本文主要是介绍Torch7深度学习教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转自:http://blog.csdn.net/u010946556/article/details/51329208 留作笔记,感谢原作者
本博文目标是介绍Torch的入门使用
博主采用iTorch界面编写,以下以图片方式展示代码。
如果记不清哪个方法的名字了可以在iTorch里面点“Tab”键会有智能输入,类似matlab
- 简单地介绍String,numbers,tables
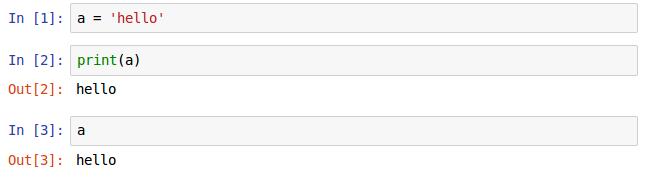
字符串的操作注意是单引号,然后第二行中的print()函数有点像c++里面的cout,即可以根据输入的要打印的类型不同而显示,这输入式字符串,后面还会输入其他数据格式的输入。由于torch是交互式的,跟matlab很像所以直接打a也能显示输出。

b是声明一个类似Array的数组类型,没有赋初值打印时显示为空。
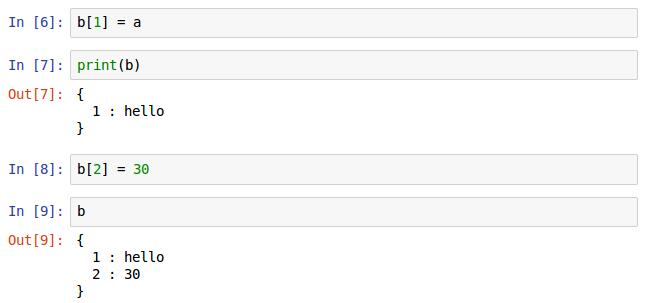
分别给数组赋值,第一个数组元素为字符串a,第二个为整型30,同样的调用print()和直接打b,打印的效果一样。值得注意的是,这里的输出是数组序号和数组元素一起打印出来的。
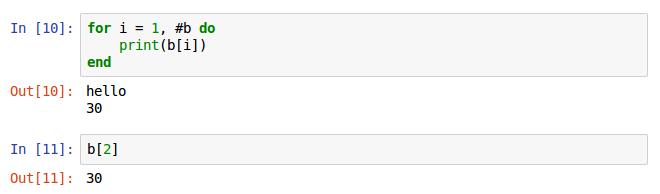
接着看一下一个简单的循环,这个是lua的数组for循环,在“#”要加循环使用的数组名,默认是i++的形式循环,可以改成i = i + 2或者其他形式,具体看下图体会

