本文主要是介绍概率图模型(1)--隐马尔科夫模型(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
HMM模型参数求解概述
HMM模型参数求解根据已知的条件可以分为两种情况。
第一种情况较为简单,就是我们已知 D 个长度为 T 的观测序列和对应的隐藏状态序列,即 { ( O 1 , I 1 ) , ( O 2 , I 2 ) , . . . ( O D , I D ) } \{(O_1, I_1), (O_2, I_2), ...(O_D, I_D)\} {(O1,I1),(O2,I2),...(OD,ID)} 是已知的,此时我们可以很容易的用最大似然来求解模型参数。
假设样本从隐藏状态 q i q_i qi 转移到 q j q_j qj 的频率计数是 A i j A_{ij} Aij ,那么状态转移矩阵求得为:
A = [ a i j ] , 其 中 a i j = A i j ∑ s = 1 N A i s A = \Big[a_{ij}\Big], \;其中a_{ij} = \frac{A_{ij}}{\sum\limits_{s=1}^{N}A_{is}} A=[aij],其中aij=s=1∑NAisAij
假设样本隐藏状态为 q i q_i qi 且观测状态为 v k v_k vk 的频率计数是 B j k B_{jk} Bjk ,那么观测状态概率矩阵为:
B = [ b j ( k ) ] , 其 中 b j ( k ) = B j k ∑ s = 1 M B j s B= \Big[b_{j}(k)\Big], \;其中b_{j}(k) = \frac{B_{jk}}{\sum\limits_{s=1}^{M}B_{js}} B=[bj(k)],其中bj(k)=s=1∑MBjsBjk
假设所有样本中初始隐藏状态为 q i q_i qi 的频率计数为 C ( i ) C(i) C(i) ,那么初始概率分布为:
π ( i ) = C ( i ) ∑ s = 1 N C ( s ) \pi(i) = \frac{C(i)}{\sum\limits_{s=1}^{N}C(s)} π(i)=s=1∑NC(s)C(i)
第一种情况下求解模型还是很简单的。但是在很多时候,我们无法得到HMM样本观察序列对应的隐藏序列,只有 D 个长度为 T 的观测序列,即 { ( O 1 ) , ( O 2 ) , . . . ( O D ) } \{(O_1), (O_2), ...(O_D)\} {(O1),(O2),...(OD)} 是已知的,此时我们能不能求出合适的HMM模型参数呢?
这就是我们的第二种情况,也是我们本文要讨论的重点。它的解法最常用的是鲍姆-韦尔奇算法,其实就是基于EM算法的求解,只不过鲍姆-韦尔奇算法出现的时代,EM算法还没有被抽象出来,所以我们本文还是说鲍姆-韦尔奇算法。
鲍姆-韦尔奇(Baum-Welch)算法原理
鲍姆-韦尔奇算法原理既然使用的就是EM算法的原理,那么我们需要在E步求出联合分布 P ( O , I ∣ λ ) P(O,I|\lambda) P(O,I∣λ) 基于条件概率 P ( I ∣ O , λ ‾ ) P(I|O,\overline{\lambda}) P(I∣O,λ) 的期望,其中 λ ‾ \overline \lambda λ 为当前的模型参数,然后再M步最大化这个期望,得到更新的模型参数 λ \lambda λ 。接着不停的进行EM迭代,直到模型参数的值收敛为止。
首先来看看E步,当前模型参数为 λ ‾ \overline{\lambda} λ , 联合分布 P ( O , I ∣ λ ) P(O,I|\lambda) P(O,I∣λ) 基于条件概率 P ( I ∣ O , λ ‾ ) P(I|O,\overline{\lambda}) P(I∣O,λ) 的期望表达式为:
L ( λ , λ ‾ ) = ∑ I P ( I ∣ O , λ ‾ ) l o g P ( O , I ∣ λ ) L(\lambda, \overline{\lambda}) = \sum\limits_{I}P(I|O,\overline{\lambda})logP(O,I|\lambda) L(λ,λ)=I∑P(I∣O,λ)logP(O,I∣λ)
在M步,我们极大化上式,然后得到更新后的模型参数如下:
