本文主要是介绍ChIP-seq助力植物着丝粒特异性组蛋白CENH3研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
着丝粒是由DNA与蛋白质组成的复合物,是染色体上的重要功能位点,在细胞有丝分裂和减数分裂过程中参与动粒的组装,控制染色单体的配对与分离。真核生物的着丝粒DNA含有大量重复序列且序列进化迅速,物种间相似性较低,因而着丝粒区域DNA的组装成为全基因组测序中最困难的任务之一。植物着丝粒特异性组蛋白CENH3可以定义活性着丝粒,其作为表观遗传标记以建立和维持着丝粒的功能。随着染色质免疫共沉淀、测序技术的发展并结合分子生物学、细胞遗传学、生物信息学的分析手段,我们可以进一步对着丝粒序列进行分析及定位,同时为其功能和进化等研究提供一定的依据。
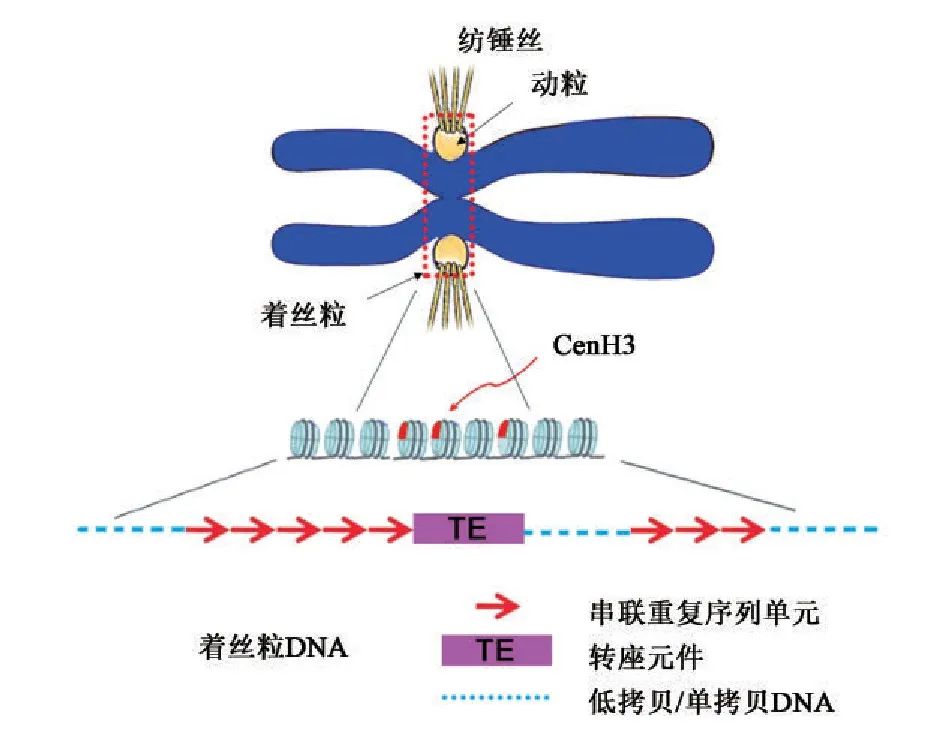
图1.着丝粒结构
由于着丝粒重复序列的物种特异性,常规比较基因组学方法往往难以对其进行有效的分离和分析。近年来,根据着丝粒存在特异组蛋白CENH3的特点,研究者建立了基于CENH3抗体的ChIP-seq的着丝粒分离分析方法,使得分离不同物种着丝粒DNA得以实现,并极大推动了着丝粒研究的深入开展。
在获得着丝粒ChIP-seq数据后,通过与基因组序列比对筛选,获得在基因组上具有单一拷贝的数据,并将其锚定到对应物种的基因组上,即可获得ChIP-seq富集的峰图,该峰图则指示着丝粒区。这一方法目前已被用于着丝粒的基因组精确定位;同时,由于大量高度重复序列的存在,着丝粒往往是基因组拼装工作中最为困难的区域,着丝粒区的组装质量往往决定和反映了基因组的整体组装质量。因此,可以根据每条染色体是否获得单一、完整的着丝粒区间来判断基因组组装质量。这一点对基因组组装质量评估具有重要的参考价值。
由于着丝粒DNA的复杂性,目前已绘制基因组草图的物种极少有完整组装的着丝粒。因此,难以将ChIP-seq数据通过与基因组比对获得着丝粒特异重复序列。近年来,由Nowak等提出的1种重复序列分析方法在着丝粒的重复序列研究中广泛应用,其原理是采用较低深度的基因组数据构建重复序列家族,并根据序列相似性组装并聚类成不同的重复簇;然后将均一化后的ChIP-seq与基因组对照(input)数据锚定到不同重复簇上,从而获得两者在各个重复簇上的富集度差,具有高的ChIP-seq/input富集度差的重复序列则被认为是在着丝粒中富集的,即候选着丝粒重复序列。