Deep Graph Library(DGL)
DGL是一个专门用于深度学习图形的Python包, 一款面向图神经网络以及图机器学习的全新框架, 简化了基于图形的神经网络的实现。
在设计上,DGL 秉承三项原则:
DGL 必须和目前的主流的深度学习框架(PyTorch、MXNet、TensorFlow 等)无缝衔接。从而实现从传统的 tensor 运算到图运算的自由转换。
DGL 应该提供最少的 API 以降低用户的学习门槛。
在保证以上两点的基础之上,DGL 能高效并透明地并行图上的计算,以及能很方便地扩展到巨图上。
设计一:DGL 是一个「框架上的框架」
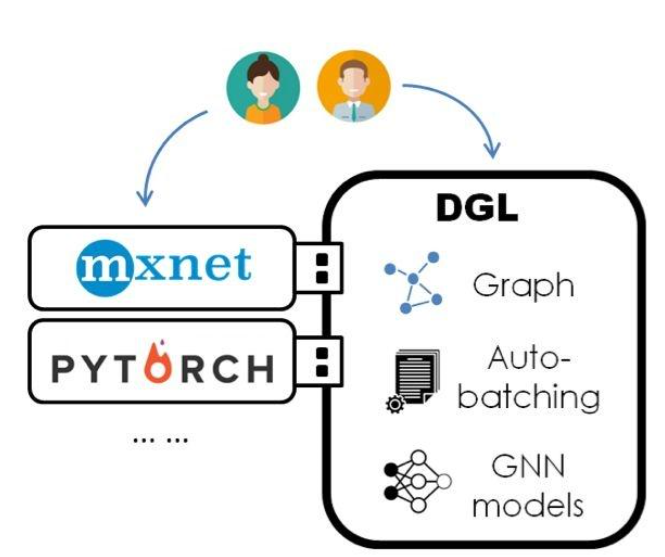
设计二:基于「消息传递」(message passing)编程模型
消息传递是图计算的经典编程模型。原因在于图上的计算往往可以表示成两步:
发送节点根据自身的特征(feature)计算需要向外分发的消息。
接受节点对收到的消息进行累和并更新自己的特征。
比如常见的卷积图神经网络 GCN(Graph Convolutional Network)可以用下图中的消息传递模式进行表示(图中 h 表示节点各自的特征)。用户可以定制化消息函数(message function),以及节点的累和更新函数(reduce function)来构造新的模型。事实上,在 Google 的 2017 年的论文中 [Gilmer et al. 2017] 将很多图神经网络都归纳到了这一体系内。
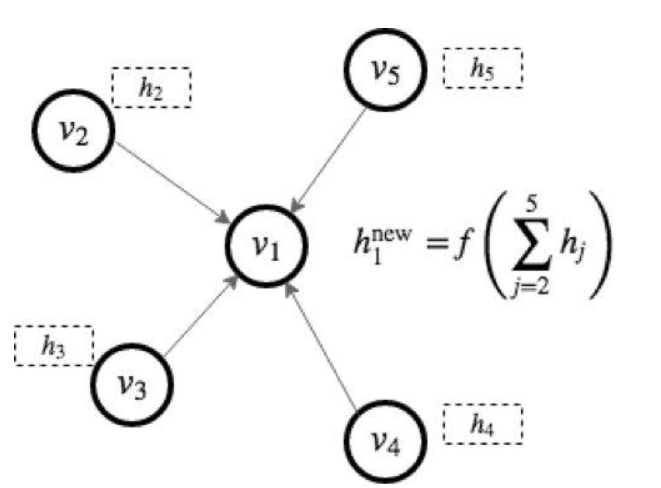
DGL 的编程模型正基于此。
设计三:DGL 的自动批处理(auto-batching)
好的系统设计应该是简单透明的。在提供用户最大的自由度的同时,将系统优化最大程度地隐藏起来。图计算的主要难点在于并行。我们根据模型特点将问题划分为三类。
首先是处理单一静态图的模型(比如 citation graph),其重点是如何并行计算多个节点或者多条边。DGL 通过分析图结构能够高效地将可以并行的节点分组,然后调用用户自定义函数进行批处理。相比于现有的解决方案(比如 Dynet 和 TensorflowFold),DGL 能大大降低自动批处理的开销从而大幅提高性能。
第二类是处理许多图的模型(比如 module graph),其重点是如何并行不同图间的计算。DGL 的解决方案是将多张图合并为一张大图的多个连通分量,从而将该类模型转化为了第一类。
第三类是巨图模型(比如 knowledge graph),对此,DGL 提供了高效的图采样接口,将巨图变为小图样本,从而转化为第一类问题。
目前 DGL 提供了 10 个示例模型,涵盖了以上三种类别。其中除了 TreeLSTM,其余都是 2017 年以后新鲜出炉的图神经网络,其中包括几个逻辑上相当复杂的生成模型(DGMG、JTNN)我们也尝试用图计算的方式重写传统模型比如 Capsue 和 Universal Transformer,让模型简单易懂,帮助进一步扩展思路。
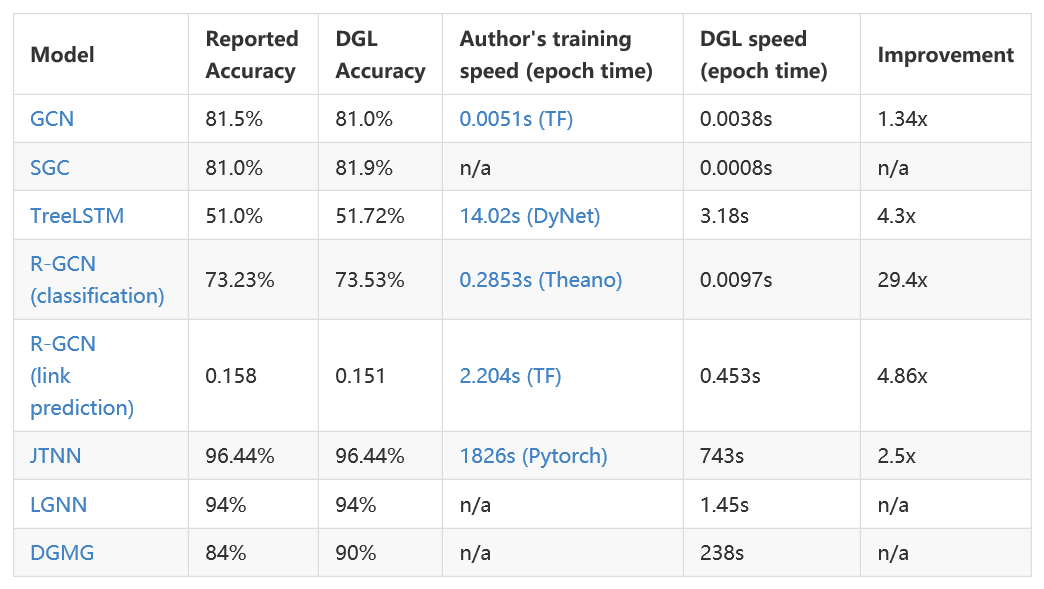
可以看到,DGL 能在这些模型上都取得了相当好的效果。我们也对 DGL 在巨图上的性能进行了测试。在使用 MXNet/Gluon 作为后端时,DGL 能支持在千万级规模的图上进行神经网络训练。
DGL 现已开源。
主页地址:http://dgl.ai
项目地址:https://github.com/jermainewang/dgl
初学者教程:https://docs.dgl.ai/tutorials/basics/index.html
所有示例模型的详细从零教程:https://docs.dgl.ai/tutorials/models/index.html
本教程目标:
了解DGL如何从高级别开始在图形上进行计算。
在DGL中训练一个简单的图形神经网络来对图形中的节点进行分类。
依赖库
- DGL 0.2
- PyTorch 1.1.0
- networkX 2.3+
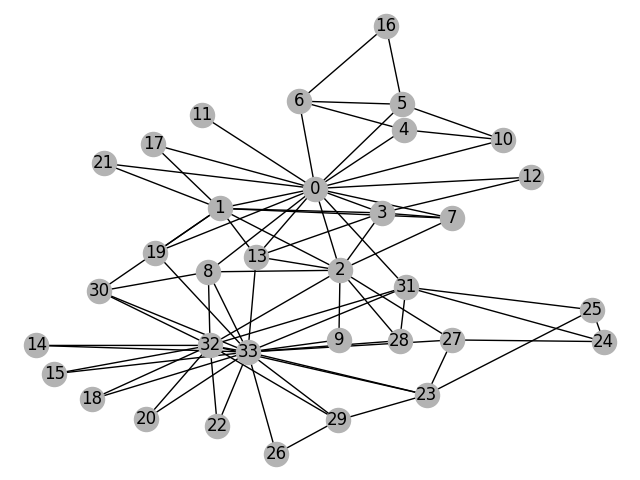
Step 0: 问题描述(Zachary’s karate club)
我们从“Zachary空手道俱乐部”问题开始。 空手道俱乐部是一个社交网络,它捕获34名成员并记录在俱乐部外互动的成员之间的成对链接。 俱乐部分为由教练(节点0)和俱乐部主席(节点33)领导的两个社区。 网络可视化如下,颜色表示社区):
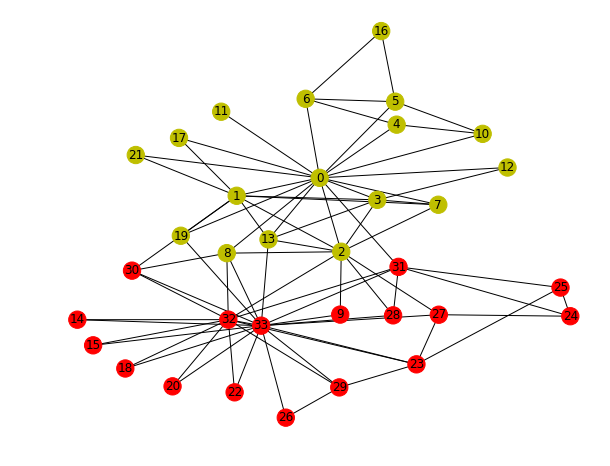
