本文主要是介绍AI上推荐 之 DIEN模型(序列模型与推荐系统的花火碰撞),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 前言
随着信息技术和互联网的发展, 我们已经步入了一个信息过载的时代,这个时代,无论是信息消费者还是信息生产者都遇到了很大的挑战:
- 信息消费者:如何从大量的信息中找到自己感兴趣的信息?
- 信息生产者:如何让自己生产的信息脱颖而出, 受到广大用户的关注?
为了解决这个矛盾, 推荐系统应时而生, 并飞速前进,在用户和信息之间架起了一道桥梁,一方面帮助用户发现对自己有价值的信息, 一方面让信息能够展现在对它感兴趣的用户前面。 推荐系统近几年有了深度学习的助推发展之势迅猛, 从前深度学习的传统推荐模型(协同过滤,矩阵分解,LR, FM, FFM, GBDT)到深度学习的浪潮之巅(DNN, Deep Crossing, DIN, DIEN, Wide&Deep, Deep&Cross, DeepFM, AFM, NFM, PNN, FNN, DRN), 现在正无时无刻不影响着大众的生活。
推荐系统通过分析用户的历史行为给用户的兴趣建模, 从而主动给用户推荐给能够满足他们兴趣和需求的信息, 能够真正的“懂你”。 想上网购物的时候, 推荐系统在帮我们挑选商品, 想看资讯的时候, 推荐系统为我们准备了感兴趣的新闻, 想学习充电的时候, 推荐系统为我们提供最合适的课程, 想消遣放松的时候, 推荐系统为我们奉上欲罢不能的短视频…, 所以当我们淹没在信息的海洋时, 推荐系统正在拨开一层层波浪, 为我们追寻多姿多彩的生活!
这段时间刚好开始学习推荐系统, 通过王喆老师的《深度学习推荐系统》已经梳理好了知识体系, 了解了当前推荐系统领域各种主流的模型架构和技术。 所以接下来的时间就开始对这棵大树开枝散叶,对每一块知识点进行学习总结。 所以接下来一块目睹推荐系统的风采吧!
这次整理重点放在推荐系统的模型方面, 前面已经把传统的推荐模型梳理完毕, 下面正式进入深度学习的浪潮之巅。在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推挤系统和计算广告领域全面进入了深度学习时代, 时至今日, 依然是主流。 在进入深度学习时代, 推荐模型主要有下面两个进展:
- 与传统的机器学习模型相比, 深度学习模型的表达能力更强, 能够挖掘更多数据中隐藏的模式
- 深度学习模型结构非常灵活, 能够根据业务场景和数据特点, 灵活调整模型结构, 使模型与应用场景完美契合
所以, 后面开始尝试整理深度学习推荐模型,它们以多层感知机(MLP)为核心, 通过改变神经网络结构进行演化,它们的演化关系依然拿书上的一张图片, 便于梳理关系脉络, 对知识有个宏观的把握:
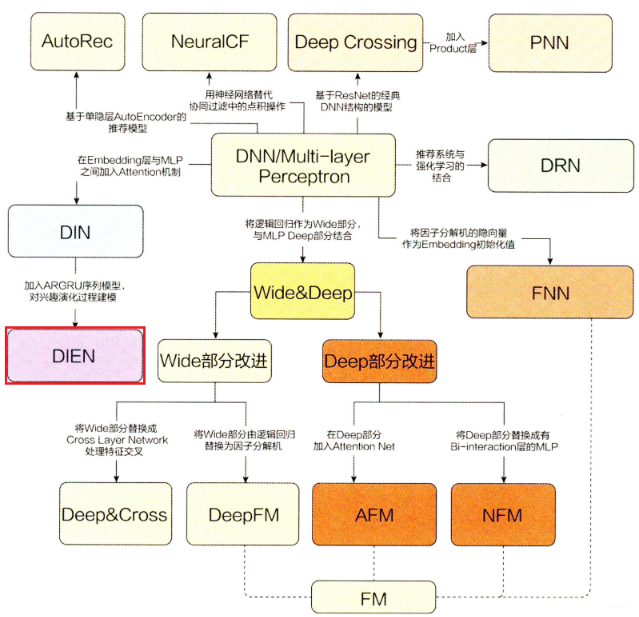
今天是深度学习模型的第六篇,介绍一个模型叫做DIEN,全称是Deep Interest Evolution Network(深度兴趣进化网络), 这个是阿里2019年提出的一个模型, 是上一篇DIN模型的演化版本。 该模型的创新点就是“兴趣进化网络”, 在这里面用序列模型模拟了用户兴趣的进化过程,能模拟用户的演化过程在很多推荐场景中是非常重要的。记得在NFM的时候,就整理过,继NFM,DeepFM之后, 深度学习模型的发展特点已经不再是单纯的把之前的各种模型组合,拼接了, 而是不断的基于业务场景,引进新的结构, 上一篇的AFM和DIN,就是Attention机制在推荐模型的一波尝试, 而今天的DIEN,是序列模型在推荐模型中的一种尝试了, 所以,这篇文章就是一点点的剖析下这个模型了。
终于到了一篇文章整理一个模型的阶段了,后面的这个系列也打算采用这种“小步快跑”的方式,每次研究一个模型,主要是基于原论文,然后通过一篇文章进行整理,包括理论和代码,顺便又如果有包能用的话也介绍下如何使用哈哈。这样正好也兼顾论文总结,最后就是保持短期更新,这样也能逼迫着快速输出了哈哈。既然是一个模型,那么模型的逻辑也比较简单, 和前面基本一样,先介绍DIEN模型的理论部分(尽量的依托原论文了),然后就是代码复现的部分(这里也不一定非得是Pytorch了,也有可能是tensorflow, 因为感觉复现模型的过程是为了更好的理解具体细节, 实在不太想纠结框架了,毕竟现在如果实际场景用的话,直接都可以掉包,人大佬都帮咱实现好了),只要会用就好了,所以以后的模型也会加上deepctr上的使用过程(前面的模型也慢慢的补上这一块)。最后基于王喆老师的书对深度排序模型这块进行总结,再开启新章程。
PS: 在读这篇文章前,建议先看下我上篇总结的DIN模型, 这样才能更好的对比串联,毕竟该文章的DIEN是DIN的进化版本。
大纲如下:
- DIEN模型的理论以及论文细节
- DIEN模型的代码复现
- Deepctr中DIEN模型的使用
- 小结
Ok, let’s go!
2. DIEN模型的理论及论文细节
2.1 DIEN的简介与"进化"动机
阿里巴巴在提出DIN模型之后,并没有停止对推荐模型演化的探索进程, 在2019年,国瑞大佬又继DIN进行了深一步的演化,再结合着淘宝的电商广告的推荐场景,提出了DIN模型的演化版本DIEN,叫做深度兴趣进化网络, 这个模型的应用场景和DIN完全一致,也是电商广告的推荐场景,这种场景非常注重用户的历史行为特征(历史购买过的商品或者类别信息)。而且还要知道三点:
- 用户兴趣多种多样,并变化多端
- 捕捉用户兴趣点非常重要
- 用户的兴趣往往可以在其历史行为中进行学习
在DIN中介绍过,这种场景下,如果是DIN之前的Embedding&MLP系列的模型,有个很大的劣势就是无法表达出用户广泛的兴趣来,因为这些模型在得到各个特征的embedding之后,就蛮力拼接了,然后就各种交叉等。这时候根本没有考虑之前用户历史行为商品具体是什么,究竟用户历史行为中的哪个会对当前的点击预测带来积极的作用。 而实际上,对于用户点不点击当前的商品广告,很大程度上是依赖于他的历史行为的。
而DIN模型改进的动机就是考虑到用户的历史行为商品与当前商品广告的一个关联性,把注意力引入到了模型,设计了一个"local activation unit"结构,利用候选商品和历史问题商品之间的相关性计算出权重,这个就代表了对于当前商品广告的预测,用户历史行为的各个商品的重要程度大小,这样自适应的去捕捉用户的兴趣变化,这样才能较为准确的实施广告推荐。
而DIN模型就完美了吗? 其实不然,作者在DIEN里面提到了DIN以及其他模型存在的不足:

简单的讲DIN有两点不足:
- 直接将用户过去的历史行为当做了用户的兴趣,缺乏对具体行为背后的潜在兴趣进行专门的建模。只计算了当前候选广告与过去历史行为的相关性,根据这个做出推荐, 但历史行为之间的依赖关系并没有很好的模拟出来,历史行为其实也是一个随时间排序的序列,既然是时间相关的序列,就一定存在或深或浅的前后依赖关系, 而这样的序列信息或者说依赖关系对推荐过程是非常有价值的(能够反映用户背后的潜在兴趣变化),大量研究发现这种信息能够用于构建更丰富的用户模型并发现附加的行为模式,而DIN模型包括之前的MLP系列模型都无法学习到这样的序列依赖关系。
- DIN模型没法捕捉到用户的兴趣变化过程,作者在论文中用到了一个词叫做”兴趣漂移", 即在相邻的访问中,用户的意图可能非常不同,用户的一个行为可能依赖于很久以前的行为。而一个用户对不同目标项的点击行为受到不同兴趣部分的影响,如果没法学习用户的兴趣演化,就很容易基于用户所有购买历史行为综合推荐,而不是针对“下一次购买”推荐, DIN虽然是能够更加注重与当前候选物品相关的历史行为,但是这些行为并不能表示出用户的兴趣变化过程,所以序列信息是非常之重要的。
其实上面两点就说明了一个核心问题DIN忽略了序列信息。王喆老师举了一个例子说明为啥序列信息是有价值的:
对一个综合电商来说,用户的兴趣迁移其实非常快,例如,上周一位用户在挑选一双篮球鞋, 这位用户上周的行为序列都会集中在篮球鞋这个品类的商品上, 但是完成购买之后,本周的购物兴趣可能变成买机械键盘。
所以序列信息的重要性在于:
- 加强了最近行为对下次行为预测的影响。 比如上面的例子, 用户近期购买机械键盘的概率会明显高于再买篮球鞋的概率
