bloom专题

Flink实例(六十八):布隆过滤器(Bloom Filter)的原理和实现
什么情况下需要布隆过滤器? 先来看几个比较常见的例子 字处理软件中,需要检查一个英语单词是否拼写正确在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上在网络爬虫里,一个网址是否被访问过yahoo, gmail等邮箱垃圾邮件过滤功能 这几个例子有一个共同的特点: 如何判断一个元素是否存在一个集合中? 常规思路 数组链表树、平衡二叉树、TrieMap (红黑树)哈希表 虽然上面描述的

吃透Redis系列(四):布隆(bloom)过滤器详细介绍
Redis系列文章: 吃透Redis系列(一):Linux下Redis安装 吃透Redis系列(二):Redis六大数据类型详细用法 吃透Redis系列(三):Redis管道,发布/订阅,事物,过期时间 详细介绍 吃透Redis系列(四):布隆(bloom)过滤器详细介绍 吃透Redis系列(五):RDB和AOF持久化详细介绍 吃透Redis系列(六):主从复制详细介绍 吃透Redi
我与Bloom filter
1 海量网页判断用Bloom Filter 面试的时候,一个面试官问我说:“有一个网络爬虫,爬虫程序会不停地爬取页面上的每一个网页,并把爬取后的网页给存储起来,那么爬虫如何判定现在在爬的网页有没有被爬过。” 我当时卡住了半天回答不上来。 面试官给我说用Bloom Filter。 Bloom Filter把爬取过的网页映射到Bloom Filter内,如果再爬取到该网页,Bloom Filt

Spring Boot(七十四):集成Guava 库实现布隆过滤器(Bloom Filter)
之前在redis(17):什么是布隆过滤器?如何实现布隆过滤器?中介绍了布隆过滤器,以及原理,布隆过滤器有很多实现和优化,由 Google 开发著名的 Guava 库就提供了布隆过滤器(Bloom Filter)的实现。在基于 Maven 的 Java 项目中要使用 Guava 提供的布隆过滤器,只需要引入以下坐标 1 引入依赖 <dependency><groupId>com

【ROS1总结】使用bloom-generat打包ROS包生成debian安装包
> 说明:<br><br> > 本文首发于 Playfish Blog,转载请保留链接。 前言 在之前的博客中,介绍了ROS包的编写,在本节中将讲述如何将之前写的ROS包打包成debian安装包形式,打包成debian安装包形式有很多,例如: 将ros包开源至github,利用ros自动生成到构建仓库(buildform) 在本地将ros包打包成debian,不需要上传到github

UnityShader实例15:屏幕特效之Bloom
Bloom特效 概述 Bloom,又称“全屏泛光”,是游戏中常用的一种镜头效果,是一种比较廉价的“伪HDR”效果(如下右图);使用了Bloom效果后,画面的对比会得到增强,亮的地方曝光也会得到加强,画面也会呈现一种朦胧,梦幻的效果,婚纱摄影中照片处理经常用到这种类似处理效果。Bloom效果一般用来近似模拟HDR效果,效果也比较相向,但实现原理却
Bloom Filter的关键公式
Bloom Filter有以下参数: m m bit数组的宽度(bit数)nn 加入其中的key的数量 k k 使用的hash函数的个数ff False Positive的比率 (1−(1−1m)kn)k≈(1−e−knm)k (1-(1-{{1}\over{m}})^{kn})^k\approx(1-e^{-{{kn}\over{m}}})^k 给

布隆过滤器(Bloom Filter)基础知识
布隆过滤器(Bloom Filter)基础知识 布隆过滤器 (Bloom Filter)是由Burton Howard Bloom于1970年提出,它是一种space efficient的概率型数据结构,用于判断一个元素是否在集合中。在网页黑名单系统、垃圾邮件过滤的黑白名单方法、爬虫(Crawler)的网址判重模块中等等经常被用到。哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希

查询利器-bloom-filter详解
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。本文着重于在实现Bloom Filter的时候会使用到的一些技巧。 布隆过滤器的原理不难理解。相对于一个精简的HashMap的数据结构,存入数据的
大数据_HBase_HBase 中的 bloom-filter
参考文章: 1.详解布隆过滤器的原理、使用场景和注意事项 https://www.jianshu.com/p/2104d11ee0a2 2.数学之美:布隆过滤器 https://zhuanlan.zhihu.com/p/72378274 什么是布隆过滤器 本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点

