本文主要是介绍(三十八)大数据实战——Atlas元数据管理平台的部署安装,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
Apache Atlas 是一个开源的数据治理和元数据管理平台,旨在帮助组织有效管理和利用其数据资产。为组织提供开放式元数据管理和治理功能 ,用以构建其数据资产目录,对这些资产进行分类和管理,形成数据字典 。并为数据分析师和数据治理团队提供围绕这些数据资产的协作功能。
本节内容是关于Apache Atlas的部署安装,在开始安装Atlas之前我们需要提前安装好Atlas需要集成的组件,如hadoop、zookeeper、kafka、hbase、solr、hive、mysql等,关于以上组件的安装内容,可以参考作者的往期博客内容,这里不在赘述。

正文
①上传atlas部署安装包到/opt/software目录

②将apache-atlas-2.1.0-server.tar.gz安装包解压到/opt/module目录下
命令:
tar -zxvf apache-atlas-2.1.0-server.tar.gz -C /opt/module/
③ 配置atlas的环境变量,并将atlas授权给hadoop用户
- 在/etc/profile.d/my_env.sh配置atlas环境变量
- 将atlas安装包授权给hadoop用户


④atlas集成hbase组件
- 在/opt/module/apache-atlas-2.1.0/conf/atlas-application.properties配置文件中添加修改hbase的配置
#配置zookeeper集群的地址 atlas.graph.storage.hostname=hadoop101:2181,hadoop102:2181,hadoop103:2181
