本文主要是介绍【医学大模型 补全主诉】BioGPT + LSTM 自动补全医院紧急部门主诉,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BioGPT + LSTM 自动补全医院紧急部门主诉
- 问题:针对在紧急部门中自动补全主诉的问题
- 子问题1: 提高主诉记录的准确性
- 子问题2: 加快主诉记录的速度
- 子问题3: 统一医疗术语的使用
- 子问题4: 减少打字错误和误解
- 子问题5: 提高非特定主诉的处理能力
- 解法
- 数据预处理
- 神经网络方法
- 迁移学习方法
- 提示调整:少量样本技术
论文:https://arxiv.org/pdf/2401.06088.pdf
问题:针对在紧急部门中自动补全主诉的问题
在医院紧急部门中:
- 急诊科:处理各种突发医疗情况,如创伤、心脏病发作等。
- 创伤中心:专门处理严重的创伤案例,如车祸伤害。
- 心脏急救中心:专注于心脏相关的紧急状况。
- 中风中心:专门处理中风患者的紧急护理。
- 儿科急诊:专门处理儿童的紧急医疗需求。
主诉自动补全系统可以帮助这些部门的医护人员快速准确地记录患者的病情描述,从而提高紧急医疗响应的效率和质量。
子问题1: 提高主诉记录的准确性
- 子解法1: 使用NLP技术自动识别和补全主诉文本
- 之所以使用NLP技术,是因为: 它能够理解和处理自然语言,自动识别医疗术语和患者描述的症状,从而提高记录的准确性。
举例: 如果一个患者描述了一系列模糊的症状,如“胸痛、呼吸困难”,NLP技术可以根据这些描述自动建议相关的、更具体的医疗术语,帮助护理人员快速准确地完成主诉记录。
子问题2: 加快主诉记录的速度
- 子解法2: 实现自动补全和预测功能
- 之所以实现自动补全和预测功能,是因为: 这可以减少医护人员输入完整词汇或句子所需的时间,特别是在忙碌的ED环境中,快速记录是非常必要的。
举例: 当医护人员开始输入“头痛”,系统就能提供一系列可能的补全选项,如“头痛持续时间”、“头痛性质”等,从而加速记录过程。
子问题3: 统一医疗术语的使用
- 子解法3: 促进标准化术语的采用
- 之所以促进标准化术语的采用,是因为: 在医疗记录中使用统一的标准术语可以减少误解和错误,确保不同的医护人员能够准确理解患者的状况。
举例: 如果系统能够识别医护人员输入的非标准术语,并自动建议对应的标准术语,比如将“心脏痛”自动更正为“胸痛”,这将有助于保持医疗记录的一致性和准确性。
子问题4: 减少打字错误和误解
- 子解法4: 提供拼写检查和语义理解支持
- 之所以提供拼写检查和语义理解支持,是因为: 打字错误和语言歧义是记录过程中常见的问题,通过技术手段减少这些错误可以提高记录的质量。
举例: 当医护人员输入“心绞痛”时,如果误输入为“新绞痛”,系统的拼写检查功能可以即时识别并更正错误,同时,语义理解支持能够确保使用正确的医学术语,减少因误解而导致的诊断错误。
子问题5: 提高非特定主诉的处理能力
- 子解法5: 引入上下文理解和预测分析
- 之所以引入上下文理解和预测分析,是因为: 非特定主诉(如“感觉不适”)需要根据上下文和患者的其他描述来准确理解和记录,NLP技术可以分析整个对话或记录的上下文,提供更准确的补全建议。
举例: 对于一个表达为“感觉不适”的主诉,系统可以根据患者之前提供的信息(如年龄、已知的健康状况)和当前的描述(如“最近旅行史”),自动建议可能相关的具体症状或需要询问的进一步信息,帮助医护人员快速定位问题。
解法
针对“在紧急部门中自动补全主诉(Chief Complaints, CC)”的问题,本文介绍了一系列解决步骤和方法。
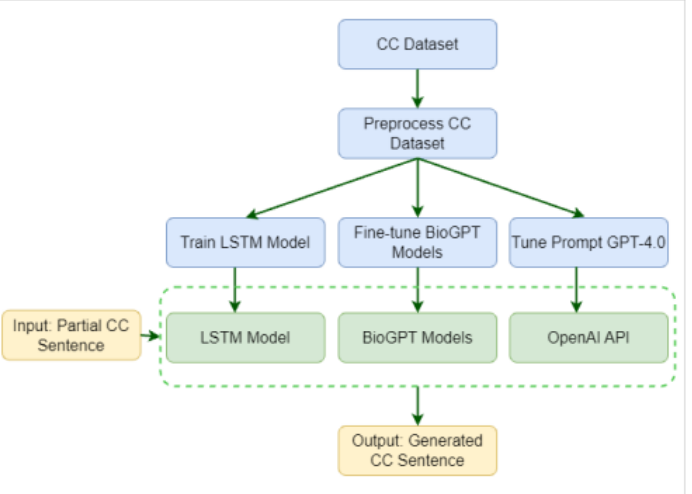
主诉(CC)数据集经过预处理步骤,然后用来训练一个LSTM模型和微调BioGPT模型。
也对GPT-4.0的提示进行了调整。输入是一个不完整的主诉句子,随后通过LSTM模型或BioGPT模型处理,利用OpenAI API对GPT-4.0的提示进行操作。输出是生成的主诉句子。
数据预处理
问题: 如何处理和优化主诉数据以便于模型学习?
