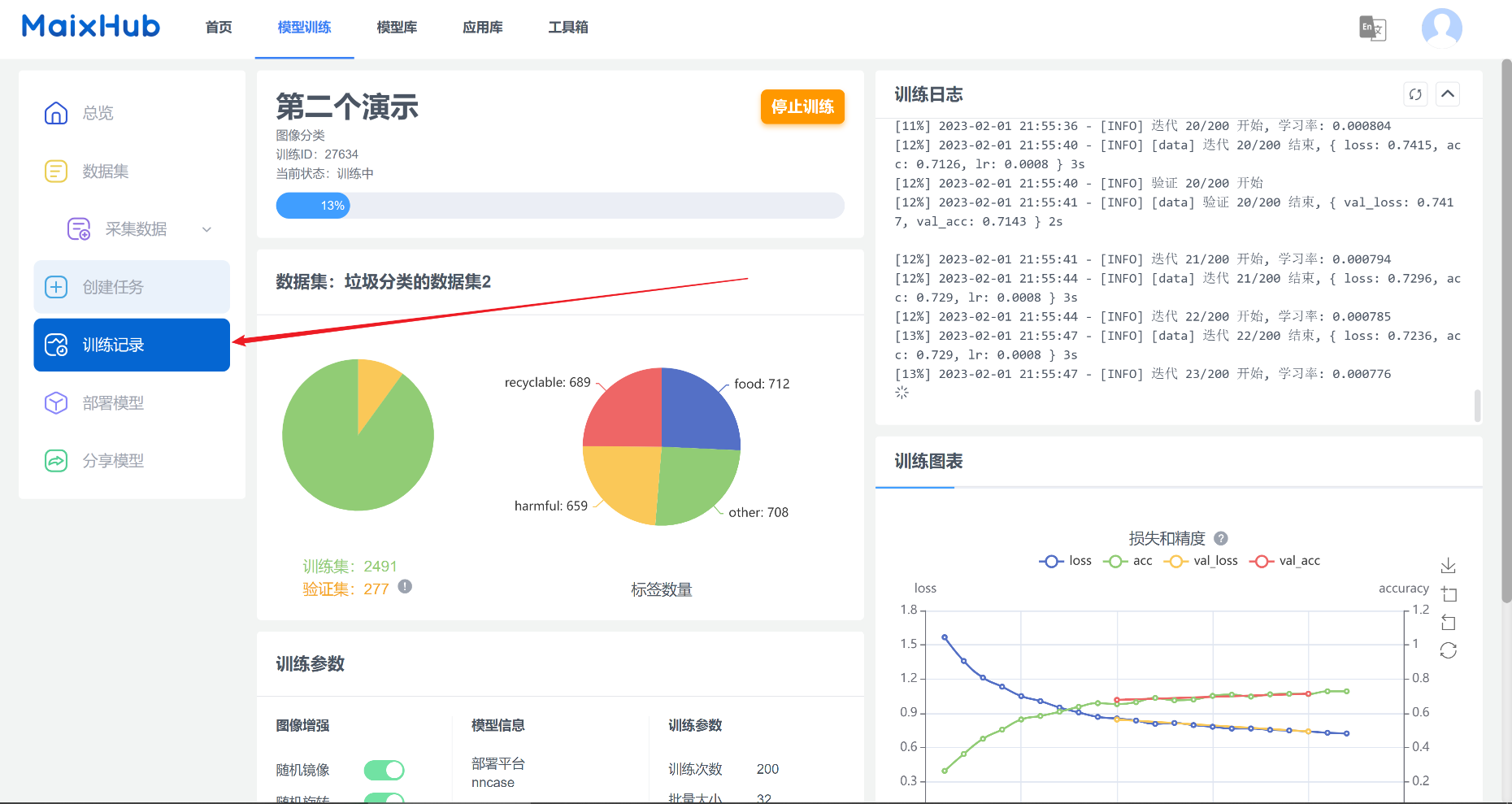
3、下载训练好的模型
将模型下载到电脑本地,为上板做准备。
在训练记录,点击部署。
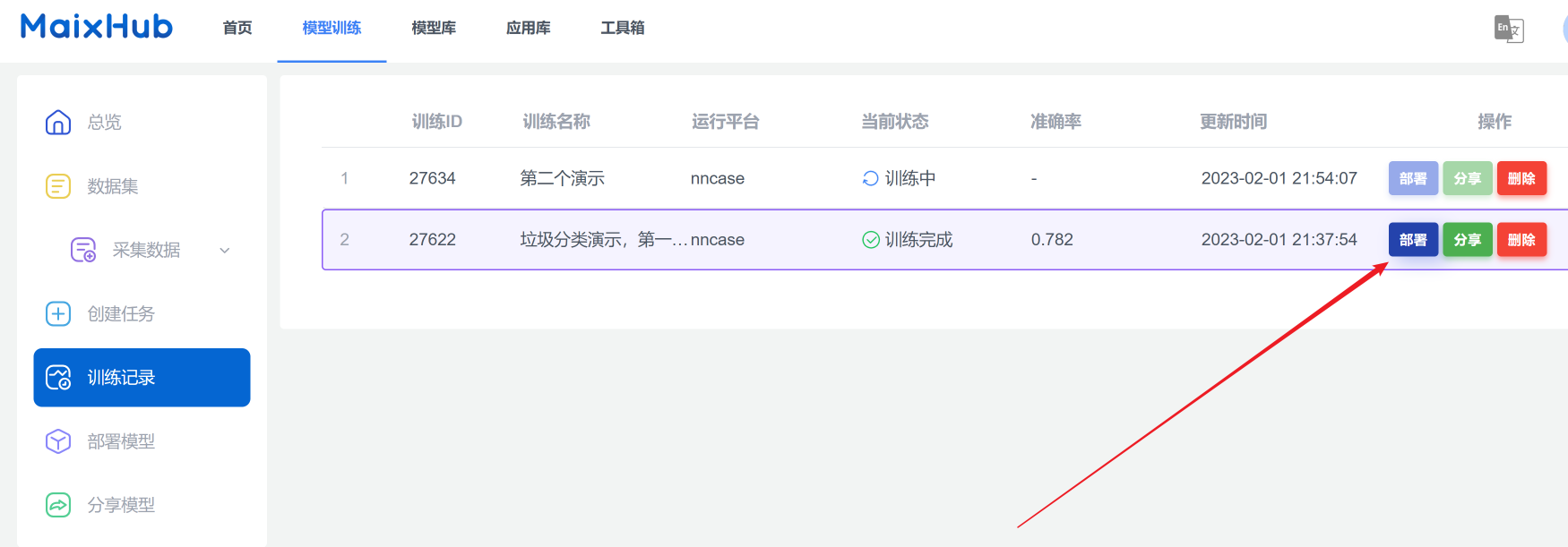
选择手动部署,然后下载模型。
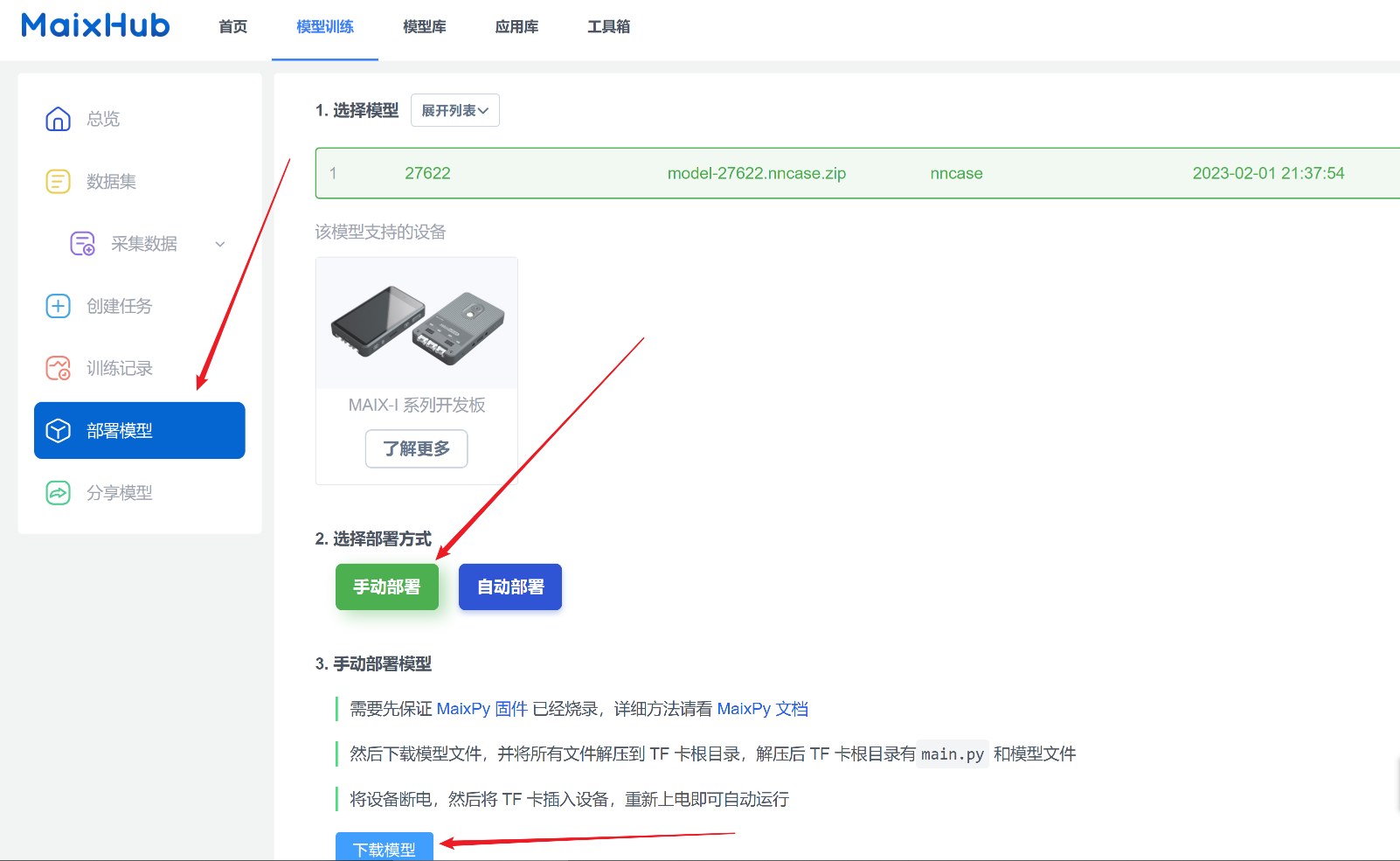
解压下载得到的压缩包,里面包含如下文件:
- main.py:python代码文件,执行它调用模型,MaixHub自动生成。也可以自己写。
