本文主要是介绍数据分析案例-基于服饰行业中消费者行为和购物习惯的可视化分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.导入数据
5.数据可视化
6.总结
文末推荐与福利
1.项目背景
随着电子商务的快速发展,消费者的购物行为和购物习惯已经发生了显著的变化,特别是在服饰行业。传统的实体店购物方式已逐渐演变成在线购物的方式,这为消费者提供了更多的选择和便利。同时,社交媒体和在线评论等因素也开始在购物过程中扮演越来越重要的角色。这一变革背后涵盖了众多的因素和关键驱动力,包括但不限于:
-
社交媒体影响: 消费者通过社交媒体平台分享他们的购物经验、产品评价和时尚趋势。这些分享可以对其他消费者的购物决策产生重大影响,因此成为了一个重要的市场推动因素。
-
在线评论的重要性: 消费者越来越依赖在线评论来了解产品质量、时尚趋势和品牌声誉。这些评论可以在一定程度上决定他们是否购买某个服饰产品。
-
移动应用的普及: 移动应用的广泛使用使得消费者能够轻松地浏览商品、比较价格、查找折扣和下订单。这为购物提供了极大的便利。
-
个性化推荐: 基于消费者的历史购物记录和喜好,电子商务平台可以提供个性化的商品推荐,以提高销售和用户满意度。
-
快速时尚和可持续时尚: 消费者对时尚的需求不断演变,他们更加关注可持续性和环保因素,这对服饰行业的供应链和产品设计提出了新的挑战。
综上所述,服饰行业中的消费者行为和购物习惯已经经历了巨大的变革。为了更好地理解这些变化,需要进行可视化分析,以深入研究消费者在购物决策中的行为和趋势。这种分析可以帮助品牌和零售商更好地满足消费者需求,提高他们的市场竞争力。因此,本实验旨在借助可视化分析工具,深入探讨服饰行业中的消费者行为和购物习惯,以便制定更精准的市场策略和决策。
2.数据集介绍
本次实验数据集来源于kaggle,原始数据集共有3900条,18个变量,各变量含义解释如下:
Customer ID:分配给每个客户的唯一标识符,有助于跟踪和分析他们随时间的购物行为。
Age:客户的年龄,为细分和有针对性的营销策略提供人口统计信息。
Gender:客户的性别认同,是影响产品偏好和购买模式的关键人口变量。
Item Purchased:客户在交易过程中选择的特定产品或商品。
Category:所购买商品所属的大致分类或组(例如服装、电子产品、杂货)。
Purchase Amount (USD):交易的货币价值,以美元 (USD) 表示,表示所购买商品的成本。
Location:购买的地理位置,提供对区域偏好和市场趋势的洞察。
