本文主要是介绍excel统计分析——多组数据的秩和检验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
单因素资料不完全满足方差的基本假定时,可进行数据转换后再进行方差分析,但有时数据转换后仍不满足方差分析的基本假定,就只能进行秩和检验了。
多组数据秩和检验的主要方法为Kruskal-Wallis检验,也称为Kruskal-Wallis秩和方差分析或H检验。Kruskal-Wallis不要求总体呈正态分布,但要求总体方差相等,为连续总体,各组效应相互独立,所有样本来自随机抽样,利用秩和来推断样本所在总体分布是否相同。
Kruskal-Wallis秩和检验的基本思想如下:在H0成立的前提下,k个样本中的任何观察值取秩为1~N的概率相等。因此,每个样本平均秩的期望值均为,检验统计量
反映实际获得的k个独立样本的平均秩与期望值的偏离程度。样本平均秩与
相差越大,则H越大,P越小;反之,H越大,P越小。当H0成立时,随着样本容量的增长,H近似服从自由度为k-1的卡方分布。当k及样本容量较小时,可直接计算统计量H的概率分布,构造适于实际应用的H临界值表,以确定P值。当k及样本容量较大时,可利用卡方分布进行检验。
Kruskal-Wallis秩和检验的基本步骤如下:
(1)提出假设。
零假设H0:各样本的总体分布相同。
