本文主要是介绍O'Reilly AI Conference纽约站 “游记”:AI应用加速落地,强化学习更受关注,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI Conference 2019北京站6月重返中国

感谢大数据文摘纽约特约记者:effy
2019年4月15日-18日,O’Reilly AI Conference在纽约举行,整个大会为期4天,在会上,参会嘉宾讨论了人工智能学术现状、公司在部署AI中遇到的问题,以及在业界的应用情况。
作为机器学习和数据科学领域最有影响力的全球峰会之一,本次大会据了解有超过2000人参加。大数据文摘作为特约合作媒体,也是整场会议唯一的中国媒体受邀参会,在现场度过了收获满满的4天。
除了现场论坛,还从各种细节安排上感受到了O’Reilly这一国际顶级AI行业论坛的诚意,所以今天的稿子与其说是干货,不如说是一次现场“游记”。
那么,请各位跟着文摘菌一起出发吧!

学术成果正加速落地
本次大会主论坛最让文摘菌印象深刻的演讲来自O’Reilly Media的首席数据科学家Ben Lorica,他介绍了现在行业的现状和发展方向。
Ben Lorica提到,2010年AI学术论文和patent and invention的转化率由的8:1到2016的3:1,种种数据都表明现在AI已经加速进入了落地实施阶段。

在所有的学术论文转化中,计算机视觉方面的专利申请最多,比2011年增长24%,排在第二位和第三位的分别是自然语言处理以及语音处理。

在自然语言处理方面,涌现出现了很多开源的模型例如 ELMo, BERT, MT-DNN 和GPT-2。另外,根据O’Reilly的问卷调查,Tensorflow 和Pytorch变得十分常见,其他工具例如Nauta,Keras等等也在帮助公司进一步优化资源、流程以及建模自动化方面发挥着越来越重要的作用。

强化学习也得到越来越多的关注。O’Reilly在一项对1300个公司的问卷调查中发现,大约有1/5的公司开始着手准备或已经在使用RL强化学习。原因之一是许多的开源工具及公司开发的专有软件proprietary tools的涌现还有云服务的发展。
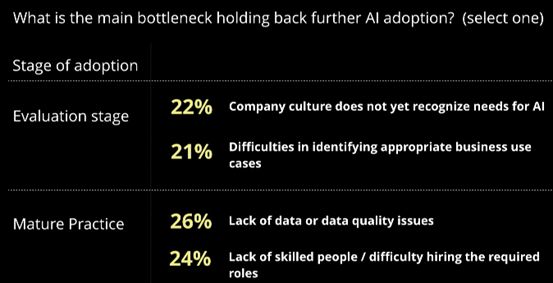
Ben Lorica还表示,不同企业的AI发展有不同的挑战,对于刚开始采用AI或还在评测考虑的企业,他们最大的瓶颈是:公司文化没有认识到AI的需求以及难以确定适当的AI业务案例。而对于AI应用和使用方面比较成熟的公司来说,他们认为缺乏足够的数据进行分析或者数据质量方面的问题与缺乏合适的人才是当前最大的瓶颈。另外,对大多数公司来说,对数据工程师和计算机基础架构人才的需求同等重要。
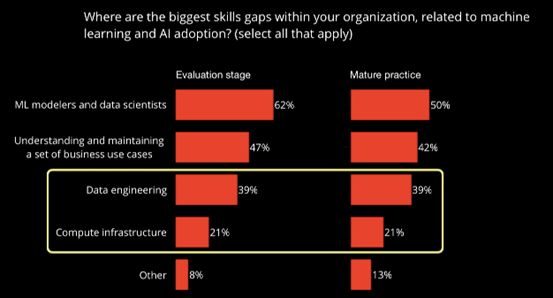
总的来说,公司应该更加关注:公平和公正、安全和可靠、隐私、安全漏洞、模型的可解释性。如果对他们排序的话,重要程度从高到低分别是:模型的可解释性以及透明度、公平以及偏见、隐私、安全和可靠性、安全漏洞。
分论坛演讲:Intel和Netflix
除了主论坛,每天下午都有5个时间段的40分钟的分论坛,第一个从午饭后开始,每场有9个可以选择,对你没有看错,会议议题就是这么的丰富!