- 序列模型能够学习到购买趋势的信息。这个感觉就是在建模用户的兴趣演化, 在上面例子中, 序列模型能在一定程度上建立“篮球鞋”到“机械键盘”的转移概率,如果这个转移概率在全局统计意义上足够高, 那么用户购买篮球鞋时,推荐机械键盘也会是一个不错的选项。 直观上,两者的用户群体很有可能一致。
如果放弃了序列信息, 则模型学习时间或者趋势类的信息就不会那么强了,所以基于了这样的一个动机, 阿里又对DIN模型进行了改进, 形成了DIEN模型的结构。 这个模型既然是从DIN上改过来的,那么大部分东西都是相似的,比如输入+embedding+连接+全连接+输出的整体架构。而修改的部分就是在用户历史行为那里(下图的绿框), 把之前那种用户历史行为特征,然后embedding,然后基于Attention网络求权重,最后加权组合表示用户的兴趣这一波操作换成了更高级的用户兴趣进化模拟过程,采用了一个“兴趣进化网络”。这里先把DIN模型的架构再拿过来,方便和DIEN的架构对比:
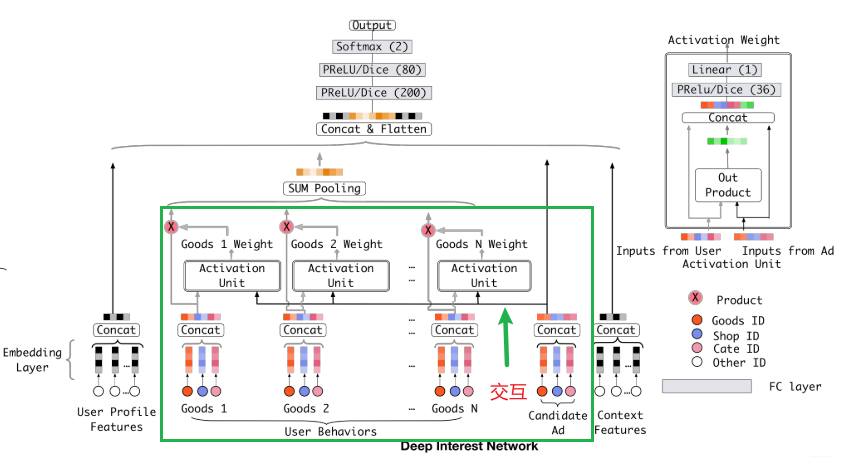
上面这个是DIN模型的架构,下面我们看一下DIEN的结构, 一定要注意和上面这个对比,再结合我上面说的替换操作看,就会发现这个模型也没有多大的神秘感:
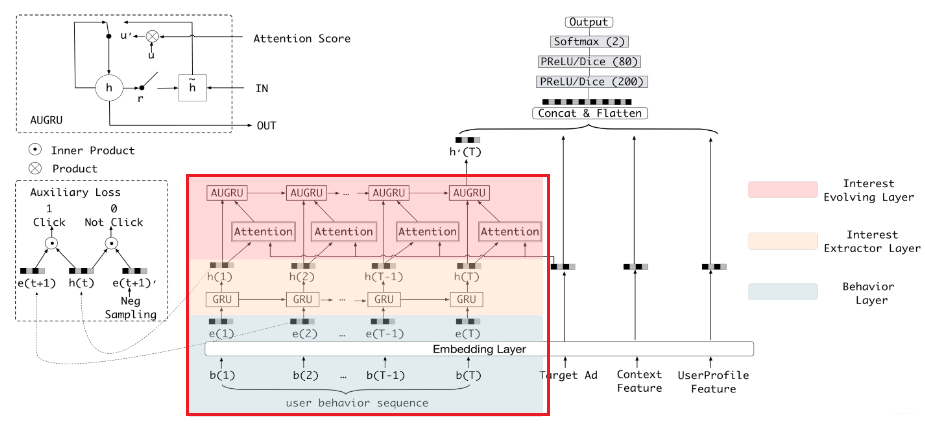
这里我们细品一下, 就会发现DIEN进化的地方就是由绿框变成了红框里面的结构,其他地方其实是一样的。所以下面就是重点剖析下这个红框,也就是"兴趣进化网络”的设计思路,看看修改成了下面这个东西之后,为啥可以能动态模拟用户的兴趣了呢?这个兴趣进化网络主要有三部分组成(从下往上, 不同颜色块):
- 行为序列层(Behavior Layer):主要作用是把原始的id类行为序列转成Embedding行为序列, 和DIN下面的Embedding层一样。
- 兴趣抽取层(Interest Extractor Layer): 主要作用是通过模拟用户的兴趣迁移过程,抽取用户兴趣,DIN模型没有这个东西。这个也就是DIN的不足①的改进,能够学习到历史序列行为之间的序列依赖关系,看到这个GRU相信大家就能了然了哈哈。这个是本篇论文的创新点之一,后面会详细介绍。
- 兴趣进化层(Interest Evolving Layer): 主要作用是通过兴趣抽取层在兴趣抽取层的基础上加入注意力机制,模拟与目标广告相关的兴趣进化过程。这个和DIN引入注意力的思路其实是一脉相承的, 如果看了后面的细节之后,会发现这个注意力的计算得分都是完全一致的。只不过这里这里不是把这个注意力计算的得分与兴趣抽取层的 h h h简单加权组合了,而是把这个注意力操作嵌入到了GRU更新门里面去,形成了一个AUGRU的结构, 用这个层来更有针对性的模拟与目标广告相关的兴趣进化路径。这个也是本篇论文的创新点之一,后面会详细介绍细节。
所以,理解DIEN的关键就是get上面提到了本篇论文的两个创新点,也就是兴趣抽取层和兴趣进化层的原理。当然,再介绍核心之前,我们依然从前面的基础架构操作一步步的捋过去。
2.2 DIEN的模型架构剖析
下面尝试对DIEN结构的每一层进行剖析和说明了, 逻辑上主要分为三大块
- 基线模型的介绍:这里依然是简单的过一下之前的Embedding&MLP模型的结构。
- DIEN的第一个创新点:兴趣抽取层
- DIEN的第二个创新点:兴趣进化层
从基础的Deep CTR架构开始。
2.2.1 BaseModel Review
对于基础的模型,还是之前的套路了,每个深度学习模型里面基本上也都见过, 这里我们简单的回顾。
首先,我这里总结的这些深度模型目前都属于排序模型的范畴,后面也会尝试整理召回(match)的相关模型,在排序模型中,接收的输入特征大体上分为四个部分: 用户画像特征(性别,年龄,职业等),用户的历史行为特征(用户的历史行为点击商品id列表, 类别列表等),物品的画像特征(物品的特征,偏类别型,商品id,商铺id等)和上下文特征(设备id,时间等)。 那么,我们就需要先对这不同的特征进行预处理的相关工作。
- 离散特征,一般需要先OneHot编码,然后进行embedding
- 连续特征, 一般需要归一化标准化操作,然后等待最后的拼接即可,深度模型的好处就是不用我们做太多的人工交叉操作,而是让模型自己学这种交叉信息。还有一种处理方式就是分桶转成离散,然后和离散的一块OneHot,embedding等操作。
所以会看到一般论文里面说上面这个流程的时候,不会提及连续特征的处理方式,因为大部分遇到的推荐场景的特征都是离散居多,连续的非常少,像年龄这种的话,如果是连续,可以分桶转离散。所以重点就是离散特征的处理了。
离散特征经过OneHot之后,一般是非常稀疏且维度很大的, 于是乎,先经过embedding的操作转成低维稠密向量几乎是特征处理的标配操作了。DIEN原论文里面也介绍了这个模块,不过这里主要是说用户行为特征的embedding过程,以及embedding之后的表示,其实所有的类别特征都得经过一个这样的过程。这里分开介绍一下吧,主要是把用户行为列表里面的idembedding和普通的类别特征embedding分开来说。论文里面这个地方我第一次读了之后反而有点懵逼,缓了好一会才知道了在说啥,主要是咱英文水平有限,再加上符号好多,并且一开始不知道他主要描述的用户历史行为特征,所以维度上一开始没反应过来,后来反应过来了才发现人家说的是咋回事,果然,大佬一般说话都是简洁性的,一点都不说废话,不像我哈哈,唉,惭愧惭愧, 现在一不留神就会出来很多”废话“,毕竟我的初衷是想让学习知识有更多的趣味性且通俗易懂,而不是发顶会嘿嘿。
先说普通的类别特征处理,这个就是一般的经过embedding层,就可以得到每个特征(域)下面的每个值的embedding向量, 当然这里其实真正实现的时候,在之前的文章里面也写过,可以不进行OneHot,因为我们OneHot再用这个只有一个1其余都是0的向量乘以我们的embedding矩阵取出相应的embedding向量,这个过程其实就是拿到与1那个索引对应的embedding向量, 这时候实现就可以直接LabelEncoder的操作,把类别特征转换成一列数字, 然后直接取对应索引的embedding向量即可。当然,具体实现的时候往往会用TensorFlow或者Pytorch的embedding层,这个会帮我们解决上面这个问题,按照人家的输入来就是了。
然后就是用户行为序列里面的各个商品的embedding, 这个其实是和上面的原理一样,只不过这里是一个列表,里面是用户的各个点击商品id,这样得到embedding之后,就是一个矩阵了,毕竟每个商品都对应一个embedding向量。 这样再看论文里面的这种表示应该就会舒服很多,比如这个
x b = [ b 1 ; b 2 ; ⋯ ; b T ] ∈ R K × T , b t ∈ { 0 , 1 } K \mathbf{x}_{b}=\left[\mathbf{b}_{1} ; \mathbf{b}_{2} ; \cdots ; \mathbf{b}_{T}\right] \in \mathbb{R}^{K \times T}, \mathbf{b}_{t} \in\{0,1\}^{K} xb=[b1;b2;⋯;bT]∈RK×T,bt∈{0,1}K
这个就代表某个用户的行为列表embedding之后得到的矩阵, K K K是embedding的维度, 而这个 T T T就是列表的长度(一共点击了多少个商品)。而论文里面的Embedding那一块,其实就是在说我上面说的那个事情,就是某个域里面某个取值的embedding向量是怎么拿到的,以及用户行为序列的embedding矩阵是怎么回事等。比如那个 e b = [ m j 1 , m j 2 , . . m j T ] , E g o o d s e_b=[m_{j1}, m_{j2}, ..m_{jT}], E_{goods} eb=[mj1,mj2,..mjT],Egoods等,都在表示embedding之后的用户列表。而通过1选相应embedding的操作,就是普通类别的那种操作了, 应该不用多解释。
