本文主要是介绍了解数据治理体系化建模,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、走近数据体系化建模
(一)软件体系化建模
(二)数据体系化建模
二、数据体系化建模实践
三、数据管理考量思考
(一)数据质量方面的考量
(二)数据安全、合规方面的考量
对数据治理的体系化建模进行初步的了解和接触。
一、走近数据体系化建模
(一)软件体系化建模
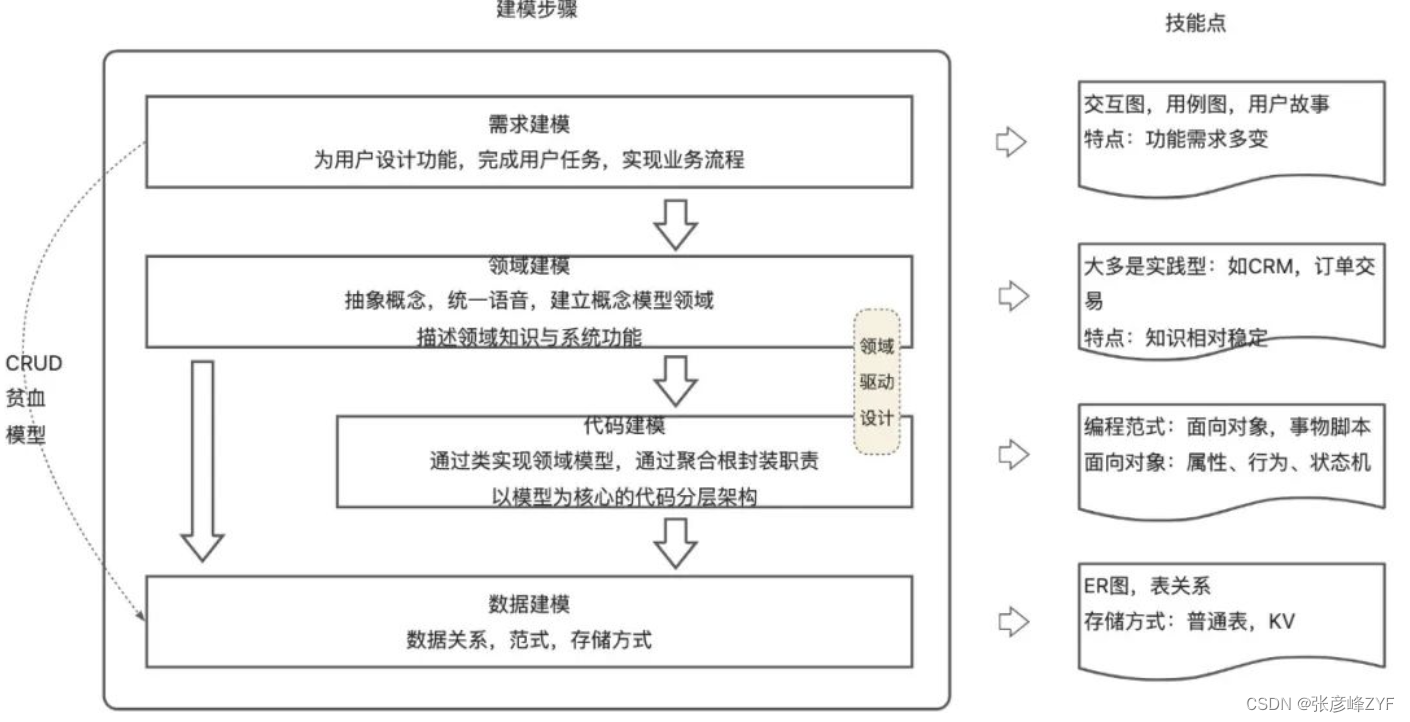
建模一般都是一项体系化的工程,需要对问题进行拆解并给出解决方案,通常建模顺利落地可拆分为四个子问题:
-
需求模型:首先需要深入了解用户的需求,这可以通过与产品团队和业务人员的密切合作来实现。这包括收集和分析用户反馈、行业数据以及业务流程。目标是确保我们理解用户的真实需求,而不仅仅是他们表面上提出的需求。
-
领域模型:基于对需求的理解,建立起领域模型。这是一种抽象层次,用于捕捉业务领域中的关键概念和它们之间的关系。这个过程通常涉及到识别和定义领域模型中的实体、属性和行为。
-
代码模型:在领域模型的基础上,进行面向对象的设计。这包括确定类的结构、方法和属性,以及它们之间的关系。在这个阶段,会考虑到面向对象设计的各种原则和技巧,以确保代码的可维护性、扩展性和复用性。
-
数据模型:最后一步是将代码模型映射到数据模型。这可以通过绘制实体关系图(ER图)来实现,用于描述数据在底层存储中的结构和关系。这个步骤确保代码模型与实际的数据存储方案相一致。
与软件建模类似,数据建模(数据建模是指对数据进行抽象和组织,以便在计算机系统中存储、操作和访问)也需要一套系统化的方法来理解数据的需求、组织结构和关系。
