本文主要是介绍Python爬虫爬取铁路列车时刻表数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、爬虫简介
- 二、列车时刻表数据简介
- 三、本文列车时刻表爬取网站介绍
- 1、网站介绍
- 2、列车时刻表数据爬取网页
- 四、时刻表数据爬取操作
- 1、Selenium库和Chromedriver的准备
- 2、网页获取
- 3、数据定位
- 4、获取表格数据的行数列数
- 5、数据输出
- 五、完整代码
一、爬虫简介
爬虫,也称作网络爬虫或网页爬虫,是一个自动化程序,其目的是在互联网上按照一定的规则抓取网页内容。爬虫的工作原理如下:
1、初始化URL列表:开始时,爬虫需要知道从哪些网页开始抓取,所以通常有一个初始的URL列表。
2、发送请求:爬虫向这些URL发送HTTP请求,获取网页内容。
3、内容解析:一旦获得网页内容,爬虫会解析这些内容。常用的解析方法有正则表达式、HTML解析库、CSS选择器等。
4、数据提取:从解析后的内容中,提取有用的数据。例如,可能提取出新闻文章的标题、内容、发布时间等。
5、数据存储:将提取的数据保存到某个位置,如数据库、文件或其他存储系统中。
6、发现新的URL:在解析网页内容的过程中,爬虫会找到其他的URL链接,这些新链接会被添加到待爬取的URL列表中,以供后续爬取。
7、循环:爬虫不断重复上述过程,直到满足某些终止条件,如爬取的页数达到上限、已爬取的内容不再有新增等。
爬虫的使用场景包括:搜索引擎的数据索引、数据挖掘、网站备份、研究与分析等。
二、列车时刻表数据简介
列车时刻表数据主要描述了列车在不同站点的到达和离开时间,它是旅客和铁路系统日常操作的重要信息来源。具体来说,列车时刻表数据主要包括以下内容:
1、列车编号/名称:用于唯一标识一个列车。
2、起始站和终点站:描述了列车的起点和终点。
3、经停站:列车在行程中会停靠的所有站点。
4、到达时间和离开时间:对于每一个经停站,都会有对应的到达时间和离开时间。
5、车次类型:例如高速、快速、普通等。
列车时刻表数据的用途主要有:
1、乘客查询和购票:乘客可以查询特定列车的运行时间、经停站点、票价等信息,以便于购买车票和规划行程。
2、铁路系统调度:铁路系统需要知道各列车的行驶时间和经停站,以便进行调度和避免列车间的冲突。