任务是根据社交网络本身预测每个成员倾向于加入哪一方(0或33)。
Step 1:利用DGL构建图
1 # -*- coding: utf-8 -*- 2 """ 3 @Date: 2019/5/27 4 @Author: ranran 5 @Summary: DGL graph 6 """ 7 8 import dgl 9 import torch 10 import networkx as nx 11 import matplotlib.pyplot as plt 12 13 14 'import dgl 创建 Zachary’s karate club 图 :' 15 def build_karate_club_graph(): 16 g = dgl.DGLGraph() 17 # add 34 nodes into the graph; nodes are labeled from 0~33 18 g.add_nodes(34) 19 # all 78 edges as a list of tuples所有78条边作为元组列表 元组属于不可变序列, 元组的访问和处理速度比列表快 20 edge_list = [(1, 0), (2, 0), (2, 1), (3, 0), (3, 1), (3, 2), 21 (4, 0), (5, 0), (6, 0), (6, 4), (6, 5), (7, 0), (7, 1), 22 (7, 2), (7, 3), (8, 0), (8, 2), (9, 2), (10, 0), (10, 4), 23 (10, 5), (11, 0), (12, 0), (12, 3), (13, 0), (13, 1), (13, 2), 24 (13, 3), (16, 5), (16, 6), (17, 0), (17, 1), (19, 0), (19, 1), 25 (21, 0), (21, 1), (25, 23), (25, 24), (27, 2), (27, 23), 26 (27, 24), (28, 2), (29, 23), (29, 26), (30, 1), (30, 8), 27 (31, 0), (31, 24), (31, 25), (31, 28), (32, 2), (32, 8), 28 (32, 14), (32, 15), (32, 18), (32, 20), (32, 22), (32, 23), 29 (32, 29), (32, 30), (32, 31), (33, 8), (33, 9), (33, 13), 30 (33, 14), (33, 15), (33, 18), (33, 19), (33, 20), (33, 22), 31 (33, 23), (33, 26), (33, 27), (33, 28), (33, 29), (33, 30), 32 (33, 31), (33, 32)] 33 34 # add edges two lists of nodes: src and dst添加两个节点列表:src和dst 35 src, dst = tuple(zip(*edge_list)) #zip(*)解压成列表形式,再构成两个元组 36 print(src) 37 #(1, 2, 2, 3, 3, 3, 4, 5, 6, 6, 6, 7, 7, 7, 7,8, 8, 9, 10, 10, 10, 11, 12, 12, 13, 13, 13, 13, 16, 16, 17, 17, 19, 19, 21, 21, 25, 25, 27, 27, 27, 28, 29, 29, 30, 30, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33) 38 print(dst) 39 #(0, 0, 1, 0, 1, 2, 0, 0, 0, 4, 5, 0, 1, 2, 3, 0, 2, 2, 0, 4, 5, 0, 0, 3, 0, 1, 2, 3, 5, 6, 0, 1, 0, 1, 0, 1, 23, 24, 2, 23, 24, 2, 23, 26, 1, 8, 0, 24, 25, 28, 2, 8, 14, 15, 18, 20, 22, 23, 29, 30, 31, 8, 9, 13, 14, 15, 18, 19, 20, 22, 23, 26, 27, 28, 29, 30, 31, 32) 40 g.add_edges(src, dst) 41 # edges