这是没两次打印元素,所以应该打印第一个数组元素“hello”和第三个,但是数组没有第三个所以结果如上图
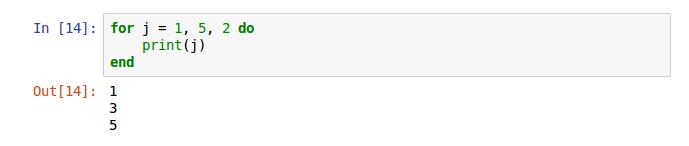
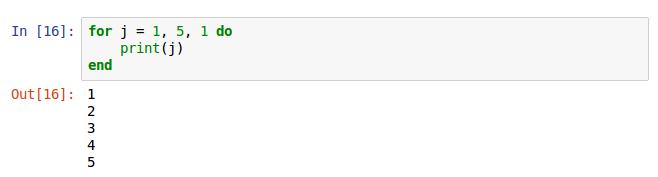
以上两图,应该能更好的说明循环
- Torch里非常重要的结构Tensor(张量),类似于Python用的Numpy
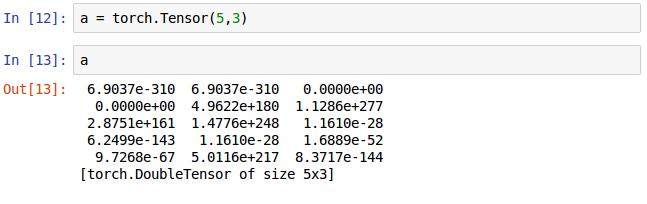
声明Tensor的格式如12行,打印a可以得到一个5x3的矩阵,这里的没有赋初值,但是Torch也会随即赋值的,具体的就跟c++里面的生命了变量虽没有初始化,但是还是会有值一样。
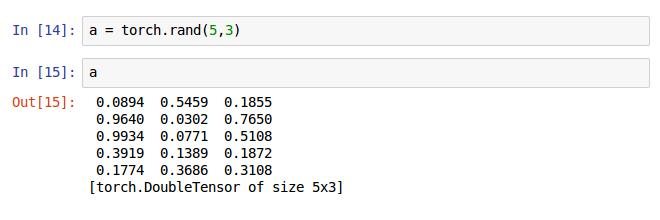
接着我们调用rand随即初始化矩阵的值(注意这里跟我上面说的随即初始化的区别)。
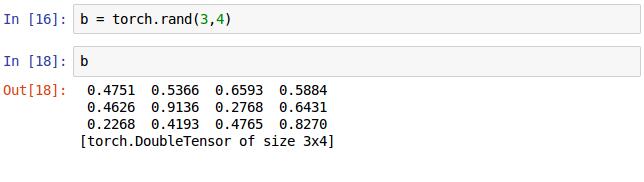
也可以直接调用随即初始化Tensor的值,如16行的代码,与a的随即初始化5x3矩阵是一样的,这里b是3x4矩阵。
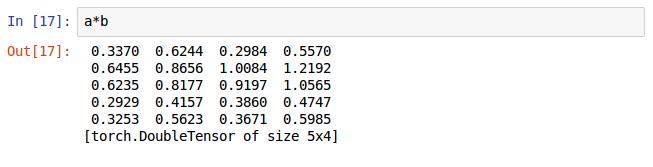
矩阵的乘实现的第一种方法
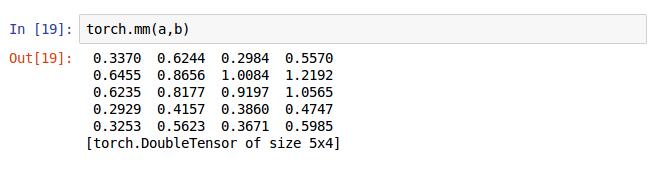
矩阵的乘实现的第二种方法
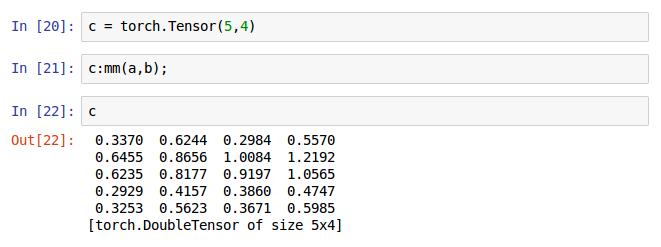
矩阵的乘实现的第三种方法,这种方法是先声明一个5x3乘以3x4矩阵生的5x4举证的Tensor变量c后,用变量c调用mm()方法进行乘运算,最后将结果保存到了c中,当然也可以用如下方式保存
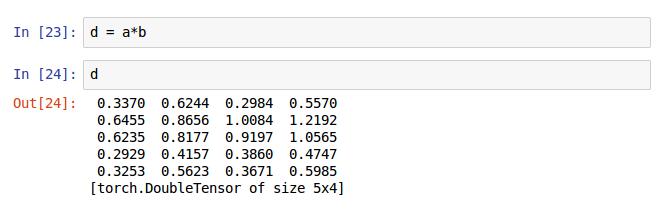
这种方式保存的不需要声明d为5x4的矩阵,直接使用即可,跟matlab特别像。

price = torch.Tensor{28993, 29110, 29436, 30791, 33384, 36762, 39900, 39972, 40230, 40146}
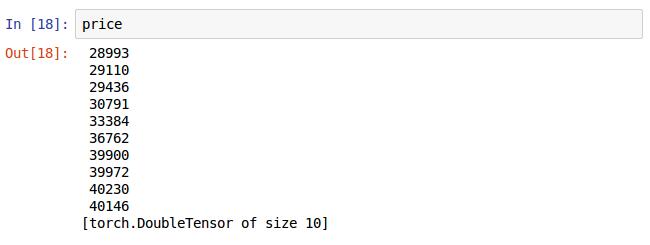
这是自己定义Tensor的值输入10个整型值,打印price,注意这时它只是一个有10数据的Tensor。
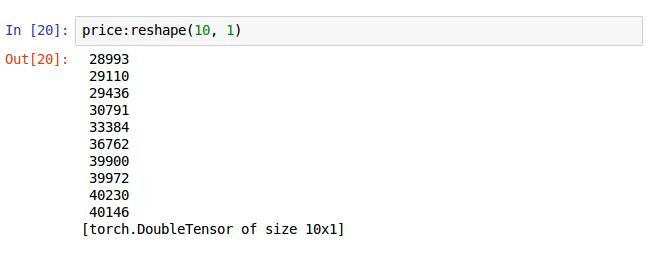
对比这两张图片,第一张是有10个数据的Tensor,第二张是10x1的矩阵,也可以成为列向量(神经网络经常用到),是调用了reshape()方法转换的,它们看着一样本质上是不一样的!