把类别特征处理好之后, 如果是普通的类别特征, 我们也是等待后面的拼接就完事了, 而用户的历史行为特征,往往还会加以利用和学习,比如DIN的这个加了一个注意力机制,算了一波与当前候选广告的相关性,然后再加权组到一块,DIEN这里加了一个“兴趣进化网络”去抽取用户的兴趣,模拟用户的兴趣迁移过程等, 所以通过这样加以利用和学习之后, 得到一个类似于可以反映用户兴趣的一个向量, 把这个和普通类别特征的embedding,连续特征等concat起来。再经过MLP和输出层就可以得到预测结果了, 根据预测结果与真实label形成监督训练,计算误差,反向传播更新各个模块的参数,最终就得到了模型。
基本上深度模型排序这块的逻辑都是这样, 损失的话这里大部分都用二分类交叉熵损失(CTR预测):
L target = − 1 N ∑ ( x , y ) ∈ D N ( y log p ( x ) + ( 1 − y ) log ( 1 − p ( x ) ) ) L_{\text {target }}=-\frac{1}{N} \sum_{(\mathbf{x}, y) \in \mathcal{D}}^{N}(y \log p(\mathbf{x})+(1-y) \log (1-p(\mathbf{x}))) Ltarget =−N1(x,y)∈D∑N(ylogp(x)+(1−y)log(1−p(x)))
关于这个的话,就基本上不用多说了,学了逻辑回归,这个应该会推导以及默写了吧哈哈。
好了,关于深度模型的预测全貌基本上是上面这个过程,下面就重点来聊聊DIEN的“兴趣进化网络”了, 上面也提到了针对用户的历史行为特征, DIEN这里会弄这样的一个网络来模拟用户兴趣演化,那么是怎么搞的呢?
作者这里首先提到了在线广告展示和赞助性的搜索的不同,在线展示广告等许多电子商务平台中,用户的意向并不明确,所以捕捉用户的兴趣和动态变化对于CTR预测是很重要的。而DIEN致力于捕获用户兴趣和模型兴趣的演进过程。 这个捕获主要依赖着两大模块,就是下面要介绍的两个重点内容了。
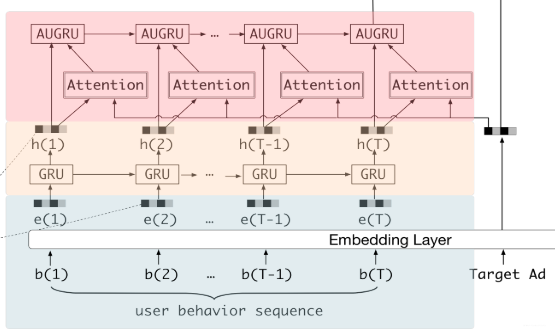
这里又把DIEN的核心结构拿出来了,这里的第二块,米黄色那块,就是兴趣提取层, 而红色那块就是兴趣进化层, 宏观上看, 这两层,其实就是一个两层的GRU网络,只不过有些不同,这里先概述,下面再具体介绍。
- 第一层GRU(兴趣抽取层)这里训练的时候,采用的是类似机器翻译的那种训练方式,每一个时间步都会有个输出,并且与真实的label形成一波损失,帮助监督和更新(auxiliary loss),记得吴恩达老师说这种结构叫多输入多输出。
- 第一层GRU得到各个时间步的隐藏状态之后, 会通过一个注意力机制得到每个隐藏状态与当前候选广告的关联得分, 这个操作和DIN那里的一模一样。
- 第二层GRU想办法把这个得分融入进了GRU里面去(AUGRU的话是改变了GRU内部的前向传播过程了,具体的讲是改了更新门计算方式)
如果没看过原论文的话,对我上面说的应该是不知所云的感觉, 这里我只是概括了下DIEN的创新点,读完了之后,其实发现也没有多大神秘,基本上是NLP里面的常规操作,唯一感觉较新的就是改GRU的更新门的这个计算(AUGRU)。 下面就具体看看了。 看完了下面的再回来看上面的,就有种悟了的感觉哈哈。
2.2.2 兴趣抽取层(Interest Extractor Layer)
在电子商务系统中,用户的行为是潜在兴趣的载体,用户的行为一旦发生,兴趣就会发生变化。在兴趣提取层,干的事情就是从连续的用户行为中提取一系列的兴趣状态,。 这里如果不太理解这些, 那我尝试在用白话说说, 干的事情是这样的, DIN那里我们一直说每个历史点击商品时间是没有啥关系的, 这样带来的问题就是没法学习到序列信息或者用户的兴趣演化过程,毕竟,让我们想的话, 这些行为序列既然是随着时间排列好的,短时间内相邻的几个行为应该是有关系的, 即使没有关系, 如果我们能串起来的话,或许也能学习到这样的一个变化过程,比如先点了几个与衣服相关的商品, 又点了几个与鞋子相关的商品,再点了几个化妆品, 如果模型能够把这几次点击串联起来学习,说不定模型会学习到“这个小姐姐好像是在精心的打扮自己,难不成要去相亲?,如果这样的话给她推荐几款新的装饰女性外表的广告或者商品是不是可以?”, 哈哈,当然我这是举了个例子,真实的情况应该没我这么智能。通过这样的串联,就能把用户的兴趣给演化出来。 那么什么模型适合这种序列数据的串联呢? 大喊一声“RNN”, 如果连这个也喊不出声, 建议先去补补深度学习的知识, RNN模型是典型的序列模型了,关于具体原理这里不说了,我之前写了两篇博客重温了RNN和LSTM,GRU, 具体内容可以去那里看看。
兴趣提取层这里采用了RNN的进化变体之一的GRU(Gated Recurrent Unit)结构, 这个相比于传统的RNN, 解决了梯度消失问题, 而相比于大名鼎鼎的LSTM, 参数数量更少,训练收敛速度快,所以对于这种大数据量的电商推荐,用GRU得到了效率和表现之间的平衡。GRU的公式如下:
u t = σ ( W u i t + U u h t − 1 + b u ) r t = σ ( W r i t + U r h t − 1 + b r ) h ~ t = tanh ( W h i t + r t ∘ U h h t − 1 + b h ) h t = ( 1 − u t ) ∘ h t − 1 + u t ∘ h ~ t \begin{array}{l} \mathbf{u}_{t}=\sigma\left(W^{u} \mathbf{i}_{t}+U^{u} \mathbf{h}_{t-1}+\mathbf{b}^{u}\right) \\ \mathbf{r}_{t}=\sigma\left(W^{r} \mathbf{i}_{t}+U^{r} \mathbf{h}_{t-1}+\mathbf{b}^{r}\right) \\ \tilde{\mathbf{h}}_{t}=\tanh \left(W^{h} \mathbf{i}_{t}+\mathbf{r}_{t} \circ U^{h} \mathbf{h}_{t-1}+\mathbf{b}^{h}\right) \\ \mathbf{h}_{t}=\left(\mathbf{1}-\mathbf{u}_{t}\right) \circ \mathbf{h}_{t-1}+\mathbf{u}_{t} \circ \tilde{\mathbf{h}}_{t} \end{array} ut=σ(Wuit+Uuht−1+bu)rt=σ(Writ+Urht−1+br)h~t=tanh(Whit+rt∘Uhht−1+bh)ht=(1−ut)∘ht−1+ut∘h~t
注意,这里这个指得是某个GRU单元里面的计算过程, 很多GRU单元从时间维度连接起来就组成一层的GRU, 纵向连接的话就组成了多层的GRU。 好吧,还是上个cell图吧:

这里的公式和上面是一样的道理。 这里想掰扯的是上面那个公式中, 各个字母的含义以及它们的维度,这样才能真正理解一个GRU里面是怎么计算的,其他的都是一样的计算方式。
- 首先,等号左边的四个 u t , r t , h ~ t , h t \mathbf{u}_{t}, \mathbf{r}_{t}, \tilde{\mathbf{h}}_{t}, \mathbf{h}_{t} ut,rt,h~t,ht分别表示GRU的某个时间步 t t t的更新门,重置门,当前状态信息计算, 隐藏状态信息, 关于这几个是干嘛的,这里不多讲,参考我这篇文章, 大白话整理的透透的。维度的话对于一个样本来说,是向量, n H × 1 n_H\times1 nH×1。 n H n_H nH表示的是隐藏单元的个数。
- 这里的 W W W系列是GRU要学习的参数, 维度是 n H × n I n_H\times n_I nH×nI的,这里的 n I n_I nI是输入向量的维度,由于 t t t时刻的话只会有一个商品embedding向量,所以这里的 i t i_t it是 n I × 1 n_I\times 1 nI×1, 这里的 n I n_I nI其实就是embedding的维度。
- 这里的 U U U系列也是学习参数, 维度是 n H × n H n_H\times n_H nH×nH的。