are directional in DGL; make them bi-directional 边在DGL中是方向性的; 使它们双向 42 g.add_edges(dst, src) 43 return g 44 45 46 if __name__ == '__main__': 47 48 '打印出刚刚创建的图的节点数 nodes 和边的个数 edges ' 49 G = build_karate_club_graph() 50 print('We have %d nodes.' % G.number_of_nodes()) 51 print('We have %d edges.' % G.number_of_edges()) 52 #We have 34 nodes. 53 #We have 156 edges. 54 55 fig, ax = plt.subplots() 56 fig.set_tight_layout(False) 57 58 'import networkx as nx import matplotlib.pyplot as plt 我们还可以通过将图转换为networkx图来可视化它:' 59 #Since the actual graph is undirected, we convert it for visualization purpose. 60 nx_G = G.to_networkx().to_undirected() 61 # Position nodes using Kamada-Kawai path-length cost-function. Kamada-Kawaii layout usually looks pretty for arbitrary graphs 62 pos = nx.kamada_kawai_layout(nx_G) 63 #Draw the graph nx_G with Matplotlib. 64 nx.draw(nx_G, pos, with_labels=True, node_color=[[0.7, 0.7, 0.7]]) #node_color 节点颜色的深浅程度 65 plt.show() 66 67 68 69 'import torch 为节点或边分配特征 assign features to nodes or edges' 70 #图形神经网络将特征与节点和边缘相关联以进行训练。 对于我们的分类示例子,我们将每个节点的输入特征指定为一个one-hot 向量: 71 # 节点vi的特征向量为[0,...,1,...,0],其中第i个位置是1。 72 #在DGL中,我们可以使用沿第一维批量节点特征的特征张量一次为所有节点添加特征。 下面的代码为所有节点添加 one—hot特征: 73 G.ndata['feat'] = torch.eye(34) 74 75 #可以打印出一些节点的特征确定下: 76 print(G.nodes[2].data['feat']) 77 print(G.nodes[1, 3].data['feat']) 78 #tensor([[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 79 # 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]) 80 #tensor([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 81 # 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], 82 # [0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 83 # 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
构建的图可视化:
Step 2: 定义 Graph Convolutional Network (GCN)
为了执行节点分类,我们使用由Kipf和Welling开发的图形卷积网络(GCN)。 在这里,我们提供了GCN框架的最简单定义,但我们建议读者阅读原始文章以获取更多详细信息。
在 l 层,每个节点vli 带有特征向量 hli
GCN的每一层都试图聚合来自uil的特征(ui是v的邻接节点)生成下一层ViL+ 1的特征。 接下来是具有一些非线性的仿射变换。an affine transformation with some non-linearity
