本文主要是介绍FPN——如雷贯耳的“特征金字塔” (目标检测)(one/two-stage)(深度学习)(CVPR 2017),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文名称:《 Feature Pyramid Networks for Object Detection 》
论文下载:https://arxiv.org/abs/1612.03144
论文代码:https://github.com/unsky/FPN(非官方)
1、模型概述:
目前多尺度的物体检测主要面临的挑战为:
(1)如何学习具有强语义信息的多尺度特征表示?
(2)如何设计通用的特征表示来解决物体检测中的多个子问题?如 object proposal, box localization, instance segmentation.
(3)如何高效计算多尺度的特征表示?
本文针对这些问题,提出了特征金字塔网络 FPN。
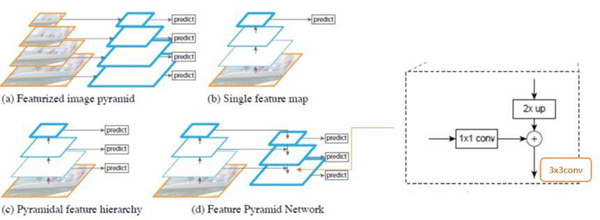
如图 (d) 所示,网络直接在原来的单网络上做修改,每个分辨率的 feature map 引入后一分辨率缩放两倍的 feature map 做 element-wise 相加的操作。通过这样的连接,每一层预测所用的 feature map 都融合了不同分辨率、不同语义强度的特征,融合的不同分辨率的 feature map 分别做对应分辨率大小的物体检测。这样保证了每一层都有合适的分辨率以及强语义特征。同时,由于此方法只是在原网络基础上加上了额外的跨层连接,在实际应用中几乎不增加额外的时间和计算量。

FPN 是基于一个特征提取网络的,它可以是常见的 ResNet 或者 DenseNet 之类的网络。在你最常用的深度学习框架下取一个预训练模型,就可以用来实现 FPN 了。
图像里的目标尺寸大小各种各样,数据集里的物体不可能涵盖所有的尺度,所以人们利用图像金字塔(不同分辨率的下采样)来帮助 CNN 学习。但是这样的速度太慢了,所以人们只使用单一尺度来预测,也有人会取中间结果来预测。后者和前者很像,只不过是在特征图上的。比较容易想到的方法是,在几层残差模块后面加一层转置卷积,提高分辨率,得到分割的结果,或者通过 1x1 的卷积或 GlobalPool 得到分类的结果。这种架构在有辅助信息和辅助损失函数时被大量使用。
模型细节
-
金字塔 - 同样尺寸的特征图属于同一级。每级最后一层输出是金字塔的特征图,比如 ResNet 第2,3,4,5个模块的最后一层。你可以根据需要进行调整。
-
侧向连接:通过 1x1 卷积并与经过上采样的从上到下连接的结果相加求和。自上而下的部分生成粗粒度特征,自下而上的部分通过侧向连接加入细粒度特征。原文的图示表达的非常明了。
-
原文中只是用一个简单的例子展示了 FPN 的设计之简单以及效果之可观,这不代表它不能用于更复杂的研究中。
除了侧向的连接,还加入了自上而下的连接。这样做效果非常好。作者把从上到下的结果和侧向得到的结果通过相加的办法融合到一起。这里的重点在于,低层次的特征图语义不够丰富,不能直接用于分类,而深层的特征更值得信赖。将侧向连接与自上而下的连接组合起来,就可以得到不同分辨率的的特征图,而它们都包含了原来最深层特征图的语义信息。
2、网络结构:
作者的主网络是使用的ResNet,而特征图金字塔分成三个部分,一个自底向上的路径(左边),一个自顶向下的路径(右边)和中间的连接部分。

(1)自底向上的路径:
自下而上的路径是卷积网络的前馈计算,该算法计算由不同比例的特征映射组成的特征层级,其缩放步长为2。通常有许多层产生相同大小的输出映射,并且我们说这些层 处于相同的网络阶段。 对于我们的特征图金字塔,为每个阶段定义一个金字塔等级, 然后选择每个阶段的最后一层的输出作为我们特征图的参考集。 这种选择是自然的,因为每个阶段的最深层应具有最强的特征。
具体而言,对于ResNets,我们使用每个阶段的最后一个residual block输出的特征激活输出。 对于conv2,conv3,conv4和conv5输出,我们将这些最后residual block的输出表示为{C2,C3,C4,C5},并且它们相对于输入图像具有{4, 8, 16, 32} 的步长。 由于其庞大的内存占用,我们不会将conv1纳入金字塔中。
(2)自顶向下的路径:
自顶向下的路径通过对在空间上更抽象但语义更强高层特征图进行上采样来幻化高分辨率的特征。随后通过侧向连接从底向上的路径,使得高层特征得到增强。每个横向连接自底向上路径和自顶向下路径的特征图具有相同的尺寸。将低分辨率的特征图做2倍上采样(为了简单起见,使用最近邻上采样)。然后通过按元素相加,将上采样映射与相应的自底而上映射合并。这个过程是迭代的,直到生成最终的分辨率图。 为了开始迭代,我们只需在C5上附加一个1×1卷积层来生成低分辨率图P5。最后,我们在每个合并的图上附加一个3×3卷积来生成最终的特征映射,这是为了减少上采样的混叠效应。这个最终的特征映射集称为{P2,P3,P4,P5},分别对应于{C2,C3,C4,C5},它们具有相同的尺寸。 由于金字塔的所有层次都像传统的特征化图像金字塔一样使用共享分类器/回归器,因此我们在所有特征图中固定特征维度(通道数,记为d)。我们在本文中设置d = 256,因此所有额外的卷积层都有256个通道的输出。