(二)数据体系化建模
体系化建模是以维度建模为理论基础,以事前治理为理念驱动,通过元数据贯穿建模流程。上承指标和维度的定义,下接实际的数据生产。具体而言,体系化建模包括以下步骤:
-
高层模型设计:首先,将业务指标结构化拆解为原子指标、计算指标以及限定条件的组合方式。然后,将这些指标归属到特定的业务过程和主题下,完成业务指标的计划化定义。
-
物理模型设计:基于高层模型设计,自动生成详细的物理模型设计。物理模型设计包括将高层模型转化为可操作的物理结构,确保数据的正确存储和处理。
-
数据加工逻辑生成:基于产生的物理模型设计,半自动或自动地生成数据加工逻辑。这些逻辑用于将原始数据转换为可用于分析和报告的格式,以确保最终的业务定义和物理实现的统一。
通过体系化建模,可以实现业务指标和数据的统一定义,并确保数据处理过程的可追溯性和一致性。这种方法能够提高数据治理的效率和质量,为数据驱动的决策提供可靠的支持。
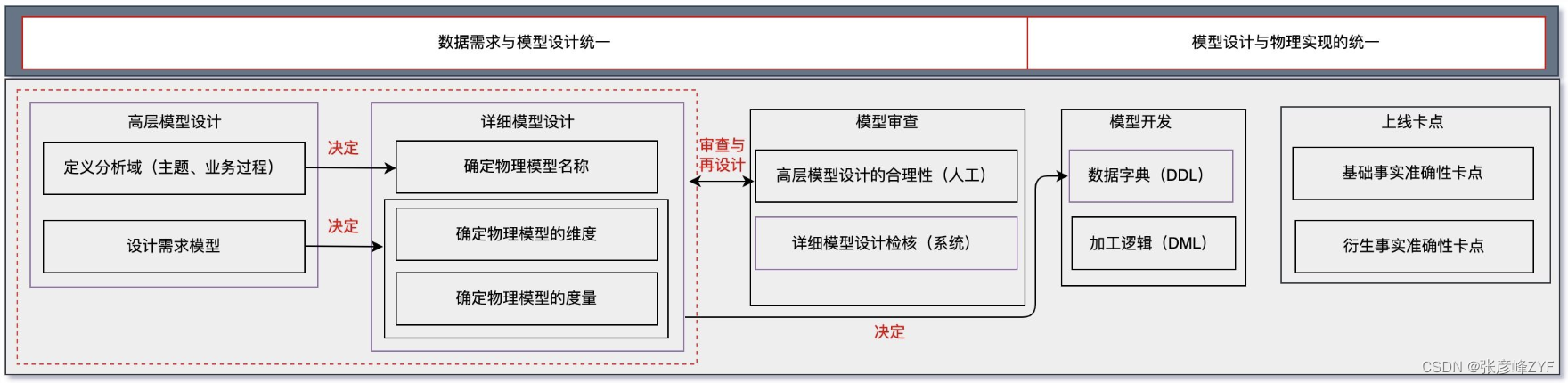
体系化建模强调了两个统一:数据需求与模型设计的统一以及模型设计与物理实现的统一。
数据需求与模型设计的统一:
- 模型设计是仓库领域划分和具体需求相结合的产物。仓库领域划分是对数据进行基于业务但超越业务需求限制的抽象,完成对数据的主题、业务过程的抽象,作为业务指标、维度需求归属和实现数据建设的依据。
- 具体的需求模型设计在仓库领域划分的基础上进行,将需求以指标、维度的形式归属到对应的主题与业务过程,驱动和约束具体详细模型设计,形成信息架构资产。
模型设计与物理实现的统一:
- 基于模型设计环节沉淀的信息架构元数据,驱动和约束实际的物理模型设计,以确保业务定义与物理实现的一致性。