Intel的AI产品组的副总裁Gadi Singer也在大会发表了演讲。他认为深度学习正在改变着计算,并且改变了计算带给人们和公司的价值。
越来越多的深度学习和机器学习被运用到企业里面,当前企业面对的AI应用三个常见的问题分别是:如何应用规模部署、如何推动绩效但保持管理成本以及如何应对未来所需的不确定性和变化。另外他还提到,现阶段的deep learning和AI应用是可以用CPU实现完成的。

在CPU上实现AI模型,3年时间经历了3个阶段的变化。
接下来Gadi分别聊到intel是如何帮助四家公司在图像识别、推荐系统、NLP等领域基于CPU应用人工智能和深度学习优化企业解决方案。

Philips在医疗领域的图像识别应用案例

Taboola在内容推荐系统的应用

科大讯飞的NLP应用
令文摘菌印象比较深刻的还有Netflix机器学习总监Tony Jebara介绍的Netflix如何用推荐系统给用户提供个性化的服务:除了众所周知的推荐节目,到标题的展示,到搜索功能等等。
Tony Jebara重点介绍了推荐系统是如何给用户提供个性化封面图片。什么意思呢?比如对于stranger things这部剧,如果用户对青少年题材感兴趣,那么推荐系统就会使用带有主角的处境的图片来推荐。而对恐怖题材感兴趣的用户就会见到留鼻血的这张图片作为推荐的图片。

接下来Tony进一步指出,传统机器学习batch machine learning和A/B test 的问题,还介绍了Netflix如何应用online learning来实现数据收集和学习相辅相成,并优化推荐系统。
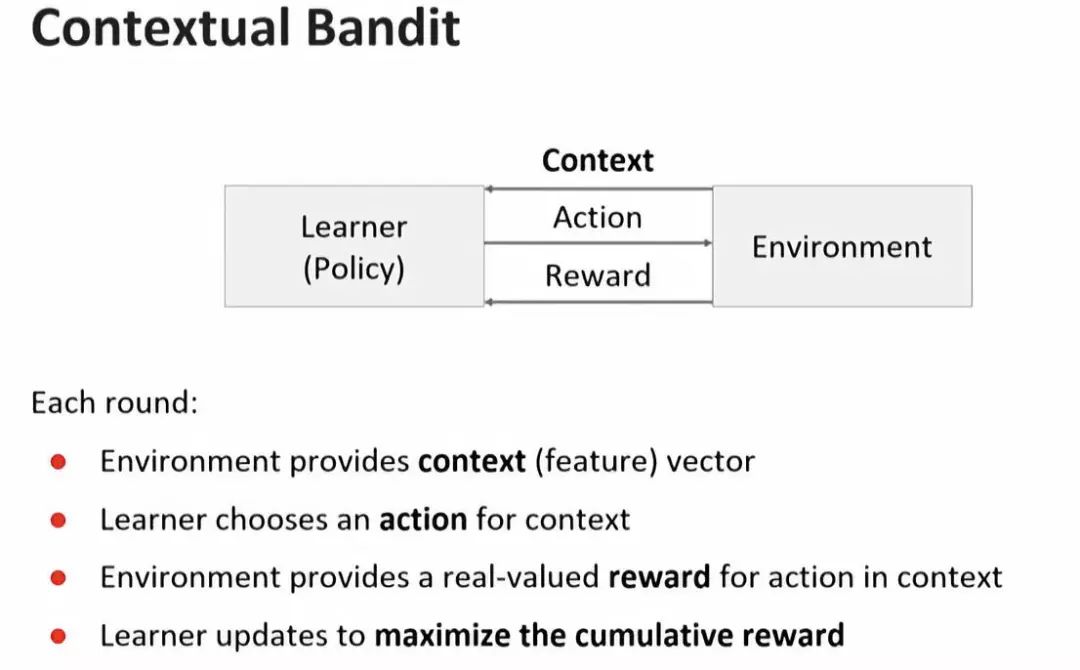
他指出,传统的监督学习和contextual bandits的不同以及netflix的图片推荐系统是如何利用online learning在更短时间内找到点击率最高的图片。