Size:所购商品的尺码规格(如果适用),与服装、鞋类和某些消费品相关。
Color:与购买的商品相关的颜色变体或选择,影响客户偏好和产品可用性。
Season:购买商品的季节相关性(例如春季、夏季、秋季、冬季),影响库存管理和营销策略。
Review Rating:客户对所购商品的满意度提供的数字或定性评估。
Subscription Status:指示客户是否选择了订阅服务,从而深入了解他们的忠诚度水平和经常性收入的潜力。
Shipping Type:指定用于交付所购商品的方法(例如,标准运输、快递),影响交付时间和成本。
Discount Applied:表示购买时是否应用了任何促销折扣,揭示了价格敏感性和促销效果。
Promo Code Used:记录交易过程中是否使用了促销代码或优惠券,有助于评估营销活动的成功。
Previous Purchases:提供有关客户先前购买的数量或频率的信息,有助于客户细分和保留策略。
Payment Method:指定客户采用的付款方式(例如信用卡、现金),提供对首选付款选项的深入了解。
Frequency of Purchases:表示客户参与购买活动的频率,是评估客户忠诚度和终身价值的关键指标。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
import numpy as np
import pandas as pd
import seaborn as sns
import plotly.express as px
import matplotlib.pyplot as plt
from matplotlib import style
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')df = pd.read_csv('shopping_behavior_updated.csv')
df.head(5)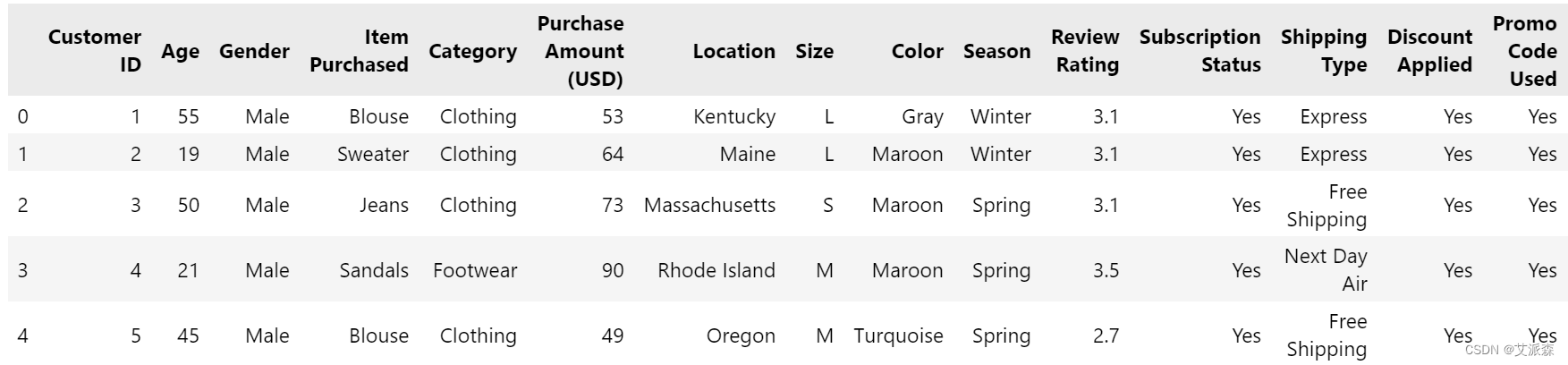
df.shape
df.info()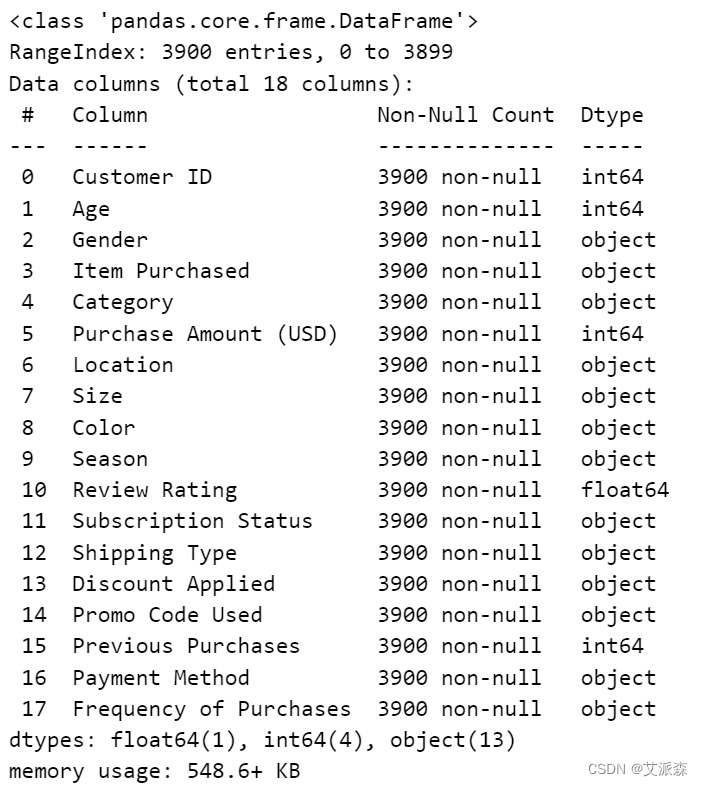
location_counts = df["Location"].value_counts()
print("Location Counts:\n", location_counts)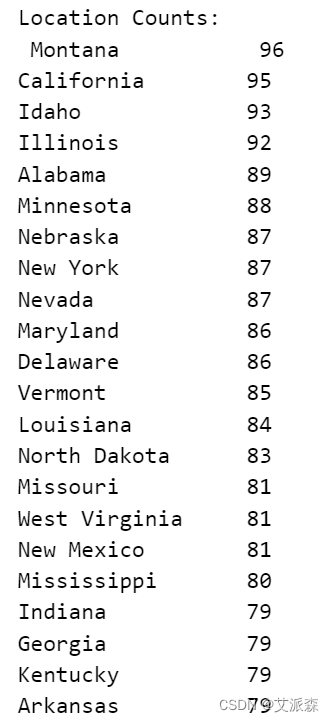
df.describe()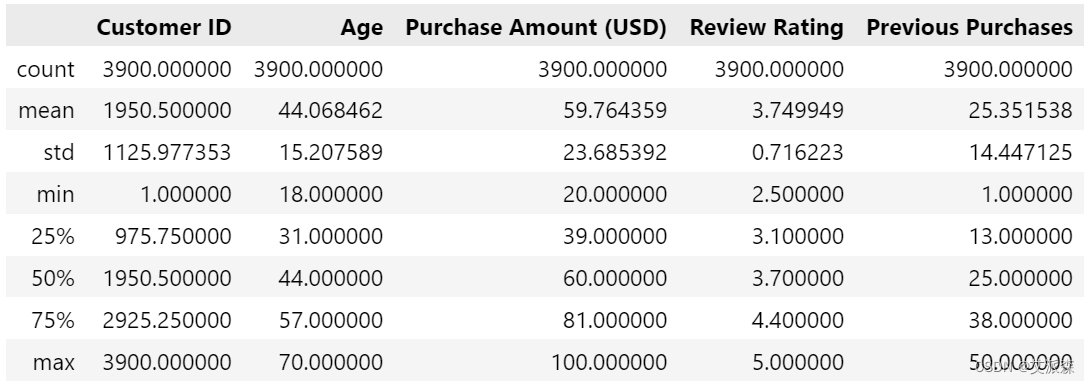