- 在数据加工过程中,利用元数据约束对应物理模型的数据定义语言(DDL),防止因缺乏有效约束而导致的分散式开发,确保数据操作语言(DML)实现的正确性。
- 在模型上线前,自动完成业务定义与物理实现一致性验证,从而确保数据处理过程中数据需求与模型设计之间的统一,以及模型设计与物理实现之间的统一。
二、数据体系化建模实践
目标是实现数据建模和ETL开发的紧密结合,确保从需求到实现的整个过程是一体化:将数据规范定义、数据模型设计和ETL开发链接在一起,以实现“设计即开发,所建即所得”。
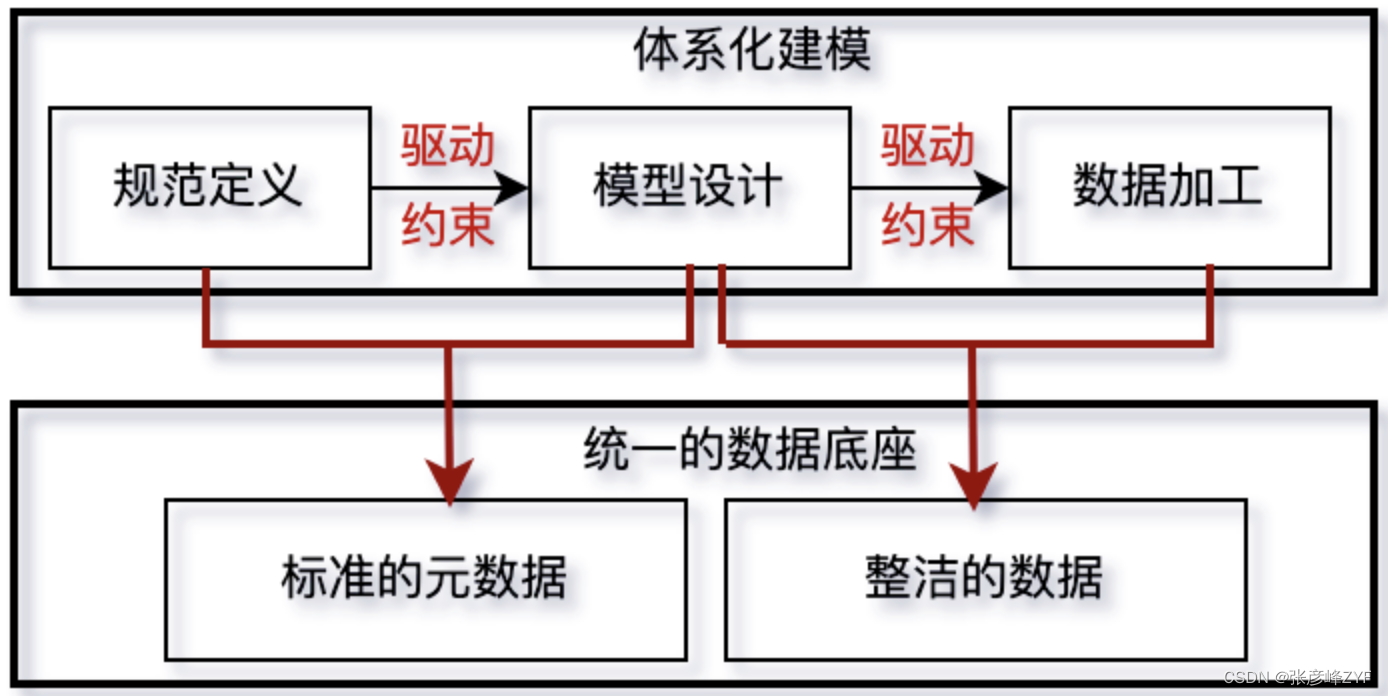
通过数仓规划和数据定义标准来实现高层模型设计和物理模型设计之间的协同,并确保模型设计与数据加工的有效对接。
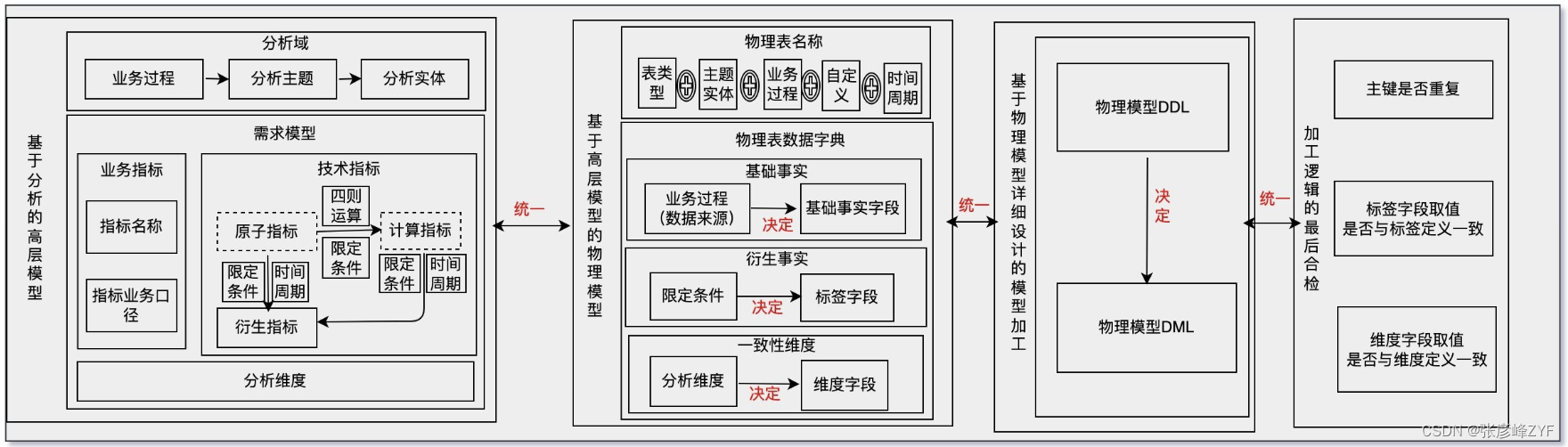
具体时间上主要包括基于分析的高层模型确定、基于高层模型的物理模型、基于物理模型详细设计的模型加工以及加工逻辑的最后合检等,具体详细的可以细分如下:
-
数仓规划和业务指标映射:首先,通过数仓规划,将业务需求中提出的指标和维度映射到对应的主题和业务过程。理清业务逻辑确保数据模型能够准确反映业务需求。
-
数据定义标准和结构化拆解:基于数据定义标准,对业务指标进行结构化拆解,将其技术定义化。这包括确定指标的数据类型、精度、计算逻辑等,以确保指标能够在数据模型中得到准确表示。
-
高层模型设计:在拆解和定义业务指标的基础上,进行高层模型设计。可能涉及到确定主题和实体之间的关系,以及定义维度和度量。高层模型设计为后续的物理模型设计提供了指导和约束。
-
元数据驱动的物理模型设计:基于高层模型设计所沉淀的元数据,驱动和约束最终的物理模型设计。这包括确定表的结构、键、索引等,以及确保物理模型与高层模型的一致性。