(3)中间连接:
采用1×1的卷积核进行连接(减少特征图数量)。
3、实验结果:
作者接下来实验了将 FPN 应用在 Faster RCNN 上的性能,在 COCO 上达到了 state-of-the-art 的单模型精度。具体而言,FPN 分别在 RPN 和 Fast RCNN 两步中起到作用。其中 RPN 和 Fast RCNN 分别关注的是召回率和正检率,在这里对比的指标分别为 Average Recall(AR) 和 Average Precision(AP)。分别对比了不同尺度物体检测情况,小中大物体分别用 s,m,l 表示。在 RPN 中,区别于原论文直接在最后的 feature map 上设置不同尺度和比例的 anchor,本文的尺度信息对应于相应的 feature map(分别设置面积为 32^2, 64^2, 128^2, 256^2, 512^2),比例用类似于原来的方式设置 {1:2, 1:1,, 2:1} 三种。与 RPN 一样,FPN 每层 feature map 加入 3*3 的卷积及两个相邻的 1*1 卷积分别做分类和回归的预测。
在 RPN 中,实验对比了 FPN 不同层 feature map 卷积参数共享与否,发现共享仍然能达到很好性能,说明特征金字塔使得不同层学到了相同层次的语义特征。RPN 网络的实验结果为:
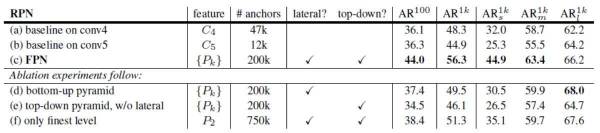
这里 FPN 对比原来取自 conv4 和 conv5 的 RPN 网络 (a)(b),召回率得到了大幅度提升,尤其在中物体和小物体上 (c)。另外,作者做了变量对比实验,比如只保留横向连接 (d),即特征分层网络,性能仅与原 RPN 差不多,原因就在于不同层之间的语义特征差距较大。另外,试验了砍掉横向连接,只保留自上而下放大 feature map 做预测结果 (e),以及只用最终得到的 feature map 层 (f),均比完整的 FPN 网络小物体检测 AR 低 10 个点左右。说明金字塔特征表示与横向连接都起了很大作用。实验 Fast RCNN 时,需要固定 FPN+RPN 提取的 proposal 结果。在 Fast RCNN 里,FPN 主要应用于选择提取哪一层的 feature map 来做 ROI pooling。
假设特征金字塔结果对应到图像金字塔结果。定义不同 feature map 集合为 {P2, P3, P4, P5},对于输入网络的原图上 w*h 的 ROI,选择的 feature map 为 Pk,其中(224 为 ImageNet 输入图像大小):
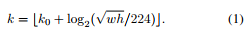
类似于 RPN 的实验,对比了原有网络,以及不同改变 FPN 结构的 Fast RCNN 实验,实验结果为:

实验发现 FPN 筛选 ROI 区域,同样对于 Fast RCNN 的小物体检测精度有大幅提升。同时,FPN 的每一步都必不可少。最后,FPN 对比整个 Faster RCNN 的实验结果如下:

对比其他单模型方法结果为:

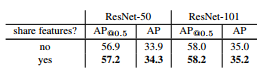
最后是在 FPN 基础上,将 RPN 和 Fast RCNN 的特征共享,与原 Faster CNN 一样,精度得到了小幅提升。FPN+Faster RCNN 的方法在 COCO 数据集上最终达到了最高的单模型精度。
总结起来,本文提出了一种巧妙的特征金字塔连接方法,实验验证对于物体检测非常有效,极大提高了小物体检测性能,同时由于相比于原来的图像金字塔多尺度检测算法速度也得到了很大提升。
这篇关于FPN——如雷贯耳的“特征金字塔” (目标检测)(one/two-stage)(深度学习)(CVPR 2017)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