df.describe(include='O')
location_groups = df.groupby("Location")# 分析区域趋势
for location, location_data in location_groups:print(f"Regional Trends for {location}:")# 计算该地区的平均购买量avg_purchase_amount = location_data["Purchase Amount (USD)"].mean()print(f"Average Purchase Amount: ${avg_purchase_amount:.2f}")# 统计一下该地区最受欢迎的产品类别popular_categories = location_data["Category"].value_counts().idxmax()print(f"Most Popular Category: {popular_categories}")# 分析网上购物偏好online_shopping = location_data["Shipping Type"].apply(lambda x: "Online" if "Express" in x or "Standard" in x else "Offline")online_percentage = (online_shopping.value_counts() / len(online_shopping)) * 100print(f"Online Shopping Preference:")print(online_percentage)print("\n")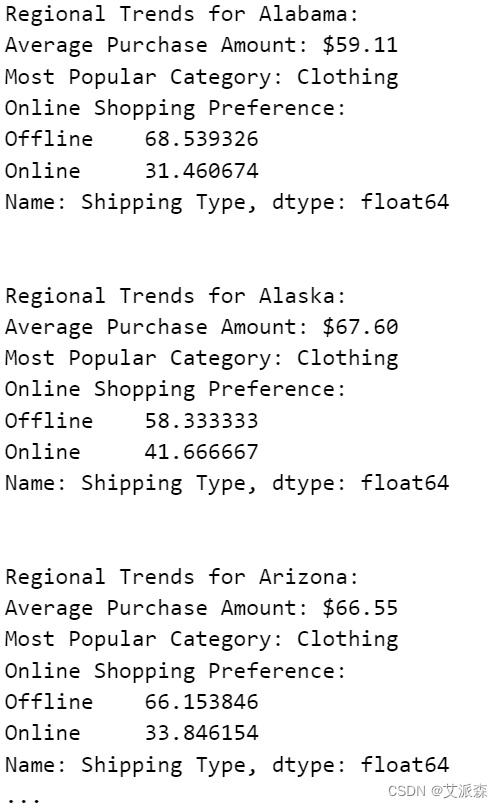
在阿拉斯加,购物者对服装表现出强烈的偏好,平均支出为67美元,在服装类别中是最高的。这表明了对质量和风格的独特偏好,反映了阿拉斯加独特的消费者行为和市场趋势。
5.数据可视化
seasons = df['Season'].unique()
average_purchase_by_season = df.groupby('Season')['Purchase Amount (USD)'].mean()plt.figure(figsize=(6, 4))
plt.bar(seasons, average_purchase_by_season, color=['skyblue', 'lightcoral', 'lightgreen', 'lightpink'])
