本文主要是介绍Deep Neural Networks for YouTube Recommendations 工程Tricks总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Deep Neural Networks for YouTube Recommendations 2016 继项亮书后值得反复品味的推荐入门神文。
首先奉上两位大佬的博客,也是主要参考的地方。其实这篇文章已经看过两三次了,一些地方总是看不懂,直到这两天王喆大佬在某乎提供了一个大家分享经验的平台后,很多地方都理解了,一些至今仍在工程中应用的东西,原来都能在这篇文章中找到。
王喆
沙韬伟
其中关于样本age的工程实践我没有详细看,可以到上面两个地址找到。
下面主要是对两篇博客的汇总和一些简单的解释,方便自己日后查阅。
整体:
- 有监督的学习,每个视频作为一个类别,观看完成作为一个正样本,预测目标是观看的时间长度。
- 为什么要分match和rank两个阶段???
matching的模块,目的是把百万级的商品、视频筛选出百级、千级的可排序的量级;再通过ranking模块,选出十位数的展示商品、视频作为最后的推送内容。之所以把推荐系统划分成Matching和Ranking两个阶段,主要是从性能方面考虑的。Matching阶段面临的是百万级,而Ranking阶段的算法则非常消耗资源,不可能对所有目标都算一遍,而且就算算了,其中大部分在Ranking阶段排名也很低,也是浪费计算资源。
召回的本质就是解决计算的性能问题。
- 在处理测试集的时候,YouTube为什么不采用经典的随机留一法(random holdout),而是一定要把用户最近的一次观看行为作为测试集???
只留最后一次观看行为做测试集主要是为了避免引入future information,产生与事实不符的数据穿越。
- 在确定优化目标的时候,YouTube为什么不采用经典的CTR,或者播放率(Play Rate),而是采用了每次曝光预期播放时间(expected watch time per impression)作为优化目标???
这个问题从模型角度出发,是因为 watch time更能反应用户的真实兴趣,从商业模型角度出发,因为watch time越长,YouTube获得的广告收益越多。而且增加用户的watch time也更符合一个视频网站的长期利益和用户粘性
- ranking model似乎与candidate generation模型没有什么区别,模型架构还是深度学习的“基本操作”,唯一的区别就是特征工程和最后预测的函数建模softmax vs. weighted lr
- Youtube的用户对新视频有偏好,那么在模型构建的过程中如何引入这个feature?=>电商用户对展示靠前的坑位有偏好,点击率高
为了拟合用户对fresh content的bias,模型引入了“Example Age”这个feature,文中其实并没有精确的定义什么是example age。按照文章的说法猜测的话,会直接把sample log距离当前的时间作为example age。比如24小时前的日志,这个example age就是24。在做模型serving的时候,不管使用那个video,会直接把这个feature设成0。(电商就是把坑位的特征纳入 训练,serving时候直接把该特征置零、)
- 在对训练集的预处理过程中,YouTube没有采用原始的用户日志,而是对每个用户提取等数量的训练样本,这是为什么?
减少高度活跃用户对于loss的过度影响
- 针对某些特征,比如#previous impressions,为什么要进行开方和平方处理后(处理后才离散化),当作三个特征输入模型???
这是很简单有效的工程经验,引入了特征的非线性。从YouTube这篇文章的效果反馈来看,提升了其模型的离线准确度。
召回阶段

- 在进行video embedding的时候,为什么要直接把大量长尾的video直接用0向量代替?
把大量长尾的video截断掉,主要还是为了节省online serving中宝贵的内存资源。从模型角度讲,低频video特征其实去掉比embedding更好效果更好,出现次数太少emb学不好。实际也可以用HashBucket去映射,对于大规模稀疏ID类特征,实际使用上用Hash不会对结果产生太大影响,反而在增量更新的情况上可能会比置为0更好。
- 召回阶段把问题归结为多分类softmax问题后,DNN其实就是处理特征的方式!
- 用户最近看过的N(固定)个video集合embedding vector,取平均作为watch vector, 和同样处理的search tokens拼接后,再和年龄,性别等特征拼接输入第一层RELU!输入RELU中后,在最后一层的隐层输出的就是最终的user embedding。
- 对召回阶段最后的softmax层的进一步理解:
softmax层是dense+ softmax激活函数,假设最后一个hidden layer维度是100代表user embedding,输出节点维度200w表示videos,全连接权重维度就是[100,200w],而hidden layer与每一个输出节点的权重维度就是[100,1],这就是一个vedio对应embedding(权重组成video embedding),计算一个vedio的概率时是u*v,即两个100维向量做内积,是可以在一个空间的。下图中对于video1,他的embedding vector就可以是隐层输入到它的权重向量,100维。这里也存在另一种说法,可能是通过其他的方法得到这些向量,比如word2vector得到item embedding vector后直接作为item特征,直接喂给网络。(pre trained to feed)
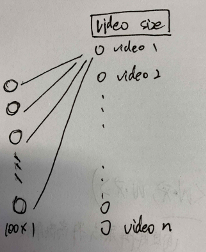
- 在预测next watch的场景下,每一个备选video都会是一个分类,因此总共的分类有数百万之巨,这在使用softmax训练时无疑是低效的,这个问题YouTube是如何解决的?
Negative sampling
提到随机负采样要由于霍夫曼树这种方法(hierarchical soft-max)!

- 召回阶段生成了召回集,serving的过程中,为什么不直接采用训练时的model进行预测,而是采用了一种最近邻搜索的方法???
是一个经典的工程和学术做trade-off的结果,在model serving过程中对几百万个候选集逐一跑一遍模型的时间开销显然太大了,因此在通过candidate generation model得到user 和 video的embedding之后,通过最近邻搜索的方法的效率高很多。我们甚至不用把任何model inference的过程搬上服务器,只需要把user embedding和video embedding存到redis或者内存中就好了。
Rank阶段

- 为什么ranking model不采用经典的logistic regression当作输出层,而是采用了weighted logistic regression???
模型采用了expected watch time per impression作为优化目标,所以如果简单使用LR就无法引入正样本的watch time信息。因此采用weighted LR,将watch time作为正样本的weight,在线上serving中使用e(Wx+b)做预测可以直接得到expected watch time的近似,完美。
- Rank阶段特征要更丰富!目的就是引入更多描述视频、用户以及二者之间关系的特征,达到对候选视频集合准确排序的目的。
- rank阶段的特征:
impression video ID embedding: 当前要计算的video的embedding
watched video IDs average embedding: 用户观看过的最后N个视频embedding的average pooling
language embedding: 用户语言的embedding和当前视频语言的embedding
time since last watch: 自上次观看同channel视频的时间
#previous impressions: 该视频已经被曝光给该用户的次数
第4个和第5个。因为这两个很好的引入了对用户行为的观察

这篇关于Deep Neural Networks for YouTube Recommendations 工程Tricks总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