λ ‾ = a r g max λ ∑ I P ( I ∣ O , λ ‾ ) l o g P ( O , I ∣ λ ) \overline{\lambda} = arg\;\max_{\lambda}\sum\limits_{I}P(I|O,\overline{\lambda})logP(O,I|\lambda) λ=argλmaxI∑P(I∣O,λ)logP(O,I∣λ)
通过不断的E步和M步的迭代,直到 λ ‾ \overline{\lambda} λ 收敛。下面我们来看看鲍姆-韦尔奇算法的推导过程。
鲍姆-韦尔奇算法的推导
我们的训练数据为 { ( O 1 , I 1 ) , ( O 2 , I 2 ) , . . . ( O D , I D ) } \{(O_1, I_1), (O_2, I_2), ...(O_D, I_D)\} {(O1,I1),(O2,I2),...(OD,ID)} ,其中任意一个观测序列 O d = { o 1 ( d ) , o 2 ( d ) , . . . o T ( d ) } O_d = \{o_1^{(d)}, o_2^{(d)}, ... o_T^{(d)}\} Od={o1(d),o2(d),...oT(d)} ,其对应的未知的隐藏状态序列表示为: I d = { i 1 ( d ) , i 2 ( d ) , . . . i T ( d ) } I_d = \{i_1^{(d)}, i_2^{(d)}, ... i_T^{(d)}\} Id={i1(d),i2(d),...iT(d)}
首先看鲍姆-韦尔奇算法的E步,我们需要先计算联合分布 P ( O , I ∣ λ ) P(O,I|\lambda) P(O,I∣λ) 的表达式如下:
P ( O , I ∣ λ ) = ∏ d = 1 D π i 1 ( d ) b i 1 ( d ) ( o 1 ( d ) ) a i 1 ( d ) i 2 ( d ) b i 2 ( d ) ( o 2 ( d ) ) . . . a i T − 1 ( d ) i T ( d ) b i T ( d ) ( o T ( d ) ) P(O,I|\lambda) = \prod_{d=1}^D\pi_{i_1^{(d)}}b_{i_1^{(d)}}(o_1^{(d)})a_{i_1^{(d)}i_2^{(d)}}b_{i_2^{(d)}}(o_2^{(d)})...a_{i_{T-1}^{(d)}i_T^{(d)}}b_{i_T^{(d)}}(o_T^{(d)}) P(O,I∣λ)=d=1∏Dπi1(d)bi1(d)(o1(d))ai1(d)i2(d)bi2(d)(o2(d))...aiT−1(d)iT(d)biT(d)(oT(d))
我们的E步得到的期望表达式为:
L ( λ , λ ‾ ) = ∑ I P ( I ∣ O , λ ‾ ) l o g P ( O , I ∣ λ ) L(\lambda, \overline{\lambda}) = \sum\limits_{I}P(I|O,\overline{\lambda})logP(O,I|\lambda) L(λ,λ)=I∑P(I∣O,λ)logP(O,I∣λ)
在M步我们要极大化上式。由于 P ( I ∣ O , λ ‾ ) = P ( I , O ∣ λ ‾ ) / P ( O ∣ λ ‾ ) P(I|O,\overline{\lambda}) = P(I,O|\overline{\lambda})/P(O|\overline{\lambda}) P(I∣O,λ)=P(I,O∣λ)/P(O∣λ) ,而 P ( O ∣ λ ‾ ) P(O|\overline{\lambda}) P(O∣λ) 是常数,因此我们要极大化的式子等价于:
λ ‾ = a r g max λ ∑ I P ( O , I ∣ λ ‾ ) l o g P ( O , I ∣ λ ) \overline{\lambda} = arg\;\max_{\lambda}\sum\limits_{I}P(O,I|\overline{\lambda})logP(O,I|\lambda) λ=argλmaxI∑P(O,I∣λ)logP(O,I∣λ)
我们将上面 P ( O , I ∣ λ ) P(O,I|\lambda) P(O,I∣λ) 的表达式带入我们的极大化式子,得到的表达式如下:
