本文主要是介绍大数据集处理策略 Bloom-Filter trie树,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大数据量处理是,除标题中提到的策略外,还有:
外排序。要点有:归并方法,置换选择 败者树原理,最优归并树
倒排索引。
快排序、堆排序等的变体版本。
数据库。
A trie 树
一、Trie的示意图
如图所示,该trie树存有abc、d、da、dda四个字符串,如果是字符串会在节点的尾部进行标记。没有后续字符的branch分支指向NULL
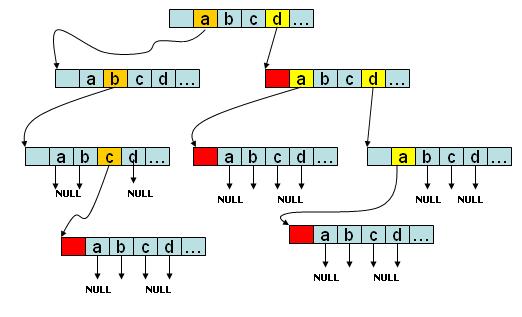
二、实例。
trie 树可采用双数组的方式实现。
例如:已知n个由小写字母构成的平均长度为10的单词,判断其中是否存在某个串为另一个串的前缀子串。下面对比方法:
2. 使用hash:我们用hash存下所有字符串的所有的前缀子串。建立存有子串hash的复杂度为O(n*len)。查询的复杂度为O(n)* O(1)= O(n)。
3. 使用trie:因为当查询如字符串abc是否为某个字符串的前缀时,显然以b,c,d....等不是以a开头的字符串就不用查找了。所以建立trie的复杂度为O(n*len),而建立+查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂度只是O(len)。
适用范围:数据量大,重复多,但是数据种类小可以放入内存
eg: 寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个,每个不超过255字节。
B 布隆过滤器
一、 Bloom-Filter的基本思想。
1.Bloom filter适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/E)*lge 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
扩展:
Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大大简单了。
三、 Bloom-Filter实例:
比如说,一个象 Yahoo,Hotmail 和 Gmai 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。
布隆过滤器是由巴顿.布隆于一九七零年提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。我们通过上面的例子来说明工作原理。
假定我们存储一亿个电子邮件地址,我们先建立一个十六亿二进制(比特),即两亿字节的向量,然后将这十六 亿个二进制位全部设置为零。对于每一个电子邮件地址 X,我们用八个不同的随机数产生器(F1,F2, ...,F8) 产生八个信息指纹(f1, f2, ..., f8)。再用一个随机数产生器 G 把这八个信息指纹映射到 1 到十六亿中的八个自然数 g1, g2, ...,g8。现在我们把这八个位置的二进制位全部设置为一。当我们对这一亿个 email 地址都进行这样的处理后。一个针对这些 email 地址的布隆过滤器就建成了。(见下图)
布隆过滤器决不会漏掉任何一个在黑名单中的可疑地址。但是,它有一条不足之处。也就是它有极小的可能将 一个不在黑名单中的电子邮件地址判定为在黑名单中,因为有可能某个好的邮件地址正巧对应八个都被设置成一的二进制位。好在这种可能性很小。我们把它称为误 识概率。在上面的例子中,误识概率在万分之一以下。
http://hi.baidu.com/cppcui/blog/item/36422bdd6dc169d78c10296d.html
http://blog.csdn.net/lyflower/article/details/5883458
这篇关于大数据集处理策略 Bloom-Filter trie树的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