plt.title("Impact of Season on Purchase")
plt.xlabel("Season")
plt.ylabel("Average Purchase (USD)")
plt.show()
从视觉上我们可以看出,消费者在冬季和秋季的购买量比春季和夏季的购买量要多。
plt.figure(figsize=(6, 4))
sns.barplot(x='Category', y='Purchase Amount (USD)', data=df, ci=None, palette='viridis')
plt.title("Impact of Category on Purchase")
plt.xticks(rotation=45)
plt.show()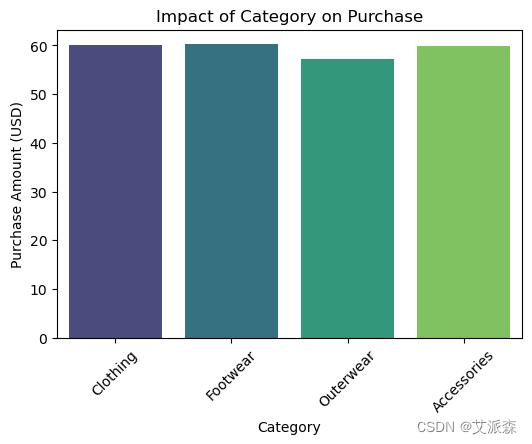
图表显示,外套类别比其他类别略低。
gender_purchase = df.groupby('Gender')['Purchase Amount (USD)'].sum()
fig, ax = plt.subplots(figsize=(8, 4))
ax.pie(gender_purchase, labels=gender_purchase.index, autopct='%1.1f%%', startangle=140, colors=['skyblue', 'yellow'], wedgeprops=dict(width=0.4))
ax.set_title("Impact of Gender on Purchase")
plt.axis('equal')
center_circle = plt.Circle((0,0),0.70,fc='white')
fig.gca().add_artist(center_circle)
plt.show()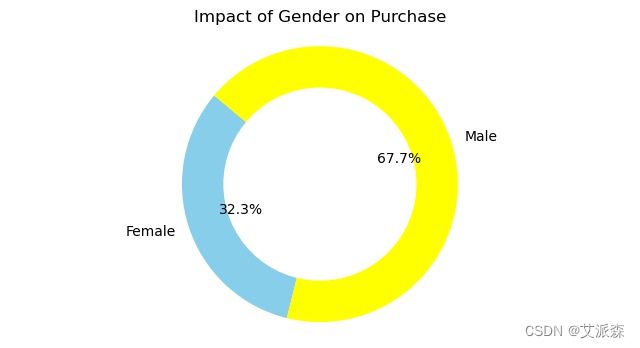
男性更愿意花钱(67%),而女性更不愿意花钱(32%)。
plt.figure(figsize=(6, 4))
sns.swarmplot(x='Size', y='Purchase Amount (USD)', data=df, palette='Set2')
plt.title("Impact of Size on Purchase")
plt.xlabel('Size')
plt.ylabel('Purchase Amount (USD)')
plt.xticks(rotation=45)
plt.show()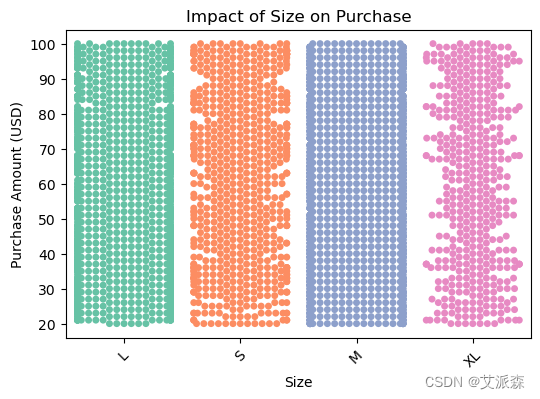