这时再次调用reshape()方法生产的2x5矩阵,值得注意的是,现在虽然调用了两次reshape(),但是原来的price还是10个数据的Tensor,如下图22行,在经过2次reshape()运算后price没有变化。
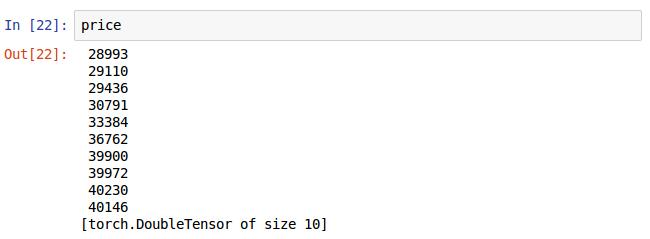
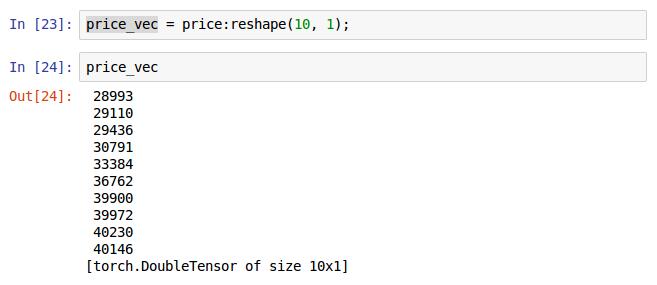
可以使用赋值语句将10x1的向量保存到price_vec中,当然也可以一直用price:reshape(10,1)来表示10x1向量,就是代码长一些。
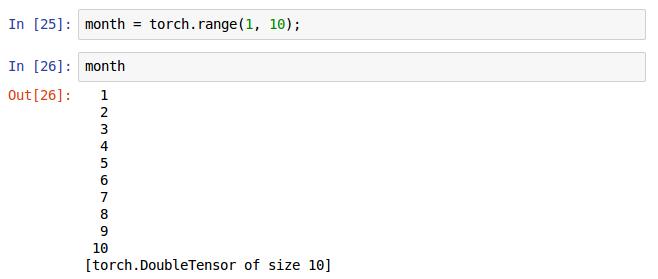
如果想输出1到10这样的类似于枚举型数据时,可以调用range()方法,再次提醒这样初始化的还是一个Tensor,而非运算时候的矩阵或者向量,要用reshape转换。
-
函数的使用
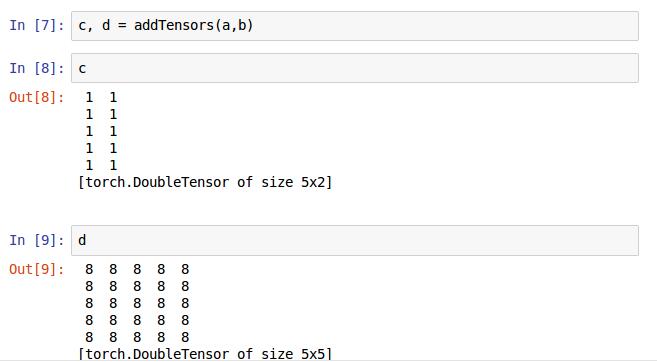
这是函数的定义方式,声明的关键字+定义的函数名+形参的名字,在此博主返回两个值,具体的函数功能在后面再说
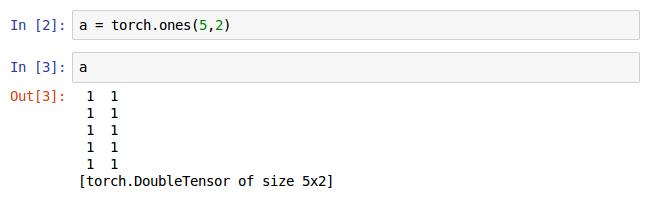
这是初始化一个5x2的矩阵,并且初值都为1。这里有多了一种初始化矩阵的方法。
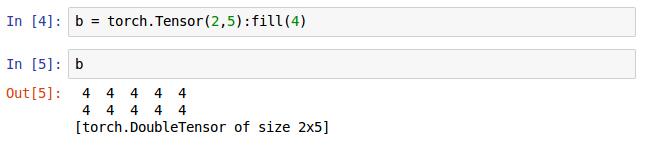
这是先声明一个2x5的矩阵,然后再调用fill()方法其值全部初始化为4。
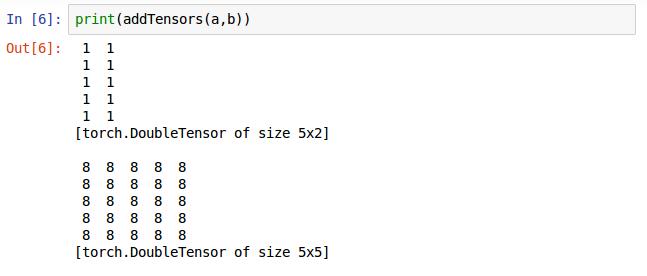
将a,b矩阵输入到addTensors函数里面,注意这里是实参,前面定义的a,b是形参,这个有点c基础的应该都分的清楚吧。打印结果就是返回a矩阵和axb的矩阵。
这样子写更像matlab,返回的a和axb分别按顺序赋值给c,d。 -
CUDA的Tensor
抱歉了,我的电脑不是NVIDIA的显卡,这里以后再补上吧,看不到运行结果


