本文主要是介绍论文翻译:Large language models in medicine 医学中的大语言模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
期刊名:nature medicine
标题:Large language models in medicine 医学中的大语言模型
作者:
Arun James Thirunavukarasu 1,2, Darren Shu Jeng Ting3,4,5, Kabilan Elangovan 6, Laura Gutierrez 6, Ting Fang Tan6,7 & Daniel Shu Wei Ting6,7,8
Abstract:
大型语言模型(LLM)可以响应自由文本查询,而无需经过相关任务的专门培训,这引起了人们对其医疗领域应用的兴奋和担忧。ChatGPT是一种生成型人工智能聊天机器人,通过对LLM进行复杂的微调而产生,其他工具也通过类似的过程被开发出来。在这里,我们概述了ChatGPT等LLM应用程序是如何开发的,并讨论了如何在临床环境中利用它们。我们考虑LLM的优势和局限性,以及它们在医学领域提高临床、教育和研究工作的效率和有效性方面的潜力。LLM聊天机器人已经被应用于一系列生物医学环境中,并取得了令人印象深刻但喜忧参半的结果。这篇综述是感兴趣的临床医生的入门读物,他们将确定LLM技术是否以及如何用于医疗保健,以造福患者和从业者。
Introduction:
大型语言模型(LLM)是一种人工智能(AI)系统,使用来自文章、书籍和其他基于互联网的内容的数十亿个单词训练而成。通常,LLM使用神经网络架构(术语表见方框1),利用深度学习来表示文本训练集中单词之间的复杂关联关系,深度学习已经在医学领域取得了令人印象深刻的结果1,2。通过这个可能是多阶段的、涉及不同程度的人类输入的训练过程,LLM学习单词在语言中如何相互使用,并可以将这些学习到的模式应用于完成自然语言处理任务。
自然语言处理描述了广泛的计算研究领域,目的是以一种模仿人类能力的方式促进语言的自动分析3。生成型人工智能开发人员的目标是生成一种模型,它们能够按需要生成内容,并与应用程序中的自然语言处理(如聊天机器人和文本预测)相结合,换句话说,就是“自然语言生成”任务4。经过多年的开发,现在已经出现了具有“少样本”或“零样本”性能的LLM(方框1),这意味着它们可以识别、解释和生成文本,而只需很少或不需要特定的微调5,6。一旦模型大小、数据集大小和计算资源足够大7,这些少样本和零样本特性就会出现。随着深度学习技术、强大的计算资源和用于训练的大型数据集的发展,LLM应用程序已经开始出现,并且可能颠覆在包括医疗保健在内的各个领域的认知。
ChatGPT(OpenAI)是一个LLM聊天机器人:一个生成型人工智能应用程序,现在可以生成文本以响应多模态的输入(以前只接受文本输入)12。其后端LLM是Generative Pretrained Transformer 3.5或4(GPT-3.5或GPT-4),如下所述13、14。ChatGPT的影响源于其对话的交互性,以及在包括医学在内的各个领域的认知任务中接近人类水平或等同于人类水平的表现14。ChatGPT在美国医学执照考试中取得了及格水平的成绩,有人建议LLM应用程序可用于临床,教育或研究环境14-16。然而,不依赖人类监督的机器自主决策模式,其潜在应用和能力是有争议的:笔试是未经验证的临床表现指标,缺乏良好的基准使得评估表现成为一项重大挑战。目前的LLM技术很可能会在密切监督下作为一种工具得到最有效的利用。
本文以ChatGPT为例,探讨了最先进的LLM在医学中的应用。首先,解释了LLM的开发,概述了开发这些模型所采用的模型架构和训练过程。接下来,讨论了LLM技术在医学中的应用,重点是已发表的用例。然后描述了LLM应用程序落地实施的技术限制和障碍,为有效的研究和开发指明了未来的方向。LLM目前处于医疗人工智能的前沿,在提高临床、教育和研究工作的效率和效果方面具有巨大的潜力,但它们需要广泛的验证和进一步的发展,以克服技术上的弱点。
Box 1:Glossary of common terms in LLM development 术语表
- 计算资源:训练和部署机器学习模型所需的硬件,包括处理能力、内存和存储。
- 深度学习:机器学习的一种变体,涉及具有多层处理“感知器”(节点)的神经网络,它们共同促进非结构化输入数据(例如,图像,视频和文本)的高级特征的提取。
- 少样本学习(few -shot learning):人工智能的开发目的是在只接触任务的几个初始示例的情况下完成任务,并对未见过的示例进行准确的归纳。
