本文主要是介绍千亿参数“一口闷”?大模型训练必备四种策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI领域的许多最新进展都围绕大规模神经网络展开,但训练大规模神经网络是一项艰巨的工程和研究挑战,需要协调GPU集群来执行单个同步计算。
随着集群数和模型规模的增长,机器学习从业者开发了多项技术,在多个GPU上进行并行模型训练。
乍一看,这些并行技术令人生畏,但只需对计算结构进行一些假设,这些技术就会变得清晰——在这一点上,就像数据包在网络交换机之间传递一样,那也只是从A到B传递并不透明的位(bits)。

三层模型中的并行策略。每种颜色代表一层,虚线分隔不同的 GPU。
训练神经网络是一个迭代的过程。在一次迭代过程中,训练数据通过模型的layer(层)进行前向传递,对一批数据中的训练样本进行计算得到输出。然后再通过layer进行反向传递,其中,通过计算参数的梯度,可以得到各个参数对最终输出的影响程度。
批量平均梯度、参数和每个参数的优化状态会传递给优化算法,如Adam,优化算法会计算下一次迭代的参数 ( 性能更佳)并更新每个参数的优化状态。随着对数据进行多次迭代训练,训练模型会不断优化,得到更加精确的输出。
不同的并行技术将训练过程划分为不同的维度,包括:
-
数据并行(Data Parallelism)——在不同的GPU上运行同一批数据的不同子集;
-
流水并行(Pipeline Parallelism)——在不同的GPU上运行模型的不同层;
-
模型并行(Tensor Parallelism)——将单个数学运算(如矩阵乘法)拆分到不同的GPU上运行;
-
专家混合(Mixture-of-Experts)——只用模型每一层中的一小部分来处理数据。
本文以GPU训练神经网络为例,并行技术同样也适用于使用其他神经网络加速器进行训练。作者为OpenAI华裔工程师Lilian Weng和联合创始人&总裁Greg Brockman。
1
数据并行
数据并行是指将相同的参数复制到多个GPU上,通常称为“工作节点(workers)”,并为每个GPU分配不同的数据子集同时进行处理。
数据并行需要把模型参数加载到单GPU显存里,而让多个GPU计算的代价就是需要存储参数的多个副本。话虽如此,还有一些方法可以增加GPU的RAM,例如在使用的间隙临时将参数卸载(offload)到CPU的内存上。
更新数据并行的节点对应的参数副本时,需要协调节点以确保每个节点具有相同的参数。
最简单的方法是在节点之间引入阻塞通信:(1)单独计算每个节点上的梯度;(2) 计算节点之间的平均梯度;(3) 单独计算每个节点相同的新参数。其中,步骤 (2) 是一个阻塞平均值,需要传输大量数据(与节点数乘以参数大小成正比),可能会损害训练吞吐量。
有一些异步更新方案可以消除这种开销,但是会损害学习效率;在实践中,通常会使用同步更新方法。
2
流水并行
流水并行是指按顺序将模型切分为不同的部分至不同的GPU上运行。每个GPU上只有部分参数,因此每个部分的模型消耗GPU的显存成比例减少。
将大型模型分为若干份连续的layer很简单。但是,layer的输入和输出之间存在顺序依赖关系,因此在一个GPU等待其前一个GPU的输出作为其输入时,朴素的实现会导致出现大量空闲时间。这些空闲时间被称作“气泡”,而在这些等待的过程中,空闲的机器本可以继续进行计算。

一个朴素的流水并行设置,其中模型按layer垂直分成 4 个部分。worker 1托管网络第一层(离输入最近)的模型参数,而 worker 4 托管第 4 层(离输出最近)的模型参数。“F”、“B”和“U”分别代表前向、反向和更新操作。下标指示数据在哪个节点上运行。由于顺序依赖性,数据一次只能在一个节点上运行,从而会导致大量空闲时间,即“气泡”。
为了减少气泡的开销,在这里可以复用数据并行的打法,核心思想是将大批次数据分为若干个微批次数据(microbatches),每个节点每次只处理一个微批次数据,这样在原先等待的时间里可以进行新的计算。
每个微批次数据的处理速度会成比例地加快,每个节点在下一个小批次数据释放后就可以开始工作,从而加快流水执行。有了足够的微批次,节点大部分时间都在工作,而气泡在进程的开头和结束的时候最少。梯度是微批次数据梯度的平均值,并且只有在所有小批次完成后才会更新参数。
模型拆分的节点数通常被称为流水线深度(pipeline depth)。