这里就是多调用一下cuda()函数,然后计算axb矩阵的乘机运算就可以了。开头的require ‘cutorch’就是导入cuda运算包,类似于c语言里面的include。
- 神经网络
首先require(相当于c语言的include)nn包,该包是神经网络的依赖包,记得在语句最后加上“;”,这个跟matlab一样不加的话会打印出来数据。Torch可以让我们自己一层一层的设计自己的网络,像是容器一样可以一层一层地把你自己的Layer(神经网络的中的层)往里面添加。
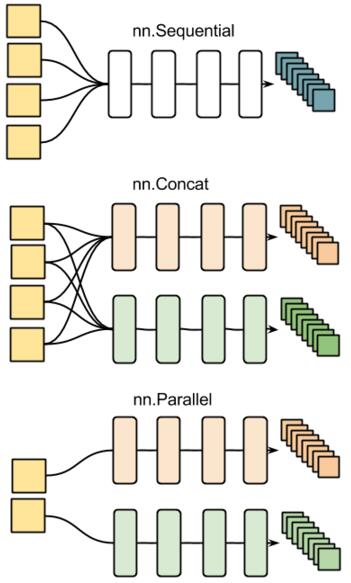
首先,要构造一个神经网络容器,即用上面的形式声明一个神经网络容器,网络名为net,博主目前知道的Torch提供了三种形式构建的神经网络的容器,如下图
这里使用的是第一种,看名字大概也能猜到就是队列形式的,一层接一层地加载,第二种,第三种,图像展示应该比我文字描述的更形象。(有时间找个其他的列子把后面的两种的试验补充上)。
这里代码行的序号没截屏好,第3行是没有的,第2行代码后直接接的是第4行代码。这里是net神经网络容器调用add()添加方法,向里面添加层,nn.SpatialConvolution()是创建一个卷基层,里面的参数值的含义分别为:1表示输入图片的通道为1,这个改写成3就是输入3通道的图片;6表示经过该层的卷积运算输出的通道数;5,5这两个参数代表的是用5x5的核进行卷积运算。总结,该层是把1通道的图片输入进来然后利用5x5的卷积核进行卷积运算,最后输出6通道的图片。
module = nn.SpatialConvolution(nInputPlane, nOutputPlane, kW, kH, [dW], [dH], [padW], [padH])
这是卷积层的函数说明,我们在上面只用到了前4个参数,[ ]为可以不用输入的参数,后面的dW,dH即横向移动和纵向移动的步长默认为1,padW为宽度维度附加0的参数,因为有的图像用你设置的卷积核和步长运算时,可能出现维数不对的情况(类比2x3的矩阵不能乘以2x4的矩阵一样,你的需要把2x4的矩阵换成3x4的矩阵,这里是在2x4的矩阵下面添加一行0元素,使其成为3x4的矩阵),默认为0,最好是设置成(kW-1)/2,即卷积核的宽-1后再除以2。padH默认为padW,最好设置成(kH-1)/2,即卷积核的高-1后再除以2。



如果对于卷积神经网络不是很了解的,可能看着还不是太明白我表达的意思,可以先把这些放一放,继续往下看,推荐一个网站http://cs231n.github.io/convolutional-networks/ 不喜欢看英文可以先看看这个http://dataunion.org/11692.html 网站。

第4行是往容器里面加入卷基层操作,现在就在卷积层里面添加激励函数ReLU函数,你也可以添加Sigmoid函数等等。

这里是添加pool池化层,即在2x2的区域内找最大的数,横向步长为2,纵向步长为2。
module = nn.SpatialMaxPooling(kW, kH, [dW], [dH], [padW], [padH])
padW和padH跟卷积层的那个函数一样,不再赘述。

添加卷基层torch的会自动连接前面的6张图片作为输入,这次是输出16张图片,卷积核为5x5,激励函数,池化层。

第7行之后是第9行,第8行没有代码。
这行是将16x5x5的3维tensor转换成16x5x5的1维tensor。通俗地理解为原先用16x5x5的立方体描述的东西,现在转化成用一条16x5x5线来描述之前的东西(后面有图,我会试着再解释下,希望可以理解地更清晰点)。

Linear是全连接层,我们将3维的tensor转化成(想象成立方体)转化成了1维的tensor,这在上一步时会输出16x5x5=400个节点,在这里我们让这400个节点与120个节点建立全连接。