- 生成式人工智能:能够按需生成文本、图像或声音等内容的计算系统。
- 大型语言模型:一种使用深度神经网络学习自然语言中词与词之间关系的AI模型,使用大型文本数据集进行训练。
-
机器学习:人工智能的一个领域,其特点是使计算机能够根据输入数据学习并做出预测,从经验中学习。
-
模型大小:AI模型中参数的个数;LLM由通信节点层组成,每个通信节点层包含一组在训练期间优化的参数。
-
自然语言处理:人工智能研究的一个领域,专注于计算机与人类语言之间的交互。
-
神经网络:受生物神经网络启发的计算系统,包括“感知器”(节点),通常分层排列,彼此通信并对输入数据进行转换。
-
参数:机器学习模型中的一个变量,它在训练期间被调整(通常是自动的)以最大化性能。在深度学习中,参数是由神经网络节点组成的“权重”或数据转换函数。
-
语义任务:自然语言处理任务需要在更深层次上理解语言输入的含义,而不仅限于最简单的表层水平的词汇和语法。
-
零样本学习:开发AI来完成任务,而无需接触任何先前的任务示例。
Development of LLM chatbots:大语言模型聊天机器人的发展
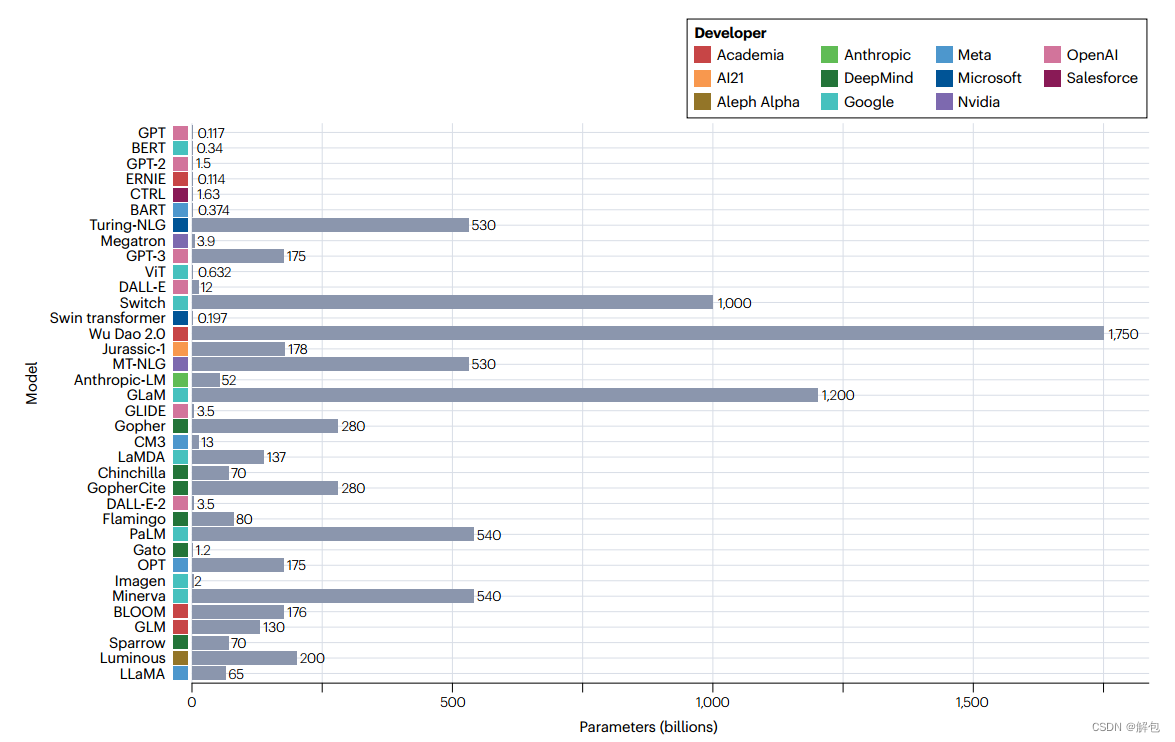
LLM的总大小并不是控制其效用的唯一重要因素:ChatGPT目前在医疗保健研究中引起了最大的兴趣,尽管它的初始后端GPT-3.5参数量并不是最大的(图1)5,11。这要归功于复杂的微调,特别是对人类输入问题的适当响应。ChatGPT及其后端LLM——GPT-3.5和GPT-4——提供了一个有用的案例研究,说明了开发最先进的LLM应用程序所需的架构、资源和训练过程,尽管最新的技术发展仍然是保密的。
第一版GPT (GPT-1)于2018年发布(参考文献19)。GPT1的训练是半监督的,首先进行无监督预训练,用以程序化语言中各个单词之间的关联关系,随后进行有监督的微调,以优化特定自然语言处理任务的性能。为了简化优化,结构化的输入问题(例如,因果顺序的段落、离散段落、选择题和答案)被转换为单一的线性单词序列19。对于预训练,GPT-1使用了BooksCorpus数据集,该数据集包含11,308本小说,包含约7400万个句子,或1 × 10 ^ 9个单词。这种新型模型的总体表现非常出色——在12项自然语言处理任务中的9项中优于定制模型,并且在许多情况下具有可接受的零样本性能。
GPT-2(于2019年发布)拥有15亿个参数,比其前身大10倍。它的训练数据来自WebText,这是一个来自800多万份文档的40gb数据集。GPT-2最初在几个自然语言处理任务(阅读理解、总结、翻译和问题回答)上进行了评估,其表现优于许多专门用于狭窄用例的定制模型,甚至在零样本环境下也是如此。GPT-2证明了大型模型以最先进水平执行不熟悉的任务的能力,但在文本摘要任务中表现明显较弱,其表现与定制模型相似或更差。在少样本环境或使用任务提示时,性能得到了提高,说明这些LLM能够整合提示信息,更好地实现用户的目标。
2020年,GPT-3发布,拥有1750亿个参数,比GPT-2(参考文献5、20)大100多倍。更广泛的训练赋予了它更强的少样本和零样本能力,在各种自然语言处理任务中取得了最先进的表现。训练数据集由5个语料库组成,总共包含45TB数据: Common Crawl(网页)、WebText2、Books1、Books2和Wikipedia5。总的来说,GPT-3的开发专门解决了其前辈的弱点,以设计迄今为止最复杂的LLM。GPT-4现在已经发布,并且在自然语言处理以及各种专业能力测试中取得了比GPT-3更高的性能。此外,GPT-4接受多模式输入:图像可以包含在用户查询中14。它的架构、开发和训练数据仍然是保密的,但GPT-4已经在ChatGPT的一个版本中实现,并且可以通过应用程序编程接口(API)访问14。
基于已发布的GPT模型的预训练任务被称为语言建模:预测序列或句子中的下一个和/或前一个“标记”(通常类似于“单词”)11,21。其他通过语言建模预训练的模型包括LLaMA、MT-NLG、对话应用语言模型(LaMDA)、Anthropic-LM、Pathways语言模型(PaLM)和Open Pretrained Transformer(OPT)(图1)11,22。存在许多可选的训练模式,从掩码语言建模(完形填空任务:预测序列中的掩码标记)和排列语言建模(使用随机采样的输入标记进行语言建模)到去噪自动编码(在故意损坏后恢复原始输入)和下一句预测(区分句子是否连续)。使用这些可选模式开发的模型包括Gato、DALL-E、Enhanced Language Representations with Informative Entities 带信息实体的增强语言表示(ERNIE), Bidirectional Encoder Representations from Transformers 来自转换器的双向编码器表示(BERT) and Bidirectional and Auto-regressive Transformers 双向自回归转换器(BART) (如图1所示)。