- *.kmodel:模型文件。
- report.json:没什么用,训练过程中的一些记录。
我们需要的是下图中
main.py和model-27622.kmodel这两个文件。

在开发板上运行模型
1、烧录模型文件到板子
使用kflash_gui工具,可以完成这个任务。
- 参考:下载教程,下载地址-github
打开kflash_gui,使用Type-c数据线连接开发板和电脑,然后将
.kmodel文件烧录到板子上。我板子上留给模型的烧录地址是0x300000。
- 烧录到小于这个值的地址,可能会覆盖掉固件。问题也不大,重新刷固件就好(下载固件,然后用kflash_gui烧录到
0x000000地址)。
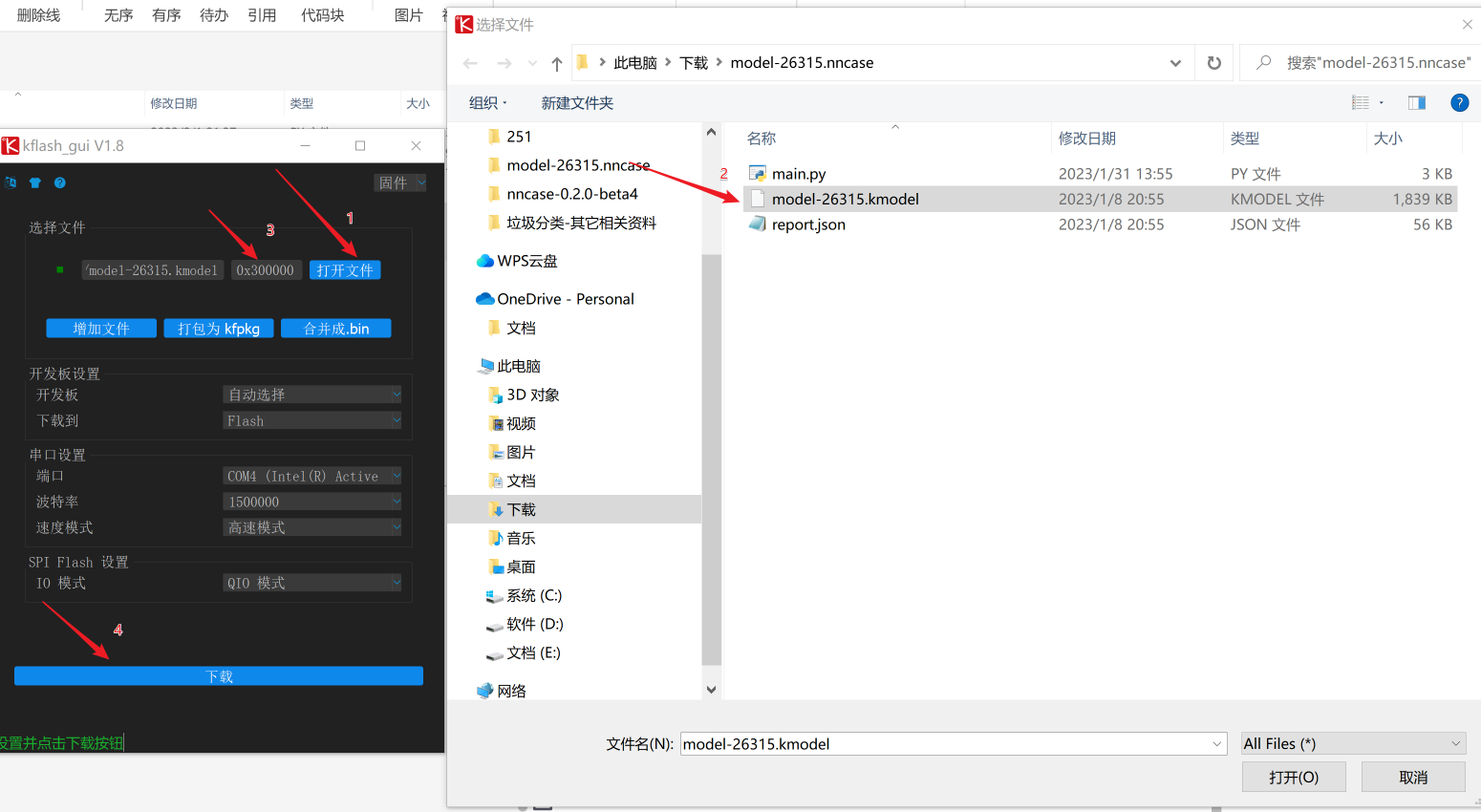
将.kmodel模型文件上传到板子上后,运行模型可以有两种方式:
- 通过MaixPy IDE中运行,需要板子连接电脑使用IDE
- 直接在板子上运行,给板子通电就可以
2、通过IDE运行模型
我们将使用MaxiPy IDE工具完成这个任务。
- 参考:MaixPy安装教程