- 在/opt/module/apache-atlas-2.1.0/conf/atlas-env.sh配置文件中添加hbase的conf安装目录全路径配置
export HBASE_CONF_DIR=/opt/module/hbase-2.4.11/conf

⑤atlas集成solr组件
- 在/opt/module/apache-atlas-2.1.0/conf/atlas-application.properties配置文件添加修改solr的配置
#solr配置 atlas.graph.index.search.solr.mode=cloud atlas.graph.index.search.solr.zookeeper-url=hadoop101:2181,hadoop102:2181,hadoop103:2181/chroot atlas.graph.index.search.solr.zookeeper-connect-timeout=60000 atlas.graph.index.search.solr.zookeeper-session-timeout=60000 atlas.graph.index.search.solr.wait-searcher=true
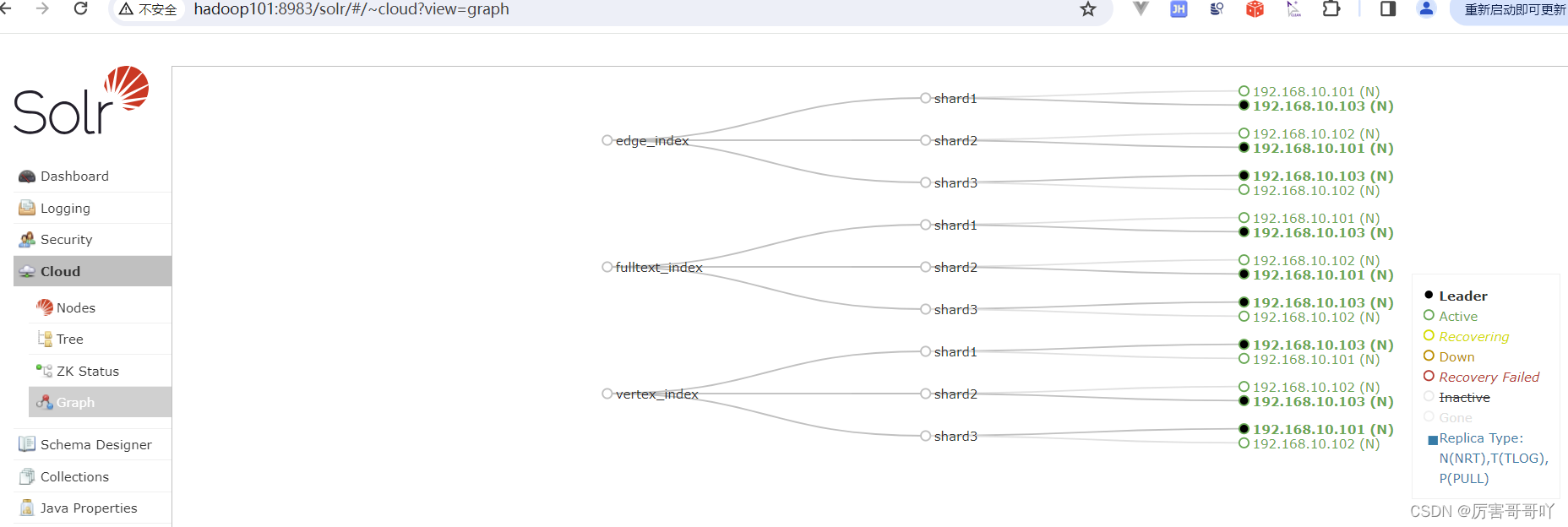
- 在solr中创建solr collection用于存储atlas索引数据
sudo -i -u solr /opt/module/solr-8.11.3/bin/solr create -c vertex_index -d /opt/module/apache-atlas-2.1.0/conf/solr -shards 3 -replicationFactor 2 sudo -i -u solr /opt/module/solr-8.11.3/bin/solr create -c edge_index -d /opt/module/apache-atlas-2.1.0/conf/solr -shards 3 -replicationFactor 2 sudo -i -u solr /opt/module/solr-8.11.3/bin/solr create -c fulltext_index -d /opt/module/apache-atlas-2.1.0/conf/solr -shards 3 -replicationFactor 2
- 在solr平台查看索引是否创建成功


⑥atlas集成kafka组件
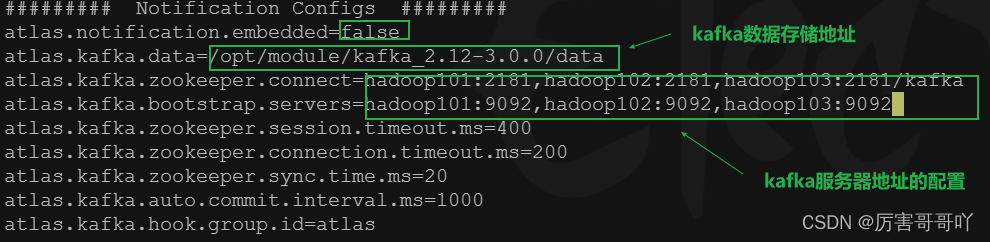
- 在/opt/module/apache-atlas-2.1.0/conf/atlas-application.properties配置文件添加修改kafka的配置
atlas.notification.embedded=false atlas.kafka.data=/opt/module/kafka_2.12-3.0.0/data atlas.kafka.zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka atlas.kafka.bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092 atlas.kafka.zookeeper.session.timeout.ms=400 atlas.kafka.zookeeper.connection.timeout.ms=200 atlas.kafka.zookeeper.sync.time.ms=20 atlas.kafka.auto.commit.interval.ms=1000 atlas.kafka.hook.group.id=atlas