- 解决方法: 数据预处理
- 特征1: 使用Python NLP库Stanza分割主诉文本为句子
- 特征2: 基于句子长度过滤,丢弃少于4个词的句子
- 特征3: 将数据集分为训练集、验证集和测试集,比例为80%、10%和10%
文本清洗(去除无关字符,标准化术语)
句子分割(区分主诉和医疗历史)
关键词提取(提取症状、疾病名称等)
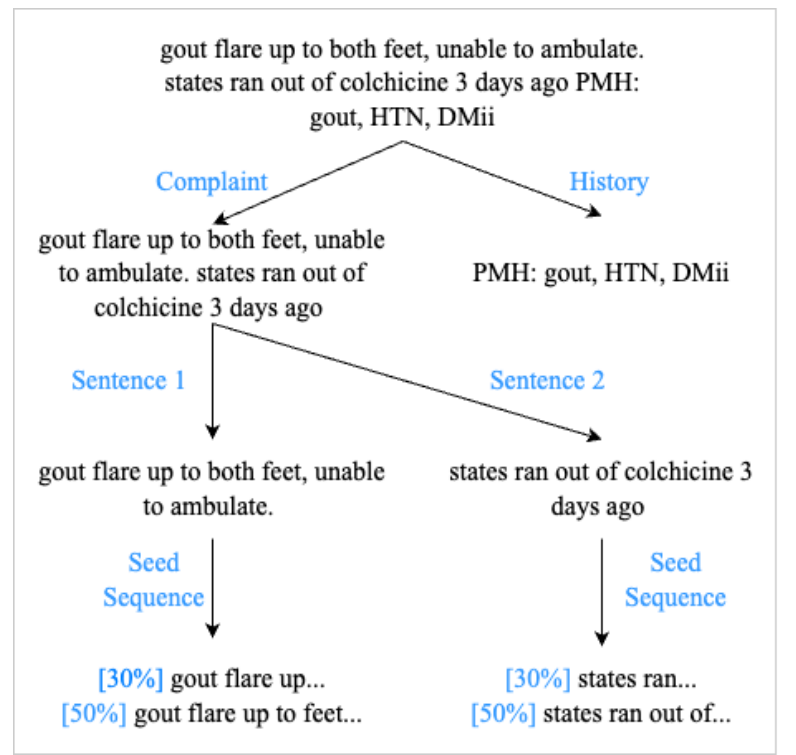
展示了如何将CC条目分割成“投诉”和“历史”部分,进一步分割成单独的句子,然后分割成种子序列以供模型处理。百分比表示种子序列包含原始句子的多少,如30%或50%。
神经网络方法
问题: 如何构建模型以自动补全主诉?
- 解决方法: LSTM模型应用
- 特征1: 嵌入层转换输入文本为密集词向量
- 特征2: LSTM层捕获文本长期依赖
- 特征3: 密集层输出序列中下一个词的概率分布
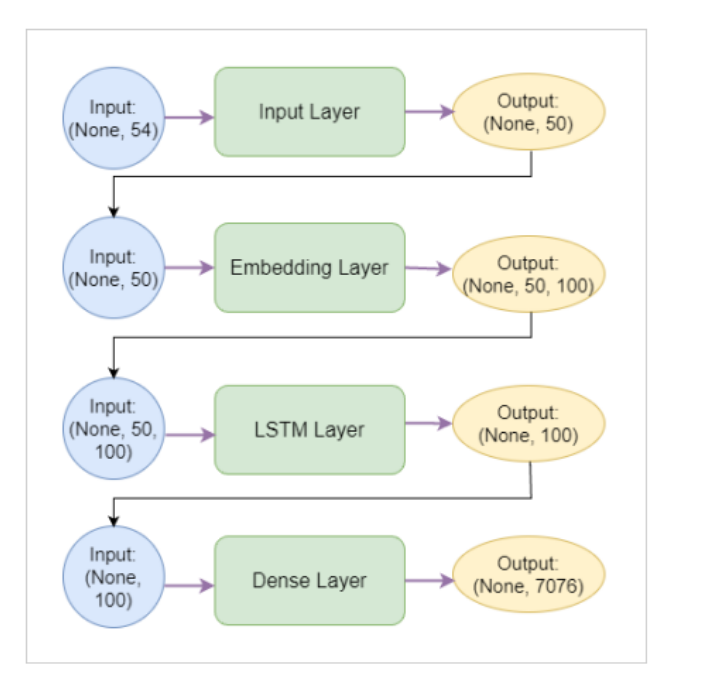
研究中使用的LSTM模型的架构。
它由一个输入层、一个将单词映射到100维向量空间的嵌入层、一个具有100个单元的LSTM层来处理序列和一个具有softmax激活的密集层组成,用于预测下一个词。
迁移学习方法
问题: 如何利用预训练模型提高自动补全的准确性?
- 解决方法: BioGPT模型应用
- 特征1: 选择已经在生物医学文献上预训练的模型,如BioGPT,因为它已经对医疗专业术语和上下文有了初步的理解。
- 特征2: 使用特定的主诉数据集进一步训练(细调)BioGPT模型,这样可以让模型更好地理解和生成针对特定医疗环境的文本。
- 特征3: 利用特殊令牌和标识句子的开始和结束,这些标记帮助模型识别文本的开始和结束,对处理多句子文本尤其重要。
提示调整:少量样本技术
问题: 如何通过少量示例提高模型对特定任务的适应性?
- 解决方法: GPT-4模型的提示调整
- 特征1: 利用OpenAI API,采用少量样本(Few-Shot)技术
- 特征2: 通过提供有限数量的任务演示在推理阶段进行条件化
- 特征3: 创建包含100个示例的提示以“编程”GPT模型
这篇关于【医学大模型 补全主诉】BioGPT + LSTM 自动补全医院紧急部门主诉的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