备择假设HA:各样本的总体分布不完全相同。
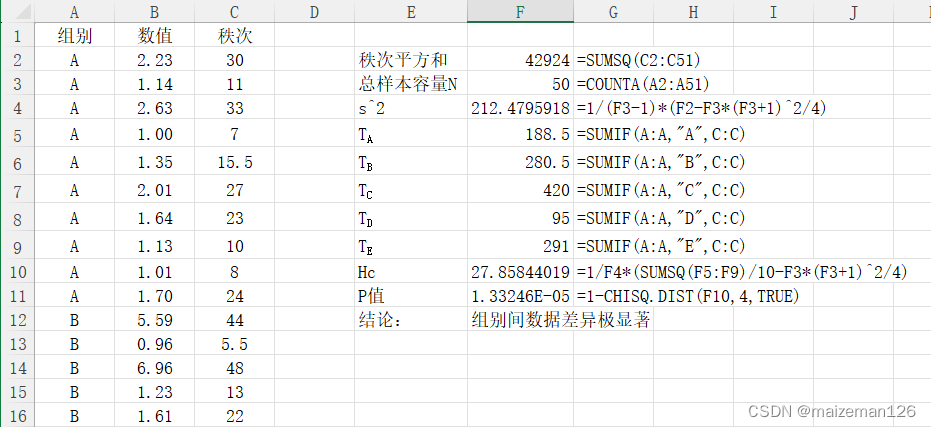
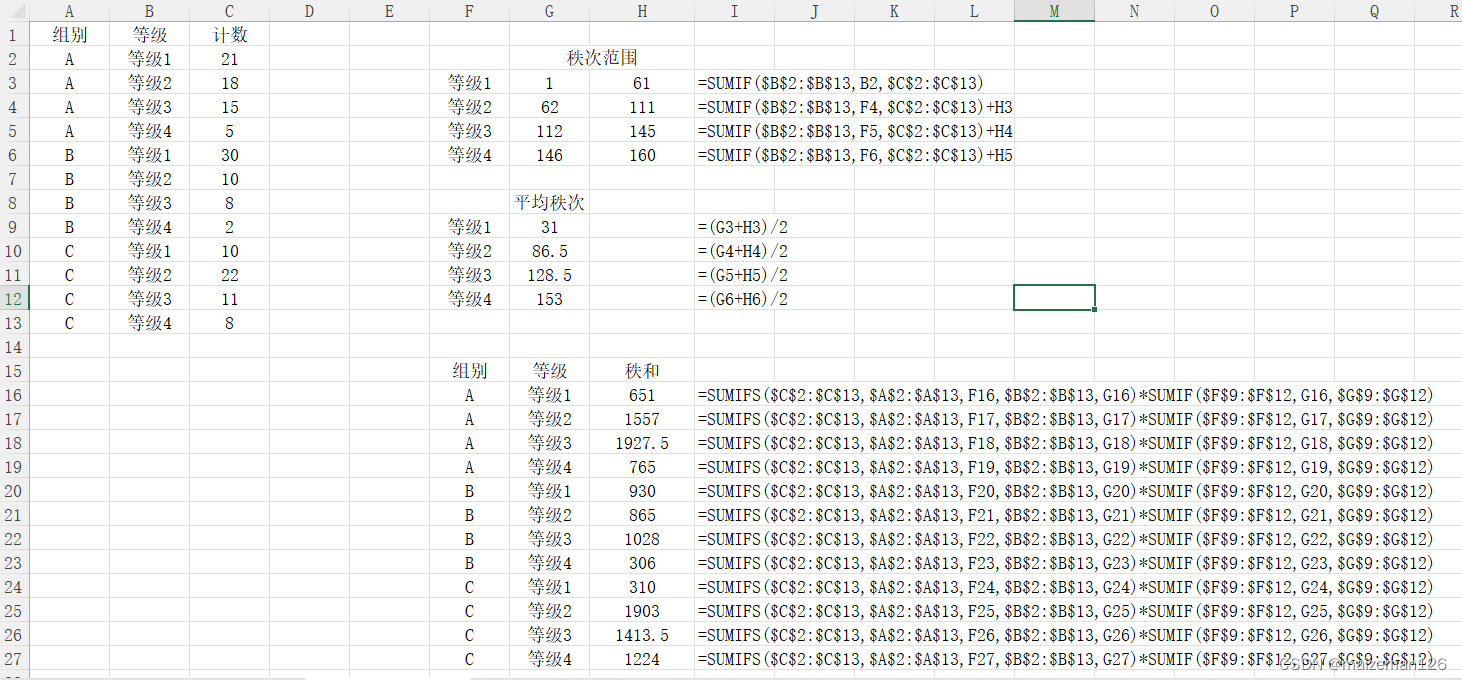
(2)编秩次、求秩和。
将各样本数据混合,从小到大编秩次。遇观察值相同时,求平均秩次。将各样本观察值对应的秩次分别累加,求出各样本的秩和。
(3)确定检验统计量H:
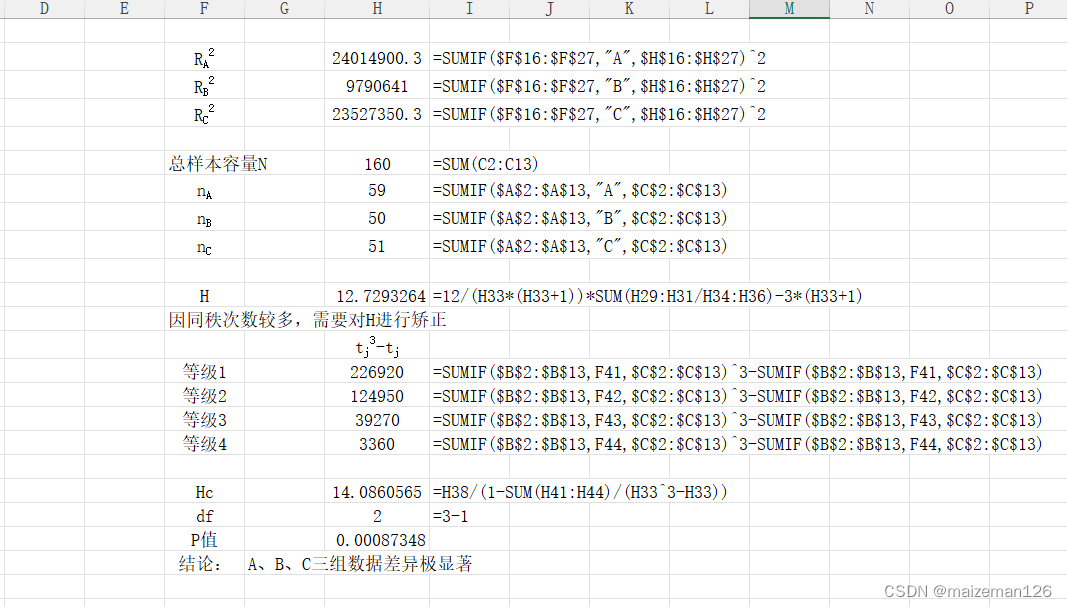
其中:Rj为第j个样本的秩和;nj为第j个样本容量;N为样本总量,即。如多个观察值同秩,则按下式求矫正的Hc:
其中,s^2为所有观察值秩转换后形成的秩变量的方差,与观察值的方差相同,即
Rij为第j个样本第i个观察值的秩次。
或按下式求矫正Hc:
其中,tj表示某个同秩的个数
(4)统计推断。
当k≤3且≤5时,可直接查Kruskal-Wallis秩和检验临界值表,H与临界值Hα比较,如果H<Hα,则P>α,表明各样本总体分布在α水平上差异不显著。当样本数k>3或
>5时,H近似服从df=k-1的卡方分布,可进行卡方检验。
excel案例操作如下:
①计量资料秩和检验
②等级资料秩和检验
这篇关于excel统计分析——多组数据的秩和检验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