一个用于白名单服务的布隆过滤器(bloom filter)
bloom filter这种数据结构用于判断一个元素是否在集合内,当然,这种功能也可以由HashMap来实现。bloom filter与HashMap的区别在于,HashMap会储存代表这个元素的key自身(如key为"IKnow7",那么HashMap将存储"IKnow7"这12个字节(java),其实还需要包括引用大小,但java中相同string只存一份),而b
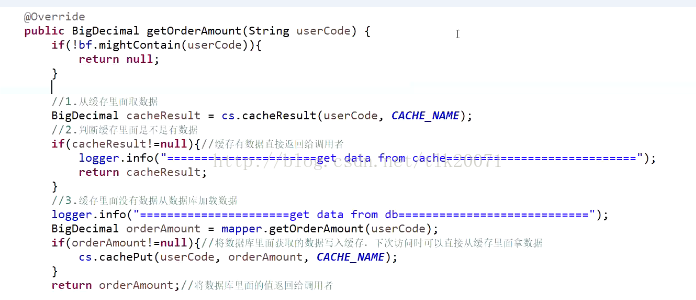
布隆过滤器(Bloom Filter)原理以及应用
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。 hash原理 Hash (哈希,或者散列)函数在计算机领域,尤其是数据快速查找领域,加密领域用的极广。 其作用是将一个大的数据集映

位图与Bloom过滤器
位图 位图常用在给定一个很大范围的数,判断某个数是否在其中。BitSet是位操作的对象,值只有0或1(即true 和 false),内部维护一个long数组,初始化只有一个long segement,所以BitSet最小的size是64;随着存储的元素越来越多,BitSet内部会自动扩充,一次扩充64位,最终内部是由N个long segement 来存储。默认情况下,BitSet所有位都是0

谈谈Bloom Filter
海量数据的过滤及去重,老生常谈的话题了。Bitmap和Bloom Filter是常见的解决办法。 Bitmap的思路很单纯,一条数据是否存在只需要一个Bit就可以表示,因此一个Byte可以表示8条数据的布尔值,一般Bitmap用来解决某个数字是否存在,这个数字就是Index。在JDK中的实现为BitSet,底层实现为long数组。Bitmap不做过多介绍,原理实现比较通俗易懂。 Bitmap对
原译:使用Bloom Filters
仙子注:这篇文章是半年前翻译的,最早贴于公司内部的BBS上,并引起一些争论。Bloom Filters是一种效率较高的内存索引算法,它本身具有矛盾性:一方面能快速测试目标成员是否存在,另一方面又不可避免的具有假命中率。如下文档仅供参考。 由于不知道如何在这里粘贴图片,因此本文中没有包含图片说明,请对照原文档来阅读,原文档在:http://www.perl.com/pub/a/2004/04/08/
用TensorRT-LLM跑通BLOOM模型
零、参考资料 NVIDIA官方 Github链接 一、构建 TensorRT-LLM的docker镜像 git lfs installgit clone https://github.com/NVIDIA/TensorRT-LLM.gitcd TensorRT-LLMgit submodule update --init --recursivemake -C docker rele

『 C++ - STL 』位图(BitMap)与布隆过滤器(Bloom Filter)
文章目录 🧸 位图(BitMap)概念🧸 位图的实现🪅 总体框架🪅 位图的数据插入🧩 左移操作与右移操作的区别 🪅 位图的数据删除🪅 位图的数据查找🪅 位图整体代码(供参考) 🧸 布隆过滤器(Bloom Filter)概念🪅 哈希函数的个数及布隆过滤器的长度 🧸 布隆过滤器的实现🪅 总体框架🪅 布隆过滤器的数据插入🪅 布隆过滤器的数据查找🪅 布隆过滤器的数据删除

大数据集处理策略 Bloom-Filter trie树
大数据量处理是,除标题中提到的策略外,还有: 外排序。要点有:归并方法,置换选择 败者树原理,最优归并树 倒排索引。 快排序、堆排序等的变体版本。 数据库。 A trie 树 一、Trie的示意图 如图所示,该trie树存有abc、d、da、dda四个字符串,如果是字符串会在节点的尾部进行标记。没有后续字符的branch分支指向NULL 二、实例。 trie 树可采用双数组的方式实

redis布隆过滤器(Bloom)详细使用教程
文章目录 布隆过滤器1. 原理2. 结构和操作3. 特点和应用场景4. 缺点和注意事项 应用-redis插件布隆过滤器使用详细过程安装以及配置springboot项目使用redis布隆过滤器下面是布隆过滤器的一些基础命令 扩展 布隆过滤器 Bloom 过滤器是一种概率型数据结构,用于快速判断一个元素是否属于一个集合。它以较小的空间占用和高效的查询时间著称。下面将对 Bloom