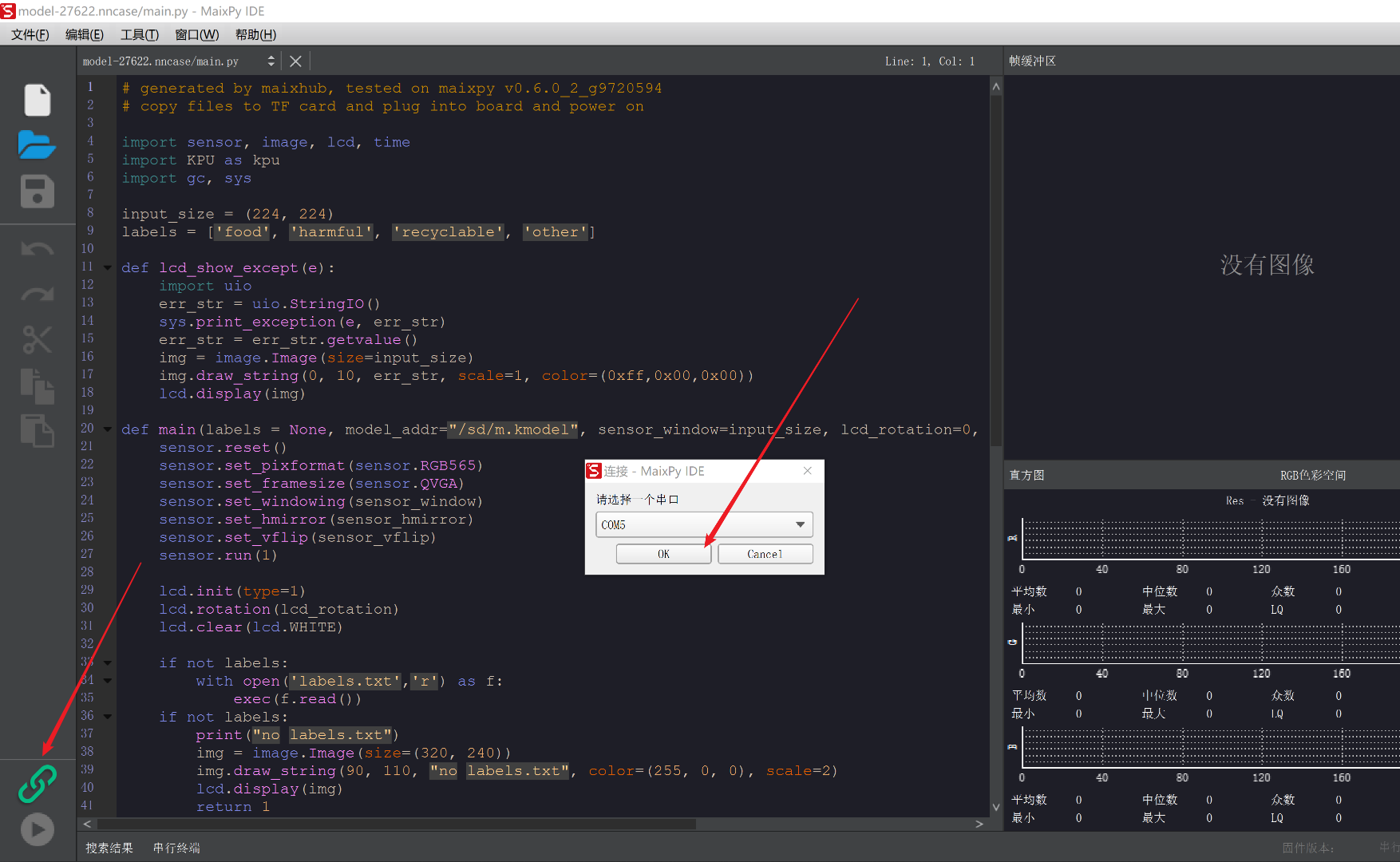
打开MaixPy IDE,保证板子连着电脑,然后在IDE中点击左下角的连接按钮(绿色),选择串口,连接成功后按钮会由绿色变成红色。
- 选择串口:如果不知道选哪个,就都试试叭。
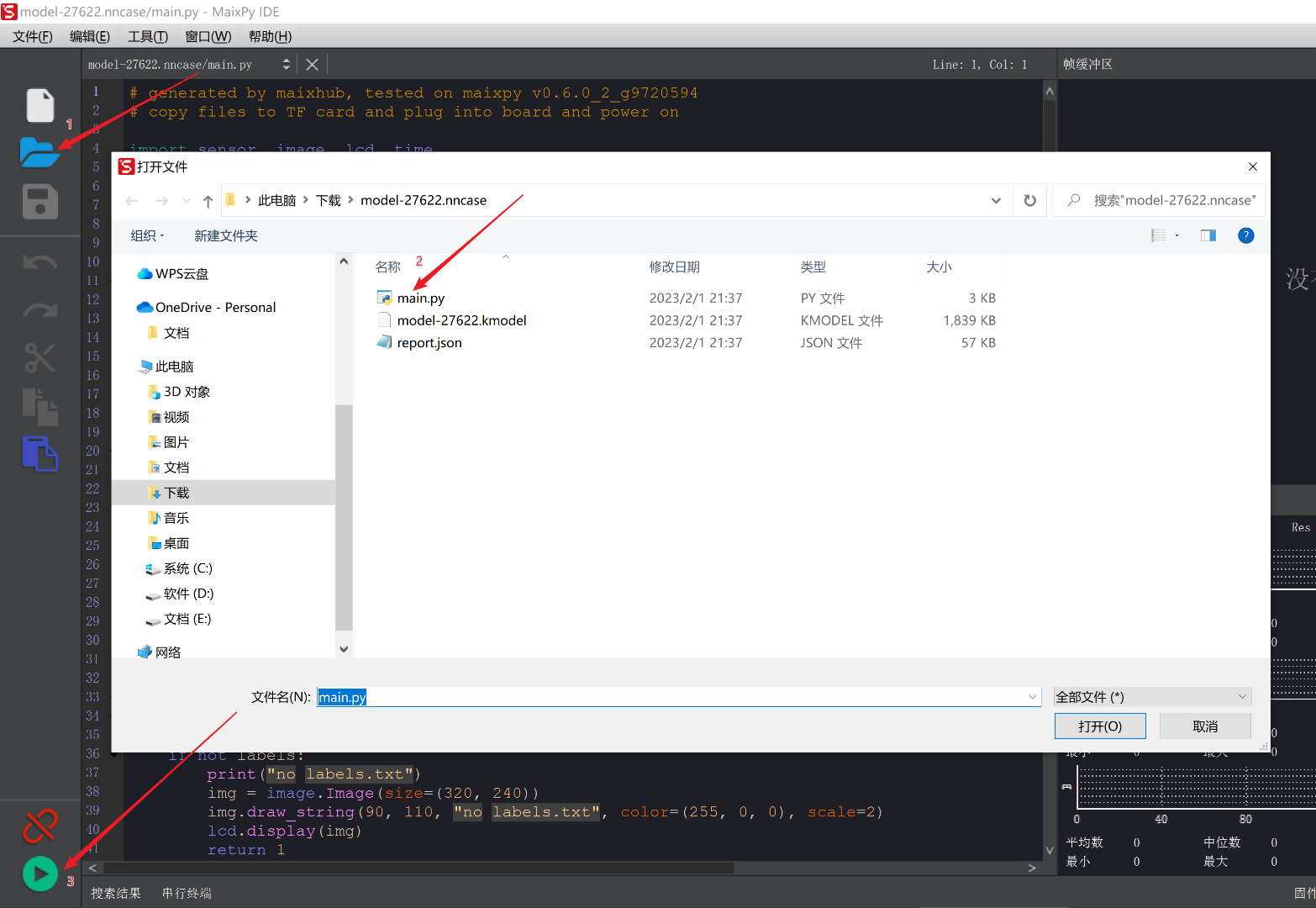
然后在IDE中打开我们下载的
main.py文件,点击左下角的播放按钮,即可开始运行。
MaixHub给你的
main.py文件或许不能直接运行,下面的代码可能需要改一下,因为你的模型是烧录在板子的指定地址的。