添加激励层

同上120个节点与84个节点全连接,添加激励层。

13行的第一步,84个节点与10个节点全连接。最后是将10个节点输出转化成对数概率,用于分类问题。
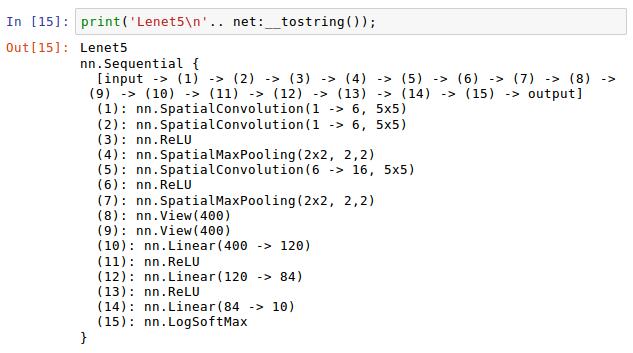
最后打印出自己的建立的的神经网络。注意net:__是两个下划线,不要打错了!!!
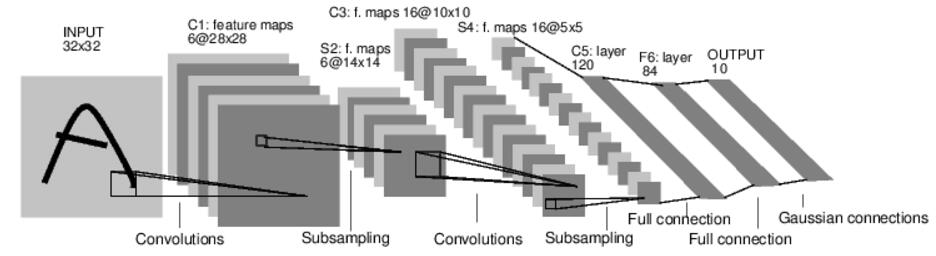
这是建立的神经网络的结构图,我再在这里解释下那个view()函数,S4层到C5层这里就是使用了view()函数,再想象下我类比的那个立方体到直线的转换,S4层总体的可以看为长16宽5高5的立方体,C5层则变成了长120的线段。
神经网络建立好了,下一章是如何训练它
- 神经网络的前向传播和反向传播
随即生产一张照片,1通道,32x32像素的。为了直观像是,导入image包,然后用itorch.image()方法显示生成的图片,就是随即的一些点。
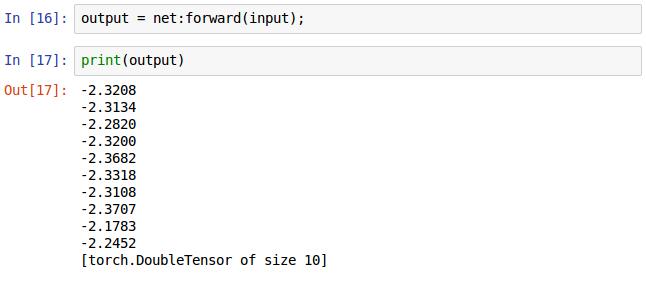
用之前建立好的神经网络net调用forward()方法输入随即生成的图片得到输出的结果,如打印出来的形式,net最后是10个输出节点,这里输出了10个值。注意,这是前向传播,网络里面的权重是随即分布的,这是BP算法之前需要做的运算。
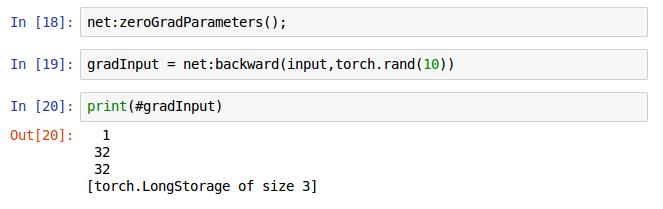
18行是将网络里面的梯度缓存设置为0,19行是网络net的反向传播方法,第一个参数是输入的图片,这里应与forward()方法里面输入的图片一致,第二个参数在这里的意思是训练用的分类标签,注意不是预测出来的标签,是训练样本的真实的标签,即需要拟合的标签。最后返回的是需要输入的梯度,即进行梯度下降算法是需要的那个梯度(可能是,我回头再确认下,这个不影响我们训练)。
前向传播和反向传播的基本过程就是上面,当然到这还不能我们的网络,还没有定义损失函数,下面介绍损失函数的基本操作。
- criterion评价准则,这是用来定义损失函数的。当你想让你的神经网络学习一些东西时,你就要给他一些反馈,告诉他怎么做是对的。损失函数能够形式化的衡量你的神经网络的好坏。例子如下:
还是在nn这个包里面有很多的评测函数,在这里我选择了ClassNLLCriterion()这种方法,这是用来多分类的方法,用的是negative log-likelihood(负对数似然概率,抱歉非数学专业不知道怎么翻译这个,不过不影响时候,只需知道他是用来做多分来的评测函数就行)。
损失函数的实现也有正向和方向两个操作,多说一点,不同的神经网络用BP算法求解的思想是一样的,但是定义的网络不同其具体的损失度量不同官方文档还强调该函数特别适合不平衡数据的分类!!!。就这个例子来说我们定义是适合对分类的损失函数,调用他的前向传播方法并输入的参数分别为预测的类和训练样本所属的类。这里执行后会有一个返回值,即他们的误差(err),博主没有进行赋值。
执行完损失函数的前向操作后,再进行反向操作,backward()方法里面的参数同forward()函数里的参数,返回值是损失函数的梯度。
调用神经网络net的backward()方法输入训练集和其对应的损失函数梯度。然后,使用神经网络net的updateParameters()更新权重,该方法的输入值为学习率,即完成了训练。注意,gradInput这个返回值可写可不写不影响我们的训练。





这一章用实例讲解在正式训练前需要对训练集的处理以及基本操作,请大家从头开始运行itorch

导入两个包,虽然这章没有涉及网络的建立,但是不导入nn这个包的话,数据的读入会出错,具体我也不太清楚,这个是google出来的,我刚开没有导入nn包,导致文件一直无法读取。

参数为文件的绝对路径,文件的下载我放到了这里(需要2个积分下载,请大家支持下,如果实在没有积分的话,给我发私信,我发你)
http://download.csdn.net/detail/u010946556/9518759