统计分析:可用于分析旅客流量、车站拥挤程度、运输效率等,从而进行优化和决策。
3、故障处理:当铁路系统出现故障时,可以快速查询受影响的列车,进行调整和通知。
4、旅行规划应用:第三方应用或网站可以利用列车时刻表数据,为乘客提供旅行规划、旅行提醒等服务。
总的来说,列车时刻表数据是铁路交通系统中的核心数据,它为乘客提供便利,同时也是铁路系统日常运营和管理的基础。
三、本文列车时刻表爬取网站介绍
1、网站介绍
网站网址:https://www.chalieche.com/
该网站的初始界面如下所示:
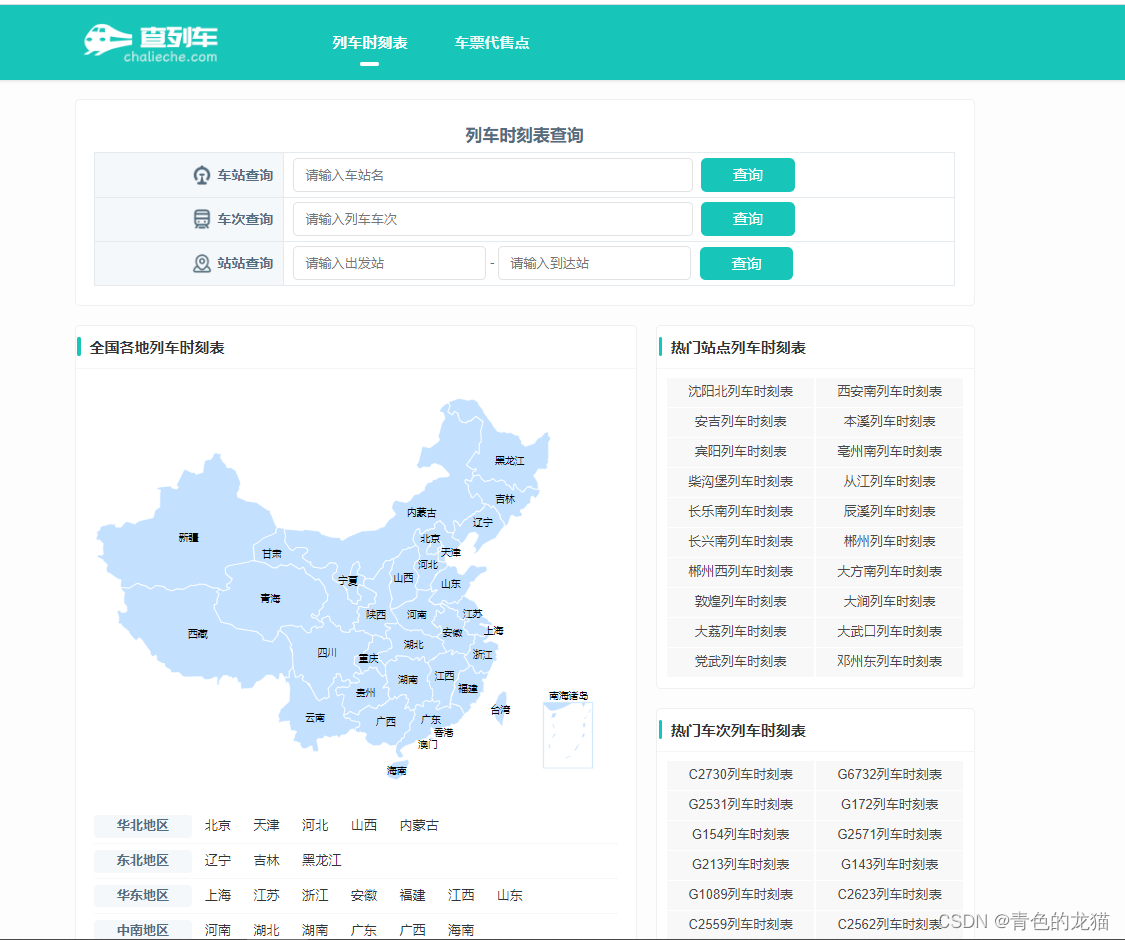
根据与12306列车时刻表信息比对,该网站包含的列车时刻表信息完整,并且含有已停运列车的信息。
2、列车时刻表数据爬取网页
我们随机打开一个列车时刻表的页面,如下所示:
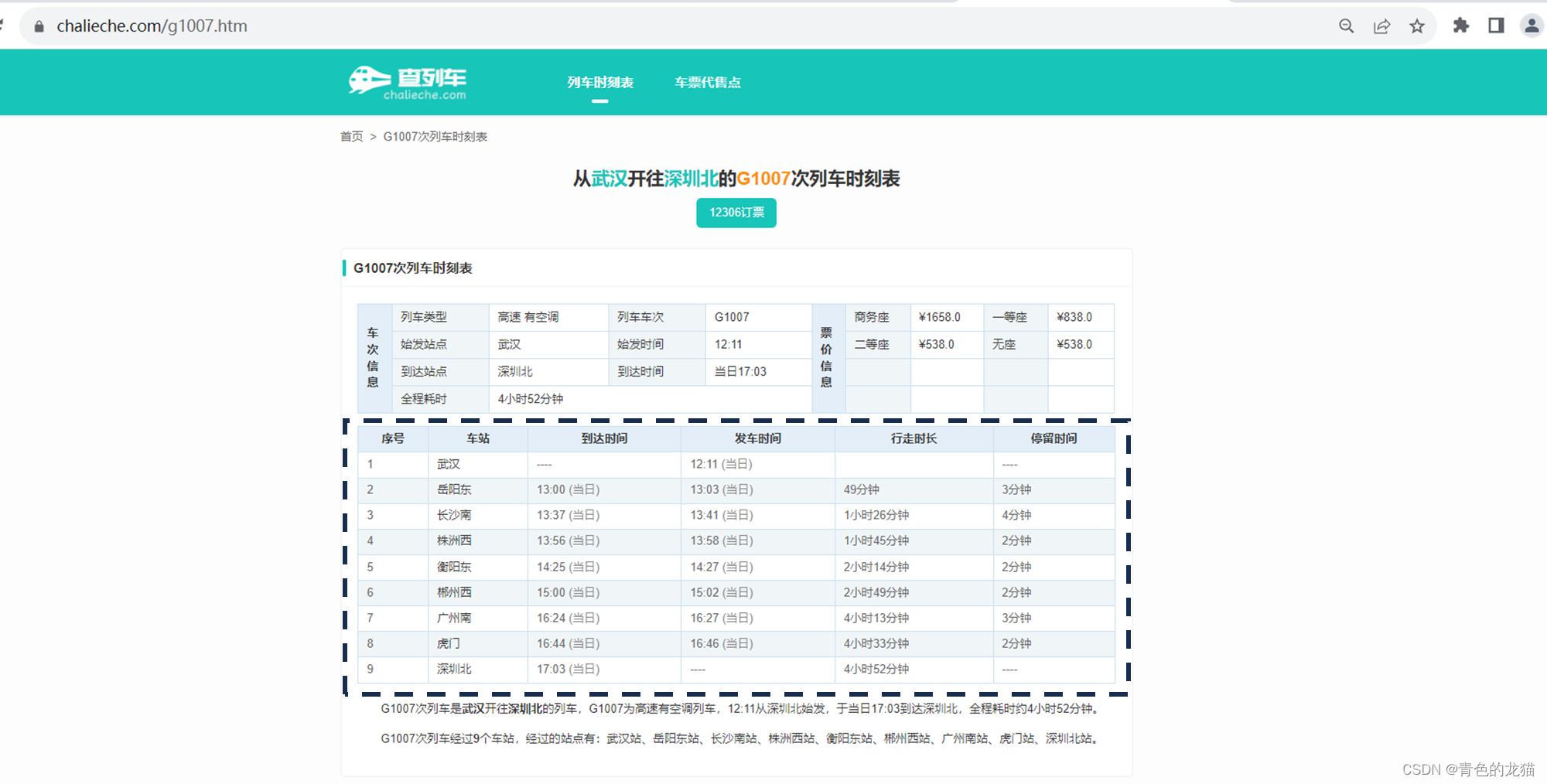
观察发现,该网页共有3个表格,分别对应 G1007次列车的车次信息、票价信息以及时刻表,在该文中,我们主要想要获取的是车辆的时刻表信息,也就是虚线框部分的信息。
根据获取的相关信息,该网站的拥有数据的列车类型如下所示:
数字:普通旅客列车
C开头:城际列车(Inter-City Rail Service)即城际专列车
D开头:动车组列车
G开头:高铁
K开头:快速旅客列车
S开头:市郊列车
T开头:特快旅客列车
Z开头:直达特快旅客列车
四、时刻表数据爬取操作
本文的数据爬取操作是通过Selenium库结合Chromedriver在谷歌浏览器中对该网站的数据进行爬取,小伙伴在进行相应的操作前别忘了对相应的库进行下载和安装以及环境的配置哈!
1、Selenium库和Chromedriver的准备
这两个库是本文数据爬取的核心,具体方法小伙伴可自行搜索,这里附上可借鉴的安装操作链接:
Selenium库:https://pythonjishu.com/docztamzjgaryke/
Chromedriver:https://blog.csdn.net/one_bird_/article/details/131592362
2、网页获取
通过观察,我们发现网页的url如下:
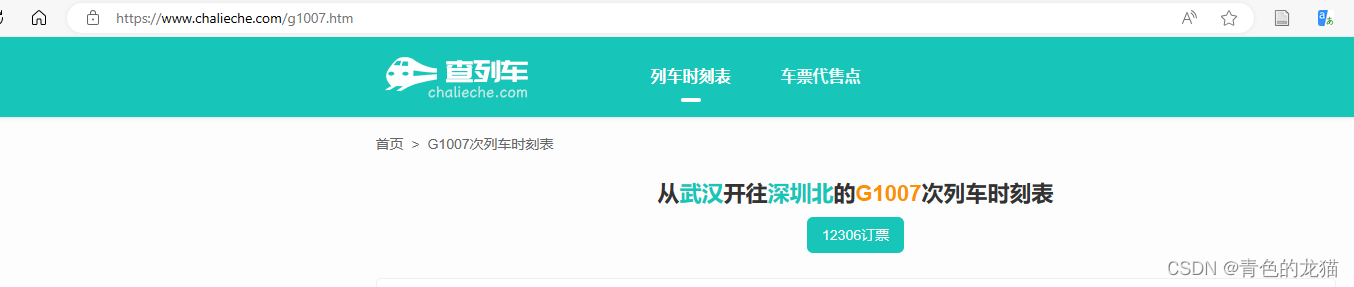
