本文主要是介绍供应链 | POMS解读:新鲜农产品的动态定价与信息披露:一种人工智能方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

问题简介
本文主要研究了动态定价和信息披露对于生鲜产品销售的影响。在传统的销售模式中,生鲜产品的价格通常是固定的,而且很难根据实际情况进行调整。这种模式容易导致浪费和损失,同时也无法满足消费者对于品质和价格的需求。因此,文章提出了一种基于质量的动态定价策略,并探讨了信息披露对于销售效果的影响。使用深度强化学习算法来优化定价和信息策略,可以使得销售商能够更好地满足消费者需求,提高利润并减少浪费。因此文章为生鲜产品销售提供了一种新思路,并为相关行业提供了有益的参考。
模型建立
该文章的模型是基于一个单一的垄断零售商销售新鲜农产品的情景。在此情景中,消费者对食品质量有不同的感知,而零售商需要根据消费者需求来制定价格策略和信息披露策略。
文章沿用 Gallego and Van Ryzin (1994) 构建的模型作为基本模型,并在其基础上考虑了产品质量的变化和信息披露的行为。假定初始时有 C C C 个单位的库存并且后续无法补货,产品质量根据 θ = Q e − y t + ϵ t \theta=Qe^{-yt} + \epsilon_t θ=Qe−yt+ϵt, ϵ t ∼ N ( 0 , σ 2 ) \epsilon_t\sim\mathcal{N}(0,\sigma^2) ϵt∼N(0,σ2)指数速度下降。不同的消费者对于指数损耗率 γ \gamma γ有不同的感知 γ ^ \hat{\gamma} γ^. 消费者被分为三类
- 认为损耗率高于实际损耗率,即 γ ^ > γ \hat{\gamma}>\gamma γ^>γ
- 认知与实际相符,即 γ ^ = γ \hat{\gamma} = \gamma γ^=γ
- 认为损耗率低于实际损耗率,即 γ ^ < γ \hat{\gamma}<\gamma γ^<γ
假设消费者的到达服从 Poisson 分布;消费者选择购买,如果商品的实际价格低于保留价格,并且实际质量高于保留质量。假设消费者的保留价格和保留质量的分布分别为 F ( ⋅ ) F(\cdot) F(⋅), M ( ⋅ ) M(\cdot) M(⋅), 于是消费者会发生购买行为的概率为 ( 1 − F ( p t ) ) M ( θ ^ t ) (1-F(p_t))M(\hat{\theta}_t) (1−F(pt))M(θ^t). 于是,商家的决策可以建模成一个离散时间马尔可夫决策过程(MDP),状态空间由剩余库存和产品质量组成,行动由定价和是否吐露真实质量信息组成。在时刻 t t t,真实质量信息披露的被设置为一个以 m t ∈ [ 0 , 1 ] m_t\in[0,1] mt∈[0,1]为概率的随机行为。消费者分为三类( γ ^ ( > , = , > ) γ \hat{\gamma}(>,=,>)\gamma γ^(>,=,>)γ) 对产品损耗率 γ \gamma γ分别有先验分布 p 0 ( γ ^ i ) ∼ N ( μ i 0 , σ i 0 2 ) p_0(\hat{\gamma}_i)\sim\mathcal{N}(\mu_{i0},\sigma_{i0}^2) p0(γ^i)∼N(μi0,σi02), 在收到商家的信息披露之后,依照贝叶斯公式 p ( γ ^ i ∣ θ t ) = p ( θ t ∣ γ ^ i ) p ( γ ^ i ) p ( θ t ) p(\hat{\gamma}_i|\theta_t)=\frac{p(\theta_t|\hat{\gamma}_i)p(\hat{\gamma}_i)}{p(\theta_t)} p(γ^i∣θt)=p(θt)p(θt∣γ^i)p(γ^i)更新自己的信念。
为简化表述,设定包含产品质量和信息披露行为为模型2;为探究考虑产品质量和信息披露对利润的影响,文章将不考虑质量的情况作为benchmark,将考虑质量但是不考虑信息披露的情况作为模型1.
