本文主要是介绍机器学习---HMM前向、后向和维特比算法的计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. HMM
import numpy as np# In[15]:class HiddenMarkov:def forward(self, Q, V, A, B, O, PI): # 使用前向算法N = len(Q) # 状态序列的大小M = len(O) # 观测序列的大小alphas = np.zeros((N, M)) # alpha值T = M # 有几个时刻,有几个观测序列,就有几个时刻for t in range(T): # 遍历每一时刻,算出alpha值indexOfO = V.index(O[t]) # 找出序列对应的索引for i in range(N):if t == 0: # 计算初值alphas[i][t] = PI[t][i] * B[i][indexOfO]print('alpha1(%d)=p%db%db(o1)=%f' % (i, i, i, alphas[i][t]))else:alphas[i][t] = np.dot([alpha[t - 1] for alpha in alphas], [a[i] for a in A]) * B[i][indexOfO] # 递推()print('alpha%d(%d)=[sigma alpha%d(i)ai%d]b%d(o%d)=%f' % (t, i, t - 1, i, i, t, alphas[i][t]))# print(alphas)P = np.sum([alpha[M - 1] for alpha in alphas]) # 求和终止# alpha11 = pi[0][0] * B[0][0] #代表a1(1)# alpha12 = pi[0][1] * B[1][0] #代表a1(2)# alpha13 = pi[0][2] * B[2][0] #代表a1(3)print(P)def backward(self, Q, V, A, B, O, PI): # 后向算法N = len(Q) # 状态序列的大小M = len(O) # 观测序列的大小betas = np.ones((N, M)) # betafor i in range(N):print('beta%d(%d)=1' % (M, i))for t in range(M - 2, -1, -1):indexOfO = V.index(O[t + 1]) # 找出序列对应的索引for i in range(N):betas[i][t] = np.dot(np.multiply(A[i], [b[indexOfO] for b in B]), [beta[t + 1] for beta in betas])realT = t + 1realI = i + 1print('beta%d(%d)=[sigma a%djbj(o%d)]beta%d(j)=(' % (realT, realI, realI, realT + 1, realT + 1),end='')for j in range(N):print("%.2f*%.2f*%.2f+" % (A[i][j], B[j][indexOfO], betas[j][t + 1]), end='')print("0)=%.3f" % betas[i][t])# print(betas)indexOfO = V.index(O[0])P = np.dot(np.multiply(PI, [b[indexOfO] for b in B]), [beta[0] for beta in betas])print("P(O|lambda)=", end="")for i in range(N):print("%.1f*%.1f*%.5f+" % (PI[0][i], B[i][indexOfO], betas[i][0]), end="")print("0=%f" % P)def viterbi(self, Q, V, A, B, O, PI):N = len(Q) # 状态序列的大小M = len(O) # 观测序列的大小deltas = np.zeros((N, M))psis = np.zeros((N, M))I = np.zeros((1, M))for t in range(M):realT = t+1indexOfO = V.index(O[t]) # 找出序列对应的索引for i in range(N):realI = i+1if t == 0:deltas[i][t] = PI[0][i] * B[i][indexOfO]psis[i][t] = 0print('delta1(%d)=pi%d * b%d(o1)=%.2f * %.2f=%.2f'%(realI, realI, realI, PI[0][i], B[i][indexOfO], deltas[i][t]))print('psis1(%d)=0' % (realI))else:deltas[i][t] = np.max(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A])) * B[i][indexOfO]print('delta%d(%d)=max[delta%d(j)aj%d]b%d(o%d)=%.2f*%.2f=%.5f'%(realT, realI, realT-1, realI, realI, realT, np.max(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A])), B[i][indexOfO], deltas[i][t]))psis[i][t] = np.argmax(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A]))print('psis%d(%d)=argmax[delta%d(j)aj%d]=%d' % (realT, realI, realT-1, realI, psis[i][t]))print(deltas)print(psis)I[0][M-1] = np.argmax([delta[M-1] for delta in deltas])print('i%d=argmax[deltaT(i)]=%d' % (M, I[0][M-1]+1))for t in range(M-2, -1, -1):I[0][t] = psis[int(I[0][t+1])][t+1]print('i%d=psis%d(i%d)=%d' % (t+1, t+2, t+2, I[0][t]+1))print(I)if __name__ == '__main__':Q = [1, 2, 3]V = ['红', '白']A = [[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]B = [[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]# O = ['红', '白', '红', '红', '白', '红', '白', '白']O = ['红', '白', '红', '白'] #例子PI = [[0.2, 0.4, 0.4]]HMM = HiddenMarkov()