可以发现,该url除了最后是列车车次号以外,其余均保持一致,因此我们也可以通过获取到的车次号循环获得不同车次号的列车时刻表。
进入网页的代码如下所示:
url = f'https://www.chalieche.com/g1007.htm'
chrome_options = Options()
chrome_options.add_argument("--headless") ##无头网页with webdriver.Chrome(options=chrome_options) as driver:driver.get(url)
3、数据定位
在进入网页后,我们需要通过一些特定的方法让代码查找我们想要的数据,首先,我们需要通过F12观察网页的源码,如下所示:
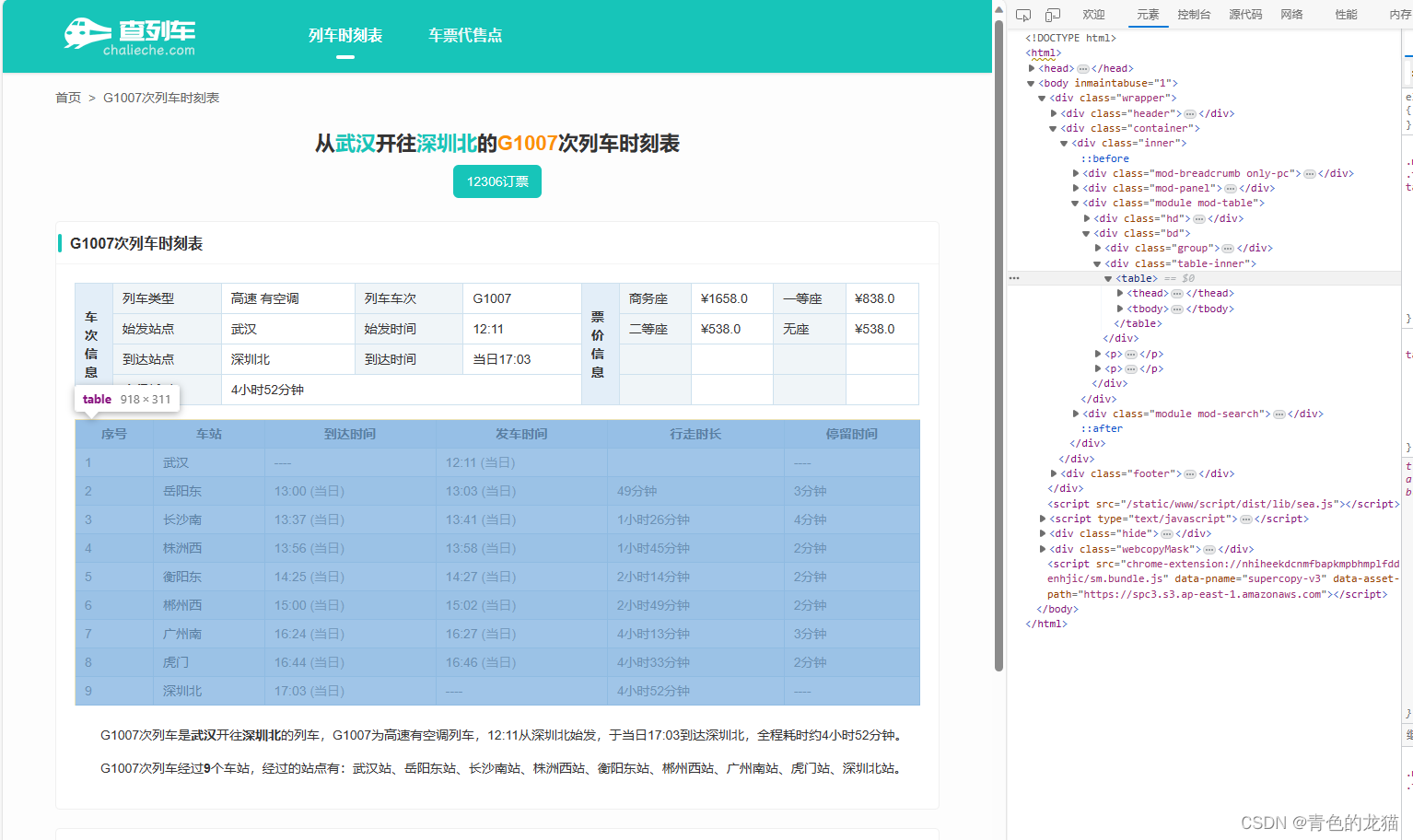
可以发现,这个table就是我们想要获取的数据表格,本文主要通过driver.find_element方法定位数据位置并获取数据,该函数的具体功能可自行去官方网站查阅。
由于文本数据的特殊性,我们通过driver.find_element中的By.XPATH定位到表格中特定行特定列的数据,获取后依次写入csv文件中。
如何获取自己想要的XPATH路径呢?在网页中通过定位鼠标定位到数据在网页源码中的位置,点击鼠标右键→点击复制→复制XPATH,如下所示:
 粘贴后得到的XPATH如下所示:
粘贴后得到的XPATH如下所示:
/html/body/div[1]/div[2]/div/div[3]/div[2]/div[2]/table/tbody/tr[1]/td[3]
我们发现,要想获得完整表格的数据,我们需要知道表格的行数tr[]和列数td[]。
4、获取表格数据的行数列数
表格的行数我们通过获取表格text文本格式并判断其换行次数获取:
Widh = driver.find_element(By.XPATH, f'/html/body/div[1]/div[2]/div/div[3]/div[2]/div[2]/table/tbody').text # 获取文本
newline_count = Widh.count('\n') + 1 # 判断表格的行数