结合细胞学的荧光原位杂交技术(FISH)验证,最终可鉴定出着丝粒区域特异的重复序列。这一策略已在包括马铃薯、玉米、棉花、二穗短柄草、甘蔗、古代莲等多个物种的着丝粒重复序列分析中得以成功应用,充分显示了该方法在着丝粒重复序列鉴定与分析中的有效性。随着三代单分子测序技术的发展,着丝粒序列的研究也将更加深入。结合单分子测序数据以及原有的ChIP-seq测序数据,可以更加确切地获得重复序列在着丝粒区的分布方式,进一步揭开着丝粒序列的组成与演化之谜。
文献案例一:泛着丝粒研究揭示大豆基因组普遍的着丝粒重定位情况

No.1 研究背景
着丝粒重定位是指在另一个染色体位置重新形成着丝粒而不进行序列重排。这种现象在哺乳动物和植物物种中都经常发生,并且与基因组进化和物种形成有关。大豆是食用最广泛的人类营养蛋白质的豆类来源。最近大豆泛基因组的构建提供了高质量的参考基因组信息,确定了许多与重要性状有关的遗传变异。中黄13号(ZH13)是中国种植最广泛的大豆品种。与大豆泛基因组相比,ZH13的基因组组装质量也较高,其完整性和准确性均高于参考基因组W82。大豆泛基因组的发布,以及ZH13的高质量参考,为群体间着丝粒多样性的调查提供了宝贵的基因组资源。
已有研究表明,大豆染色体的着丝粒区包含三种串联重复序列,分别是CentGm-1、CentGm-2和CentGm-4。在大豆中也发现了着丝粒特异性的反转录转座子。然而,种群内和种群间着丝粒结构和序列多样性的范围尚未得到详细的研究。在此,研究者进行了比较基因组学研究,从遗传学(序列组成)和表观遗传学(CENH3定位)两个方面探讨大豆着丝粒的多样性和动态。
No.2 研究思路

No.3 研究结果
结果表明,在杂交遗传背景下,着丝粒位置可以随着世代的传递而改变。此外,本文还揭示了不同着丝粒之间的CENH3结合模式和重复DNA含量的差异,这些差异可能解释了这些ENC(新着丝粒)具有独特的序列特征和重复DNA含量。本文的研究也为了解作物品种间的亲缘关系和着丝粒的进化提供了新的线索。