如图所示,小号的购买量低于大号、小号和中号的购买量。
promo_counts = df['Promo Code Used'].value_counts()
plt.figure(figsize=(6, 4))
plt.pie(promo_counts, labels=promo_counts.index, autopct='%1.1f%%', startangle=140, colors=['lightgreen', 'lightcoral'])
plt.title("Impact of Promo Code Used on Purchase")
plt.axis('equal')
plt.show()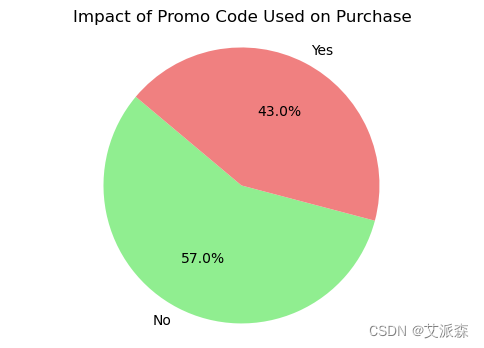
正如我们所看到的,在购买时使用Promocode没有这样的影响。
让我们来分析一下顾客的位置(年龄和性别)和他们的购买行为之间的关系。
location_counts.plot(kind="bar", figsize=(12, 4))
plt.title("Customer Distribution by Location")
plt.xlabel("Location")
plt.ylabel("Number of Customers")
plt.show()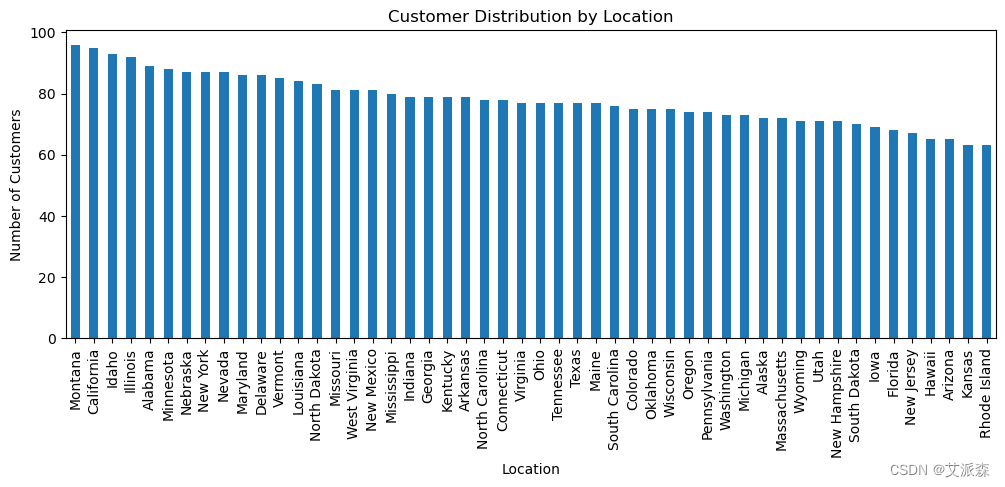
蒙大拿州以其惊人的客户数量脱颖而出,在这方面超过了所有其他州。该州蓬勃发展的商业环境和充满活力的消费市场为其令人印象深刻的客户群做出了贡献。
category_counts = df['Category'].value_counts()
colors = ['skyblue', 'lightcoral', 'lightseagreen', 'lightsalmon', 'lightpink']
plt.figure(figsize=(10, 6))
ax = plt.gca()
bars = plt.bar(category_counts.index, category_counts.values, color=colors)
plt.xlabel('Product Categories')
plt.ylabel('Count')
plt.title('Distribution of Product Categories')
plt.xticks(rotation=90)
plt.tight_layout()