只需要用上面那行注释掉的代码代替下面的代码。
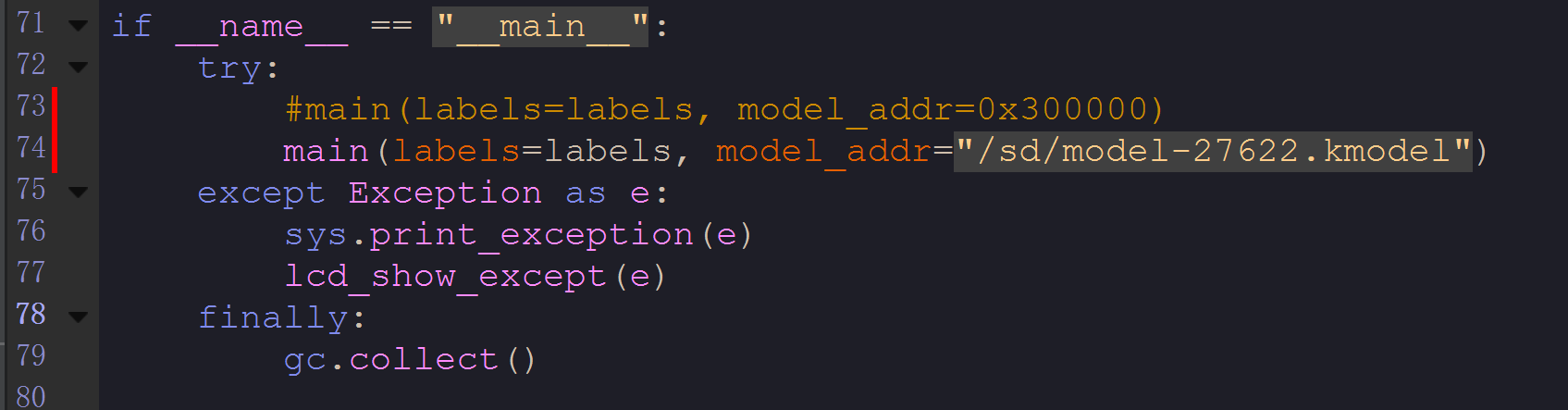
修改如下:
if __name__ == "__main__":try:main(labels=labels, model_addr=0x300000)except Exception as e:sys.print_exception(e)lcd_show_except(e)finally:gc.collect()