- 这里的 h t h_t ht系列是隐藏层的单元输出, 维度是 n H × 1 n_H \times 1 nH×1的,也就是一个向量(这里拿一个样本说的哈), 表示的某个时间步 t t t的隐藏状态信息。
- 这里的 b b b系列是偏置单元, 维度是 n H × 1 n_H \times 1 nH×1的, 也是学习参数。
- ∘ \circ ∘表示点乘, σ \sigma σ表示sigmoid函数。
这样就可以跟着上面这几个算算是不是对应上了。这里都先不考虑样本的维度。图右边的那个公式是一个向量化版本, 把所有时间步 t t t的这些都合并起来一块算了。最好是先理解论文里面这种单个时间步算的,然后合并就容易理解了。
说明虽然说了半天的GRU计算, 但这个玩意不是这里的关键,并且像深度学习框架里面都已经集成好了, 要实现这个东西,直接调个函数就搞定了。这里剖析是为了加深理解。 下面说重点了。
DIEN这里用了一个GRU网络,来对用户的历史行为进行抽取得到兴趣的抽象表示, 上面说的从连续的用户行为中提取一系列的兴趣状态,这个兴趣状态其实就是每个时间步的隐藏层的状态输出 h t h_t ht。这里考虑的是加入了这个GRU之后, 每个历史点击行为就从时间的维度串联起来了(GRU就是干这个事情的), 这样就能够学习到一些行为之间的关联或者序列的一些信息。那么作者在这里改了啥东西呢? 是的,GRU的训练损失
这里引进了一个叫做“auxiliary loss”的东西,帮助监督更新这一层的GRU参数, 这东西一开始会感觉高大上, 但看了计算公式之后会觉得不是多么神秘:
L a u x = − 1 N ( ∑ i = 1 N ∑ t log σ ( h t , e b i [ t + 1 ] ) + log ( 1 − σ ( h t e ^ b i [ t + 1 ] ) ) ) \begin{aligned} L_{a u x}=-\frac{1}{N}\left (\sum_{i=1}^{N} \sum_{t} \log \sigma\left(\mathbf{h}_{t}, \mathbf{e}_{b}^{i}[t+1]\right)+\log \left(1-\sigma\left(\mathbf{h}_{t}\hat{\mathbf{e}}_{b}^{i}[t+1]\right)\right)\right) \end{aligned} Laux=−N1(i=1∑Nt∑logσ(ht,ebi[t+1])+log(1−σ(hte^bi[t+1])))
先解释下这个公式之后再解释为啥要引入这个东西吧, 这里写的时候发现逻辑和论文里面的不太一样了, 所以索性我这里先介绍改进的点,后面解释作者用这个东西的原因。 这个式子就是GRU这里用的损失函数。至少第一眼应该能认出二分类交叉熵的格式。 这里的 N N N表示的是行为embedding序列的对数,后面采样那里就明白了, t t t是时间步的个数,也就是用户行为列表长度, h t h_t ht是当前时间步隐藏状态, e b i [ t + 1 ] e_b^i[t+1] ebi[t+1]表示的是下一个时间步的输入embedding。 这里是想让每一步的隐藏状态尽量的接近下一个时间步的输入embedding。 所以才采用了这样的类似二分类交叉熵的一种方式。这里的 σ ( x 1 , x 2 ) = 1 1 + exp ( − [ x 1 , x 2 ] ) \sigma\left(\mathbf{x}_{\mathbf{1}}, \mathbf{x}_{\mathbf{2}}\right)=\frac{1}{1+\exp \left(-\left[\mathbf{x}_{1}, \mathbf{x}_{2}\right]\right)} σ(x1,x2)=1+exp(−[x1,x2])1,也是sigmoid函数, 不过我这里的疑问是这种向量的sigmoid应该咋算? 这个先抛在这里,后面看代码的时候,会介绍这里的损失细节计算。先理解这个公式的含义,反正这个损失的作用呢? 就是让当前时刻输出的隐藏状态 h t h_t ht尽量的与下一个时刻用户点击的行为embedding相似,与下一个时刻里面用户没有点击过的行为embedding越远。下面我们再来对比和之前的GRU。
原来的GRU是只在最后一个时间步进行输出,然后与真实label进行了一个交叉熵的计算, 而改进的这个核心点是每个时间步都会有一个输出,然后都会与一个label进行一个交叉熵计算, 所以这里就会多出了时间步 t t t维度上的加和损失,还有点不同就是label这里,当前时间步用的label是下一个时间步的输入值。如果有些NLP基础,尤其是看过Seq2Seq模型架构的话,就会发现这里的改进又是常规操作了。这里拿个Seq2Seq里面的解码器部分看一下下:

这样看是不是会有些感觉了,反正给我的感觉就是每一步里面都会输出一个预测值,然后求损失。只不过这里求损失的方式换成了二分类交叉熵, 而上面编码器这种更像是多分类的softmax。并且之前的GRU,就相当于只有最后一个时间步输出的RNN了, 编码器的感觉有木有,哈哈。

好了,这里说完了改进的这个点之后, 再看一下为啥作者要这么改呢?

这里的一句话总结就是:中间隐层状态没有办法进行监督。这个原理我感觉真的和解码器那边的机器翻译类似, 我们如果只用一个label的话,比如输入一个用户的历史item点击序列 [ I 3 , I 5 , I 7 , I 8 , I 1 , I 2 ] [I_3,I_5, I_7, I_8, I_1, I_2] [I3,I5,I7,I8,I1,I2], 假设对应的label是 I 9 I_9 I9, 如果用这个训练GRU, 就会发现这些历史点击行为都是为最后的点击商品服务的,也就是通过一系列的时间步上的时间传播之后, 尽量的让模型预测出 I 9 I_9 I9。 这时候就会发现,这所有的中间隐层状态的更新全部依赖了最后的那个交叉熵损失。 这时候其实是不合理的,就像作者说的, 目标商品的行为是由最后的兴趣触发, 但是前面的那些时间步或许和目标商品并没有太大的关系,就像我上面举得那个兴趣在演化的例子,用户兴趣经过了一系列变化,这种情况显然用目标商品去更新前面时间步的中间隐藏状态就不合理了呀。所以作者在这里改进了这个损失的计算方式,因为我们都知道, 每个相邻的时间步之间的兴趣状态信息应该是非常相关的(这里其实又和NLP对上了,中心词往往和相邻上下文单词关联性较大,利用这个原理训练word2vec, 学习知识最好能进行串联)。所以这里作者提出了一个auxiliary loss, 让每个时间步都会有个输出, 而这里的label用的是下个时间步的输入 b t + 1 b_{t+1} bt+1, 这样就是相当于用下个时间步的输入去监督训练当前时间步的隐藏状态 h t h_t ht。当然,这里具体的训练方式是采用了一种二分类的训练方式,这个倒是和解码器那种不一样了, 那个更像是一个多分类的任务。 这里是二分类,也就是每一步的输出都在做一个二分类的任务。 除了使用真实的next行为作为正实例外,还使用从项目集采样的负实例(除了点击的项目)。

PS: 这里有没有发现word2vec那里的影子?这里每个时间步的输出在做一个二分类的交叉熵损失计算, 而word2vec那里开始做了一个多分类softmax,后来发现计算量大,采用了负采样的方式,也是转成了一个二分类的问题。 其实和这里这种原理是类似的。这里其实也可以和解码器那里一样用多分类交叉熵损失的,只不过商品的话数目庞大,这种多分类计算量太大,不如用负采样的方式转成二分类问题来的容易。
有了这个auxiliary loss的帮助, 每个隐藏状态 h t h_t ht的的更新变得更合理,也更能表示用户在进行了 i t i_t it次点击行为之后的兴趣状态了。作者在这里总结了auxiliary loss的几个优点,这里一块总结下:
- 使得每个隐藏层能合理训练,充分表达用户当前兴趣
- 降低反向传播的难度
- 为embedding矩阵提供了更多语义信息,方便这个东西的学习
理论上, 在兴趣状态向量序列的基础上, GRU网络已经可以做出下一个兴趣状态向量的预测, 那么为啥DIEN在上面又进一步搞了个兴趣进化层呢?