⑦Atlas Server的配置
- 在/opt/module/apache-atlas-2.1.0/conf/atlas-application.properties配置文件添加修改server的配置
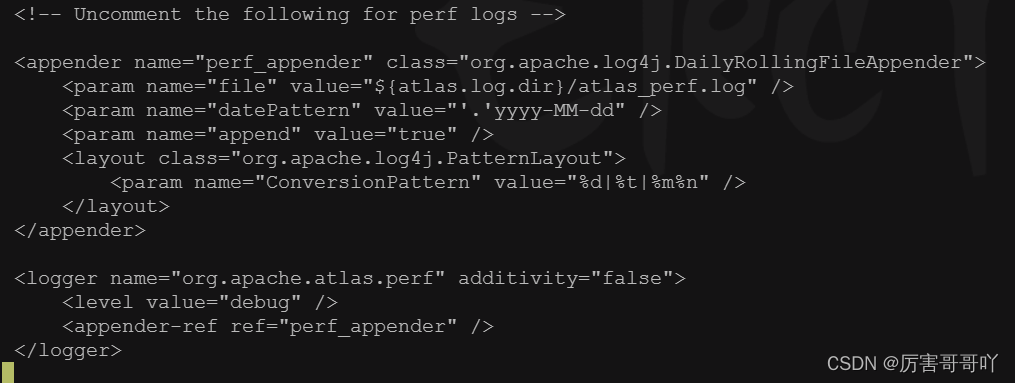
- 在/opt/module/apache-atlas-2.1.0/conf/atlas-log4j.xml中开启记录性能指标的日志输出

⑧atlas集成hive组件
- 在/opt/module/apache-atlas-2.1.0/conf/atlas-application.properties配置文件添加hive hook的配置
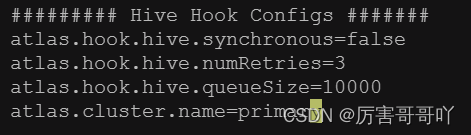
######### Hive Hook Configs ####### atlas.hook.hive.synchronous=false atlas.hook.hive.numRetries=3 atlas.hook.hive.queueSize=10000 atlas.cluster.name=primary
- 在hive组件的配置文件/opt/module/hive-3.1.3/conf/hive-site.xml中添加hive hook配置
<property><name>hive.exec.post.hooks</name><value>org.apache.atlas.hive.hook.HiveHook</value> </property>
- 解压hive hook的程序压缩包
- 将解压后的内容拷贝到atlas安装目录下