如果一切顺利的话,开始体验你的模型吧!祝你好运!
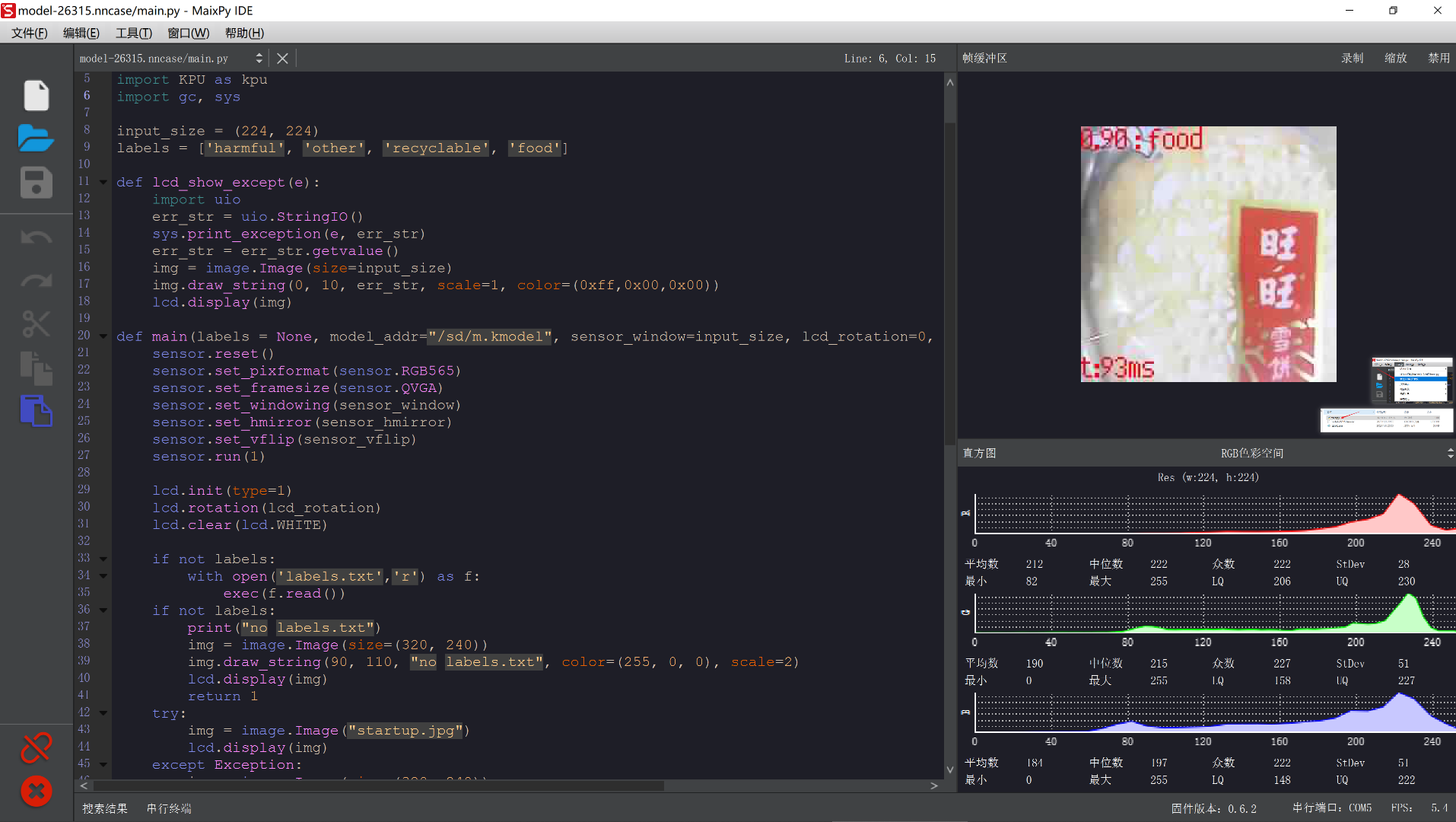
3、上传main.py文件到板子(直接板上运行)
上传main.py文件到板子后,你可以通过两种途径查看模型的运行效果:
- 串口终端(还是要连电脑)
- 板子的屏幕配件(只需给板子通电)
和烧录类似,都是把文件传到板子。但烧录是直接从指定的地址开始,写入二进制文件;而接下来的文件,是上传后交给板子上的文件系统管理的。
打开MaixPy IDE,将IDE连接板子(左下角的连接按钮),连接成功后,在工具栏选择发送文件到开发板即可,选择