这个操作实际上是延续了DIN那里的思路的, 简单的理解,其实兴趣提取层的输出,也就是每个时间步输出的 h t h_t ht,其实就相当于加了序列兴趣信息的用户行为向量 b t b_t bt,DIN那里是直接用的 b t b_t bt的哈。但加完了之后, 还是考虑了DIN那里引入Attention的原因,也就是DIEN在模拟兴趣进化的过程中,也是需要考虑与目标广告之间的相关性的。
所以在兴趣抽取层上面加上了兴趣进化层,就是为了更有针对性的模拟与目标广告相关的兴趣进化路径, 由于阿里巴巴这类综合电商的特点, 用户非常有可能同时购买多类商品,比如在购买“机械键盘”的同时还在查看“衣服”品类的商品,那么这时候注意力机制就显得格外重要。 而当目标广告是某个电子产品的时候,用户购买“机械键盘”相关的兴趣演化路径显然比购买“衣服”的演化路径重要。 这样的筛选功能在兴趣抽取层是没法做到的。下面就看看兴趣进化层是怎么做到这一点的呢?
2.2.3 兴趣进化层(Interest Evolving Layer)
作者在论文中总结了用户兴趣在演化过程中的两个特点:

基于上面这两个兴趣的演化特征,作者结合注意机制的局部激活能力和GRU的顺序学习能力,构建了兴趣进化模型。相比兴趣提取层,兴趣进化层最大的特点就是加入了注意力机制, 这个注意力机制的分数计算和DIN是完全一样的,也是根据兴趣提取层在每个时间步的输出 h t h_t ht与当前候选广告之间的关联性大小计算的,计算公式如下:
a t = exp ( h t W e a ) ∑ j = 1 T exp ( h j W e a ) a_{t}=\frac{\exp \left(\mathbf{h}_{t} W \mathbf{e}_{a}\right)}{\sum_{j=1}^{T} \exp \left(\mathbf{h}_{j} W \mathbf{e}_{a}\right)} at=∑j=1Texp(hjWea)exp(htWea)
这个计算分数的公式其实和DIN那里是一样的, 只不过这里的输入换成了 h t h_t ht而不是原来的 b t b_t bt, 毕竟这个 h t h_t ht经过了第一层的兴趣抽取,蕴含了行为点击的序列表征信息。这里的 e a e_a ea是候选广告的embedding向量, 维度是 n A × 1 n_A \times 1 nA×1, n A n_A nA是候选广告特征的embedding维度。这里的 W W W是参数矩阵,维度是 n H × n A n_H\times n_A nH×nA, n H n_H nH是兴趣抽取层GRU隐藏状态的维度, h t h_t ht是某个时间步 t t t的兴趣抽取层GRU的隐藏状态, 维度是 1 × n H 1 \times n_H 1×nH, 整体上是个softmax的操作, 这样我们就可以算一下,最后的 a t a_t at是一个数值分数,表示的是当前时间步的兴趣序列特征 h t h_t ht与当前候选广告的关联程度, 这个值越大,说明当前的 h t h_t ht与候选广告更加相关,值的我们关注。 还有一个小细节,就是上面这种Attention机制使用的形式 h t W e a h_tWe_a htWea,是一种双线性的形式,Attention机制的几种不同表示形式:
从权值分布 α \alpha α的计算角度
- 内积: 两个向量直接内积, 因为内积可以衡量两个向量的相似程度嘛 α = V T U \alpha = V^TU α=VTU
- 全连接: 过一层全连接神经网络之后再做内积。 增加非线性 α = V T t a n h ( W T U + b ) \alpha = V^Ttanh(W^TU+b) α=VTtanh(WTU+b)
- 双线性: α = V T W U = V T ( l T h ) U = ( l v ) T ( h U ) \alpha = V^TWU = V^T(l^Th)U=(lv)^T(hU) α=VTWU=VT(lTh)U=(lv)T(hU) 双线性的理解
attention的q,k,v的角度 —> 自注意力, 这个就是大名鼎鼎的transformer所有的注意力机制了,具体的可以看我整理的一篇论文笔记《Attention is all you need》
那么计算出这个 a t a_t at来之后,怎么和第二层的GRU结合起来模拟兴趣的演化呢? 论文里面介绍了三种方式:
-
GRU with attentional input(AIGRU):这种方式是影响兴趣进化层的输入,和seq2seq那种利用attention的机制类似,大多数加注意力的方式都是这么玩,这里可以拿个图对比下:
计算公式如下:
i t ′ = h t ∗ a t \mathbf{i}_{t}^{\prime}=\mathbf{h}_{t} * a_{t} it′=ht∗at
直接拿的 a t a_t at乘上了兴趣抽取层的隐藏兴趣状态,得到一个新输入 i t ′ i_t^ {\prime} it′, 把这个作为下一层GRU的输入。这个新输入就类似于上面seq2seq里面的上下文变量c。从直观上看,这个操作貌似是可行,毕竟通过注意力分数高低就可以看到当前时间步的输入与候选广告的相关程度, 如果很低的话,这个输入值就会很低,甚至可以减少到0, 这样应该能相对于候选广告对用户的兴趣演化趋势建模了吧。 哈哈,其实这个的效果并不好,为啥呢? 因为即使这个输入减少的0, 也依然能改变GRU的隐藏层状态不是吗? 看更新公式后两项:

i t i_t it为0了, 这里的 h t h_t ht也是可以照常计算的对吗,所以作者认为即使是非常不相关的兴趣也会影响兴趣演化层的学习。如果你说, 上面这种seq2seq难道不会出现这种问题吗? 其实我只是说影响输入的这种思路类似,具体计算那个和这里不一样的,比如人家那个计算注意力分数的时候是解码器前一个时刻的隐藏状态与编码器各个隐藏状态的输出之间计算的,而这里是候选广告与兴趣抽取层的隐藏状态, 这个候选广告是压根不走GRU的。 既然这个不行了, 还有别的方式吗? -
Attention based GRU(AGRU): 这种方式是该GRU结构了,把这个 a t a_t at嵌入到GRU里面去直接影响隐藏状态的更新。从而影响兴趣的演化过程,和上面那个区分开哈,上面那个是影响了输入,而这里是影响了隐藏状态的更新, 看AGRU的更新公式就明白了:

和上面图片的最后一步对比一下子, 这里会发现, AGRU当中,是拿这个 a t a_t at替换掉了更新门。这个能够缓解上面AIGRU的问题, 比如某个时间步 t t t的兴趣 h t h_t ht与当前候选广告一点关系都没有, 即 a t a_t at为0, 这时候代入公式会发现AGRU的隐藏状态更新直接用前一个时刻的。同理,如果前一个时刻的 h t − 1 h_{t-1} ht−1也和当前候选广告无关,那么就继续用前一个时刻的, 这也就是说, 如果前面某个时间步的隐藏状态与当前候选广告相关了,极端情况是非常相关, 那么这时候更新AGRU的隐藏状态为当前这个非常相关的兴趣, 通过上面这种机制,AGRU能够保证只关注和当前候选广告相关的兴趣演化过程。不像AIGRU那样, 即使不相关的兴趣也能够影响演化。但这个有啥问题呢? 那就是忽视了不同维度上值的重要性, 这是啥意思? 我们知道这个过程中是 a t a_t at直接替换了原来GRU的更新门 u t u_t ut, 但其实这俩是有区别的, 非常明显的一个就是 a t a_t at只是一个数, 而 u t u_t ut是一个向量,维度是 n H × 1 n_H \times 1 nH×1, 用一个标量直接替换向量会忽略了 h t h_t ht系列不同维度上的重要性,我们可以想想, h t h_t ht系列是个向量,之前隐藏状态更新的时候,由于是更新门,这是个向量,每个维度值应该不一样, 这时候点乘 h t h_t ht的时候,不同维度上乘的系数会不一样,这样能够保持不同维度的重要性。 而这里换成标量之后, 相当于 h t h_t ht的每个维度都乘以相同的系数了, 不同维度的重要性就忽略了呀。一个小细节就是公式里面的 ∘ \circ ∘换成了 ∗ * ∗。向量点乘和标量相乘的区别。 -
GRU with attentional update gate(AUGRU): 这就是作者提出的更新了, 为了解决上面的这个小问题, 作者决定让这个 a t a_t at去影响更新门而不是直接影响隐藏状态, 公式变成了这样:

这时候, AUGRU既保留了AGRU的优点, 能够让与当前候选广告相关的兴趣合理演化而不受非相关兴趣的影响, 又克服了AGRU忽略了兴趣在不同维度上的保持重要性的不足,因为这个并没有改变更新门的向量维度,依然是向量,依然每个维度可以决定兴趣相应维度的重要性。

所以兴趣演化层这里作者的创新思路是通过改变GRU的内部结构,准确的说应该是新搞了个更新门,成功把注意力得分融合了进去,得到了AUGRU,这个东西能使得每一步的局部激活都能强化相关兴趣的作用,减弱兴趣漂移的干扰,有助于模拟相对目标项目的兴趣演化过程。
到这里,关于DIEN的理论部分介绍完毕了。
2.3 论文的其他细节
关于论文里面的其他细节,DIEN这里介绍的并不如前面的几个模型丰富,做实验这里也是比较常规的方式, 用了亚马逊的公开数据集(Electronics和Books两个子集)和淘宝的工业数据及做的实验, 对比了几个先进的模型(W&D, PNN , DIN, Two layer GRU attention), 结果证明提出的DIEN方法会更好些。
然后做了消融研究实验, 验证了提出的AUGRU和auxiliary loss 的有效性。
这里整理几个线上服务时用到的技术吧, 因为序列模型有比较高的训练复杂度,使其在线上服务过程中延迟较大, 所以序列模型工程化还是非常重要的, 论文里面提到了几个服务技术提高服务的性能:
- element parallel GRU 和 kernel fusion: 融合了尽可能多的独立内核。此外,GRU隐藏状态的每个元素都可以并行计算
- Batching: 不同用户的相邻请求合并为一批,以充分利用GPU
- Model compressing with Rocket Launching: 我们使用(Zhou et al. 2018b)中提出的方法来训练一个light网络,它的规模较小,但性能接近更深和更复杂的网络。例如,在Rocket Launching的帮助下,GRU隐藏状态的维度可以从108压缩到32。 这个技术第一次听说,也不知道具体怎么用的, 这里先记录,后面实际过程中如果用到了,再去看这里面提到的这篇论文了。现在没有接触工业上的东西,估计看了也不知道说啥事情。
关于DIEN的理论就先介绍到这里吧, 下面就从代码的角度再去看这个模型具体实现过程中的细节部分了。
3. DIEN模型的代码复现
DIEN这里的代码复现过程参考了Deepctr的代码, 写了一个简化的版本,看过deepctr之后,发现tf的函数式API方式比较帅,所以这里用了这种风格的代码,当然,之前的那些模型,我也会相应的在我GitHub项目中补充这种风格的代码实现过程。上一篇的DIN模型我已经补充了Deepctr风格的代码, 这次DIEN是从上面的DIN基础上改的,毕竟这是个进化版本,有很多东西都是一致的, 比如数据的处理格式,Attention层等, 如果感觉后面的代码读起来有压力,可以先看看DIN的。 当然这里我正好顺便借着这个机会梳理下这种代码风格。关于代码的整理逻辑,这里不过多说了,还是数据处理,建立模型,然后预测的逻辑,只不过之类的建立模型风格相比之前的pytorch代码会有所改变,具体的可以参考后面的GitHub了。 下面梳理DIEN的代码细节。
3.1 数据处理部分