求解算法
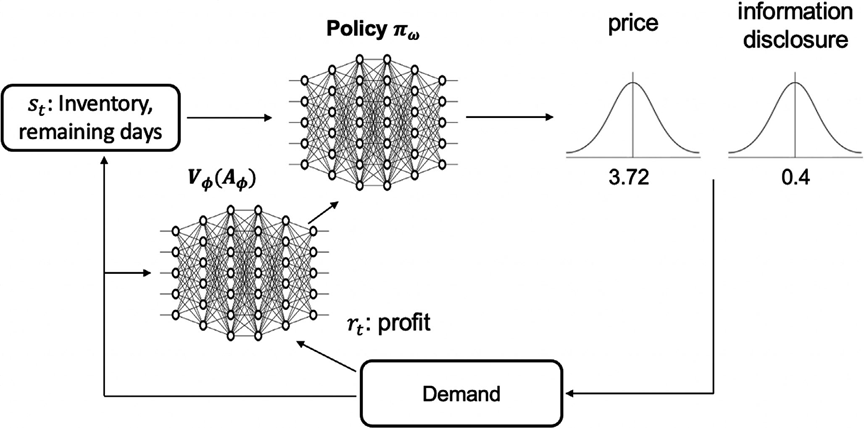
本文使用的算法是经典的PPO (Proximal Policy Optimization) 算法。在PPO算法由策略网络、评价网络两个DNN (Deep Neural Network) 组成,其中策略网络用于生成定价、信息披露的策略,评价网络用于评价生成策略的表现。PPO算法的流程图如下图所示。
首先从仿真模型得到当前状态 S t S_t St, 将 S t S_t St输入到策略网络中,得到策略 a t a_t at, 然后将 a t a_t at带回仿真模型进行迭代,得到收益 r t r_t rt和下一阶段状态 S t + 1 S_{t+1} St+1. 收集到足够多的数据 { S t , a t , r t , S t + 1 } \{S_t,a_t,r_t,S_{t+1}\} {St,at,rt,St+1}后,策略网络将会计算损失函数,并根据损失函数的梯度对策略网络和评价网络的参数进行更新。
PPO算法有两个主要特点。第一,在强化学习中,“探索”和“利用” (Exploration and Exploitation) 的平衡是一个重要的问题。为了平衡“探索”和“利用”,PPO算法的策略网络输出不是一个具体的价格和信息披露,而是价格和信息披露的正态分布,然后从两个分布中随机抽样得到具体的决策。第二,在PPO算法中,使用了重要性采样 (Importance Sampling) 以有效利用历史数据。(由于篇幅限制,这里不展开讲解PPO算法,感兴趣的同学可自行查阅相关资料。)
仿真结果
首先,设置销售周期 T = 12 T=12 T=12天,库存为 C = 500 C=500 C=500个单位,单位成本为 q = 3 q=3 q=3, 顾客到达率服从参数为 λ = 70 \lambda=70 λ=70的参数分布,设置真是的腐败率 γ = 0.1 \gamma=0.1 γ=0.1以及三种消费者认知的腐败率为 γ ^ 1 = 0.15 \hat{\gamma}_1=0.15 γ^1=0.15, γ ^ 2 = 0.1 \hat{\gamma}_2=0.1 γ^2=0.1, γ ^ 3 = 0.05 \hat{\gamma}_3=0.05 γ^3=0.05. 最后,设置三种市场情况:
- 三种消费者的比例分别为 [ 0.33 , 0.33 , 0.33 ] [0.33, 0.33, 0.33] [0.33,0.33,0.33]
- 三种消费者的比例分别为 [ 0.5 , 0.25 , 0.25 ] [0.5, 0.25, 0.25] [0.5,0.25,0.25]
- 三种消费者的比例分别为 [ 0.75 , 0.125 , 0.125 ] [0.75, 0.125, 0.125] [0.75,0.125,0.125]