From LLM to generative AI chatbot:从LLM到生成AI聊天机器人
为了开发有用的应用程序,需要对LLM进行进一步的微调,正如在GPT-3.5的工程中所看到的那样,它对自由文本输入提示产生适当的响应(图2)。在这里,微调涉及将GPT-3暴露于一系列提示和响应中,而这些提示和响应是由扮演应用程序用户和AI助手角色的人类研究员生成的;这有助于模型学习如何正确回答自定义查询。接下来,使用奖励模型进行“从人类反馈中强化学习”(RLHF),模型的训练数据来源于人类打分员对GPT-3.5的问题响应的评分。这种奖励模型使自主决策的RLHF的规模远远大于人工评分所能达到的规模13。为了提高安全性,使用模型生成的输入查询和输出完成了进一步的自主对抗训练。
集成了GPT-4作为其后端LLM的ChatGPT后续版本目前还没有得到解释,因为新的架构,数据集和训练是保密的。然而,似乎类似的原则也适用于GPT-3.5和ChatGPT初始版本的训练,因为新旧模型容易出现类似的错误——尽管新的训练模式可能已经被开发出来,这种训练模式的数据来源于快速增长的用户群(图2,虚线箭头)。即使在单独的对话中,ChatGPT也表现出了非凡的“学习”能力,特别是通过提供挑战任务的示例来提高性能——也即从zero-shot到few-shot。用户提供的示例使LLM能够训练自己,类似于其初始开发中的微调过程。
除了ChatGPT之外,临床医生和患者也可以使用其他LLM聊天机器人。必应的AI聊天机器人(微软)使得用户可以访问GPT-4,而无需额外访问ChatGPT。Sparrow(DeepMind)是使用LLM“Chinchilla”构建的,通过利用谷歌搜索结果、人工反馈和广泛的初始化提示(长达591个单词,包含23个明确规则),减少了不准确和不适当的情况。ChatGPT的对抗性测试没有显示出类似的初始化提示,尽管这些测试是不确定的,因为ChatGPT的安全措施可能已经实现了隐藏初始指令的功能。使用OPT作为其后端LLM的BlenderBot 3(Meta Platforms)也利用互联网接入来提高准确性,BlenderBot 3在发布后可能会通过使用有机生成的数据继续提高性能,正如与ChatGPT的关系所述(图2,虚线箭头)。Google Bard最初是使用LaMDA构建的,但现在利用了PaLM 2,它在通用和特定领域的能力方面能与GPT-4相媲美。HuggingChat提供了一个免费访问的聊天机器人,其界面与ChatGPT类似,但使用Large Language Model Meta AI(LLaMA)作为其后端模型。最终,具有相对中等处理能力的个人可能会开发出最先进的LLM聊天机器人的廉价仿制品。
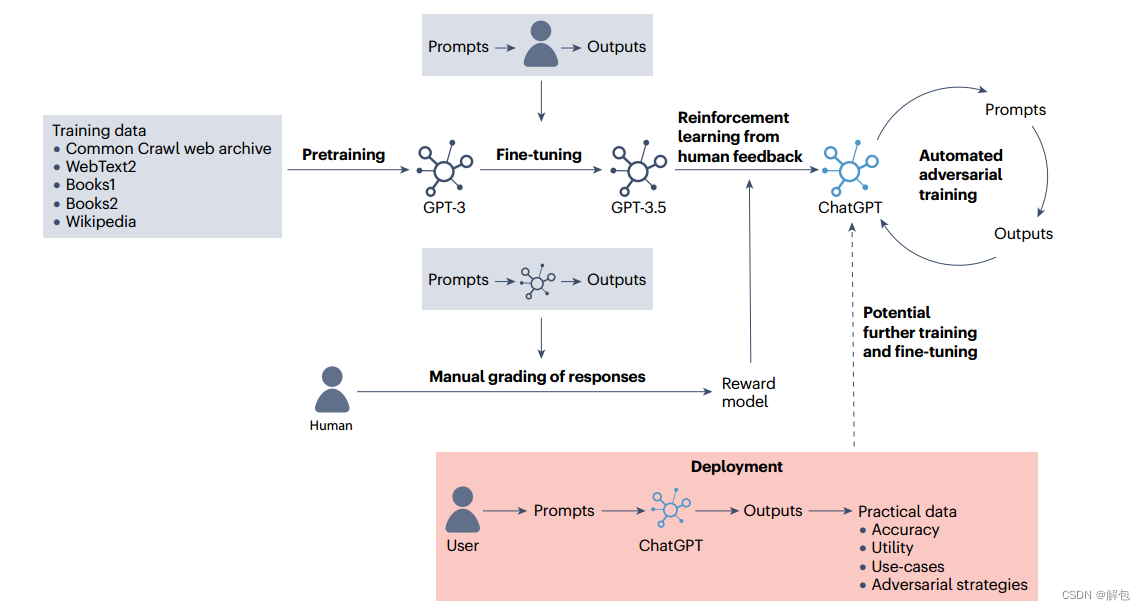
GPT-3通过使用来自互联网的大量文本数据集的单词预测任务进行训练,并经过微调以开发GPT-3.5。微调涉及将模型暴露于人类生成的输入输出对中,使模型学习如何对提问做出适当的响应。为了开发ChatGPT,使用了RLHF。RLHF采用了一种奖励模型,该模型使用人类对GPT-3.5在一系列提示下所产生输出的评分进行训练。这种奖励模型可以与更大的提示列表一起使用,以促进更大规模的训练,而不是人工对每个输出进行评分。GPT-4和后续版本的ChatGPT的架构和训练过程是保密的,但可能应用类似的原则,因为这两个模型都容易出现类似类型的错误。改编自欧阳等人。
以目前的形式,LLM还没有准备好替代医生,因为其专业检查的能力远远不够完善,这引发了严重的不准确和不确定性问题(除了伦理问题,如下所述)。尽管最近报告的各行各业benchmark的表现令人印象深刻,但仍需要进行具体的评估和验证,以证明在任意特定背景下的有效性和实用性。从根本上说,临床实践与正确回答考试问题不同,找到合适的基准来衡量LLM的临床潜力是一个巨大的挑战17。尽管如此,令人鼓舞的结果表明,现有的技术已经很好地影响临床实践,并且其进一步的发展可能会加速和扩大自然语言处理人工智能在医学中的应用。