这里也有两个小细节和前面不一样。首先,这次使用的数据集是deepctr里面的movielens数据集,数据集的处理过程这里不多说,可以参考GitHub代码,这里说一下注意的点或者和DIN不同的地方。 首先,这里的数据集格式长下面这样:
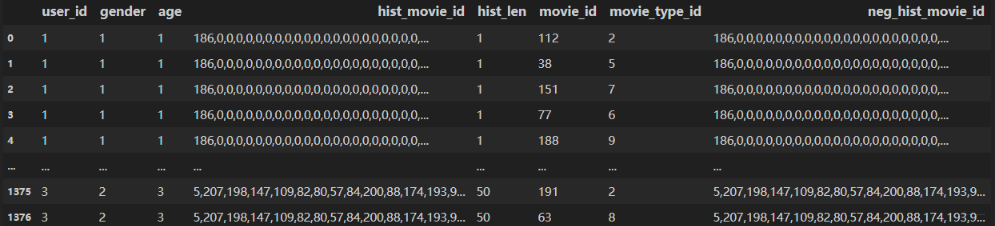
这里的第一个细节就是这次的数据会有个neg_hist_movie_id列,这个是基于用户的历史行为进行的负采样的行为,不过这里我为了先调模型,并没有去采,而是直接等于了历史行为了。 这里应该在制作数据集的时候就采这块。 并且针对一个历史行为可以采多个负行为, 而这里就相当于一个正行为对应一个负行为了。
第二个细节就是这里需要弄一个一维数组来记录每个用户的历史行为长度,方便后面Attention时进行mask的操作。
behavior_len = np.array([len([int(i) for i in l.split(',') if int(i) != 0]) for l in X['hist_movie_id']])
这个东西要传入兴趣进化网络里面去,第一个就是方便attention那里的mask操作,第二个,就是这里的兴趣提取,采用了动态的GRU实现, 需要这个东西告诉GRU每个序列的实际长度。
3.2 DIEN网络的代码全貌
下面开始DIEN网络, 这里先放一个全貌,然后简单的解释下这个风格。
def DIEN(feature_columns, behavior_feature_list, behavior_seq_feature_list, use_neg_sample=False, alpha=1.0):# 构建输入层input_layer_dict = build_input_layers(feature_columns)# 将Input层转化为列表的形式作为model的输入input_layers = list(input_layer_dict.values()) # 各个输入层input_keys = list(input_layer_dict.keys()) # 各个列名user_behavior_length = input_layer_dict["seq_length"]# 筛选出特征中的sparse_fea, dense_fea, varlen_feasparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if feature_columns else []varlen_sparse_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []history_feature_columns = []neg_history_feature_columns = []history_fc_names = list(map(lambda x: "hist_"+x, behavior_feature_list))neg_history_fc_names = list(map(lambda x: "neg_"+x, history_fc_names))for fc in varlen_sparse_feature_columns:feature_name = fc.nameif feature_name in history_fc_names:history_feature_columns.append(fc)elif feature_name in neg_history_fc_names:neg_history_feature_columns.append(fc)# 获取densednn_dense_input = []for fc in dense_feature_columns:dnn_dense_input.append(input_layer_dict[fc.name])# 将所有的dense特征拼接dnn_dense_input = concat_input_list(dnn_dense_input)# 构建embedding字典embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)# 因为这里最终需要将embedding拼接后直接输入到全连接层(Dense)中, 所以需要Flattendnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)# 将所有sparse特征的embedding进行拼接dnn_sparse_input = concat_input_list(dnn_sparse_embed_input)# 获取当前的行为特征(movie)的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)# 获取行为序列(movie_id序列, hist_movie_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)# 把q,k的embedding拼在一块query_emb, keys_emb = concat_input_list(query_embed_list), concat_input_list(keys_embed_list)# 采样的负行为neg_uiseq_embed_list = embedding_lookup(neg_history_fc_names, input_layer_dict, embedding_layer_dict)neg_concat_behavior = concat_input_list(neg_uiseq_embed_list)# 兴趣进化层的计算过程dnn_seq_input, aux_loss = interest_evolution(keys_emb, query_emb, user_behavior_length, neg_concat_behavior, gru_type="AUGRU")# 后面的全连接层deep_input_embed = Concatenate()([dnn_dense_input, dnn_sparse_input, dnn_seq_input])# 获取最终dnn的logitsdnn_logits = get_dnn_logits(deep_input_embed, activation='prelu')model = Model(input_layers, dnn_logits)# 加兴趣提取层的损失 这个比例可调if use_neg_sample:model.add_loss(alpha * aux_loss)# 所有变量需要初始化tf.compat.v1.keras.backend.get_session().run(tf.compat.v1.global_variables_initializer())return model
这是一种函数式API的搭建模型的方式, 就是为了增强模型中各个模块的复用程度, 这里会把每一个重要模块单独的进行构建, 这样, 把这些模块简单的进行拼接就可以得到最终的模型,好处就是这些块也能用于搭建其他的模型。 如果看过deepctr,就会发现很多模型使用的模块都很相似。 比如建立的Input层,Embedding层, 最后的DNN网络等。这些在很多模型中都有出现,所以可以通过这种方式单独成块。这里就是采用了这种思想了。 下面解释下上面的逻辑,其实就是围绕着输入数据来的。
首先, DIEN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),也就是指的上面的历史行为数据。而不同的类型特征也就决定了后面处理的方式会不同:
- Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
- Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
- VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入兴趣进化网络,获取到用户的兴趣之后,得到输出。
通过上面的三种处理, 就得到了处理好的连续特征,离散特征和变长离散特征, 接下来把这三种特征拼接,进DNN网络,得到最后的输出结果即可。 所以上面的逻辑就非常清晰了应该, 每个模块进行解释下:
build_input_layers(feature_columns): 这个函数负责为每个特征建立一个Input层来进行接收。具体细节这里不说了。build_embedding_layers: 这个函数负责对每个离散特征建立一个embedding层,这个层会接收Input的输出,然后转成低维稠密向量。concat_embedding_list: 这个函数负责把embedding向量存放到一个列表里面concat_input_list: 这个函数负责把所有embedding在embedding的维度拼接起来, 在DNN之前要用到embedding_lookup: 这个函数负责从输入到embedding层的计算, 得到某些特征的embedding列表interest_evolution:这个就是兴趣进化网络全貌了,也是DIEN的核心,后面重点整理get_dnn_logits:这个就是全连接网络的操作,从全连接的输入映射出最终结果。
下面重点剖析interest_evolution这个模块了。
3.3 兴趣进化网络
这一块完成的操作,是从兴趣提取到兴趣演化的过程。 逻辑就是兴趣提取层, 这里是一个动态的GRUCell,得到输出之后,计算auxiliary_loss。 如果过注意力层得到score, 然后根据兴趣演化层cell的不同,会使用不同的计算方式得到输出。 代码如下:
def interest_evolution(concat_behavior, query_input_item, user_behavior_length, neg_concat_behavior, gru_type="GRU", use_neg=True):aux_loss = Noneuse_aux_loss = Noneembedding_size = None# 兴趣提取层 rnn_outputs = DynamicGRU(embedding_size, return_sequence=True)([concat_behavior, user_behavior_length]) # (None, max_len, embed_dim)# "AUGRU"并且采用负采样序列方式,这时候要先计算auxiliary_lossif gru_type == "AUGRU" and use_neg:aux_loss = auxiliary_loss(rnn_outputs[:, :-1, :], concat_behavior[:, 1:, :], neg_concat_behavior[:, 1:, :],tf.subtract(user_behavior_length, 1))# 兴趣演化层用的GRU, 这时候先得到输出, 然后把Attention的结果直接加权上去if gru_type == "GRU":rnn_outputs2 = DynamicGRU(embedding_size, return_sequence=True)([rnn_outputs, user_behavior_length]) # (None, max_len, embed_dim)hist = AttentionPoolingLayer(user_behavior_length, return_score=False)([query_input_item, rnn_outputs2])else: scores = AttentionPoolingLayer(user_behavior_length, return_score=True)([query_input_item, rnn_outputs])# 兴趣演化层如果是AIGRU, 把Attention的结果先乘到输入上去,然后再过GRUif gru_type == "AIGRU":hist = multiply([rnn_outputs, Permute[2, 1](scores)])final_state2 = DynamicGRU(embedding_size, gru_type="GRU", return_sequence=False)([hist, user_behavior_length])else: # 兴趣演化层是AUGRU或者AGRU, 这时候, 需要用相应的cell去进行计算了final_state2 = DynamicGRU(embedding_size, gru_type=gru_type, return_sequence=False)([rnn_outputs, user_behavior_length,Permute([2, 1])(scores)])hist = final_state2return hist, aux_loss