legend_labels = category_counts.index[:len(colors)]
legend = plt.legend(bars[:len(colors)], legend_labels, title='Categories', loc='upper right')
plt.setp(legend.get_title(), fontsize=12)
plt.show()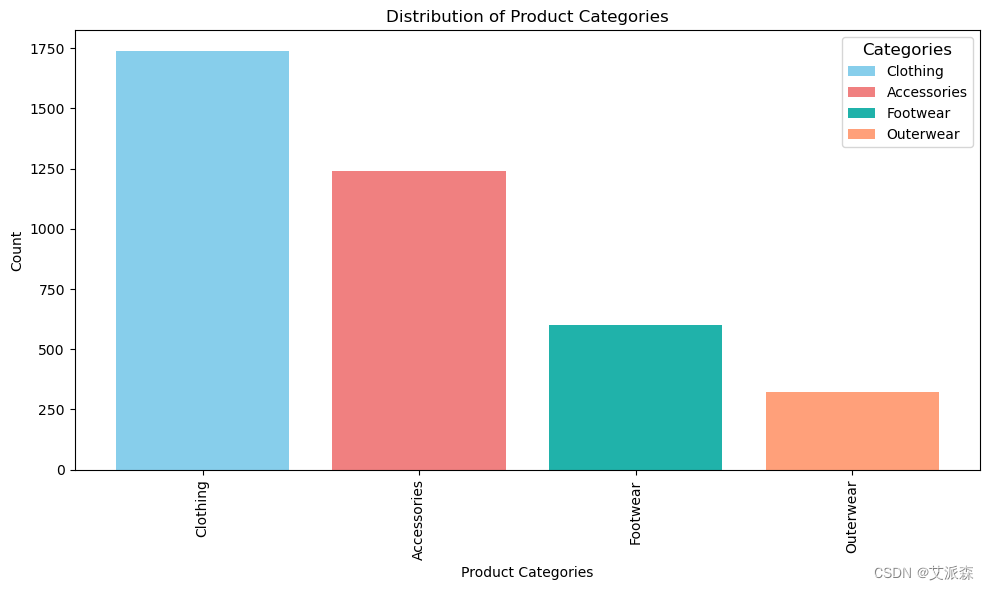
正如我们所看到的,服装类是最受消费者欢迎的。让我们来看看在排名前五的状态中,谁在这一类别中花费最多。
top_locations = df['Location'].value_counts().head(5).index
colors = ['#98FB98', '#FFE5CC', '#FFCCFF', '#CCE5FF', '#9467bd', '#8c564b', '#e377c2', '#7f7f7f', '#bcbd22', '#17becf']
fig, axes = plt.subplots(5, 1, figsize=(10, 15))
for i, location in enumerate(top_locations):location_data = df[df['Location'] == location]category_counts = location_data['Category'].value_counts().head(10)ax = axes[i]category_counts.plot(kind='bar', ax=ax, color=colors)ax.set_title(f"Categories in {location}")ax.set_xlabel("Category")ax.set_ylabel("Count")ax.set_xticklabels(category_counts.index, rotation=45)ax.grid(axis='y', linestyle='--', alpha=0.7)plt.tight_layout()
plt.show()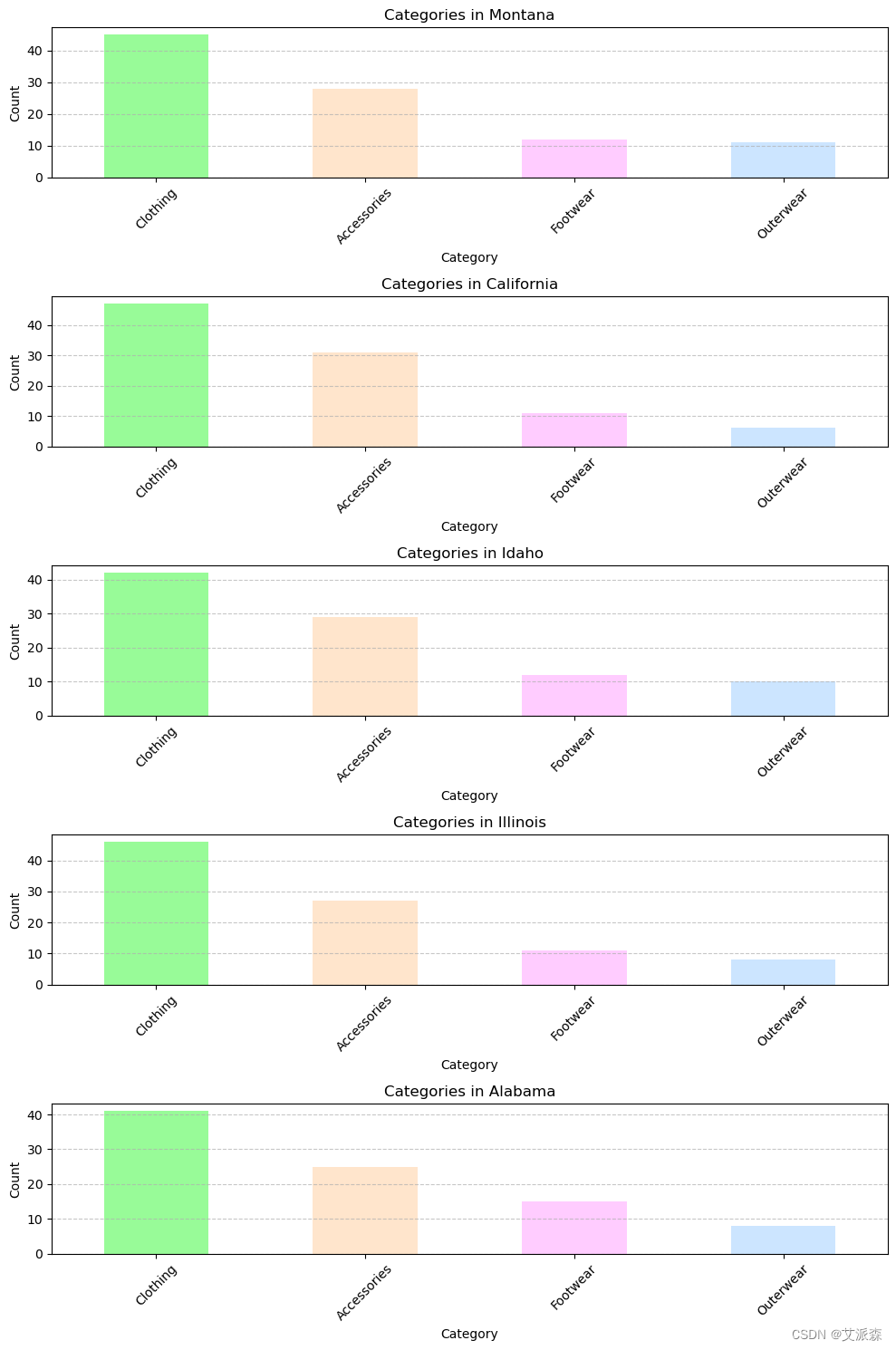
正如我们所看到的,蒙大拿州、加利福尼亚州、爱达荷州、伊利诺伊州和阿拉巴马州是服装支出最高的五个州。
age_groups = [15, 25, 35, 45, 55, 65]
fig, ax = plt.subplots(figsize=(14, 6))