GCN的上述定义适合于消息传递范例:每个节点将使用从相邻节点发送的信息更新其自己的特征。 下面显示了图形演示。
# -*- coding: utf-8 -*- """ @Date: 2019/5/27 @Author: ranran @Summary: define a Graph Convolutional Network (GCN) """ import torch import torch.nn as nn'定义 message 和 reduce 函数' #注意:本教程忽略GCN标准化常量c_ij。 def gcn_message(edges):#参数是一批边。它使用源节点的特征'h'计算一个名为'msg'的(批处理)消息。"""compute a batch of message called 'msg' using the source nodes' feature 'h':param edges::return:"""return {'msg': edges.src['h']}def gcn_reduce(nodes):#参数是一批节点。这通过将每个节点收到的'msg'相加来计算新的'h'特征。"""compute the new 'h' features by summing received 'msg' in each node's mailbox.:param nodes::return:"""'??????'return {'h': torch.sum(nodes.mailbox['msg'], dim=1)}'定义GCNLayer Module (一层GCN) ' class GCNLayer(nn.Module):def __init__(self, in_feats, out_feats):super(GCNLayer, self).__init__()self.linear = nn.Linear(in_feats, out_feats)def forward(self, g, inputs):# g—graph#inputs—input node features# first set the node features首先设置节点特征g.ndata['h'] = inputs# trigger message passing on all edges 在所有边上触发消息传送 g.send(g.edges(), gcn_message)# trigger aggregation at all nodes 在所有节点上触发聚合 g.recv(g.nodes(), gcn_reduce)# get the result node features 获取结果节点特征h = g.ndata.pop('h')# perform linear transformation 执行线性变换return self.linear(h)#通常,节点发送通过message函数计算的信息,并使用reduce函数聚合传入信息。 #然后,我们定义了一个包含两个GCN层的更深层次的GCN模型:'定义一个2层的GCN 网络' class GCN(nn.Module):def __init__(self, in_feats, hidden_size, num_classes):super(GCN, self).__init__()self.gcn1 = GCNLayer(in_feats, hidden_size) #两层self.gcn2 = GCNLayer(hidden_size, num_classes)def forward(self, g, inputs):h = self.gcn1(g, inputs)h = torch.relu(h) # h = self.gcn2(g, h)return hif __name__ == '__main__':net = GCN(34, 5, 2) #输入特征34维向量,隐藏层5, 输出层2(分两类)
Step 4: 数据准备及初始化 训练 可视化
可视化模块我还没学