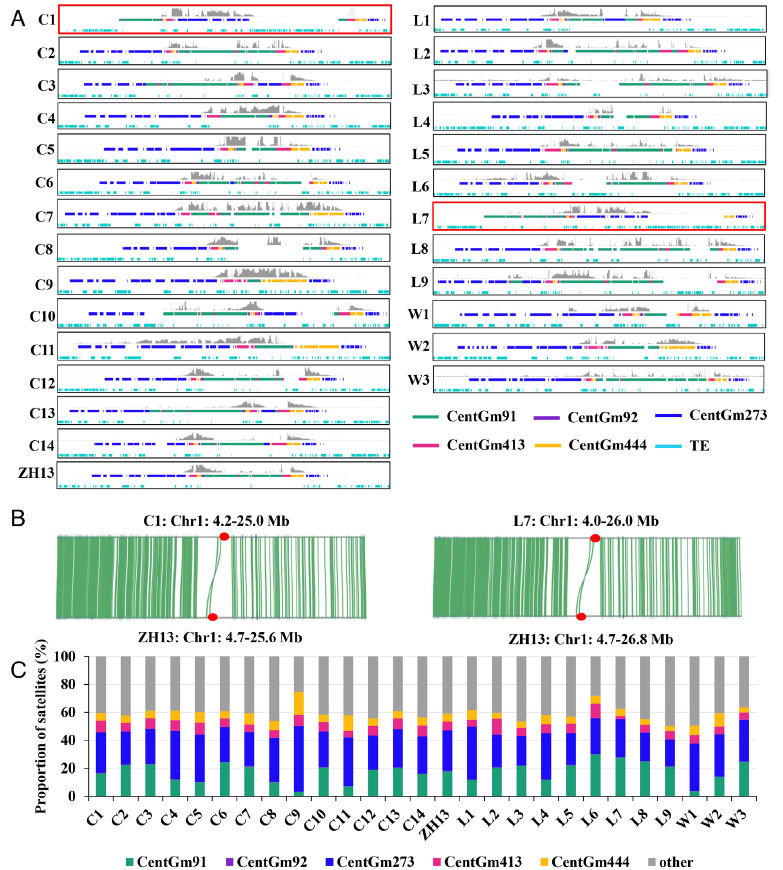
图2. 27个大豆品种中Cen1上的着丝粒卫星、TE和CENH3-ChIP的分布特征
文献案例二:甜橙着丝粒重复序列信息为着丝粒进化与G-四链体分布提供新见解

No.1 研究背景
着丝粒在保证细胞分裂过程中染色体的准确分离中起着至关重要的作用。尽管甜橙经历了三轮基因组测序技术,但其基因组中大量重复DNA元件的存在导致着丝粒基因组图谱存在实质性空白,使着丝粒重复序列的组成不清楚。为了解决这个问题,研究者采用了甜橙着丝粒特异性组蛋白H3变体的抗体(CsCenH3,自制抗体)进行染色质免疫沉淀测序(ChIP-seq)和着丝粒特异性的BAC-3a测序(BAC-3a-seq)相结合的方法来精确定位着丝粒。
No.2 研究思路
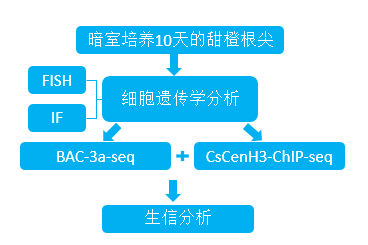
No.3 研究结果
该研究识别了一系列着丝粒特异性重复序列,包括5个串联重复序列和9个长末端重复序列反转录转座子。通过全面的生物信息学分析,获得了可能的着丝粒进化事件的有价值的见解,并发现了在甜橙中存在着丝粒重复序列的DNA G -四链体结构。总之,该研究不仅为甜橙的着丝粒基因组组装提供了有价值的参考,而且揭示了甜橙的着丝粒的结构特征。
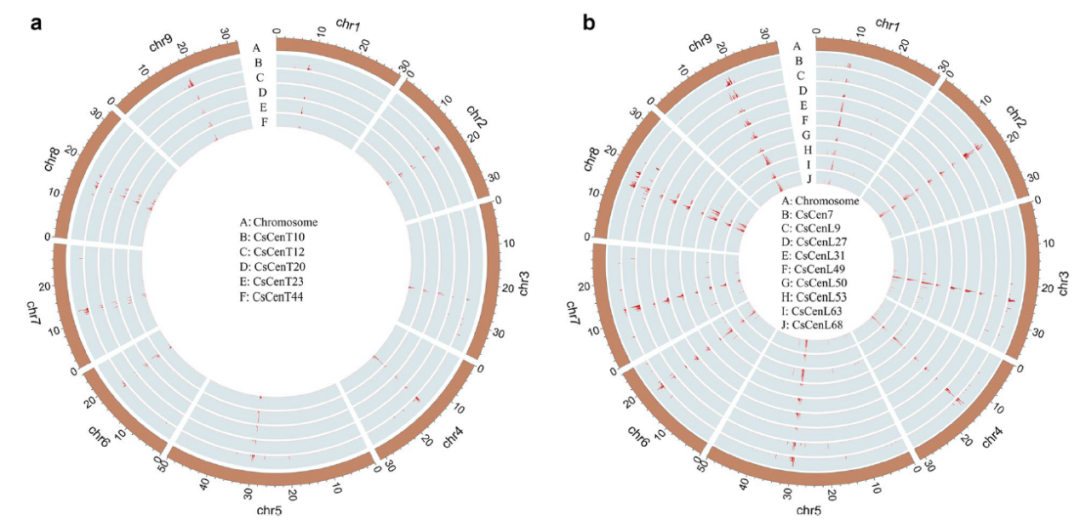
图3.5个串联重复序列和9个长末端反转录转座子重复序列特异分布在甜橙V3基因组的着丝粒处
总 结
着丝粒是真核生物染色体不可或缺的功能元件,继续开展着丝粒组成、结构及演化研究是揭示着丝粒功能之谜的关键。借助着丝粒组蛋白ChIP-seq的分析策略,实现了不同物种着丝粒序列的正确分离和鉴定,借助ChIP-seq的单拷贝序列回帖基因组实现了着丝粒的精确定位,这些极大推动了着丝粒区的组装工作。随着更长读长和更高准确率的测序技术的应用,着丝粒重复序列将被更加准确的拼接组装,着丝粒序列组成之谜也将进一步被破解,这也将推动着丝粒起源、演化乃至基因组工作的深入开展。

这篇关于ChIP-seq助力植物着丝粒特异性组蛋白CENH3研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