colors = plt.cm.viridis(np.linspace(0, 1, len(age_groups)))
category_counts_by_age = {age: [] for age in age_groups}
for age in age_groups:age_group_data = df[(df['Age'] >= age) & (df['Age'] < age + 10)]category_counts = age_group_data['Category'].value_counts()category_counts_by_age[age] = category_countswidth = 0.15
x = np.arange(len(category_counts_by_age[age_groups[0]].index))
for i, age in enumerate(age_groups):category_counts = category_counts_by_age[age]ax.bar(x + i * width, category_counts, width=width, label=f'{age}-{age+10}', color=colors[i])ax.set_xlabel('Product Categories')
ax.set_ylabel('Count')
ax.set_title('Category Distribution by Age Groups')
ax.set_xticks(x + width * (len(age_groups) - 1) / 2)
ax.set_xticklabels(category_counts_by_age[age_groups[0]].index, rotation=45)
ax.legend(title='Age Group')
plt.tight_layout()
plt.show()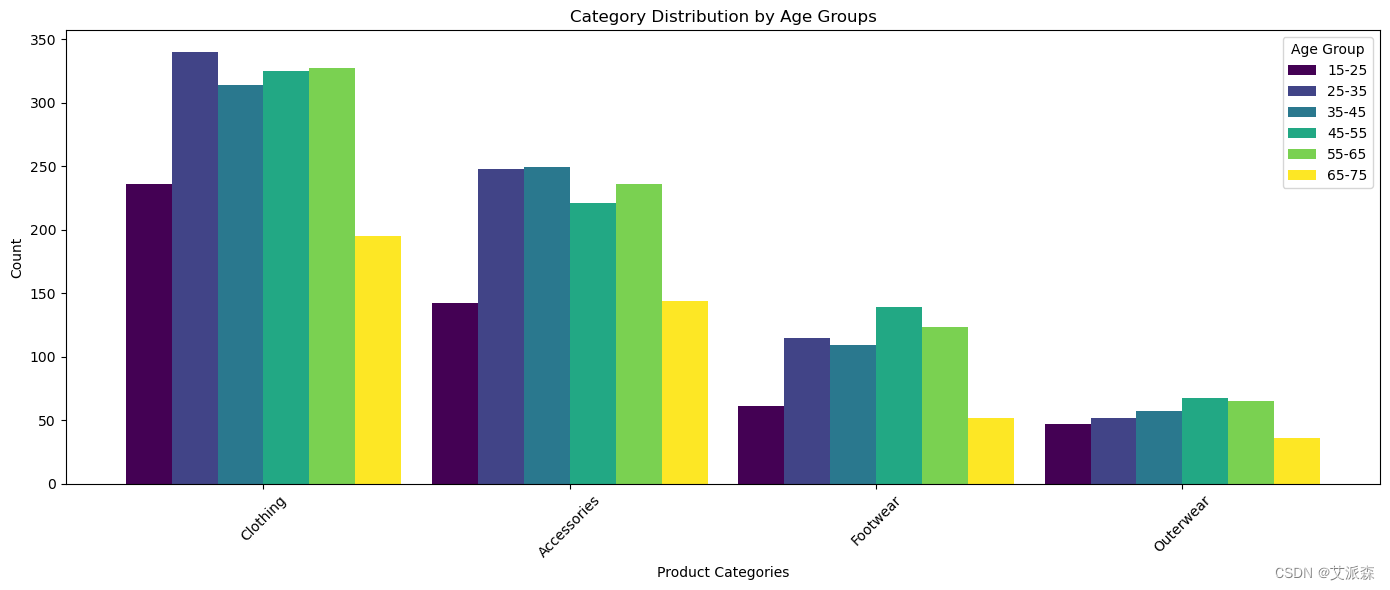
正如我们所看到的,服装是所有年龄组中最受欢迎的类别。除了15-25岁和65-75岁年龄段外,所有年龄段的配饰都同样出名。然而,我们已经看到,在鞋类类别中,45-55岁年龄组的人最出名。外套在所有年龄组中几乎同样出名。
6.总结
通过前面的数据可视化,我们可以得出以下结论:
- 与春夏相比,消费者往往在冬季和秋季购买更多的东西。
- 与其他品类相比,外衣品类的购买量略低,这表明有可能改进的领域。
- 男性占总消费的67%,而女性占32%。
- 与大号、小号和中号等其他尺码相比,超大号的购买量更低。