Reducing economic, computational and environmental costs of development:减少开发的经济、计算和环境成本
GPT-3和GPT-4的开发依赖于一些最强大的可用计算硬件,由微软Azure提供。这种能源密集型基础设施碳排放量巨大,并且投入大量资金致力于提高硬件和软件效率,以尽量减少开发带来的环境成本。训练LLM所需的成本和能源一直呈下降趋势,预计到2030年左右将达到个人负担得起的水平(参考文献37)。然而,快速的创新正在以比预期更快的速度加速进步。如,研究人员使用GPT-3.5 API生成的查询和输出对LLaMA的小型版本(70亿个参数)进行了微调。子型号“羊驼”(Alpaca)实现了与GPT-3.5相似的性能,尽管其架构要小得多,培训时间以小时为单位,总成本低于600美元(参考文献31)。以更大的LLM为基础的模型,例如650亿个参数的LLaMA版本,如果用来自GPT-4、PaLM 2或随后开发的LLM的数据进行微调,可能会产生更令人印象深刻的结果。除了降低训练高性能模型的经济成本和环境影响外,这些方法还可以大大增加LLM的可及性。例如,大量减少开发高性能LLM所需的资源可以使这项技术民主化,允许更多的临床医生开发用于特定临床目的的工具,并使低收入和中等收入国家的研究人员能够开发和使用LLM应用程序。
然而,这种“仿制品”的发展可能会对投入大量资金开发最先进模型的公司产生严重影响。即使训练数据、模型架构和微调协议完全保密,就像GPT-4一样,提供大规模访问(例如通过API)允许外部研究人员从父模型中构建足够的问题和答案库,也能对开源的LLM进行微调,并且产生性能接近父模型的交互式子模型。廉价仿制品可能会损害激励该行业投资的竞争壁垒,并可能导致公司限制对其模型的访问。例如,如果没有约束性协议来限制竞争模型的开发,未来的前沿LLM可能就不会提供API访问。此外,子模型的激增带来了处理方面的另一层不确定性,加剧了下文所述的“黑匣子”问题。
Medical applications of LLM technology:LLM技术的医学应用
最近几个月,LLM技术的许多使用案例,特别是ChatGPT,已经被报道(图3)。高质量的研究对于确定新技术的优势和局限性至关重要,但是,在把基于LLM的创新性工具应用于临床、教育或研究方面,却鲜有有设计良好且务实的试验。
Clinical applications:临床应用
ChatGPT在美国医学执照考试中获得及格成绩,引起了医学界的特别关注,并且GPT-4的成绩明显高于其前身GPT-3.5(参考文献15,38)。Med PaLM 2(谷歌)是PaLM 2的一个版本,根据医学数据进行了微调,最近取得了最先进的成果,达到了接近人类临床医生专家水平39。当把ChatGPT对患者查询的回复与医生提供的回复进行比较时(空闲时间在社交网络上的回复),LLM的输出在质量和同理心方面是更优的。这导致人们认为人工智能已经准备好取代医生,但现实并没有那么戏剧性17,40-42。即使在医学生考试中,成绩也远非完美,没有报告的分数接近100%。ChatGPT已被证明无法通过医生的专家测试,并在回答现实患者有关心血管疾病预防的询问时提供了不准确的信息。尽管LLM展现出了解释临床诊断和回答相关问题的能力,但它往往无法提供适合患者个人情况的信息46–48。这些案例就宣告了:不能将机器自主决策的LLM用于决策或患者沟通,尤其是当患者经常无法区分LLM和人类临床医生提供的信息时。由于连续模型倾向于获得数量上的收益,而不是质量上的收益——容易受到相同弱点的影响,尽管频率较低——这可能是现状,至少在可预见的未来是如此。(这段没看懂)
特定领域的LLM可能通过提供新颖的功能而证明是有用的。Foresight是一种具有GPT架构的模型,使用811,336例患者电子健康记录的非结构化数据进行了微调。它在验证研究中证明了其预测的有效性。通用风险模型可以替代当前的大量工具,对患者进行分层和分诊。其他潜在的用途包括反事实模拟和虚拟临床试验,这可以通过促进有价值的风险回报推断来加速临床研究,从而可以告知研究人员哪些研究最有可能为患者提供价值51。新型架构,如混合价值感知转换器(HVAT),可以通过整合纵向、多模态的临床数据来进一步提高LLM的性能。