λ ‾ = a r g max λ ∑ d = 1 D ∑ I P ( O , I ∣ λ ‾ ) ( l o g π i 1 + ∑ t = 1 T − 1 l o g a i t , i t + 1 + ∑ t = 1 T l o g b i t ( o t ) ) \overline{\lambda} = arg\;\max_{\lambda}\sum\limits_{d=1}^D\sum\limits_{I}P(O,I|\overline{\lambda})(log\pi_{i_1} + \sum\limits_{t=1}^{T-1}log\;a_{i_t,i_{t+1}} + \sum\limits_{t=1}^Tlog b_{i_t}(o_t)) λ=argλmaxd=1∑DI∑P(O,I∣λ)(logπi1+t=1∑T−1logait,it+1+t=1∑Tlogbit(ot))
我们的隐藏模型参数 λ = ( A , B , π ) \lambda =(A,B,\pi) λ=(A,B,π) ,因此下面我们只需要对上式分别对 A , B , π A,B,\pi A,B,π 求导即可得到我们更新的模型参数 λ ‾ \overline \lambda λ
首先我们看看对模型参数 π \pi π 的求导。由于 π \pi π 只在上式中括号里的第一部分出现,因此我们对于 π \pi π 的极大化式子为:
π i ‾ = a r g max π i 1 ∑ d = 1 D ∑ I P ( O , I ∣ λ ‾ ) l o g π i 1 = a r g max π i ∑ d = 1 D ∑ i = 1 N P ( O , i 1 ( d ) = i ∣ λ ‾ ) l o g π i \overline{\pi_i} = arg\;\max_{\pi_{i_1}} \sum\limits_{d=1}^D\sum\limits_{I}P(O,I|\overline{\lambda})log\pi_{i_1} = arg\;\max_{\pi_{i}} \sum\limits_{d=1}^D\sum\limits_{i=1}^NP(O,i_1^{(d)} =i|\overline{\lambda})log\pi_{i} πi=argπi1maxd=1∑DI∑P(O,I∣λ)logπi1=argπimaxd=1∑Di=1∑NP(O,i1(d)=i∣λ)logπi
由于 π i \pi_i πi 还满足 ∑ i = 1 N π i = 1 \sum\limits_{i=1}^N\pi_i =1 i=1∑Nπi=1 ,因此根据拉格朗日子乘法,我们得到 π i \pi_i πi 要极大化的拉格朗日函数为:
a r g max π i ∑ d = 1 D ∑ i = 1 N P ( O , i 1 ( d ) = i ∣ λ ‾ ) l o g π i + γ ( ∑ i = 1 N π i − 1 ) arg\;\max_{\pi_{i}}\sum\limits_{d=1}^D\sum\limits_{i=1}^NP(O,i_1^{(d)} =i|\overline{\lambda})log\pi_{i} + \gamma(\sum\limits_{i=1}^N\pi_i -1) argπimaxd=1∑Di=1∑NP(O,i1(d)=i∣λ)logπi+γ(i=1∑Nπi−1)
其中, γ \gamma γ 为拉格朗日系数。上式对 π i \pi_i πi 求偏导数并令结果为0, 我们得到:
∑ d = 1 D P ( O , i 1 ( d ) = i ∣ λ ‾ ) + γ π i = 0 \sum\limits_{d=1}^DP(O,i_1^{(d)} =i|\overline{\lambda}) + \gamma\pi_i = 0 d=1∑DP(O,i1(d)=i∣λ)+γπi=0
令 i 分别等于从1到 N,从上式可以得到 N 个式子,对这 N 个式子求和可得:
∑ d = 1 D P ( O ∣ λ ‾ ) + γ = 0 \sum\limits_{d=1}^DP(O|\overline{\lambda}) + \gamma = 0 d=1∑DP(O∣λ)+γ=0
从上两式消去 γ \gamma γ ,得到 π i \pi_i πi 的表达式为:
π i = ∑ d = 1 D P ( O , i 1 ( d ) = i ∣ λ ‾ ) ∑ d = 1 D P ( O ∣ λ ‾ ) = ∑ d = 1 D P ( O , i 1 ( d ) = i ∣ λ ‾ ) D P ( O ∣ λ ‾ ) = ∑ d = 1 D P ( i 1 ( d ) = i ∣ O , λ ‾ ) D = ∑ d = 1 D P ( i 1 ( d ) = i ∣ O ( d ) , λ ‾ ) D \pi_i =\frac{\sum\limits_{d=1}^DP(O,i_1^{(d)} =i|\overline{\lambda})}{\sum\limits_{d=1}^DP(O|\overline{\lambda})} = \frac{\sum\limits_{d=1}^DP(O,i_1^{(d)} =i|\overline{\lambda})}{DP(O|\overline{\lambda})} = \frac{\sum\limits_{d=1}^DP(i_1^{(d)} =i|O, \overline{\lambda})}{D} = \frac{\sum\limits_{d=1}^DP(i_1^{(d)} =i|O^{(d)}, \overline{\lambda})}{D} πi=d=1∑DP(O∣λ)d=1∑DP(O,i1(d)=i∣λ)=DP(O∣λ)d=1∑DP(O,i1(d)=i∣λ)=Dd=1∑DP(i1(d)=i∣O,λ)=Dd=1∑DP(i1(d)=i∣O(d),λ)
利用我们在前向概率的定义可得:
P ( i 1 ( d ) = i ∣ O ( d ) , λ ‾ ) = γ 1 ( d ) ( i ) P(i_1^{(d)} =i|O^{(d)}, \overline{\lambda}) = \gamma_1^{(d)}(i) P(i1(d)=i∣O(d),λ)=γ1(d)(i)
因此最终我们在M步 π i \pi_i πi 的迭代公式为:
π i = ∑ d = 1 D γ 1 ( d ) ( i ) D \pi_i = \frac{\sum\limits_{d=1}^D\gamma_1^{(d)}(i)}{D} πi=Dd=1∑Dγ1(d)(i)
现在我们来看看 A 的迭代公式求法。方法和 π \pi π的类似。由于 A 只在最大化函数式中括号里的第二部分出现,而这部分式子可以整理为:
∑ d = 1 D ∑ I ∑ t = 1 T − 1 P ( O , I ∣ λ ‾ ) l o g a i t , i t + 1 = ∑ d = 1 D ∑ i = 1 N ∑ j = 1 N ∑ t = 1 T − 1 P ( O , i t ( d ) = i , i t + 1 ( d ) = j ∣ λ ‾ ) l o g a i j \sum\limits_{d=1}^D\sum\limits_{I}\sum\limits_{t=1}^{T-1}P(O,I|\overline{\lambda})log\;a_{i_t,i_{t+1}} = \sum\limits_{d=1}^D\sum\limits_{i=1}^N\sum\limits_{j=1}^N\sum\limits_{t=1}^{T-1}P(O,i_t^{(d)} = i, i_{t+1}^{(d)} = j|\overline{\lambda})log\;a_{ij} d=1∑DI∑t=1∑T−1P(O,I∣λ)logait,it+1=d=1∑Di=1∑Nj=1∑Nt=1∑T−1P(O,it(d)=i,it+1(d)=j∣λ)logaij
由于 a i j a_{ij} aij 还满足 ∑ j = 1 N a i j = 1 \sum\limits_{j=1}^Na_{ij} =1 j=1∑Naij=1 。和求解 π i \pi_i πi 类似,我们可以用拉格朗日子乘法并对 a i j a_{ij} aij 求导,并令结果为0,可以得到 a i j a_{ij} aij 的迭代表达式为:
a i j = ∑ d = 1 D ∑ t = 1 T − 1 P ( O ( d ) , i t ( d ) = i , i t + 1 ( d ) = j ∣ λ ‾ ) ∑ d = 1 D ∑ t = 1 T − 1 P ( O ( d ) , i t ( d ) = i ∣ λ ‾ ) a_{ij} = \frac{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T-1}P(O^{(d)}, i_t^{(d)} = i, i_{t+1}^{(d)} = j|\overline{\lambda})}{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T-1}P(O^{(d)}, i_t^{(d)} = i|\overline{\lambda})} aij=d=1∑Dt=1∑T−1P(O(d),it(d)=i∣λ)d=1∑Dt=1∑T−1P(O(d),it(d)=i,it+1(d)=j∣λ)
利用前向概率的定义和 ξ t ( i , j ) \xi_t(i,j) ξt(i,j) 的定义可得们在M步 a i j a_{ij} aij 的迭代公式为:
a i j = ∑ d = 1 D ∑ t = 1 T − 1 ξ t ( d ) ( i , j ) ∑ d = 1 D ∑ t = 1 T − 1 γ t ( d ) ( i ) a_{ij} = \frac{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T-1}\xi_t^{(d)}(i,j)}{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T-1}\gamma_t^{(d)}(i)} aij=d=1∑Dt=1∑T−1γt(d)(i)d=1∑Dt=1∑T−1ξt(d)(i,j)
现在我们来看看 B 的迭代公式求法。方法和 π \pi π 的类似。由于 B 只在最大化函数式中括号里的第三部分出现,而这部分式子可以整理为:
∑ d = 1 D ∑ I ∑ t = 1 T P ( O , I ∣ λ ‾ ) l o g b i t ( o t ) = ∑ d = 1 D ∑ j = 1 N ∑ t = 1 T P ( O , i t ( d ) = j ∣ λ ‾ ) l o g b j ( o t ) \sum\limits_{d=1}^D\sum\limits_{I}\sum\limits_{t=1}^{T}P(O,I|\overline{\lambda})log\;b_{i_t}(o_t) = \sum\limits_{d=1}^D\sum\limits_{j=1}^N\sum\limits_{t=1}^{T}P(O,i_t^{(d)} = j|\overline{\lambda})log\;b_{j}(o_t) d=1∑DI∑t=1∑TP(O,I∣λ)logbit(ot)=d=1∑Dj=1∑Nt=1∑TP(O,it(d)=j∣λ)logbj(ot)
由于 b j ( o t ) b_{j}(o_t) bj(ot) 还满足 ∑ k = 1 M b j ( o t = v k ) = 1 \sum\limits_{k=1}^Mb_{j}(o_t =v_k) =1 k=1∑Mbj(ot=vk)=1 。和求解 π i \pi_i πi 类似,我们可以用拉格朗日子乘法并对 b j ( k ) b_{j}(k) bj(k) 求导,并令结果为0,得到 b j ( k ) b_{j}(k) bj(k) 的迭代表达式为:
b j ( k ) = ∑ d = 1 D ∑ t = 1 T P ( O , i t ( d ) = j ∣ λ ‾ ) I ( o t ( d ) = v k ) ∑ d = 1 D ∑ t = 1 T P ( O , i t ( d ) = j ∣ λ ‾ ) b_{j}(k) = \frac{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T}P(O,i_t^{(d)} = j|\overline{\lambda})I(o_t^{(d)}=v_k)}{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T}P(O,i_t^{(d)} = j|\overline{\lambda})} bj(k)=d=1∑Dt=1∑TP(O,it(d)=j∣λ)d=1∑Dt=1∑TP(O,it(d)=j∣λ)I(ot(d)=vk)
其中 I ( o t ( d ) = v k ) I(o_t^{(d)}=v_k) I(ot(d)=vk) 当且仅当 o t ( d ) = v k o_t^{(d)}=v_k ot(d)=vk 时为1,否则为0. 利用前向概率的定义可得 b j ( o t ) b_{j}(o_t) bj(ot) 的最终表达式为:
b j ( k ) = ∑ d = 1 D ∑ t = 1 , o t ( d ) = v k T γ t ( d ) ( j ) ∑ d = 1 D ∑ t = 1 T γ t ( d ) ( j ) b_{j}(k) = \frac{\sum\limits_{d=1}^D\sum\limits_{t=1, o_t^{(d)}=v_k}^{T}\gamma_t^{(d)}(j)}{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T}\gamma_t^{(d)}(j)} bj(k)=d=1∑Dt=1∑Tγt(d)(j)d=1∑Dt=1,ot(d)=vk∑Tγt(d)(j)
有了 π i , a i j , b j ( k ) \pi_i, a_{ij},b_{j}(k) πi,aij,bj(k) 的迭代公式,我们就可以迭代求解HMM模型参数了。
鲍姆-韦尔奇算法流程总结
这里我们概括总结下鲍姆-韦尔奇算法的流程。
输入: D 个观测序列样本 { ( O 1 ) , ( O 2 ) , . . . ( O D ) } \{(O_1), (O_2), ...(O_D)\} {(O1),(O2),...(OD)}
输出:HMM模型参数
1)随机初始化所有的 π i , a i j , b j ( k ) \pi_i, a_{ij},b_{j}(k) πi,aij,bj(k)
2) 对于每个样本 d = 1 , 2 , . . . D d = 1,2,...D d=1,2,...D,用前向后向算法计算 γ t ( d ) ( i ) , ξ t ( d ) ( i , j ) , t = 1 , 2... T \gamma_t^{(d)}(i),\xi_t^{(d)}(i,j), t =1,2...T γt(d)(i),ξt(d)(i,j),t=1,2...T
3) 更新模型参数:
π i = ∑ d = 1 D γ 1 ( d ) ( i ) D \pi_i = \frac{\sum\limits_{d=1}^D\gamma_1^{(d)}(i)}{D} πi=Dd=1∑Dγ1(d)(i)
a i j = ∑ d = 1 D ∑ t = 1 T − 1 ξ t ( d ) ( i , j ) ∑ d = 1 D ∑ t = 1 T − 1 γ t ( d ) ( i ) a_{ij} = \frac{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T-1}\xi_t^{(d)}(i,j)}{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T-1}\gamma_t^{(d)}(i)} aij=d=1∑Dt=1∑T−1γt(d)(i)d=1∑Dt=1∑T−1ξt(d)(i,j)
b j ( k ) = ∑ d = 1 D ∑ t = 1 , o t ( d ) = v k T γ t ( d ) ( j ) ∑ d = 1 D ∑ t = 1 T γ t ( d ) ( j ) b_{j}(k) = \frac{\sum\limits_{d=1}^D\sum\limits_{t=1, o_t^{(d)}=v_k}^{T}\gamma_t^{(d)}(j)}{\sum\limits_{d=1}^D\sum\limits_{t=1}^{T}\gamma_t^{(d)}(j)} bj(k)=d=1∑Dt=1∑Tγt(d)(j)d=1∑Dt=1,ot(d)=vk∑Tγt(d)(j)
- 如果 π i , a i j , b j ( k ) \pi_i, a_{ij},b_{j}(k) πi,aij,bj(k) 的值已经收敛,则算法结束,否则回到第2)步继续迭代。
HMM最可能隐藏状态序列求解概述
给定模型和观测序列,求给定观测序列条件下,最可能出现的对应的隐藏状态序列。
HMM模型的解码问题最常用的算法是维特比算法,当然也有其他的算法可以求解这个问题。同时维特比算法是一个通用的求序列最短路径的动态规划算法,也可以用于很多其他问题。