3.3.1 兴趣提取层
这个对应的是代码的上半部分,兴趣提取层这里的逻辑, 接收的输入是用户历史行为的embedding序列向量, 然后过一个GRU网络得到隐藏层状态的过程。如果这里没有论文里面的那个创新点, 就直接用GRU网络就可以,这里要注意的是使用的动态的GRU, 这个也是单独的一个模块,这里面会根据传入的GRU的cell类型选择不同的操作。这个具体就看后面的代码吧。但是论文里面的那个训练过程,是基于了“auxiliary loss”, 所以上面的那个判断是AUGRU并且采用负采样的话,就会计算这个损失,然后还把这个加到模型中。 我们重点来剖析下这个是如何完成的。
def auxiliary_loss(h_states, click_seq, noclick_seq, mask):"""计算auxiliary_loss:param h_states: 兴趣提取层的隐藏状态的输出h_states (None, T-1, embed_dim):param click_seq: 下一个时刻用户点击的embedding向量 (None, T-1, embed_dim):param noclick_seq:下一个时刻用户未点击的embedding向量 (None, T-1, embed_dim):param mask: 用户历史行为序列的长度, 注意这里是原seq_length-1,因为最后一个时间步的输出就没法计算了 (None, 1) :return: 根据论文的公式,计算出损失,返回回来"""hist_len, _ = click_seq.get_shape().as_list()[1:] # (T-1, embed_dim) 元组解包的操作, hist_len=T-1mask = tf.sequence_mask(mask, hist_len) # 这是遮盖的操作 (None, 1, T-1) 每一行是bool类型的值, 为FALSE的为填充mask = mask[:, 0, :] # (None, T-1) mask = tf.cast(mask, tf.float32)click_input = tf.concat([h_states, click_seq], -1) # (None, T-1, 2*embed_dim)noclick_input = tf.concat([h_states, noclick_seq], -1) # (None, T-1, 2*embed_dim)auxiliary_nn = DNN([100, 50], activation='sigmoid')click_prop = auxiliary_nn(click_input)[:, :, 0] # (None, T-1)noclick_prop = auxiliary_nn(noclick_input)[:, :, 0] # (None, T-1)click_loss = -tf.reshape(tf.compat.v1.log(click_prop), [-1, tf.shape(click_seq)[1]]) * masknoclick_loss = -tf.reshape(tf.compat.v1.log(1.0-noclick_prop), [-1, tf.shape(noclick_seq)[1]]) * maskaux_loss = tf.reduce_mean(click_loss + noclick_loss)return aux_loss
这个是参考deepctr写的简化版本, 通过这个就能看出这玩意到底是怎么算的,唯一和论文里面不太一样的是,这里的负采样个数,对于每一个正样本,采的负样本的个数也是1。而关于这个的具体计算,首先传入的是GRU的各个隐藏状态值, 注意这个不包含最后一个时间步,然后是点击的行为序列和未点击的行为序列,注意这俩不包含第一个时间步,所以序列长度会减1。 这里loss的实现技巧是把当前的隐藏状态和下一个时刻的正embedding拼起来,然后过一个全连接网络,得到预测正embedding的概率。 当前隐藏状态和一个时刻的负embedding拼起来,过全连接,得到预测负embedding的概率。 最后再根据公式计算交叉熵损失得到的。 解决了读论文时的疑惑。
3.3.2 兴趣进化层
兴趣进化层这里的核心或者亮点是attention得分与GRU组合的过程, 论文里面介绍了三种方式,这里也同样是用了三种方式进行的实现过程。 简单解释下:
# 兴趣演化层用的GRU, 这时候先得到输出, 然后把Attention的结果直接加权上去if gru_type == "GRU":rnn_outputs2 = DynamicGRU(embedding_size, return_sequence=True)([rnn_outputs, user_behavior_length]) # (None, max_len, embed_dim)hist = AttentionPoolingLayer(user_behavior_length, return_score=False)([query_input_item, rnn_outputs2])else: scores = AttentionPoolingLayer(user_behavior_length, return_score=True)([query_input_item, rnn_outputs])# 兴趣演化层如果是AIGRU, 把Attention的结果先乘到输入上去,然后再过GRUif gru_type == "AIGRU":hist = multiply([rnn_outputs, Permute[2, 1](scores)])final_state2 = DynamicGRU(embedding_size, gru_type="GRU", return_sequence=False)([hist, user_behavior_length])else: # 兴趣演化层是AUGRU或者AGRU, 这时候, 需要用相应的cell去进行计算了final_state2 = DynamicGRU(embedding_size, gru_type=gru_type, return_sequence=False)([rnn_outputs, user_behavior_length, Permute([2, 1])(scores) ])
这时候已经得到了兴趣抽取层的输出了,也就是兴趣抽取层的隐藏状态H, 这里就是加注意力机制,然后万层兴趣进化层计算。 这里根据兴趣进化层cell类型的不同分三种计算情况:
- 如果是GRU, 这时候,直接用动态GRU计算,此时的cell就是普通的GRU,这样得到最后的输出之后,把分数直接对应维度乘上去即可
- 如果是AIGRU,也就是改变第二层序列网络的输入,这个就是把注意力机制的分数乘到输入上去,然后过普通的GRU得到输出
- 如果是AGRU或者是AUGRU,这时候,会改变兴趣进化层的cell结构,也就是会换cell,具体代码参考DynamicGRU里面的过程。 这时候会把这个分数也作为输入的一部分了。
然后就是这个分数是怎么计算的呢? 这里使用的是注意力网络,这个和DIN的一模一样了,由于代码篇幅原因,这里就不解释了,在DIN那里,我给出了详细的注释。 这里面需要强调的一点就是mask的那个操作, 原来在层之中进行mask操作的最好方式,就是输入的时候构建一个序列长度的层, 然后用tf.sequence_mask操作。作为这篇文章的一种补充方式。 还是把注意力层的代码放一下吧:
class AttentionPoolingLayer(Layer):def __init__(self, user_behavior_length, att_hidden_units=(256, 128, 64), return_score=False):super(AttentionPoolingLayer, self).__init__()self.att_hidden_units = att_hidden_unitsself.local_att = LocalActivationUnit(self.att_hidden_units)self.user_behavior_length = user_behavior_lengthself.return_score = return_scoredef call(self, inputs):# keys: B x len x emb_dim, queries: B x 1 x emb_dimqueries, keys = inputs # 获取行为序列embedding的mask矩阵,将Embedding矩阵中的非零元素设置成True,key_masks = tf.sequence_mask(self.user_behavior_length, keys.shape[1]) # (None, 1, max_len) 这里注意user_behavior_length是(None,1)key_masks = key_masks[:, 0, :] # 所以上面会多出个1维度来, 这里去掉才行,(None, max_len)# 获取行为序列中每个商品对应的注意力权重attention_score = self.local_att([queries, keys]) # (None, max_len)# 创建一个padding的tensor, 目的是为了标记出行为序列embedding中无效的位置paddings = tf.zeros_like(attention_score) # B x len# outputs 表示的是padding之后的attention_scoreoutputs = tf.where(key_masks, attention_score, paddings) # B x len# 将注意力分数与序列对应位置加权求和,这一步可以在outputs = tf.expand_dims(outputs, axis=1) # B x 1 x lenif not self.return_score:# keys : B x len x emb_dimoutputs = tf.matmul(outputs, keys) # B x 1 x dimoutputs = tf.squeeze(outputs, axis=1)return outputs
好了,到这里DIEN模型介绍的差不多了, 具体的代码参考后面的GitHub吧。
4. deepctr中的DIEN模型的使用
知道了模型原理和代码的实现细节,下面就是真实环境下使用了,在真实使用的时候,我们一般是不会重复造轮子,自己建立模型玩的, 可以使用deepctr的工具包,里面大部分模型都实现好了,并且进行了一些优化过程。 下面整理下DIEN如果要用的话,应该怎么使用。
