本文主要是介绍中文点选识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
中文点选识别
测试网站:https://www.geetest.com/adaptive-captcha-demo
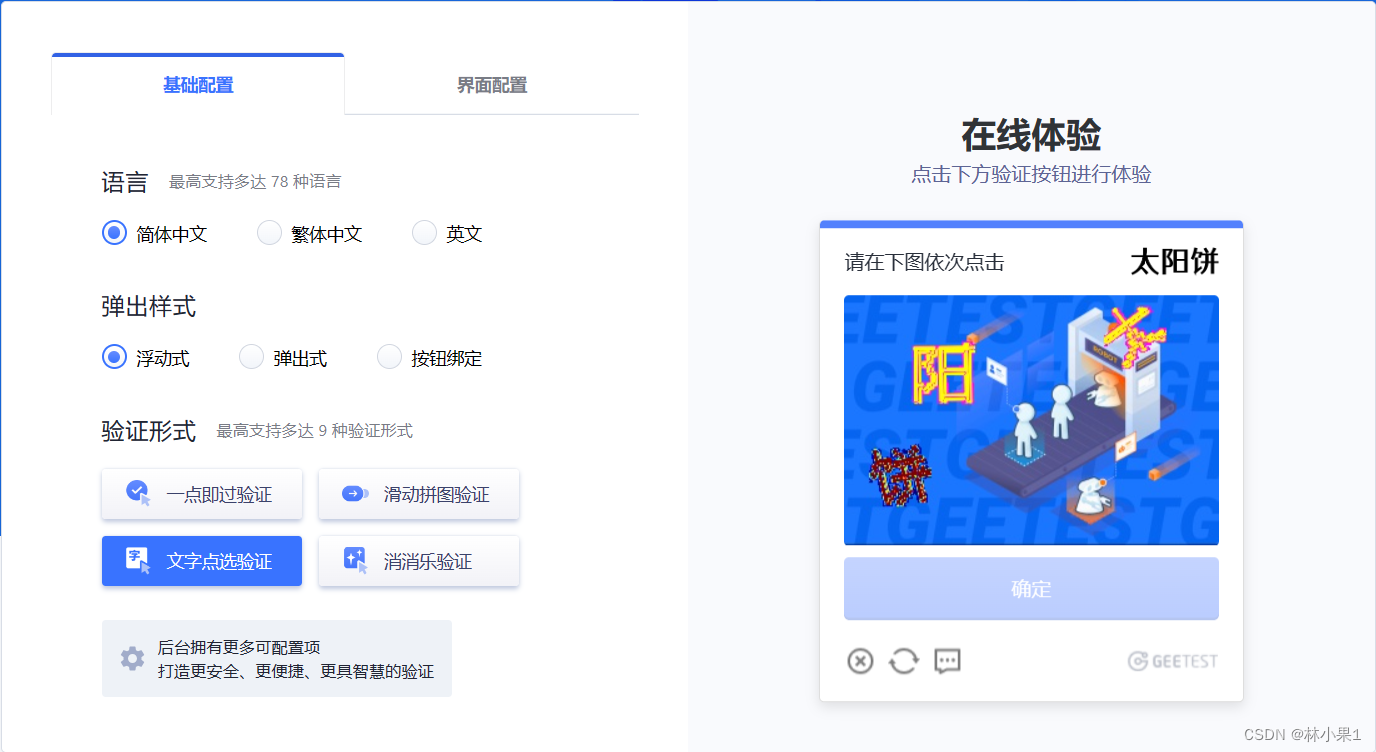
1. 开始验证
# 1.打开首页
driver.get('https://www.geetest.com/adaptive-captcha-demo')# 2.点击【文字点选验证】
tag = WebDriverWait(driver, 30, 0.5).until(lambda dv: dv.find_element(By.XPATH,'//*[@id="gt-showZh-mobile"]/div/section/div/div[2]/div[1]/div[2]/div[3]/div[4]'
))
tag.click()# 3.点击开始验证
tag = WebDriverWait(driver, 30, 0.5).until(lambda dv: dv.find_element(By.CLASS_NAME,'geetest_btn_click'
))
tag.click()time.sleep(5)
2. 获取图片
# 要识别的目标图片
parent = driver.find_element(By.CLASS_NAME, 'geetest_ques_back')
tag_list = parent.find_elements(By.TAG_NAME, "img")
3. 目标文字识别
target_word_list = []
for tag in tag_list:ocr = ddddocr.DdddOcr(show_ad=False)word = ocr.classification(tag.screenshot_as_png)target_word_list.append(word)print("要识别的文字:", target_word_list)
4. 背景坐标识别
超级鹰:https://www.chaojiying.com/
import base64
import requestsres = requests.post(url='http://upload.chaojiying.net/Upload/Processing.php',data={'user': "自己的用户名",'pass': "自己的密码",'codetype': "9501",'file_base64': base64.b64encode(content)},headers={'Connection': 'Keep-Alive','User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',}
)res_dict = res.json()
print(res_dict)
结果:
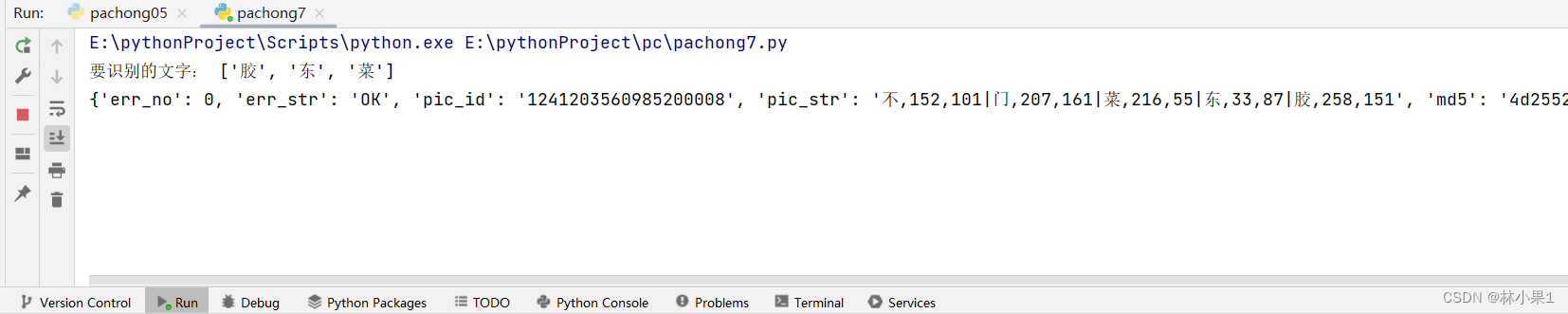
将结果封装成字典,方便后续找到相应的字并点击
bg_word_dict = {}
for item in res_dict["pic_str"].split("|"):word, x, y = item.split(",")bg_word_dict[word] = (x, y)
print(bg_word_dict)

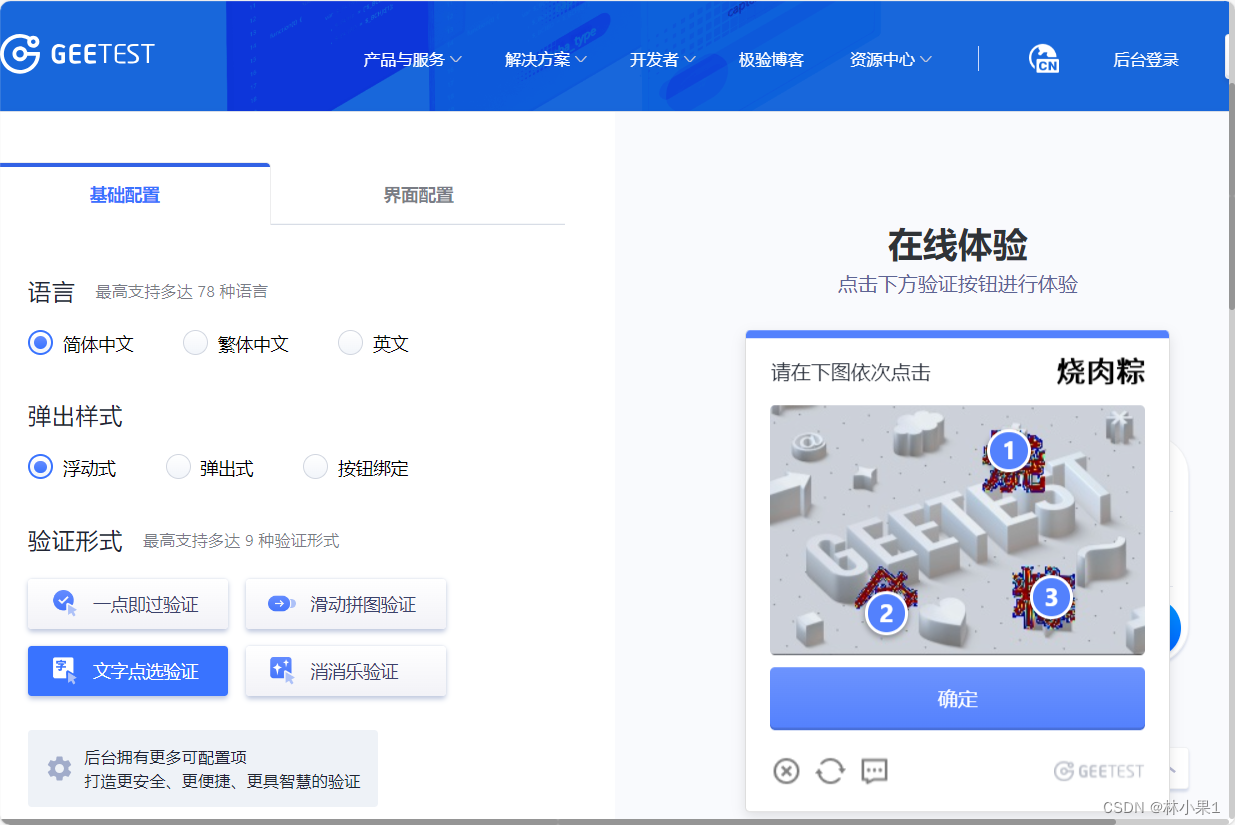
5. 坐标点击
根据坐标,在验证码上进行点击。
# 8.点击
from selenium.webdriver import ActionChainsfor word in target_word_list:time.sleep(0.5)group = bg_word_dict.get(word)if not group:continuex, y = groupx = int(x) - int(bg_tag.size['width'] / 2)y = int(y) - int(bg_tag.size['height'] / 2) # 超级鹰获取到的坐标原点为图片左上角,而我们需要的坐标原点为图片中心,所以需要进行转换。ActionChains(driver).move_to_element_with_offset(bg_tag, xoffset=x, yoffset=y).click().perform()time.sleep(1000)driver.close()
结果:
6. 完整代码
import base64
import timeimport ddddocr
import requests
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWaitdriver = webdriver.Edge()
# 1.打开首页
driver.get('https://www.geetest.com/adaptive-captcha-demo')# 2.点击【文字点选验证】
tag = WebDriverWait(driver, 30, 0.5).until(lambda dv: dv.find_element(By.XPATH,'//*[@id="gt-showZh-mobile"]/div/section/div/div[2]/div[1]/div[2]/div[3]/div[4]'
))
tag.click()# 3.点击开始验证
tag = WebDriverWait(driver, 30, 0.5).until(lambda dv: dv.find_element(By.CLASS_NAME,'geetest_btn_click'
))
tag.click()time.sleep(3)# 要识别的目标图片
parent = driver.find_element(By.CLASS_NAME, 'geetest_ques_back')