Bloom Filters Count-Min Sketch
今日看了两个基于概率的数据结构(Probabilistic data structures) Bloom Filters 和 Count-Min Sketch,基本思想相类似。 其实是两个实现简单的算法,但是需要用到一定的数学原理。 但本文仅介绍方法,不介绍数学原理。 Bloom Filters 问给出的数是否在集合 S S S 中,集合可增可删,且集合中数的取值范围 w w w 较大
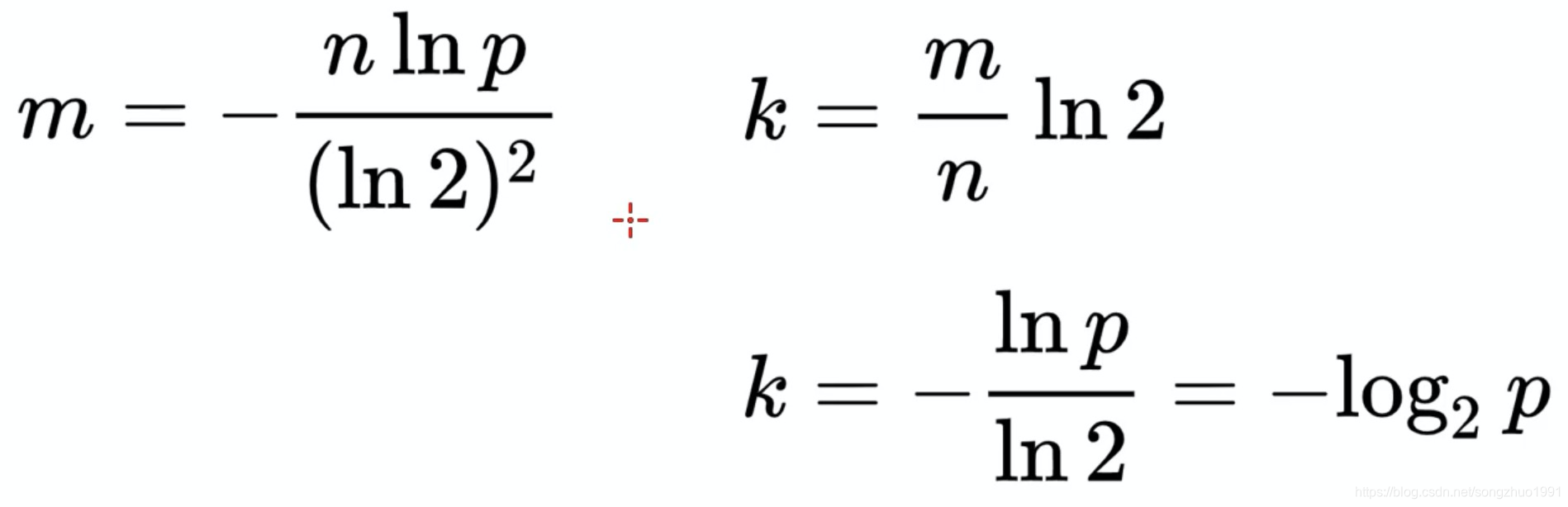
数据结构 - 布隆过滤器(Bloom Filter)
思考 如果要经常判断1个元素是否存在,你会怎么做? 很容易想到使用哈希表(HashSet、HashMap),将元素作为key去查找 时间复杂度:O(1),但是空间利用率不高,需要占用比较多的内存资源如果需要编写一个网络爬虫去爬10亿个网站数据,为了避免爬到重复的网站,如何判断某个网站是否爬过? 很显然,HashSet、HashMap并不是非常好的选择是否存在时间复杂度低、占用内存较少的方案?布隆

海外抖音TikTok、正在内测 AI 生成歌曲功能,依靠大语言模型 Bloom 进行文本生成歌曲
近日,据外媒The Verge报道,TikTok正在测试一项新功能,利用大语言模型Bloom的AI能力,允许用户上传歌词文本,并使用AI为其添加声音。这一创新旨在为用户提供更多创作音乐的工具和选项。 Bloom 是由AI初创公司Hugging Face在法国政府的资助下发起的项目,数百名研究人员合作开发和发布的1760亿参数语言模型,被认为是一个强大的人工智能技术。它是在一个称为 ROOTS

【Unity3D】Bloom特效
1 Bloom 特效原理 Bloom 特效是指:将画面中较亮的区域向外扩散,造成一种朦脓的效果。实现 Bloom 特效,一般要经过 3 个阶段处理:亮区域检测、高斯模糊、Bloom 合成。 本文完整资源见→Unity3D Bloom 特效。 1)亮区域检测 根据亮度阈值检测亮区,如下从原图中提取亮区域。 原图

redis安装bloom过滤器
首先卸载原本的redis 在下图目录位置创建文件夹用来存放bloom和redis的config文件 /usr/local/software/redis/6379 [root@localhost redis]# cd 6379[root@localhost 6379]# mkdir conf[root@localhost 6379]# mkdir data 上传redis.co
Unity 实现部分物体Bloom效果
之前研究了一下怎么让屏幕里部分东西显示bloom效果,例如只是特效显示bloom效果而角色不显示,现在记录一下 我这里加了效果图和工程下载地址,方便大家了解 PS:这个性能有问题,建议看看这边博客,用存储alpha来替换重新渲染一遍带来的性能问题 https://blog.csdn.net/SnoopyNa2Co3/article/details/88075047 扩展:可以修改替换