压缩包里有两个数据,分别导入trainset和testset

声明一个classes的数组,用于说明训练集图片所对应的名字,图片总共有10类

打印下trainset可以看到有10000张图片,3通道,像素是32x32,对应的标签同样有10000个

为了直观些,可以打印其中的一张照片观看下。
itorch.image()是用来打印图片,trainset.data[100]表示第100张图片。
trainset.label[100]表示标签的第100个的标签,注意标签分别是用1到10表示,第100个标签的值是2,对应的classes数组的第2个元素是“汽车”

为了利用“nn.StochasticGradient”方法来计算权值,数据集的数据必须满足两个条件:1)数据集必须包含size()方法;2)数据集必须有一个索引,即data[i]表示第i个样本的数据。所以为了使数据集满足以上两点,需要使用setmetatable这个函数。这个函数有时间会单独拿出来一章详细讲,这里就先大概知道它就是用来给数据集添加索引的。将ByteTensor 转变成DoubleTensor。声明一个size()函数,用来返回自身数据的size(1)
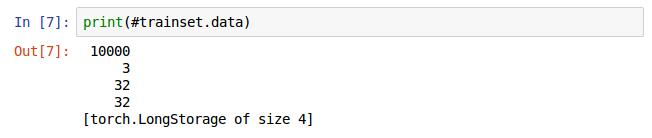
trainset.data的张量(Tensor)的结构打印出来如上(想象成4维数组),定义的size()函数就是用来放回size(1),即10000。如果这里不太清楚,插个例子说明下。
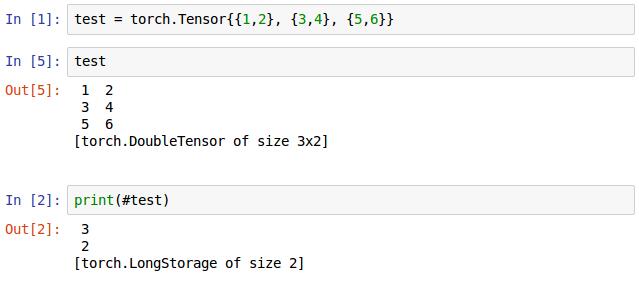
这是一个初始化的张量(Tensor),类似于二维数组,size(1)为3,size(2)为2。
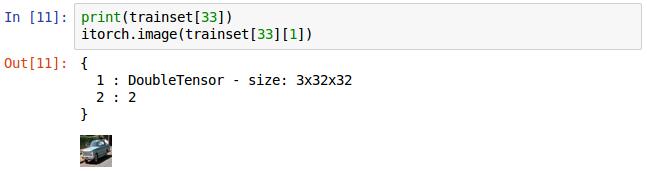
说了这么多就是让之前的trainset.data[33](存的是图片)和trainset.label[33](存的是图片的标签)所包含的数据转变成trainset[33]这种形式表示。itorch.image()显示对应的图片。
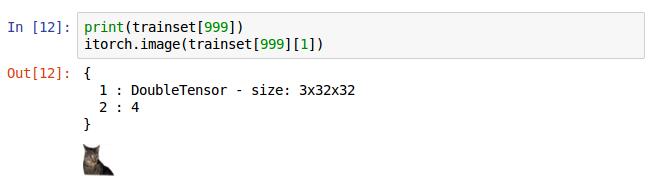
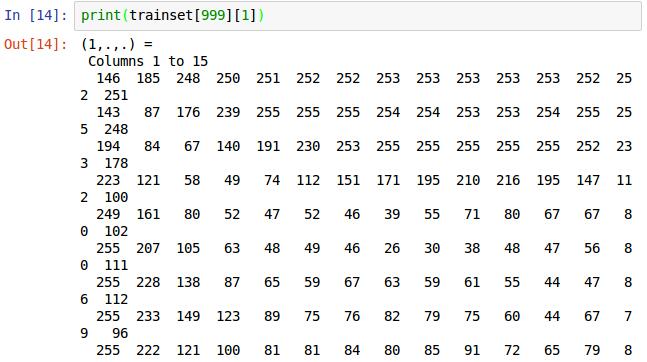
这是第999张图片对应的数据trainset[999],如果换成print(trainset[999][1])则打印的是具体存的图像的数值数值,如下图
下面需要再插入一段,讲解下张量(Tensor)的索引操作
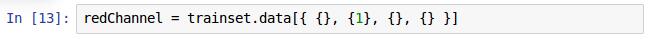
张量的索引操作最开始都是用“[{ }]”,里面的是”{ }“。结合到我们这个例子,trainset.data的张量是4维的,分别代表着”第几张图片“, ”图片的通道“,”图片的纵像素“,”图片的横像素“,”{ }“代表选择该维纵所有的元素。对应第13行代码里为,选取全部图片,选取第1个通道,选取所有x轴和一轴方向的像素。
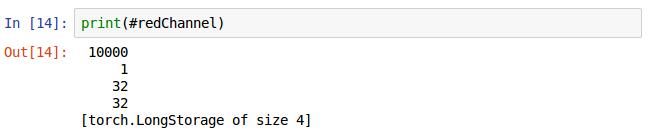
打印出来为上图结果,注意第二维的值由3变为了1
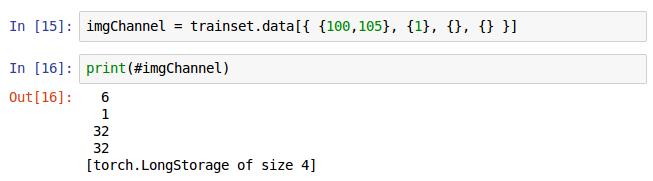
再如这次选取100到105图片,打印结果为6张图片,1通道(红色),32x32像素