ChatGPT在不需要专业知识、或用户提示中包含了相关知识的任务中表现出更强的性能5,22,32。与临床决策辅助工具相比,这为实施提供了更直接的前景。LLM能够快速吸收、总结和改写信息,从而减轻临床医生的管理负担。出院总结就是一个很有启发性的例子——涉及信息的解释和压缩,且几乎不需要解决问题或回忆的重复性任务。新兴的多模态模型将扩展功能并与更多数据源兼容;甚至医生的笔迹也可以被自动准确地解读。微软和谷歌的目标是在整个管理工作流程中分别集成ChatGPT和PaLM 2,允许来自视频通话、文档、电子表格、演示文稿和电子邮件的信息无缝地自动集成55,56。然而,在有患者健康风险的临床环境中使用,需要广泛的验证57。质量评估对于确保患者安全和行政效率不受损害至关重要,并且需要具体的治理结构来分配责任58。
Educational applications:教育应用
GPT-4和Med-PaLM 2在医学测试中的出色表现表明,对于那些目前在此类测试中只能达到较低水平的学生而言,LLM可能是一种的有用教学工具38,59。GPT-4的元提示功能允许用户明确描述聊天机器人在对话过程中所扮演的角色;有用的例子包括“苏格拉底导师模式”,它鼓励学生通过提出降低难度的问题来独立思考,直到学生们能够找到解决手头问题的方法。对话记录可以让人类教师监控进度,并迎合教学,直接解决学生的弱点。非营利教育机构可汗学院(Khan Academy)正在积极研究如何将GPT-4等人工智能工具应用于“Khanmigo”,以优化在线教学。Duolingo是一个主要免费的语言学习平台,它在角色扮演和答案解释功能中实现了GPT-4,以提高在线学习的交互性61。类似的工具可能也会促进医学教育。
然而,谨慎是有必要的,因为频繁的错误——尤其是在医学方面——以及缺乏一种伴随输出的不确定性指标:学生如何知道老师教的是否准确?这对LLM教师来说是一个相当大的问题。LLM可能会采纳一些谎言和偏见。尽管存在这些限制,LLM工具仍可以在专家监督下使用,以前所未有的规模高效地产出教学材料,如临床诊断、问题评估和内容摘要。多模态LLM可以让教师更快地整合和分析学生制作的不同格式的材料,其好处与临床用例中描述的类似。
Research applications:研究应用
与临床用例类似,LLM的不精确性排除了机器自主决策的可能性,但让其扮演辅助角色可能会显著提高效率。可以指示模型简洁地总结信息,详细地描述一组提供的结果,或者重写段落以满足特定的读者或受众。利用特定领域信息进行微调的模型可能表现出优异的性能,例如源自一个LLM(BERT),包括PubMedBERT和BioBERT64,65。这就可以减轻批判性评价、研究报告和同行审查的负担,这些是研究人员工作量的重要组成部分66。通过确保使用这些工具的临床医生和研究人员对其产出负责,有关问责制的问题将得到改善。
LLM可以促进新颖的研究,例如比以前更大规模的语言分析。示例包括ClinicalBERT、GPT-3.5和GatorTron,它们能够使研究人员有效地分析大量临床文本数据68–70。LLM也可能推动看起来联系不太明显的领域研究,因为基于文本的信息包含的不仅仅是人类语言。例如,遗传和蛋白质结构数据通常以文本形式表示,并适用于以LLM为基础的自然语言处理技术。模型已经产生了令人印象深刻的结果:AlphaFold从氨基酸序列推断蛋白质结构;ProGen产生具有可预测生物学功能的蛋白质序列;TSSNote CyaPromBERT找到了细菌DNA中的启动子区域71-73。最后,用于分析患者数据的生成人工智能应用程序也可用于合成人造数据,加之适当的质量评估,就可以扩大用于开发LLM和其他人工智能工具的训练语料库的规模,从而加强临床研究74。
Barriers to implementation of generative AI LLMs:生成人工智能LLM具体实施的障碍
有几个问题和限制阻碍了ChatGPT和其他类似应用程序的大规模临床部署(表1)。首先,训练数据集不足以确保生成的信息准确有用。其中一个原因是缺乏近期性:GPT-3.5和GPT-4(ChatGPT的后端LLM)主要使用截至2021年9月生成的文本进行训练(参考文献14,75)。由于包括医学在内的各个领域的研究和创新都在不断进行,缺乏最新的内容可能会加剧不准确性。在语言突然变化的情况下,比如当研究人员发明了新的术语,或者改变了用于描述新发现和新方法的特定词汇的使用方式时,这个问题尤其严重。思维模式的转变也会产生问题——例如,一些被认为不可能的事情实现了。经典的案例包括以前所未有的速度开发出了2019新冠病毒(COVID-19)疫苗,以及针对以前“无法治疗”的靶点的抗肿瘤药物,如KRAS。如果类似事件晚于训练数据集的阈值日期,模型将不可避免地对相关查询提供低质量的响应。因此,咨询医疗专业人员仍然至关重要。
| 局限性 | 描述 | 缓解策略 |
|---|---|---|