首先数据要封装成下面的格式:
def get_xy_fd(use_neg=False, hash_flag=False):feature_columns = [SparseFeat('user', 3, embedding_dim=10, use_hash=hash_flag),SparseFeat('gender', 2, embedding_dim=4, use_hash=hash_flag),SparseFeat('item_id', 3 + 1, embedding_dim=8, use_hash=hash_flag),SparseFeat('cate_id', 2 + 1, embedding_dim=4, use_hash=hash_flag),DenseFeat('pay_score', 1)]feature_columns += [VarLenSparseFeat(SparseFeat('hist_item_id', vocabulary_size=3 + 1, embedding_dim=8, embedding_name='item_id'),maxlen=4, length_name="seq_length"),VarLenSparseFeat(SparseFeat('hist_cate_id', 2 + 1, embedding_dim=4, embedding_name='cate_id'), maxlen=4,length_name="seq_length")]behavior_feature_list = ["item_id", "cate_id"]uid = np.array([0, 1, 2])ugender = np.array([0, 1, 0])iid = np.array([1, 2, 3]) # 0 is mask valuecate_id = np.array([1, 2, 2]) # 0 is mask valuescore = np.array([0.1, 0.2, 0.3])hist_iid = np.array([[1, 2, 3, 0], [1, 2, 3, 0], [1, 2, 0, 0]])hist_cate_id = np.array([[1, 2, 2, 0], [1, 2, 2, 0], [1, 2, 0, 0]])behavior_length = np.array([3, 3, 2])feature_dict = {'user': uid, 'gender': ugender, 'item_id': iid, 'cate_id': cate_id,'hist_item_id': hist_iid, 'hist_cate_id': hist_cate_id,'pay_score': score, "seq_length": behavior_length}if use_neg:feature_dict['neg_hist_item_id'] = np.array([[1, 2, 3, 0], [1, 2, 3, 0], [1, 2, 0, 0]])feature_dict['neg_hist_cate_id'] = np.array([[1, 2, 2, 0], [1, 2, 2, 0], [1, 2, 0, 0]])feature_columns += [VarLenSparseFeat(SparseFeat('neg_hist_item_id', vocabulary_size=3 + 1, embedding_dim=8, embedding_name='item_id'),maxlen=4, length_name="seq_length"),VarLenSparseFeat(SparseFeat('neg_hist_cate_id', 2 + 1, embedding_dim=4, embedding_name='cate_id'),maxlen=4, length_name="seq_length")]x = {name: feature_dict[name] for name in get_feature_names(feature_columns)}y = np.array([1, 0, 1])return x, y, feature_columns, behavior_feature_list
这样就能通过下面的代码直接获取输入:
x, y, feature_columns, behavior_feature_list = get_xy_fd(use_neg=USE_NEG)
下面可以直接建立DIEN模型:
from deepctr.models import DIEN
model = DIEN(feature_columns, behavior_feature_list,dnn_hidden_units=[4, 4, 4], dnn_dropout=0.6, gru_type="AUGRU", use_negsampling=USE_NEG)
模型的训练和评估就非常简单了:
model.compile('adam', 'binary_crossentropy',metrics=['binary_crossentropy'])
history = model.fit(x, y, verbose=1, epochs=10, validation_split=0.5)
5. 小总
到这里, 就把DIEN,一个又比较强大的序列推荐模型过了一遍,这篇文章拖了好长时间了,中间经历个开学,还经历了一些琐事,所以一直拖着没弄代码部分,回到学校之后,抓紧先把这个小尾巴干掉,这篇文章也超级长,因为是第一次尝试学习deepctr并使用这种代码风格,后面也会相应的把前面的模型补充上这种风格代码,因为这种代码还是有点帅哈哈。所以介绍起代码来可能会多一些。好了,开始总结了。
这篇文章基于原论文详细介绍了DIEN的改进细节部分, 核心就是兴趣进化网络,而这个网络的核心是兴趣提取层和兴趣进化层两层的操作, 这两层都引入了GRU的训练模型来模拟用户兴趣的动态变化, 顺便还有还有两个小改造, 在兴趣提取层提出了auxiliary loss来监督GRU每个中间隐藏状态的训练过程, 这个东西感觉是NLP里面的一种思路,和seq2seq的解码器那种很像,而把每一步多分类的交叉熵损失改成二分类问题又很像Word2Vec的负采样操作,哈哈,反正是似曾相识, 第二个小创新是在兴趣进化层修改了GRU更新门的计算方式, 基于原有的更新门,把注意力分数融合进了里面去, 提出了一个新结构叫AUGRU,在这个东西使得与当前候选广告相关的兴趣合理演化而不受非相关兴趣的影响, 这样更加有利于预测。
最后通过代码又看了DIEN的很多细节,比如auxiliary loss的具体计算呀, 这个AUGRU是怎么计算的,具体是怎么实现的等。由于序列模型有非常强大的时间序列表达能力, 使其非常适合预估用户经过一系列行为后的下一次动作。 实际上, 不仅序列模型用到了阿里的电商模型, YouTube,Netflix等视频流媒体公司也成功的在视频推荐模型中用了序列模型。所以序列模型与推荐系统的花火碰撞也是一种趋势性的发展了。DIEN也不是银弹,DIEN有效的两个条件:①应用场景存在“兴趣的进化” ②用户兴趣的进化过程能够被数据完整捕获。如果这两个条件其中一个不满足,DIEN就可能不会带来较大的收益。所以,构建推荐模型的过程中, 从应用场景出发,基于用户的行为和数据特点,提出合理的改进模型动机才是最重要的,一定要和具体的业务结合
这个模型从读论文到整理完这篇博客,花了好多天了,通篇下来,还是收获很多的哈哈。这样王喆老师书里面的排序模型已经学的差不多了,还差个DRN(深度强化网络),这个涉及到强化学习,估计这段时间得先补一波基础,所以这个想推迟下。 后面有两个打算,一是继续补充最新的前沿排序模型,比如加自注意力机制的AutoInt, 加transformer的BST,阿里的多兴趣网络MIND,FibiNet等,二是开始学习各种召回模型了(deep match),比如著名的双塔,水波网络和图的一些召回deepwalk, node2vec, LINE等。
但是再整理后面的这些模型之前, 我们是时候总结一下深度排序模型这里面的一些规律性的东西了,通过前面的一系列模型,大家应该隐约的有这种感觉了。只不过不知道怎么描述罢了, 下面我给大家总结下。
CTR模型的三个改进大点:显性特征交叉, 特征重要度, user历史信息的挖掘。
- 显性特征交叉: 针对的是隐性无脑交叉的DNN的不足, 针对一些重要的关键特征进行显性特征交叉, 提取出再一个层次上的重要特征来, 然后再去无脑隐性。 代表模型: PNN,NeuralFM,DeepFM,NFM,DCN等。 改进思路:①内积 ②哈达玛积 ③外积 ④DCN的交叉网络(这是个亮点思路)
- 特征重要度: 对原始特征和线性交叉特征做重要性排序,或者加权,代表模型:AFM,DIN,DIEN等。 改进思路: ①注意力机制 ②哈达玛积做交叉 ③FiBiNet里面用的双线性的思路(这个模型后期会整理)
- user历史信息的挖掘: 这个就是考虑用户的历史行为特征,对这些历史行为进行信息挖掘。 典型的DIN,DIEN,DSIN(下一篇)等。 改进思路:序列加上,然后Attention ②RNN系列的网络提取,包括transformer, 计算量大, 部署困难 ③先根据时间段分组,然后pooling ④ 引入sideinfo信息之后,分组, 然后pooling。
后面再整理网络模型的时候,我们就着重看看模型到底是从上面哪个方向进行改进的, 基本上改进的思路都围绕着上面这几个进行。由于这学期涉及到找工作, 估计后面的模型整理没有啥规律性了,先挑重点的模型,面试容易问的整理了,哈哈。
工业上常用的推荐模型:
- 传统模型:LR, GBDT+LR, FM,FFM
- Deep 模型: wide&Deep, deepFM, DIN, PNN, DCN, Fi-BiNet
常用程度:
- 第一梯队: LR, GBDT+LR, FM
- 第二梯队: DeepFM, W&D
- 第三梯队: DIN, FFM, PNN 等
所以从这里也可以看到,一些很复杂的模型, 虽然可能理论上效果比较好,但是在真正工程实践中并不是很常用。 可能的原因是部署复杂,且训练难度很大。
还要说个模型增量更新的问题, 增量训练是定时更新某层模型参数, 所以树模型是没法进行增量训练的。一训练就改变树结构了,一般,模型是梯度更新的那种,比如LR ,FM, W&D, deepFM等可以增量训练。 而GBDT+LR的话,只能增量更新LR的部分。
最后,用王喆老师书上的表对上面整理过的模型以及优缺点进行一个大总结:

参考:
- DIEN原论文
- 《深度学习推荐系统》-- 王喆
- 推荐系统遇上深度学习(二十四)–深度兴趣进化网络DIEN原理及实战
- DIEN的复现代码参考项目
- Deepctr的项目代码
整理这篇文章的同时, 也建立了一个GitHub项目, 准备后面把各种主流的推荐模型用复现一遍,并用通俗易懂的语言进行注释和逻辑整理, 今天的DIEN都已经上传, 从DIEN开始,后面的模型复现代码不仅局限于pytorch了,而是主要参考deepctr的代码风格,写简化版的并进行解释了。前面的模型也会陆续补充上deepctr风格的代码, 感兴趣的可以看一下 ,star下我会更开心哈哈😉
筋斗云:https://github.com/zhongqiangwu960812/AI-RecommenderSystem
这篇关于AI上推荐 之 DIEN模型(序列模型与推荐系统的花火碰撞)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