# -*- coding: utf-8 -*- """ @Date: 2019/5/27 @Author: ranran @Summary: train semi-supervised setting """import torch import torch.nn.functional as Fimport networkx as nx import matplotlib.animation as animation import matplotlib.pyplot as pltfrom model import GCN from build_graph import build_karate_club_graphimport warnings warnings.filterwarnings('ignore')net = GCN(34, 5, 2) print(net) G = build_karate_club_graph()'数据准备和初始化' #我们使用one—hot向量来初始化节点特征。 由于这是半监督设置,因此仅向教练(节点0)和俱乐部主席(节点33)分配标签。 实施如下 inputs = torch.eye(34) labeled_nodes = torch.tensor([0, 33]) # only the instructor and the president nodes are labeled labels = torch.tensor([0, 1])'训练' #训练循环与其他PyTorch模型完全相同。 # (1)创建一个优化器 # (2)将输入数据喂给模型 # (3)计算损失 # (4)使用autograd来优化模型。 optimizer = torch.optim.Adam(net.parameters(), lr=0.01) all_logits = []for epoch in range(30): #训练20次logits = net(G, inputs) #返回的h保存在logits中#为了之后的可视化保存logits'detach()?????'all_logits.append(logits.detach())#返回的是个概率?# 非线性函数torch.nn.functional.log_softmax(input, dim=None, _stacklevel=3, dtype=None)logp = F.log_softmax(logits, 1)# 只计算标记节点的损失# logp-labels# torch.nn.functional.nll_loss(input, target, weight=None, size_average=True)# size_average (bool, optional) – 默认情况下,是mini-batchloss的平均值,然而,如果size_average=False,则是mini-batchloss的总和。loss = F.nll_loss(logp[labeled_nodes], labels)optimizer.zero_grad()loss.backward()optimizer.step()print('Epoch %d | Loss: %.4f' % (epoch, loss)) #去掉.items()也正常运行''' 这是一个小示例,它没有验证或测试集。 由于模型为每个节点生成大小为2的输出特征,我们可以通过在2D空间中绘制输出特征来进行可视化。 以下代码将训练过程从初始猜测(其中节点根本没有正确分类)到结束(节点可线性分离)进行动画处理。 '''def draw(i):cls1color = '#00FFFF'cls2color = '#FF00FF'pos = {}colors = []for v in range(34):pos[v] = all_logits[i][v].numpy()cls = pos[v].argmax()colors.append(cls1color if cls else cls2color)ax.cla()#ax.axis('off')ax.set_title('Epoch: %d' % i)nx.draw_networkx(nx_G.to_undirected(), pos, node_color=colors,with_labels=True, node_size=300, ax=ax)nx_G = G.to_networkx().to_undirected() fig = plt.figure(dpi=150) fig.clf() ax = fig.subplots()draw(29) # draw the prediction of the last epoch#'以下动画显示了模型在一系列训练时期之后如何正确预测社区?????显示不了动画' # ani = animation.FuncAnimation(fig, draw, frames=len(all_logits), interval=200) plt.show()