| 近期性 | GPT训练数据集不包括2021年9月之后创建的内容。 所有预训练数据集都必须在任意日期“截止”。 | -从最新来源收集培训数据。 -实时互联网接入(例如,Bing AI、Sparrow和BlenderBot 3)。 |
| 准确性 | GPT-3的数据被限制为570GB。 模型没有被训练着去“理解”;相反,它们仅限于学习单词之间的概率关联。 培训数据来源于未经验证的网站和书籍。 | -对训练数据进行验证。 -不确定性指标。 -利用微调来优化医学精度。 -通过智能提示(例如,思维链)进行自我完善。 |
| 连贯性 | 模型的输出是基于所学单词之间的关联,而不是理解输入查询或输出中使用的信息。 捏造的事情也会被当成真实的呈现出来。 | -重新开发模型架构和训练策略,以开发真正的语义知识。 -微调以消除不准确信息的呈现。 |
| 透明度和可解释性 | 目前还不清楚模型如何从输入查询、架构数据和算法中生成答案(称为“黑箱”问题)。 目前还不清楚训练数据集的哪些部分被用于生成响应。 | -要求输出数据集的哪些部分促成了模型的答案。 -“可解释的”AI研究和开发。 |
| 伦理问题 | 回答可能是危险的、歧视性的或冒犯性的。 -隐私和安全漏洞的风险。 -对模型输出的后果没有既定的问责机制。 -对于人工智能在医学中应该扮演什么角色,不应该扮演什么角色,没有达成共识。 | -微调以减少不良输出的发生率。 -建立治理体系和监督机构。 -安装报告系统,供使用者标记危险回答。 -病人和医生参与的共识建立倡议。 |
第二,训练数据没有经过特定领域准确性的验证,这导致了“垃圾输入,垃圾输出”的问题——早在1864年,现代计算之父查尔斯·巴贝奇(Charles Babbage)就(更雄辩地)描述了这一点(参考文献78)。GPT-3.5是根据书籍、维基百科和更广泛的互联网数据进行训练的,没有设计任何机制来交叉检查或验证这些文本的准确性。尽管LLM的大小令人印象深刻,有1750亿个参数,GPT-3.5却只使用了570 GB的初始训练数据——仅仅是互联网上可用数据(估计为120 zb (1.2 × 10^14 GB) )的一小部分。然而,多样化、高质量文本数据的相对稀缺可能会限制数据集,最近的评估表明,用于训练的新文本可能会在几年内耗尽36,80。此外,ChatGPT在响应查询时无法实时访问互联网,因此其知识库从根本上是有限的。可以在生成响应时访问互联网的替代应用程序已经被开发出来,如BlenderBot 3和Sparrow。
第三,LLM没有被训练成像人类一样理解语言。通过“学习”人类使用过的单词之间的统计学关联,GPT-3开发了一种成功预测哪个单词最适合完成一个短语或句子的能力。通过密集的微调和进一步的训练,后续的模型可能会发展出一种能力,使其能够对查询做出听起来合理、措辞连贯但不一定准确的回应。所谓的“幻觉”已经被广泛报道,即不准确的信息被发明(因为它没有在训练数据集中表示)并被清晰地支持;为了避免不恰当的拟人化,我们更倾向于使用另一个术语,如“事实捏造”。另一方面,LLM可能会受到激励而进行自我改进:思维链提示与自我一致性的鼓励相结合,促进了自主微调,使具有5400亿个参数的LLM的推理能力提高了5-10%。然而,由于准确性不一致和缺乏不确定性指标,需要谨慎部署。
第四,LLM处理是一个“黑匣子”,这就使处理和决策的可解释性受到挑战85。除非明确要求,否则LLM不会引用或对答复做出解释,解释的实际代表性也不清楚。这加剧了准确性问题,因为不清楚应该如何重新训练或微调模型以提高性能。这个问题最好通过参考另一种基于GPT-3的生成型人工智能DALL-E 2来说明,DALL-E是一种基于文本的提示生成图像响应的应用程序86。例如,担心皮肤癌的用户可以使用DALL-E2来了解黑色素瘤在他们皮肤上的外观,但生成的图像并不一定准确。类似的问题无疑会使ChatGPT复杂化,可能会导致错误的保证和中继诊断。(看不懂)可解释AI方案可能会提高可解释性,但在自然语言处理的背景下进行的此类研究相对较新,目前的机器学习技术似乎不足以真正产生信任。
第五,随着生成式人工智能模型的出现,伦理问题已经出现,这些模型能够产生与人类书面文本无法区分的回答。使用基于有偏见数据(例如,来自书籍和互联网的未经验证的内容)训练的模型可能会使这些偏见永久化。LLM应用所带来的许多其他风险已经被注意到,但这里的讨论主要集中在那些与临床环境最相关的风险。LLM认知辅助带来的研究加速可能会导致安全标准和伦理道德的下降。尽管ChatGPT被明确设计来降低这些风险,但问题仍然存在,并已被广泛报道,且对抗性提示可能被用来“越狱”ChatGPT,从而逃避其内置规则90,91。尽管为改善这些漏洞进行了大量工作,但GPT-4仍然容易受到对抗性提示方法的攻击,例如“相反模式”和“系统消息攻击”。大型科技公司、工业和学术界的许多知名人士都担心这些风险,一封呼吁暂停开发的公开信引起了全世界的关注。然而,LLM开发的代表领导人却不愿意签字,这表明创新将继续,开发者将对其发布产品的安全负责。