从情况1到情况3,认为质量较低的消费者占比越来越高。
实施效果
我们主要通过利润以及残余库存两个指标去评价算法优劣,原文的表3和表4分别展示了三种模型在三种市场情况中的利润表现和残余库存表现。表3中,在三种市场中模型2的利润都显著高于模型1,模型1的利润也都高于基准模型。表4中,在三种市场中模型2的残余库存都显著低于模型1,模型1的残余库存也都显著低于基准模型。
结合两个指标综合分析,与基准模型相比,模型1以更低的价格实现了更大的利润,并且降低了期末的残余库存;与模型1相比,模型2实施了质量信息披露,这使得零售商可以定更高的价格(相对于模型1),同时实现了更大的需求。


策略比较
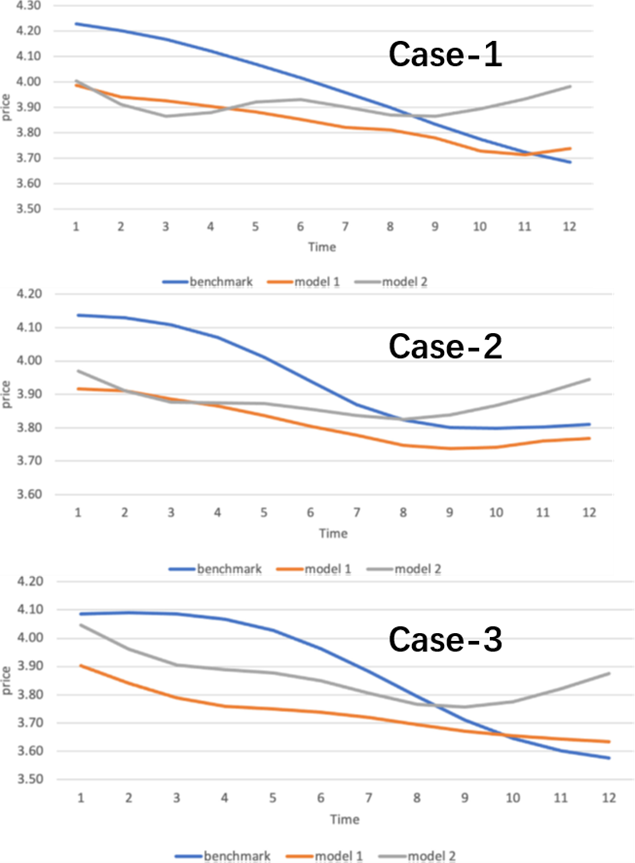
下面三幅图分别展示了三种模型在三种市场情况下的价格变化趋势,其中蓝线为基准模型,橙线为模型1,灰线为模型2。基准模型和模型1在三种市场中都是价格随着时间下降,但模型1的定价水平相对更低。模型2的定价策略是先降后升,再降再升,虽然有波动,整体价格更稳定,且期末的定价是三种模型中最高的,这主要是因为质量信息披露。
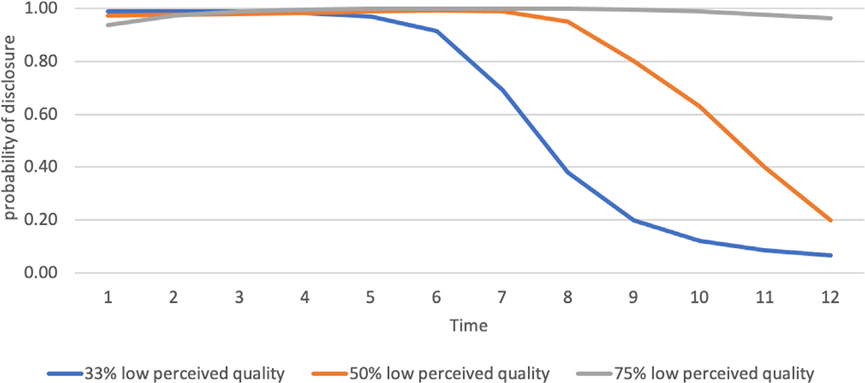
下图展示了模型2在三种市场情况的信息披露策略。在销售前期,由于产品质量高,所以进行信息披露;但在销售中后期,产品质量降低,进行信息披露的概率降低。此外,随着市场中认为产品低质量的顾客占比增大(从情况1到情况3),零售商越倾向于全程信息披露。
主要结论
1.基于质量的定价策略是三赢策略,提高了零售商利润,减少了社会浪费,并通过更低的价格,提升了消费者福利。
2.当市场中低估产品质量的消费者占比较大时,信息披露可以进一步提升利润,并降低残余库存。此外还有利于消费前期和后期的价格相对稳定。
3.当风险规避消费者占比较大/需求率较低时,基于质量的价格和信息披露联合决策能够产生最大的利润和最小的残余库存。
4.本文将强化学习与运营管理问题的结合是一种创新。
总体而言,本文为生鲜产品销售提供了一种新思路,并为相关行业提供了有益的参考。通过使用人工智能技术,销售商可以更好地了解消费者需求,并根据实际情况进行调整,从而提高销售效果和利润。同时,这种方法也有助于减少浪费和损失,促进可持续发展。
参考文献
Gallego, G., & Van Ryzin, G. (1994). Optimal dynamic pricing of inventories with stochastic demand over finite horizons. Management Science, 40(8), 999-1020.
这篇关于供应链 | POMS解读:新鲜农产品的动态定价与信息披露:一种人工智能方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