# HMM.forward(Q, V, A, B, O, PI)HMM.backward(Q, V, A, B, O, PI)
# HMM.viterbi(Q, V, A, B, O, PI)隐马尔可夫模型是一个统计模型,用于描述由隐藏的状态序列和对应的观测序列组成的系统。在这
个模型中,隐藏的状态是无法直接观测到的,而只能通过观测序列来进行推断。
前向算法(Forward Algorithm):前向算法用于计算在给定观测序列下每个时间步长处于特定状态
的概率。前向算法利用动态规划的思想,通过递推计算每个时间步的前向概率。前向概率
(alpha)的计算公式为:alpha[t][j] = sum(alpha[t-1][i] * A[i][j] * B[j][O[t]]) for i in range(N)
其中,alpha[t][j]表示在时间步t处于状态j的概率,A[i][j]表示从状态i转移到状态j的概率,B[j]
[O[t]]表示在状态j下观测到序列中的第t个观测的概率。
后向算法(Backward Algorithm):后向算法用于计算在给定观测序列下每个时间步从特定状态开始
的概率。后向算法同样利用动态规划的思想,通过递推计算每个时间步的后向概率。后向概率
(beta)的计算公式为: beta[t][i] = sum(A[i][j] * B[j][O[t+1]] * beta[t+1][j]) for j in range(N),其
中,beta[t][i]表示在时间步t从状态i开始的概率,A[i][j]表示从状态i转移到状态j的概率,B[j][O[t+1]]
表示在状态j下观测到序列中的第t+1个观测的概率,beta[t+1][j]表示在时间步t+1处于状态j的概率。
维特比算法(Viterbi Algorithm):维特比算法用于找到在给定观测序列下最可能的隐藏状态序列。
维特比算法利用动态规划的思想,通过递推计算每个时间步的最大概率和对应的状态。维特比算法
中使用的两个变量是delta和psi,分别表示到达某个状态的最大概率和之前的最优状态。 delta[t][j]
= max(delta[t-1][i] * A[i][j] * B[j][O[t]]) for i in range(N)
psi[t][j] = argmax(delta[t-1][i] * A[i][j]) for i in range(N)
其中,delta[t][j]表示在时间步t到达状态j的最大概率,psi[t][j]表示在时间步t到达状态j时的最优前一
个状态,argmax表示取最大值的索引。

import numpy as np# In[15]:class HiddenMarkov:def forward(self, Q, V, A, B, O, PI): # 使用前向算法N = len(Q) # 状态序列的大小M = len(O) # 观测序列的大小alphas = np.zeros((N, M)) # alpha值T = M # 有几个时刻,有几个观测序列,就有几个时刻for t in range(T): # 遍历每一时刻,算出alpha值indexOfO = V.index(O[t]) # 找出序列对应的索引for i in range(N):if t == 0: # 计算初值alphas[i][t] = PI[t][i] * B[i][indexOfO]print('alpha1(%d)=p%db%db(o1)=%f' % (i, i, i, alphas[i][t]))else:alphas[i][t] = np.dot([alpha[t - 1] for alpha in alphas], [a[i] for a in A]) * B[i][indexOfO] # 递推()print('alpha%d(%d)=[sigma alpha%d(i)ai%d]b%d(o%d)=%f' % (t, i, t - 1, i, i, t, alphas[i][t]))# print(alphas)P = np.sum([alpha[M - 1] for alpha in alphas]) # 求和终止# alpha11 = pi[0][0] * B[0][0] #代表a1(1)# alpha12 = pi[0][1] * B[1][0] #代表a1(2)# alpha13 = pi[0][2] * B[2][0] #代表a1(3)print(P)def backward(self, Q, V, A, B, O, PI): # 后向算法N = len(Q) # 状态序列的大小M = len(O) # 观测序列的大小betas = np.ones((N, M)) # betafor i in range(N):print('beta%d(%d)=1' % (M, i))for t in range(M - 2, -1, -1):indexOfO = V.index(O[t + 1]) # 找出序列对应的索引for i in range(N):betas[i][t] = np.dot(np.multiply(A[i], [b[indexOfO] for b in B]), [beta[t + 1] for beta in betas])realT = t + 1realI = i + 1print('beta%d(%d)=[sigma a%djbj(o%d)]beta%d(j)=(' % (realT, realI, realI, realT + 1, realT + 1),end='')for j in range(N):print("%.2f*%.2f*%.2f+" % (A[i][j], B[j][indexOfO], betas[j][t + 1]), end='')print("0)=%.3f" % betas[i][t])# print(betas)indexOfO = V.index(O[0])P = np.dot(np.multiply(PI, [b[indexOfO] for b in B]), [beta[0] for beta in betas])print("P(O|lambda)=", end="")for i in range(N):print("%.1f*%.1f*%.5f+" % (PI[0][i], B[i][indexOfO], betas[i][0]), end="")print("0=%f" % P)def viterbi(self, Q, V, A, B, O, PI):N = len(Q) # 状态序列的大小M = len(O) # 观测序列的大小deltas = np.zeros((N, M))psis = np.zeros((N, M))I = np.zeros((1, M))for t in range(M):realT = t+1indexOfO = V.index(O[t]) # 找出序列对应的索引for i in range(N):realI = i+1if t == 0:deltas[i][t] = PI[0][i] * B[i][indexOfO]psis[i][t] = 0print('delta1(%d)=pi%d * b%d(o1)=%.2f * %.2f=%.2f'%(realI, realI, realI, PI[0][i], B[i][indexOfO], deltas[i][t]))print('psis1(%d)=0' % (realI))else:deltas[i][t] = np.max(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A])) * B[i][indexOfO]print('delta%d(%d)=max[delta%d(j)aj%d]b%d(o%d)=%.2f*%.2f=%.5f'%(realT, realI, realT-1, realI, realI, realT, np.max(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A])), B[i][indexOfO], deltas[i][t]))psis[i][t] = np.argmax(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A]))print('psis%d(%d)=argmax[delta%d(j)aj%d]=%d' % (realT, realI, realT-1, realI, psis[i][t]))print(deltas)print(psis)I[0][M-1] = np.argmax([delta[M-1] for delta in deltas])print('i%d=argmax[deltaT(i)]=%d' % (M, I[0][M-1]+1))for t in range(M-2, -1, -1):I[0][t] = psis[int(I[0][t+1])][t+1]print('i%d=psis%d(i%d)=%d' % (t+1, t+2, t+2, I[0][t]+1))print(I)if __name__ == '__main__':Q = [1, 2, 3]V = ['红', '白']A = [[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]B = [[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]# O = ['红', '白', '红', '红', '白', '红', '白', '白']O = ['红', '白', '红', '白'] #例子PI = [[0.2, 0.4, 0.4]]HMM = HiddenMarkov()
# HMM.forward(Q, V, A, B, O, PI)
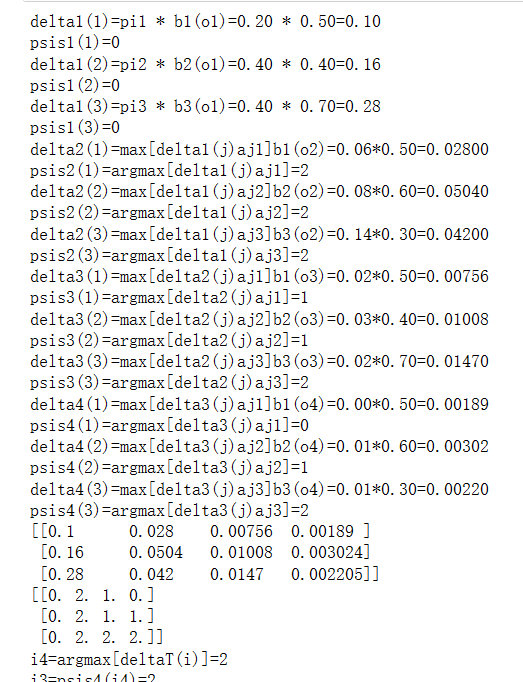
# HMM.backward(Q, V, A, B, O, PI)HMM.viterbi(Q, V, A, B, O, PI)前向算法(Forward Algorithm):前向算法用于计算给定观测序列下每个时刻的前向概率
(alpha),表示在当前时刻观测到特定状态的概率。通过递推计算,利用前一时刻的前向概率和
状态转移概率、发射概率来计算当前时刻的前向概率。数学公式:alpha[i][t] = PI[t][i] * B[i]
[indexOfO],其中alpha[i][t]表示在时刻t处于状态i的前向概率,PI[t][i]表示初始状态概率,B[i]
[indexOfO]表示在状态i观测到观测序列的概率。
后向算法(Backward Algorithm):后向算法用于计算给定观测序列下每个时刻的后向概率
(beta),表示从当前时刻开始,在未来时刻观测到特定状态的概率。通过递推计算,利用后一时
刻的后向概率和状态转移概率、发射概率来计算当前时刻的后向概率。数学公式:beta[i][t] = Σ(A[i]
[j] * B[j][indexOfO] * beta[j][t+1]),其中beta[i][t]表示在时刻t处于状态i的后向概率,A[i][j]表示状态i
转移到状态j的概率,B[j][indexOfO]表示在状态j观测到观测序列的概率。
维特比算法(Viterbi Algorithm):维特比算法用于找到给定观测序列下最可能的隐藏状态序列,
即根据观测序列推断出最可能的隐藏状态路径。通过动态规划的方式,利用状态转移概率、发射概
率和初始状态概率,计算每个时刻每个状态的最大概率值和对应的前一个状态。数学公式:delta[i]
[t] = max(delta[t-1][j] * A[j][i]) * B[i][indexOfO],其中delta[i][t]表示在时刻t处于状态i的最大概率值,
A[j][i]表示状态j转移到状态i的概率,B[i][indexOfO]表示在状态i观测到观测序列的概率。
这篇关于机器学习---HMM前向、后向和维特比算法的计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