main.py文件上传。
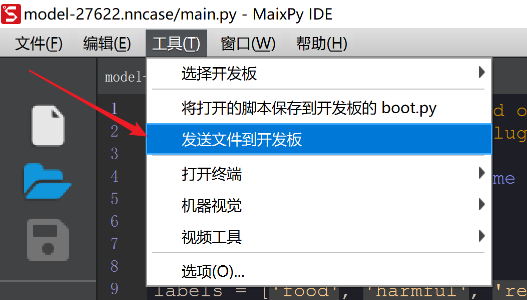
接下来演示一下通过串口终端的运行方式。(因为我板子没有屏幕配件?)
- 虽然和IDE左下角的播放按钮运行一样,需要连接电脑。但串口终端还是有它的优势:
- 占用板子内存更少
- 出错时可能显示更多的错误信息
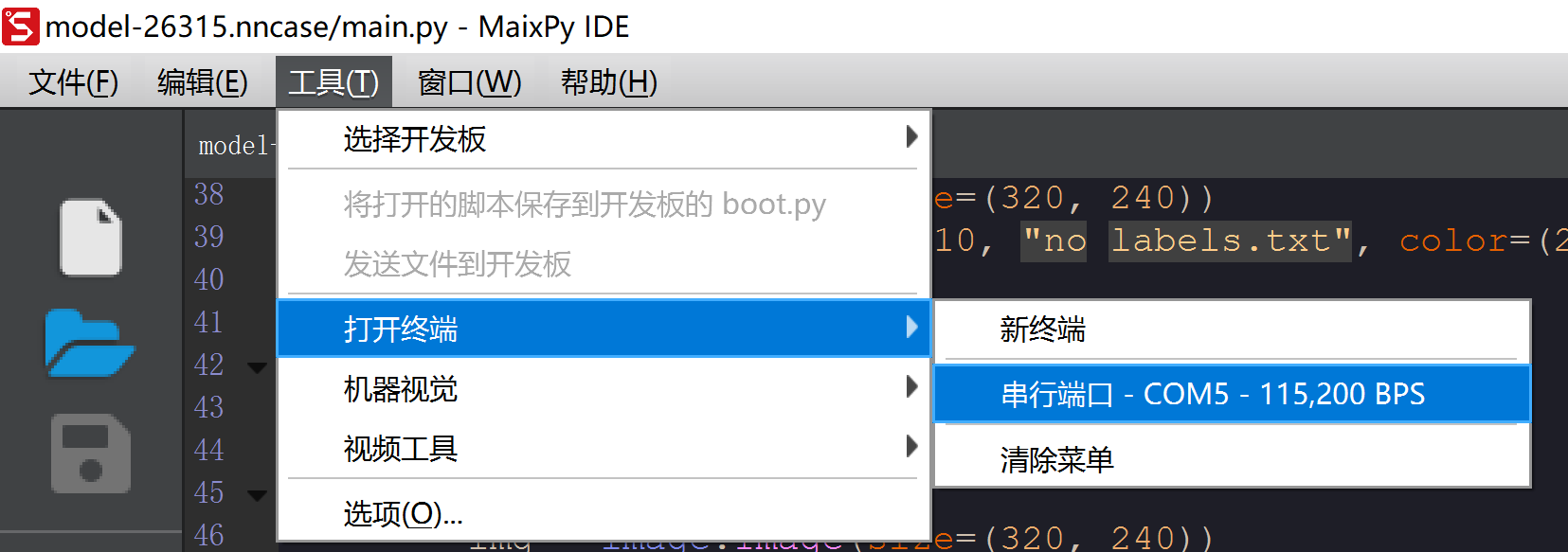
IDE需处于断开连接状态,否则会和串口终端的连接冲突!