在HMM模型的解码问题中,给定模型 λ = ( A , B , π ) \lambda = (A, B, \pi) λ=(A,B,π) 和观测序列 O = { o 1 , o 2 , . . . o T } O =\{o_1,o_2,...o_T\} O={o1,o2,...oT} ,求给定观测序列O条件下,最可能出现的对应的状态序列 I ∗ = { i 1 ∗ , i 2 ∗ , . . . i T ∗ } I^*= \{i_1^*,i_2^*,...i_T^*\} I∗={i1∗,i2∗,...iT∗} ,即 P ( I ∗ ∣ O ) P(I^*|O) P(I∗∣O) 要最大化。
一个可能的近似解法是求出观测序列 O 在每个时刻 t 最可能的隐藏状态 i t ∗ i_t^* it∗ 然后得到一个近似的隐藏状态序列 I ∗ = { i 1 ∗ , i 2 ∗ , . . . i T ∗ } I^*= \{i_1^*,i_2^*,...i_T^*\} I∗={i1∗,i2∗,...iT∗} 。要这样近似求解不难,利用定义:在给定模型λλ和观测序列 O 时,在时刻 t 处于状态 q i q_i qi 的概率是 γ t ( i ) \gamma_t(i) γt(i) ,这个概率可以通过HMM的前向算法与后向算法计算。这样我们有:
i t ∗ = a r g max 1 ≤ i ≤ N [ γ t ( i ) ] , t = 1 , 2 , . . . T i_t^* = arg \max_{1 \leq i \leq N}[\gamma_t(i)], \; t =1,2,...T it∗=arg1≤i≤Nmax[γt(i)],t=1,2,...T
近似算法很简单,但是却不能保证预测的状态序列是整体是最可能的状态序列,因为预测的状态序列中某些相邻的隐藏状态可能存在转移概率为0的情况。
而维特比算法可以将HMM的状态序列作为一个整体来考虑,避免近似算法的问题,下面我们来看看维特比算法进行HMM解码的方法。
维特比算法
维特比算法是一个通用的解码算法,是基于动态规划的求序列最短路径的方法。
既然是动态规划算法,那么就需要找到合适的局部状态,以及局部状态的递推公式。在HMM中,维特比算法定义了两个局部状态用于递推。
第一个局部状态是在时刻 t 隐藏状态为i所有可能的状态转移路径 i 1 , i 2 , . . . i t i_1,i_2,...i_t i1,i2,...it 中的概率最大值。记为 δ t ( i ) \delta_t(i) δt(i) :
δ t ( i ) = max i 1 , i 2 , . . . i t − 1 P ( i t = i , i 1 , i 2 , . . . i t − 1 , o t , o t − 1 , . . . o 1 ∣ λ ) , i = 1 , 2 , . . . N \delta_t(i) = \max_{i_1,i_2,...i_{t-1}}\;P(i_t=i, i_1,i_2,...i_{t-1},o_t,o_{t-1},...o_1|\lambda),\; i =1,2,...N δt(i)=i1,i2,...it−1maxP(it=i,i1,i2,...it−1,ot,ot−1,...o1∣λ),i=1,2,...N
由 δ t ( i ) \delta_t(i) δt(i) 的定义可以得到 δ \delta δ 的递推表达式:
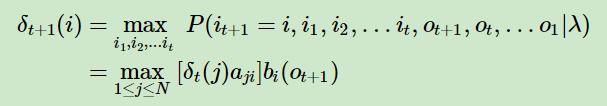
第二个局部状态由第一个局部状态递推得到。我们定义在时刻 t 隐藏状态为 i 的所有单个状态转移路径 ( i 1 , i 2 , . . . , i t − 1 , i ) (i_1,i_2,...,i_{t-1},i) (i1,i2,...,it−1,i) 中概率最大的转移路径中第 t − 1 t-1 t−1 个节点的隐藏状态为 Ψ t ( i ) \Psi_t(i) Ψt(i) ,其递推表达式可以表示为:即 Ψ \Psi Ψ存储了最优路径末状态 的前驱状态
Ψ t ( i ) = a r g max 1 ≤ j ≤ N [ δ t − 1 ( j ) a j i ] \Psi_t(i) = arg \; \max_{1 \leq j \leq N}\;[\delta_{t-1}(j)a_{ji}] Ψt(i)=arg1≤j≤Nmax[δt−1(j)aji]
有了这两个局部状态,我们就可以从时刻0一直递推到时刻 T,然后利用 Ψ t ( i ) \Psi_t(i) Ψt(i) 记录的前一个最可能的状态节点回溯,直到找到最优的隐藏状态序列。