-
确定DDL并约束数据开发:根据物理模型设计,确定最终的数据定义语言(DDL),并将其用于约束后续的数据开发过程。DDL定义了数据表的结构和约束条件,确保数据开发能够按照设计要求进行。
通过这个过程,实现了高层模型设计和物理模型设计之间的有效协同,确保数据模型能够准确地反映业务需求,并为后续的数据加工提供了清晰的指导和约束。
三、数据管理考量思考
实施数据治理一体化实践的体系化建模需要综合考虑数据管理的方方面面,包括数据质量、数据安全、数据合规等方面。
(一)数据质量方面的考量
在数据治理一体化实践中,数据质量是一个至关重要的方面。良好的数据质量能够确保数据可信度、准确性和完整性,从而支持组织的决策和运营活动。
-
数据质量度量指标:制定适用于组织的数据质量度量指标,例如准确性、完整性、一致性、时效性等。这些指标可以帮助组织评估数据质量水平,并定期监控数据质量的变化。
-
数据质量规则和标准:制定数据质量规则和标准,定义数据质量的期望水平和标准。例如,对于每个数据元素,确定其允许的值范围、格式、精度等。
-
数据质量评估和监控:建立数据质量评估和监控机制,定期对数据质量进行评估和监控。可以包括使用自动化工具进行数据质量检查、制定数据质量报告等。针对发现的数据质量问题,制定数据质量改进计划,并采取相应的措施进行改进。这可能涉及到数据清洗、数据修复、数据标准化等。
-
数据权限与管理:明确数据质量的责任与义务,包括数据所有者、数据管理员、数据质量团队等在内的相关角色。确保每个角色都清楚其在数据质量方面的责任,并有相应的授权和资源支持。进行数据质量培训与意识提升,使组织成员了解数据质量的重要性,掌握相关的数据质量工具和技能,并能够积极参与到数据质量管理的过程中来。