然后在工具栏,选择打开终端,串行端口。
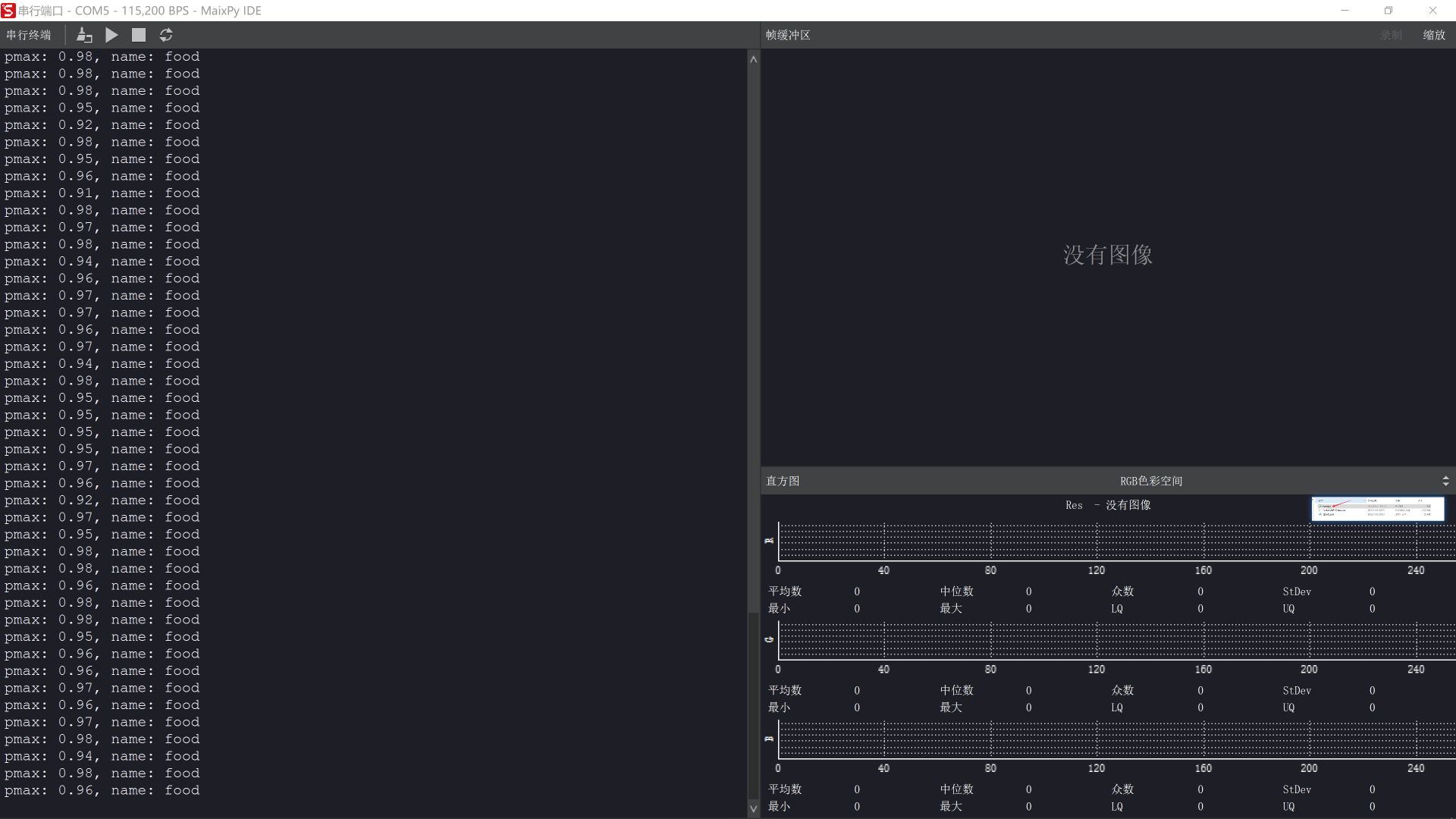
我的串口终端并不能显示摄像头拍摄到的图像(不知是否正常现象),所以我选择修改代码将运行结果打印出来。
结束
写得有点累,不知道对你有没有帮助,感谢阅读!
到此为止。
这篇关于垃圾分类模型训练部署教程,基于MaixHub和MaixPy-k210的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