- 在hive的环境变量配置文件/opt/module/hive-3.1.3/conf/hive-env.sh中增加atlas的hive hook文件配置
export HIVE_AUX_JARS_PATH=/opt/module/apache-atlas-2.1.0/hook/hive
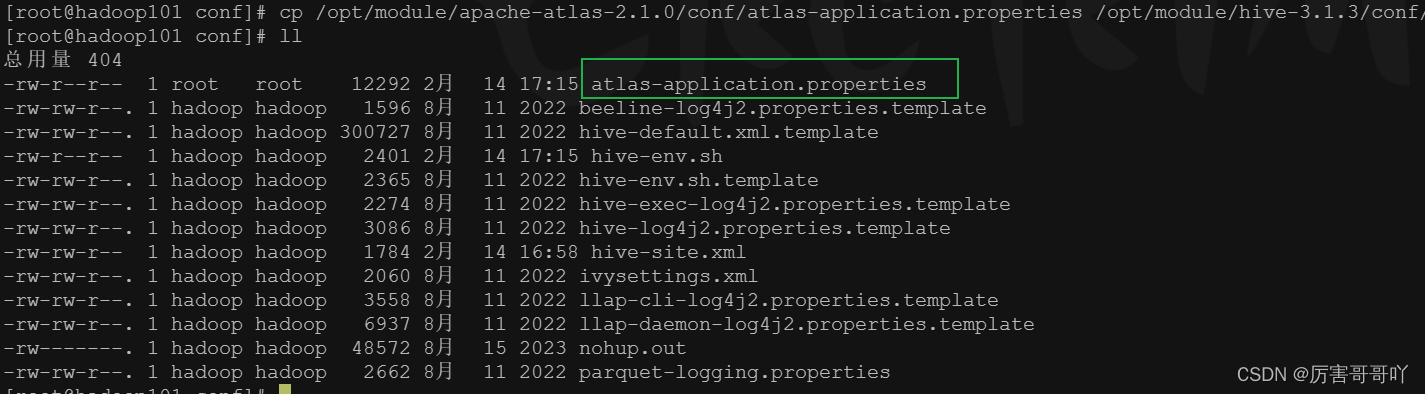
- 将atlas的配置文件/opt/module/apache-atlas-2.1.0/conf/atlas-application.properties拷贝至hive的配置文件目录/opt/module/hive-3.1.3/conf目录下




⑨atlas服务启动
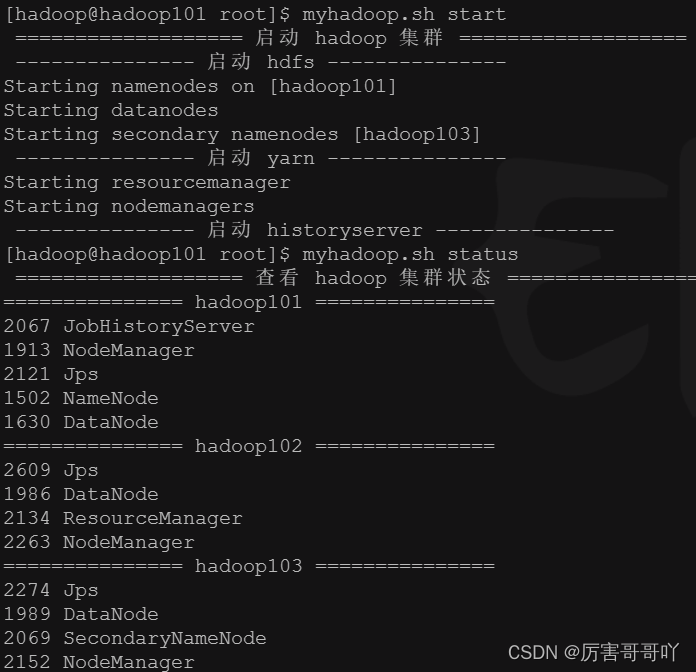
- 启动hadoop集群
- 启动zookeeper集群
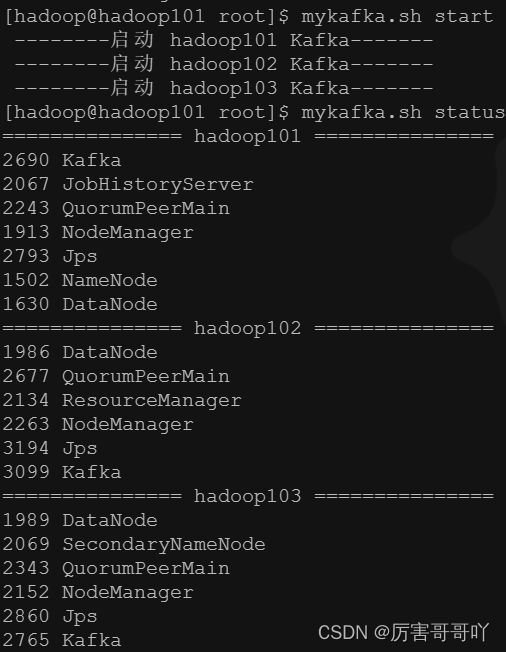
- 启动kafka集群
- 启动hbase集群
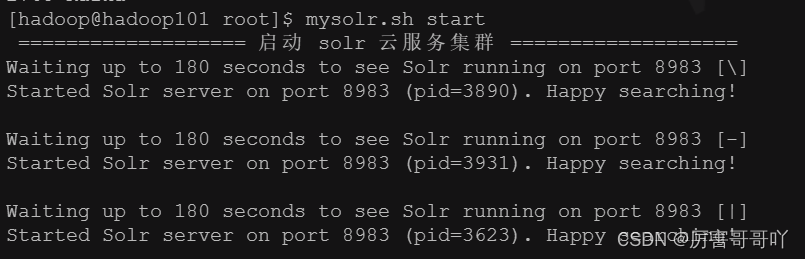
- 启动solr云服务集群
- 启动atlas服务
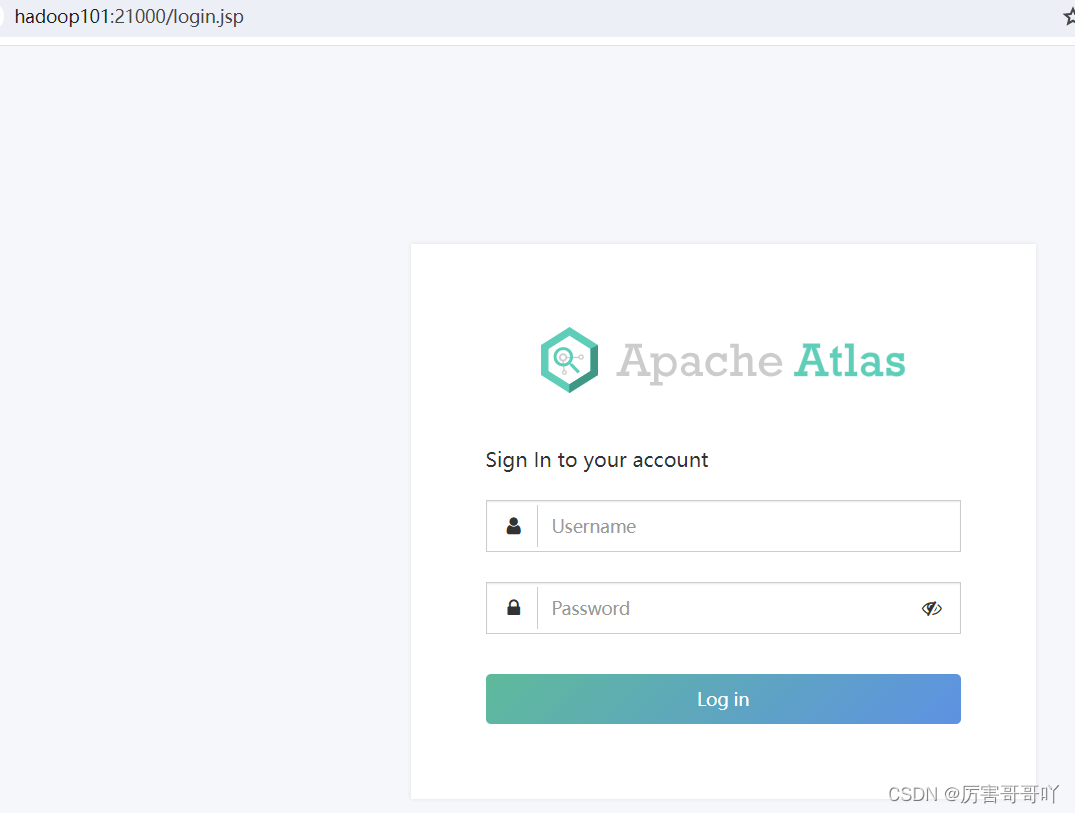
- 访问atlas的web服务:http://hadoop101:21000/
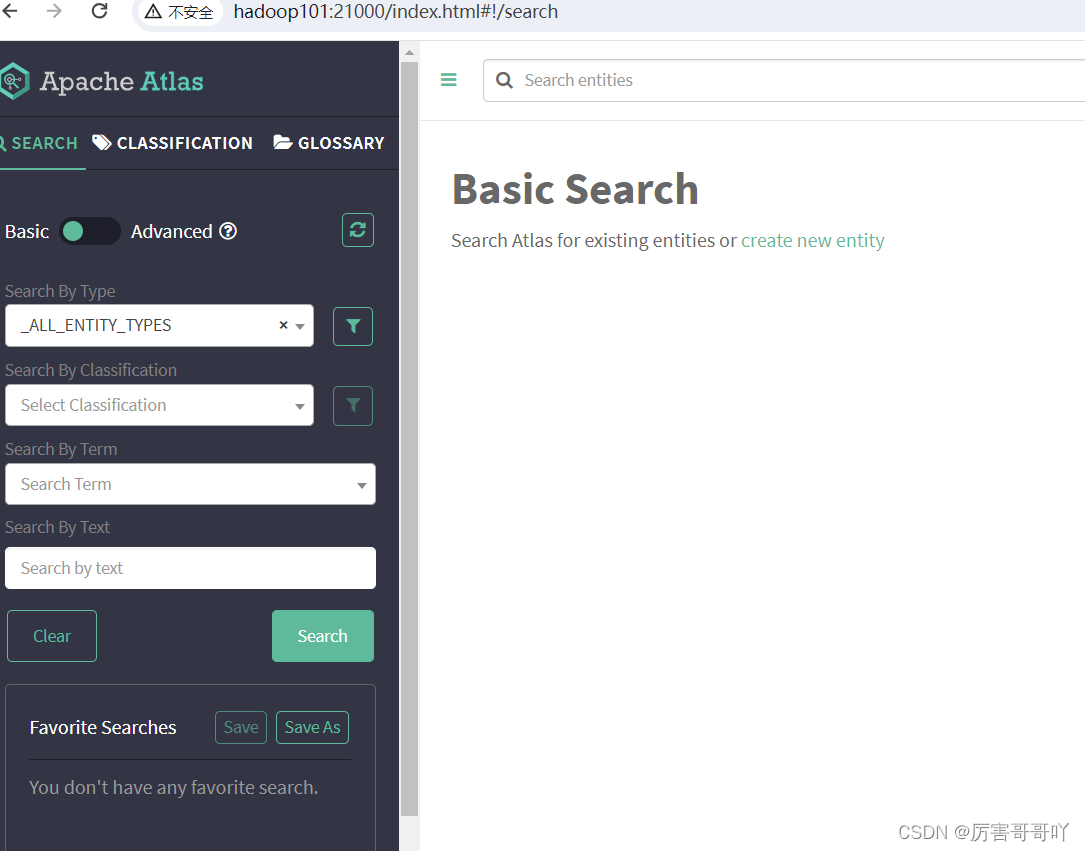
- 使用户初始化默认账号和密码登录atlas,账号:admin 密码:admin



结语
至此,关于Atlas元数据管理平台的部署安装的内容到这里就结束了,我们下期见。。。。。
这篇关于(三十八)大数据实战——Atlas元数据管理平台的部署安装的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