此外,安全和隐私问题与基于互联网的平台的使用密切相关,尤其是当由商业企业运营时92。如果禁止将患者可识别的数据作为模型的提示输入,那么这些问题可能会限制部署机会。GPT-4还通过同化其大量训练数据和多模态输入提示,从而引入了人员识别的风险32。在模型训练过程中个人数据的纳入是不可逆转的,这与1993年《通用数据保护条例》(General data Protection Regulation)“被遗忘权”等法律权利相冲突。最终,这些禁令和规定是由人类来遵守的,但自主决策的应用程序带来了一个严重的问责问题。
科学期刊迅速采取行动,停止了ChatGPT作为作者的认证,这表明该技术无法承担作者需要承担的责任,相反,它应该像任何其他帮助人类工作的方法工具一样被对待[94 - 96]。在更详细的用例出现之前,很难设想和设计出一种治理结构来建立人工智能对临床决策的责任。一个更基本的伦理问题在于LLM应该被允许协助或参与哪些任务。尽管可以提出功利主义的论点来证明任何被证明可以改善患者结果的干预措施都是合理的,但利益相关者必须就人工智能参与的可接受性达成共识——自主、半自主或作为一种完全从属的工具。
最后,衡量LLM在临床任务中的表现是一个相当大的挑战。早期的定量研究集中在考试上,这是在现实环境中对临床能力的未经验证的衡量方法。定性评估已被用于人工环境,如社交媒体领域,由志愿医生提供建议17。最终,使用LLM的临床干预措施应该在随机对照试验中进行测试,以评估对死亡率和发病率的影响,但应该使用什么样的基准来确定干预措施是否适合这种昂贵且有风险的试验呢?下一节将更深入地讨论这些悬而未决的问题以及回答这些问题的方法。
Directions for future LLM research and development:LLM的未来研发方向
上述限制提供了有用的指示,说明后续的研究和开发应该集中在哪里,以提高LLM应用的实用性(图3)。在训练过程中加入特定领域的文本可以提高临床任务的表现97。潜在的数据来源包括临床文本(例如,患者笔记和医疗信件)和准确的医疗信息(例如,指南和同行评审文献)。根据临床文本构建或微调的现有模型包括ClinicalBERT、Med PaLM 2和GatorTron,它们在生物医学自然语言处理任务中的综合表现优于各种通用LLM。最新的知识可以实时来源于互联网,而不是依赖于有限的预训练数据集;Bing AI和Google Bard已经具备了这一功能,ChatGPT也紧随其后,开始接受插件28。然而,医学笔记、科学文献和其他互联网材料中的频繁错误将继续阻碍LLM的表现;临床实践、科学探究和知识传播不会、也永远不会完美地执行。数据集质量可以通过二次验证来提高,但是涉及的文本量可能是手动质量评估不能完成的。机器学习解决方案——包括由专家进行初始人工评分,结果用于训练自动模型以处理更大规模的数据——在平衡效率和有效性方面可能是最佳的,如用于优化ChatGPT的奖励模型所示(图2)13。此外,由专家验证指导的特定任务微调(可能通过机器学习进行增强)可以提高输出的准确性和安全性。
目前,捏造的事实和其他错误抑制了对LLM输出的信心,需要密切监督,尤其是在高风险的医疗环境中14-16。在准确性提高到与人类专家性能相匹配或超过人类专家性能之前,不确定性指标的开发可以促进半自主角色的部署,前提是在应用程序无法提供有用信息的情况下引入负责任的临床医生。Google Bard最初实施的保护措施不允许该模型回答许多临床问题,但这种笼统的方法限制了医疗工具的开发和实施。
如果LLM被用作工具,则必须解决责任和信用问题96,101–103。同行评审期刊对这一问题采取了多种方法——一些完全禁止使用,另一些则要求明确描述用途40,94,104-106。剑桥大学出版社发布了明确的指导意见,总结为四点107。首先,人工智能的使用必须被声明并明确解释(与其他软件、工具和方法一样);第二,人工智能不符合署名要求;第三,人工智能生成的文本不得违反抄袭政策;第四,作者需要对使用或不使用人工智能生成的文本的准确性、完整性和独创性负责。然而,目前尚不清楚法规将如何执行:尽管正在开发检测人工智能生成语言的工具,但其准确性目前非常差,尤其是在文本片段较短的情况下。“水印”协议可以通过可检测的签名来促进高质量的文本生成,以表明LLM的参与,但这目前尚未在最流行的模型中实现109。伦理问题和解决方案可能是针对具体用例的,但人类监督可能是一种成功的通用方法,可以降低风险,确保由责任的个人对临床决策负责。尽管这限制了半自主人工智能的潜在应用,但它们仍然可以使一些耗时的认知工作自动化,从而彻底改变临床工作。