- 促销码的使用似乎对购买行为没有显著影响。
- 蒙大拿州的顾客数量惊人,表明消费市场蓬勃发展。
- 服装是所有消费者中最受欢迎的产品类别。
- 除了15-25岁和65-75岁的人群外,配饰在各个年龄段都同样受欢迎。
- 鞋类在45-55岁年龄组中特别受欢迎。
- 外套在所有年龄组中都很受欢迎。
对顾客行为和购买数据的分析揭示了一些有价值的见解。季节变化、产品类别、性别、尺寸和促销码的使用都会影响消费者的购买决策。数据还表明,蒙大拿州拥有强大的消费市场,服装是各个年龄段的首选产品类别。这些发现可以为营销策略、产品供应和促销提供信息,以更好地瞄准和服务不同的客户群。
文末推荐与福利
《AI时代系列》4选1免费包邮送出3本!

内容简介:
在AI时代,程序员面临着新的机遇和挑战。为了适应这个快速发展的时代,掌握新技能并采取相应的应对策略是至关重要的。
对于办公人员或程序员来说,利用AI可以提高工作效率。例如,使用AI助手可以帮助自动化日常的重复性工作,如邮件筛选、日程安排等。此外,AI还可以用于数据分析和预测,帮助办公人员更好地做出决策和规划。
AI时代系列书籍:《AI时代程序员开发之道:ChatGPT让程序员插上翅膀》《AI时代项目经理成长之道:ChatGPT让项目经理插上翅膀》《AI时代产品经理升级之道:ChatGPT让产品经理插上翅膀》《AI时代架构师修炼之道:ChatGPT让架构师插上翅膀》由北京大学出版社出版,一套专注于帮助程序员在AI时代实现晋级、提高效率的图书。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-11-8 20:00:00
《AI时代程序员开发之道:ChatGPT让程序员插上翅膀》
京东购买链接:https://item.jd.com/13816183.html
《AI时代项目经理成长之道:ChatGPT让项目经理插上翅膀》
京东购买链接:https://item.jd.com/14129232.html
《AI时代产品经理升级之道:ChatGPT让产品经理插上翅膀》
京东购买链接:https://item.jd.com/14194202.html
《AI时代架构师修炼之道:ChatGPT让架构师插上翅膀》
京东购买链接:https://item.jd.com/13897131.html
名单公布时间:2023-11-8 21:00:00

这篇关于数据分析案例-基于服饰行业中消费者行为和购物习惯的可视化分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