创建两数组,分别用来存平均值,和标准差,这一步是做数据中心化以及归一化操作。通俗地说中心化就是让图片对应的矩阵的各个数值以0为原点上下波动而不是在其他的某个值波动,归一化是为了加快和使算法更好地收敛,为什么归一化可见下图
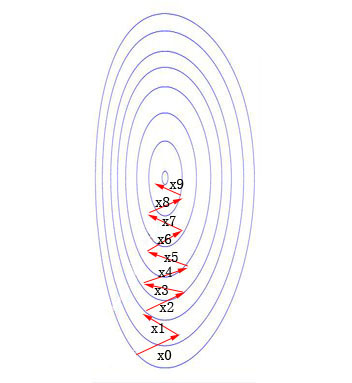
假如未归一化,收敛的过程可能是这种情况,要9步才能收敛到最优值
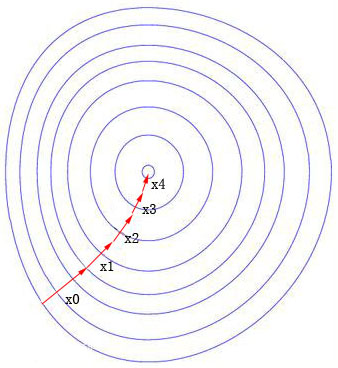
归一化就是将“椭圆”的数据变得“正圆”,这样收敛的速度会加快。
详情请看cousera上面Andrew Ng的讲解
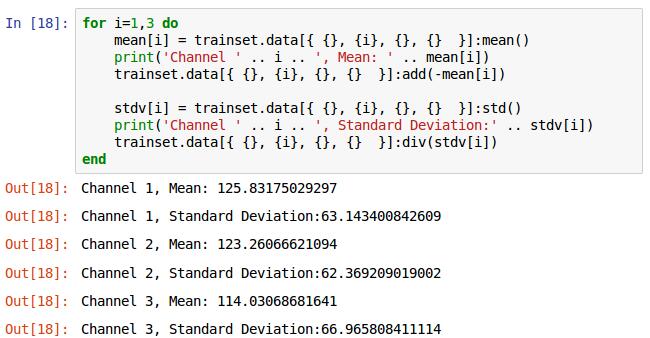
这是一个中心化,归一化的操作,利用for循环完成。
循环是i从1到3,mean[i]为刚刚创建的数组用于存储求得的每个通道的平均值,注意mean( )是求平均值的方法,不要同mean这个数组搞混了。print( )打印算出的第i个通道的平均值mean[i]。调用add( )方法加上负的mean[i]完成中心化。同样,第二部分,算出第i通道的标准差,打印标准差stdv[i],调用div( )除以stdv[i],完成归一化。当然归一化的方法不是唯一的这里是用到标准差处理,相关的其他算法可以google一下。
总结
这一章主要分享预测的基本操作,并且先将前面分享的内容总结下,完整地实现CNN图像分类的实例
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
数据的预处理
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
与之前建立好的网络有一点不同是将原来的1通道变为3通道,输入的数据集是3通道的彩色图像
- 1
- 2
- 3
- 4
- 5
- 6
- 7
训练的过程与前面一样,再重复下,加深印象。
定义损失函数,选择优化的方法,将网路和损失函数传入,设置学习率和最大迭代次数,开始训练,结果如下图。
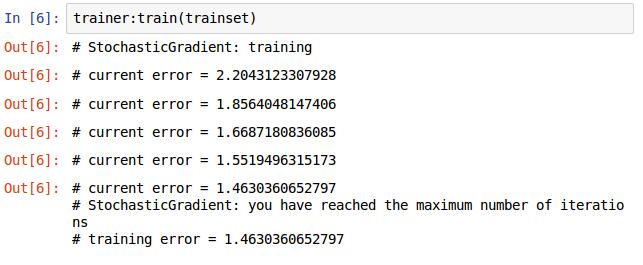
现在我们的CNN网络已经训练完了,迭代次数可以多一些,效果不一样,让我测试下看看效果如何。