在前向传递过程中,节点只需将其layer块的输出(激活)发送给下一个节点;在反向传递过程中,节点将这些激活的梯度发送给前一个节点。如何安排这些进程以及如何聚合微批次的梯度有很大的设计空间。GPipe 让每个节点连续前向和后向传递,在最后同步聚合多个微批次的梯度。PipeDream则是让每个节点交替进行前向和后向传递。
GPipe 和 PipeDream 流水方案对比。每批数据分为4个微批次,微批次1-8对应于两个连续大批次数据。图中,“(编号)”表示在哪个微批次上执行操作,下标表示节点 ID。其中,PipeDream使用相同的参数执行计算,可以获得更高的效率。
3
模型并行
在流水并行中,模型沿layer被“垂直”拆分,如果在一个layer内“水平”拆分单个操作,这就是模型并行。许多现代模型(如 Transformer)的计算瓶颈是将激活值与权重相乘。
矩阵乘法可以看作是若干对行和列的点积:可以在不同的 GPU 上计算独立的点积,也可以在不同的 GPU 上计算每个点积的一部分,然后相加得到结果。
无论采用哪种策略,都可以将权重矩阵切分为大小均匀的“shards”,不同的GPU负责不同的部分。要得到完整矩阵的结果,需要进行通信将不同部分的结果进行整合。
Megatron-LM在Transformer的self-attention和MLP layer进行并行矩阵乘法;PTD-P同时使用模型、数据和流水并行,其中流水并行将多个不连续的layer分配到单设备上运行,以更多网络通信为代价来减少气泡开销。
在某些场景下,网络的输入可以跨维度并行,相对于交叉通信,这种方式的并行计算程度较高。如序列并行,输入序列在时间上被划分为多个子集,通过在更细粒度的子集上进行计算,峰值内存消耗可以成比例地减少。
4
混合专家(MoE)
混合专家(MoE)模型是指,对于任意输入只用一小部分网络用于计算其输出。在拥有多组权重的情况下,网络可以在推理时通过门控机制选择要使用的一组权重,这可以在不增加计算成本的情况下获得更多参数。
每组权重都被称为“专家(experts)”,理想情况是,网络能够学会为每个专家分配专门的计算任务。不同的专家可以托管在不同的GPU上,这也为扩大模型使用的GPU数量提供了一种明确的方法。
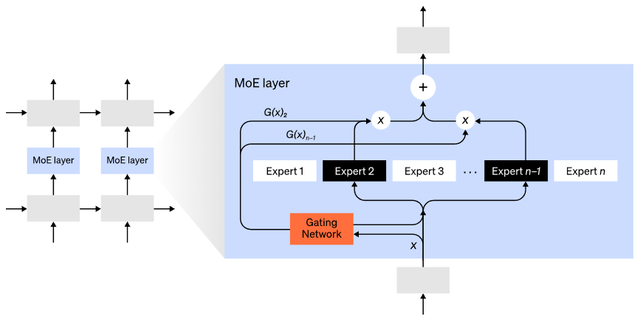
混合专家(MoE)层。门控网络只选择了n个专家中的2个(图片改编自:Shazeer et al., 2017)。
GShard将MoE Transformer扩展到6000亿个参数,其中MoE layers被拆分到多个TPU上,其他layers是完全重复的。 Switch Transformer将输入只路由给一个专家,将模型大小扩展到数万亿个参数,具有更高的稀疏性。
5
其他节省内存的设计
除了以上的并行策略,还有很多其他的计算策略可以用于训练大规模神经网络:
-
要计算梯度,需要保存原始激活值,而这会消耗大量设备显存。Checkpointing(也称为激活重计算)存储激活的任何子集,并在反向传播时及时重新计算中间的激活。这可以节省大量内存,而计算成本最多就是增加一个完整的前向传递。还可以通过选择性激活重计算(https://arxiv.org/abs/2205.05198)在计算和内存成本之间不断权衡,也就是对那些存储成本相对较高但计算成本较低的激活子集进行检查。
-
混合精度训练(https://arxiv.org/abs/1710.03740)是使用较低精度的数值(通常为FP16)来训练模型。现代加速器可以用低精度的数值完成更高的FLOP计数,同时还可以节省设备显存。处理得当的话,几乎不会损失生成模型的精度。
-
Offloading是将未使用的数据临时卸载到CPU或其他设备上,在需要时再将其读回。朴素实现会大幅降低训练速度,而复杂的实现会预取数据,这样设备不需要再等待数据。其中一个实现是ZeRO(https://arxiv.org/abs/1910.02054),它将参数、梯度和优化器状态分割到所有可用硬件上,并根据需要将它们实现。
-
内存效率优化器可减少优化器维护的运行状态的内存,例如Adafactor。
-
压缩可用于存储网络的中间结果。例如,Gist可以压缩为反向传递而保存的激活;DALL·E可以在同步梯度之前压缩梯度。
(原文:https://openai.com/blog/techniques-for-training-large-neural-networks/)
这篇关于千亿参数“一口闷”?大模型训练必备四种策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