tag_list = parent.find_elements(By.TAG_NAME, "img")# 识别图片
target_word_list = []
for tag in tag_list:ocr = ddddocr.DdddOcr(show_ad=False)word = ocr.classification(tag.screenshot_as_png)target_word_list.append(word)print("要识别的文字:", target_word_list)# 6.背景图片
bg_tag = driver.find_element(By.CLASS_NAME,'geetest_bg'
)
content = bg_tag.screenshot_as_png# 7.识别背景中的所有文字并获取坐标
ocr = ddddocr.DdddOcr(show_ad=False, det=True)
poses = ocr.detection(content) res = requests.post(url='http://upload.chaojiying.net/Upload/Processing.php',data={'user': "自己的用户名",'pass': "自己的密码",'codetype': "9501",'file_base64': base64.b64encode(content)},headers={'Connection': 'Keep-Alive','User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',}
)res_dict = res.json()
print(res_dict)# 封装成字典
bg_word_dict = {}
for item in res_dict["pic_str"].split("|"):word, x, y = item.split(""",")bg_word_dict[word] = (x, y)
print(bg_word_dict)# 8.点击
for word in target_word_list:time.sleep(0.5)group = bg_word_dict.get(word)if not group:continuex, y = groupx = int(x) - int(bg_tag.size['width'] / 2)y = int(y) - int(bg_tag.size['height'] / 2) # 超级鹰获取到的坐标原点为图片左上角,而我们需要的坐标原点为图片中心,所以需要进行转换。ActionChains(driver).move_to_element_with_offset(bg_tag, xoffset=x, yoffset=y).click().perform()time.sleep(5)
driver.close()
这篇关于中文点选识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