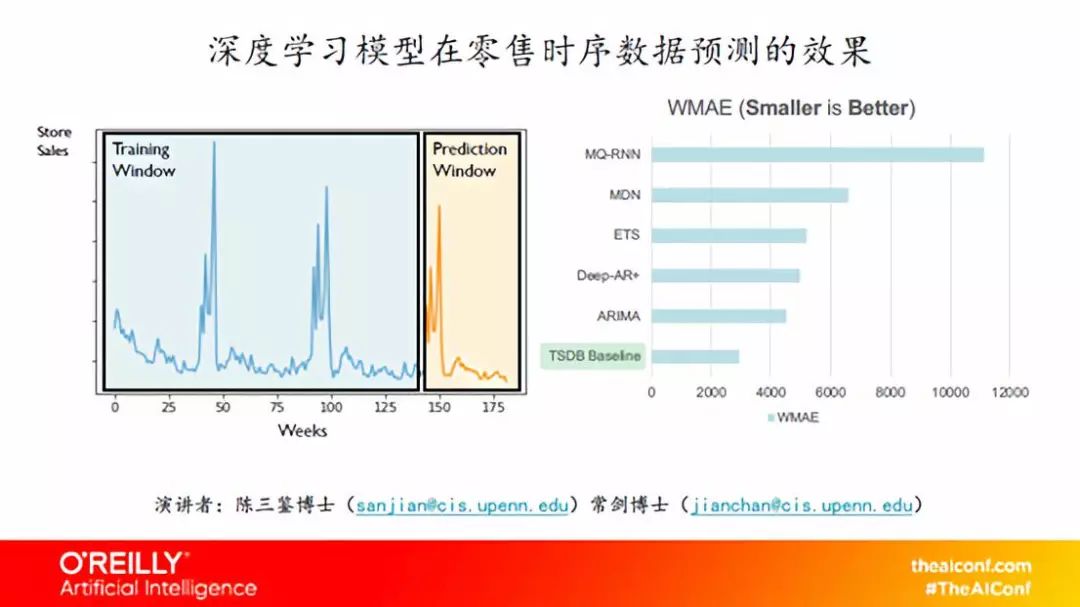
来自Alibaba硅谷研发中心的人工智能专家陈三鉴博士和常剑博士介绍了时间序列模型的特点以及AI技术在时序预测中产生的巨大效果提升,受到了现场听众的热烈反响。因为篇幅限制,我们直接与两位演讲人沟通获取到了完整版ppt,感兴趣的同学可以在大数据文摘回复“纽约”下载哦。
陈三鉴博士在做完演讲之后,在现场被提问者团团围住?

现场花絮
最近火到爆炸的BERT模型创始人之一Chang-Ming Wei也受邀来到现场介绍BERT模型。?

Dr. Chang-Ming Wei 先简单介绍了现阶段的几种比较受欢迎的NLP模型包括Word embeddings, ELMO等,指出现阶段模型的不足之处。接着详细讲解了BERT 这种双向编码器连接(transformer blocks)是如何打破了前几个模型的纪录。并着重介绍pretraining 和 fine-tuning两个BERT的训练步骤,他指出这两者的区别在于pretraining是用大量的没有标签的数据(unlabel)完成的,而后者是用少量的针对特定任务的标签数据(task-specific label data)完成的。如果小伙伴对BERT感兴趣可以参见我们前两天发的另外一篇科普文哦~link is here。
大会从第三天开始,也开启了现场展位。各个booth前都热闹非常,企业和各公司都很想借助这个机会更多了解不同的service provider和不同类型的服务,以及如何借力AI使公司进一步发展。

H20.ai的现场展位?熟悉kaggle竞赛的小伙伴应该都知道H2Oai有好几位grandmaster的加持,并且他们的xx产品是号称“brings you the intelligence of a Kaggle Grandmaster in a box(拥有xx产品你就拥有了世界顶级的数据科学家)。”

文摘菌在参会过程中也和参会者们聊了聊,基本都是来自业内顶级公司的技术从业者。各大公司当然也不会放弃这么好的招人机会,现场黑板留言区满满的招聘信息?

大会现场文摘菌还偶遇了不少大咖,包括Deep Learning Cookbook一书的作者Douwe Osinga,并且请他为大数据文摘的读者们签了个名?

最后,这次峰会的部分精彩演讲已经被主办方放上官网啦,对keynote感兴趣的小伙伴可以通过下面的网址注册会员观看!
https://learning.oreilly.com/home/
部分精彩演讲如下:
主题:Machine learning for personalization
演讲人:Tony Jebra(Columbia Univerisity| netflix)
主题:Fast,Flexible and functional: 4 real world AI deployment at enterprise scale
演讲人:Gadi Singer (Intel)
主题:Software 2.0 & snorkel
演讲人:Christopher Re(Stanford University | Apple)
推荐理由:christopher提出训练数据(training data)是software 2.0的替代品以及通过编程抽象使用各种特征的训练数据
主题:AI and the robotics revolution
演讲人:Martial Hebert (Carnegie Mellon University)
推荐理由: AI在机器人领域面临的当前挑战,以及对当前研究中出现的发展
主题:Automation of AI: Accelerating the AI revolution
演讲人:Ruchir Puri (IBM)
推荐理由:AI自!动!化!也就是可以自动完成构建、部署、管理AI的AI!
另外,O’Reilly AI Conference在今年6月份也要来北京啦,不用飞到纽约就能直接体验这个超棒的会议,学习先进的行业知识与顶尖的AI科技公司0距离接触哦~届时大数据文摘作为合作媒体会将会为大家带来最新的资讯。
AI Conference 2019北京大会
讲师明星阵容!

参会指南
请点击 阅读原文 登录会议官网查看已公布的部分讲师和议题,以及早期优惠门票价格等详情。
会议内容将持续更新,请大家关注O'Reilly官网及公众号。
早期优惠门票将于5月10日结束。

这篇关于O'Reilly AI Conference纽约站 “游记”:AI应用加速落地,强化学习更受关注的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