对于表格的列数,我们发现表格列数较为统一,案例的列数为6列,但是由于一些列车存在同一班次变号的情况(向京、离京),会存在车次号,导致表格数据会变成7列,如下所示:
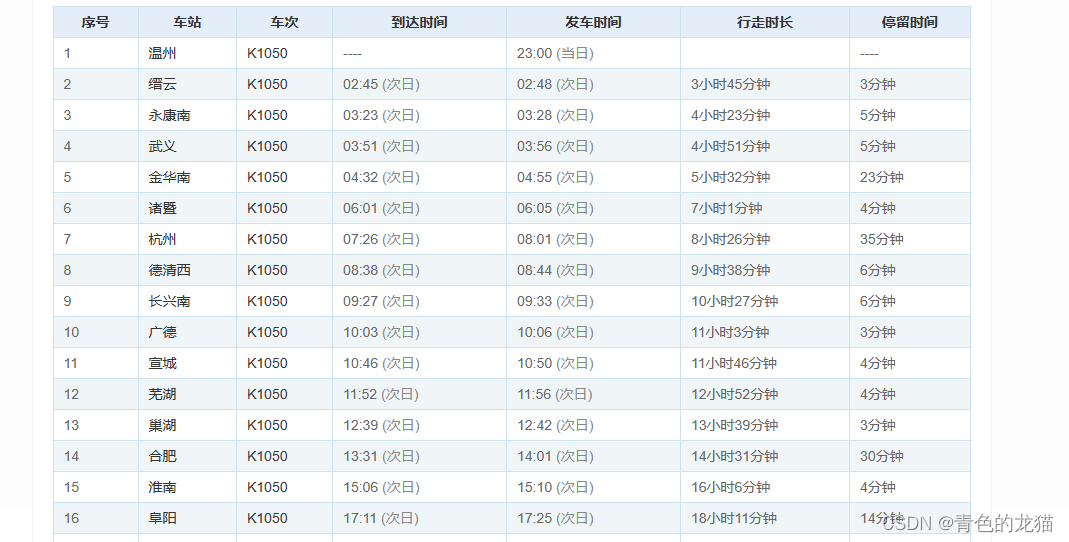
因此,我们通过判断第一行标题列字符的长度来区分这两种情况,代码如下所示:
header_columns = driver.find_element(By.XPATH,'/html/body/div[1]/div[2]/div/div[3]/div[2]/div[2]/table/thead/tr').text
print(len(header_columns)) # 判断表格的列数,若为25则是6列,为28则为7列(车次列)if (len(header_columns) == 25): ##6列,没有车次方向else: ##为28,7列,有车次5、数据输出
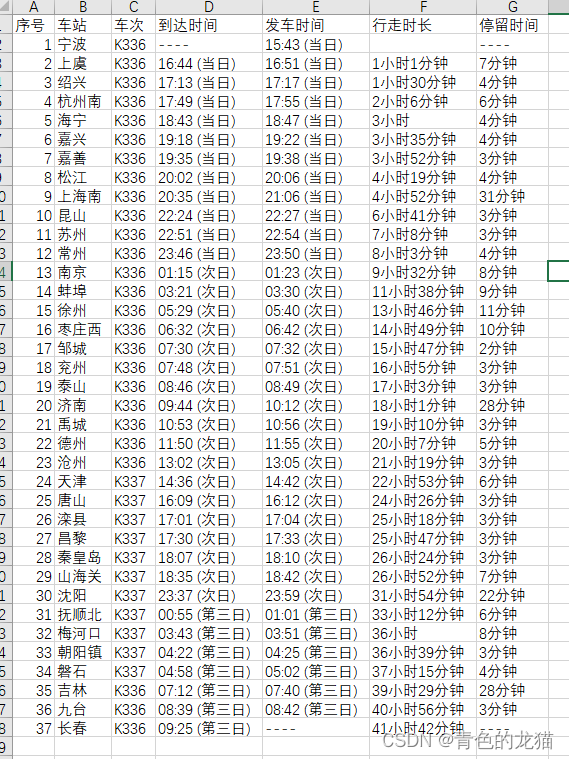
在获取表格行列数据后,我们通过循环依次将数据写入csv文件中并输出,得到结果如下图所示:
五、完整代码
完整的数据爬取代码如下所示:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import pandas as pd
import wcwidthtrain_list = pd.read_csv('车次表.csv')
#print(type(train_list['车次'][0]))
list1 = []
list2 = []
for i in range(len(train_list)):#print(train_list['车次'][i])train = train_list['车次'][i]print(train)url = f'https://www.chalieche.com/{train}.htm'print(url)chrome_options = Options()chrome_options.add_argument("--headless")with webdriver.Chrome(options=chrome_options) as driver:driver.get(url)Widh = driver.find_element(By.XPATH, f'/html/body/div[1]/div[2]/div/div[3]/div[2]/div[2]/table/tbody').text # 获取文本newline_count = Widh.count('\n') + 1 # 判断表格的行数header_columns = driver.find_element(By.XPATH,'/html/body/div[1]/div[2]/div/div[3]/div[2]/div[2]/table/thead/tr').textprint(len(header_columns)) # 判断表格的列数,若为25则是6列,为28则为7列(车次列)if (len(header_columns) == 25): ##6列,没有车次方向df = pd.DataFrame(columns=['序号', '车站', '到达时间', '发车时间', '行走时长', '停留时间'], index=range(newline_count)) # 创建一个空的dataframefor Hang in range(1, newline_count + 1):for Lie in range(1, 7):value = driver.find_element(By.XPATH, f'/html/body/div[1]/div[2]/div/div[3]/div[2]/div[2]/table/tbody/tr[{Hang}]/td[{Lie}]').text # 获取文本df.iloc[Hang - 1, Lie - 1] = valuenew_column_name = '车次'new_column_value = train # 您可以根据需要设置不同的值df.insert(loc=2, column=new_column_name, value=new_column_value)#print(df)list1.append(train)df_list1 = pd.DataFrame(list1[0:])df_list1.to_csv('按车次爬取列车时刻表数据/单向/车次.csv', index=False,encoding='utf_8_sig')df.to_csv(f'按车次爬取列车时刻表数据/单向/{train}.csv', encoding='utf_8_sig', index=None)print(f"-----------------------------------------------------{train}-----------------------------------------------------")else: ##为28,7列,有车次df = pd.DataFrame(columns=['序号', '车站', '车次', '到达时间', '发车时间', '行走时长', '停留时间'],index=range(newline_count)) # 创建一个空的dataframefor Hang in range(1, newline_count + 1):for Lie in range(1, 8):value = driver.find_element(By.XPATH,f'/html/body/div[1]/div[2]/div/div[3]/div[2]/div[2]/table/tbody/tr[{Hang}]/td[{Lie}]').text # 获取文本df.iloc[Hang - 1, Lie - 1] = value#print(df)list2.append(train)df_list2 = pd.DataFrame(list2[0:])df_list2.to_csv('按车次爬取列车时刻表数据/双向/车次.csv', index=False,encoding='utf_8_sig')df.to_csv(f'按车次爬取列车时刻表数据/双向/{train}.csv', encoding='utf_8_sig', index=None)print(f"-----------------------------------------------------{train}-----------------------------------------------------")
由于完整的车次表数据获取工作量较大,这里不做分享,想要的小伙伴可以私聊我。希望这次的分享能对大家的爬虫学习带来一点帮助!!
这篇关于Python爬虫爬取铁路列车时刻表数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