将测试的图像数据用先前的平均值和方差进行同训练集一样的中心化和归一化。
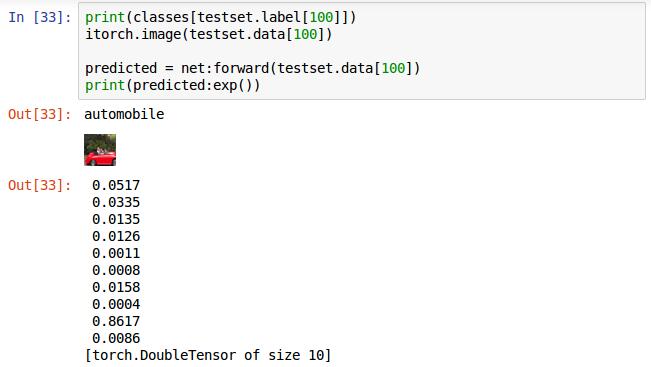
选取第100张图片输入,前两行分别为打印其对应的标签和显示图片,第三行,执行网络的前向传播算法,返回值赋值给predicted。直接打印predicted给出的不是概率而是对数概率。在这十个概率中值最大的为识别的结果,这个是倒数第二个值最大,对应label标签为9,即这张图片被识别成了ship
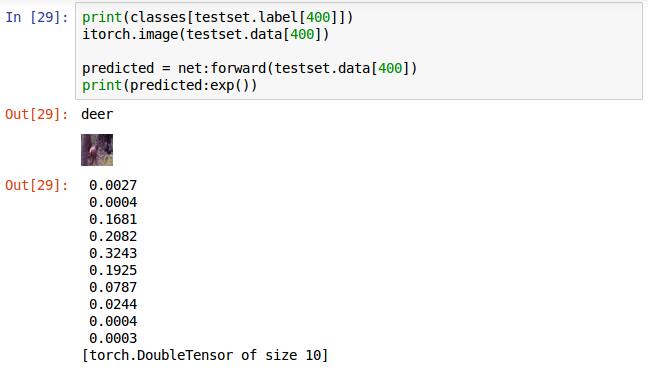
这张最大的是第5个值,即label对应的5,为deer识别正确。

前面的输出的格式还是有些不好,利用torch的sort排序方法将结果排序,返回值中confidences是属于各类的可信度从大到小的排序结果,indices是可信度对应的类的标签,看下打印结果图,一目了然。

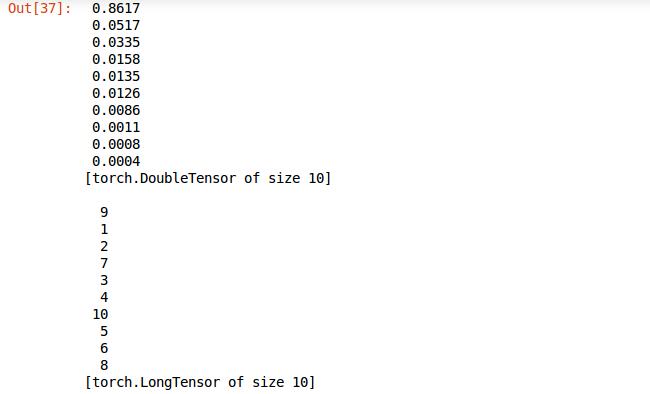

再进一步完善格式,只选取张量的第一个元素打印,并且利用先前定义的classes数组输出名字。
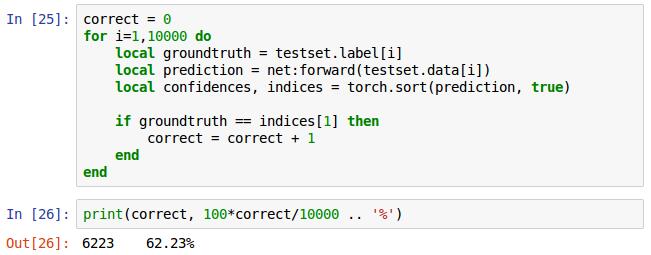
最后是验证总的识别率,for循环,提取测试集中每张照片的标签,每张测试集使用网络net的前向传播forward获得预测结果,将预测结果排序,true表示按递减排序,对比预测结果同真是标签,正确计数器correct加1,将correct除以测试总数10000乘以100得出百分比,这是我迭代10次的正确率为62.23%。

这是统计每类对应的正确率,声明一个数组计数器,用来记录每一类正确识别的个数,改动if语句里面的赋值语句即可完成计数,其他同上。
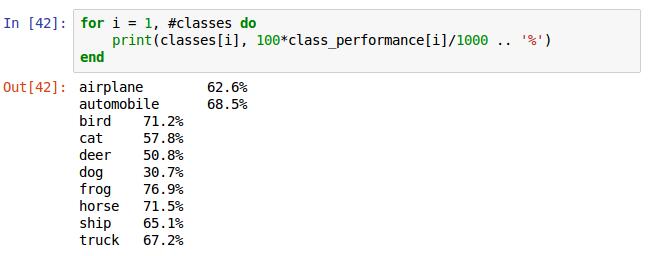
for循环1到classes的数组长度,即10。class_performance[i]里存储的是第i个类的真确识别个数,由于每类有1000张,除以1000,打印结果。
预测的源码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
如果想利用GPU训练该实例用下面的代码替代上文中的训练部分即可
- 1
- 2
- 3
- 4
- 5
- 6
- 7
修改这些就可以使用GPU编程。
这篇关于Torch7深度学习教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