维特比算法流程总结
现在我们来总结下维特比算法的流程:
输入:HMM模型 λ = ( A , B , π ) \lambda = (A, B, \pi) λ=(A,B,π),观测序列 O = ( o 1 , o 2 , . . . o T ) O=(o_1,o_2,...o_T) O=(o1,o2,...oT)
输出:最有可能的隐藏状态序列 I ∗ = { i 1 ∗ , i 2 ∗ , . . . i T ∗ } I^*= \{i_1^*,i_2^*,...i_T^*\} I∗={i1∗,i2∗,...iT∗}
1)初始化局部状态:
δ 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2... N \delta_1(i) = \pi_ib_i(o_1),\;i=1,2...N δ1(i)=πibi(o1),i=1,2...N
Ψ 1 ( i ) = 0 , i = 1 , 2... N \Psi_1(i)=0,\;i=1,2...N Ψ1(i)=0,i=1,2...N
- 进行动态规划递推时刻 t = 2 , 3 , . . . T t=2,3,...T t=2,3,...T 时刻的局部状态:
δ t ( i ) = max 1 ≤ j ≤ N [ δ t − 1 ( j ) a j i ] b i ( 0 t ) , i = 1 , 2... N \delta_{t}(i) = \max_{1 \leq j \leq N}\;[\delta_{t-1}(j)a_{ji}]b_i(0_{t}),\;i=1,2...N δt(i)=1≤j≤Nmax[δt−1(j)aji]bi(0t),i=1,2...N
Ψ t ( i ) = a r g max 1 ≤ j ≤ N [ δ t − 1 ( j ) a j i ] , i = 1 , 2... N \Psi_t(i) = arg \; \max_{1 \leq j \leq N}\;[\delta_{t-1}(j)a_{ji}],\;i=1,2...N Ψt(i)=arg1≤j≤Nmax[δt−1(j)aji],i=1,2...N
- 计算时刻 T 最大的 δ T ( i ) \delta_{T}(i) δT(i) ,即为最可能隐藏状态序列出现的概率。计算时刻 T最大的 Ψ t ( i ) \Psi_t(i) Ψt(i) ,即为时刻 T 最可能的隐藏状态。
P ∗ = max 1 ≤ j ≤ N δ T ( i ) P* = \max_{1 \leq j \leq N}\delta_{T}(i) P∗=1≤j≤NmaxδT(i)
i T ∗ = a r g max 1 ≤ j ≤ N [ δ T ( i ) ] i_T^* = arg \; \max_{1 \leq j \leq N}\;[\delta_{T}(i)] iT∗=arg1≤j≤Nmax[δT(i)]
- 利用局部状态 Ψ t ( i ) \Psi_t(i) Ψt(i) 开始回溯。对于 t = T − 1 , T − 2 , . . . , 1 t=T-1,T-2,...,1 t=T−1,T−2,...,1:
i t ∗ = Ψ t + 1 ( i t + 1 ∗ ) i_t^* = \Psi_{t+1}(i_{t+1}^*) it∗=Ψt+1(it+1∗)
最终得到最有可能的隐藏状态序列 I ∗ = { i 1 ∗ , i 2 ∗ , . . . i T ∗ } I^*= \{i_1^*,i_2^*,...i_T^*\} I∗={i1∗,i2∗,...iT∗}
HMM模型维特比算法总结
如果了解文本挖掘的分词中的维特比算法,就会发现这两篇个维特比算法稍有不同。主要原因是在中文分词时,我们没有观察状态和隐藏状态的区别,只有一种状态。但是维特比算法的核心是定义动态规划的局部状态与局部递推公式,这一点在中文分词维特比算法和HMM的维特比算法是相同的,也是维特比算法的精华所在。
维特比算法也是寻找序列最短路径的一个通用方法,和dijkstra算法有些类似,但是dijkstra算法并没有使用动态规划,而是贪心算法。同时维特比算法仅仅局限于求序列最短路径,而dijkstra算法是通用的求最短路径的方法。
这篇关于概率图模型(1)--隐马尔科夫模型(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