在无法解释的黑盒模型87中,很难调查其他伦理问题。因此,尽管文献中有很多偏见的示例,但调查研究和缓解策略要有限得多。众包刻板印象对(CrowS Pairs)基准能够量化偏见,50%对应于“完美”不含美式刻板印象。令人担忧的是,所有参与测试的LLM都显示出偏见。然而,积极的开发降低了有偏见和危险输出的发生率,GPT-4对不被允许的内容请求作出响应的可能性比其前身GPT-3.5低82%。为了解决这些目前普遍存在的偏见,可以使用“数据陈述”来提供与数据集相关的上下文信息,这些信息将性能和结论的可推广性告知研究人员和消费者114。另一方面,通过提供新的研究方法和对人脑语言处理的见解,可解释的AI方案可以解决黑匣子问题,促进对偏见和其他伦理问题更深的理解,从而带来LLM应用之外的好处。
防护措施的价值仅取决于它们在面对对抗性攻击时的健壮性,否则恶意行为者的规避可能会损害降低风险的努力。由于广泛的定向训练,GPT-4比它的前辈更加健壮。然而,还需要进一步的工作来解决其剩余的弱点。外部研究人员能够通过API使用最先进的LLM生成的大规模数据来训练自己的模型,这可能没有任何保障措施,从而带来了额外的风险。GPT-4对其内部工作保密,以保护隐私,同时也保持竞争优势;而API访问可能会危及两者。随着LLM的能力不断扩大,必须特别注意保护隐私,因为可以使用模型从训练数据和输入查询中的不同信息中识别患者。临床医生还应注意,不要将可识别的数据输入可能存储数据并将其用于未知目的的数据平台。当在医学中开发和使用这些工具时,治理结构应该清楚地说明什么是允许的,什么是不允许的。
LLM在医学中应用的实验研究很少,因此迫切需要进行严格的研究,来对创新用例作出验证和证明。前瞻性临床试验应该是务实的,反映现实世界的临床实践,并且应该测试在可接受性、有效性和实用性方面有真正机会实施的干预措施。例如,人工智能辅助模型(而不是自主模型)应根据标准实践进行评估,因为众所周知,LLM的无监督部署不太可能实现。衡量成功或失败需要适当的指标,理想情况下可以是降低死亡率和/或发病率。其他创新终点可能包括文件质量(需要经过验证的质量评估)、工作效率和患者或医生满意度。其他创新终点可能包括文件质量(需要经过验证的质量评估)、工作效率和患者或医生满意度。一些人认为,开发和使用经过验证的基准来证明临床干预的真正潜力,将是大规模临床试验的必要前提,这些试验可能会为将LLM用于临床工作提供证据。然而,由于之前已经在随机对照试验中对非LLM的聊天机器人进行了测试,并且LLM代表了自然语言处理的一个有意义的进步,因此已经有理由将LLM干预用于临床试验。应尽可能使用指导方针,以最大限度地提高研究的质量,还需要进一步的工作来调整和开发适合NLP研究的框架。
在临床效率的背景下,需要进行研究,以确保LLM工具实际上减少了工作量,而不是给医疗保健专业人员带来更大的管理负担16,118。例如,电子健康记录被誉为数字健康的一项了不起的进步,但许多医生抱怨由此增加了琐碎的数据输入和行政工作118。有针对性的研究可以降低LLM引发类似问题的风险。此外,需要进行健康经济分析,以确定LLM应用程序的实施具有成本效益,而不是浪费的“白象”119。因此,应该鼓励来自不同学科的研究人员共同努力,提高已发表研究的质量和严谨性120。
Conclusion:
LLM已经彻底改变了自然语言处理,GPT-4和PaLM 2等最先进的模型现在在医学人工智能创新的前沿占据着核心地位。这项新技术在临床、教育和研究工作中有很多机会,尤其是伴随着新兴的多模态与插件工具的整合(图3)。然而,潜在的风险正在引起专家和更广泛的社会对安全、道德和在某些情况下可能取代人类的关注41。LLM应用程序的自主部署目前尚不可行,临床医生仍将负责为患者提供最佳和人道的护理14,16。然而,只要伦理和技术问题得到解决,经过验证的应用程序可能会成为改善患者和医疗保健从业者的宝贵工具。成功的验证将涉及务实的临床试验,以最大限度地减少偏见,以透明的报告来证明真正的益处。
这篇关于论文翻译:Large language models in medicine 医学中的大语言模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