综合考虑这些因素,可以建立一个综合的数据质量管理框架,有效地提高组织的数据质量水平,并确保数据质量与整体数据治理实践的一体化。
(二)数据安全、合规方面的考量
数据安全涵盖保护数据免受未经授权访问、泄露、篡改或破坏的各种威胁。
-
访问控制:确保只有经过授权的用户能够访问特定的数据资源。这可以通过实施访问控制策略、权限管理和身份验证机制来实现。
-
数据加密:对敏感数据进行加密,以防止数据在传输和存储过程中被未经授权的人员访问。包括数据传输过程中的加密和数据存储介质上的加密。
-
数据备份与恢复:建立有效的数据备份与恢复策略,确保在发生数据丢失或损坏时能够迅速恢复数据。备份应该定期进行,并存储在安全可靠的位置。
-
漏洞管理:定期进行漏洞扫描和安全审计,及时发现和修复系统中的安全漏洞和弱点。
-
合规性和监管要求:确保数据处理活动符合适用的合规性和监管要求,如GDPR、HIPAA等。包括对数据处理活动进行审计和监管,并确保数据安全措施符合法律和行业标准。
通过综合考虑以上因素采取相应的措施和控制措施,可以有效保护组织的数据安全,并确保数据安全与整体数据治理实践的一体化。
推荐阅读:
数据治理一体化实践之体系化建模 - 美团技术团队
数据治理的本质:体系化建模(1)-阿里云开发者社区
数据治理一体化实践之体系化建模-腾讯云开发者社区-腾讯云
领域建模的体系化思维与6种方法论
数据仓库建模体系化总结-百度开发者中心
谈谈如何理解数据建模也是数据治理的一种形式-阿里云开发者社区
实时数据产品实践——美团大交通战场沙盘 - 美团技术团队
这篇关于了解数据治理体系化建模的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






