本文主要是介绍自然语言处理(NLP)——使用Rasa创建聊天机器人,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 基本概念
1.1 自然语言处理的分类
IR-BOT:检索型问答系统
Task-bot:任务型对话系统
Chitchat-bot:闲聊系统
1.2 任务型对话Task-Bot:task-oriented bot
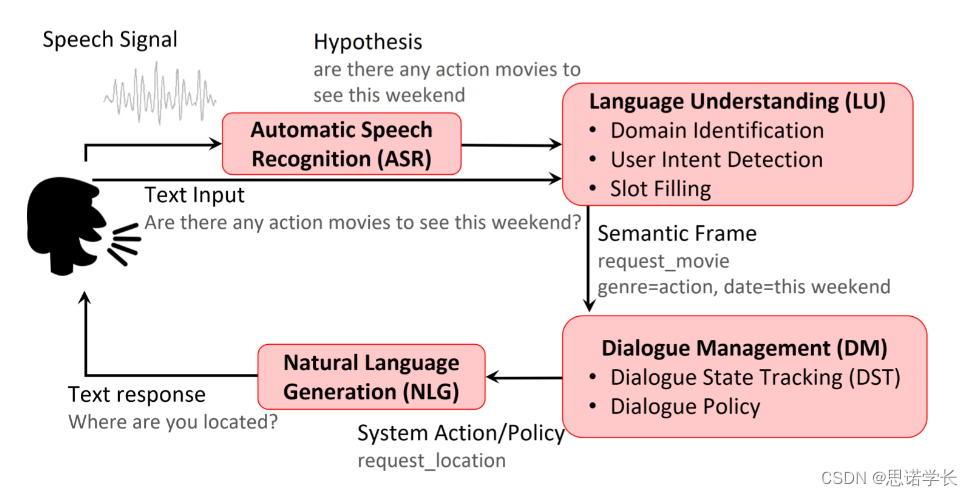
这张图展示了一个语音对话系统(或聊天机器人)的基本组成部分和它们之间的工作流程。这个系统可以接受语音信号作为输入,输出文本响应,并且它包括以下几个主要部分:
1.2.1 自动语音识别(ASR)
这个部分的任务是将用户的语音信号转换成文本。在这个例子中,ASR将语音信号识别为文本输入“Are there any action movies to see this weekend?”
1.2.2 语言理解(SLU)
一旦语音转换为文本,语言理解部分就开始工作,包括三个子任务:
领域识别(Domain Identification):确定用户的请求属于哪一个领域或类别,例如电影、音乐或天气等。
用户意图检测(User Intent Detection):识别用户的目的或意图,例如询问电影信息、预订餐厅等。
槽位填充(Slot Filling):从用户的话中提取具体信息,如电影类型、日期、时间等。
1.2.3 语义框架(Semantic Frame)
这是语言理解的结果,它结构化地表达了用户的请求,包括动作(如请求电影)、属性(如类型是动作片)和时间(如这个周末)。
1.2.4 对话管理(DM)
对话管理组件控制对话的流程,并决定如何响应用户的输入。它包括两个部分:
对话状态跟踪(DST):保持对话的当前状态,追踪对话历史和用户提供的信息。
对话策略(Dialogue Policy):基于对话的当前状态和过去的交互,决定下一步的最佳动作。
1.2.5 自然语言生成(NLG)
这个部分根据对话管理系统的输出生成自然语言文本。例如,如果系统需要知道用户的位置,NLG会生成问题“Where are you located?”
这张图通过展示从语音输入到文本响应的完整流程,概述了一个典型的语音对话系统的工作方式。这种系统可以用于各种应用,如虚拟助手、客服聊天机器人等。
1.2.6 SLU的深入学习
1.2.6.1 SLU的结构
结构化表示自然语言的语言:act-slot-value tuples
act1(slot1=value1,slot2=value2,...).act2(slot1=value1,......),....
accttype ,slot,value的取值范围已预先定义好
”您好韩小姐,麻烦提供下手机号哦“——>request(phone,name=韩小姐)
1.2.6.2 实现SLU的技术
1.2.6.2.1 语法分析
通过语法以及语法结构分析出客户意图与槽值。
1.2.6.2.2 Semantic tagging eg. HMM,CRF
给句子进行手动标柱槽值,进行机器学习训练
1.2.6.2.3 分类的思想
使用多个分类器,对句子内容进行分类
1.2.6.2.4 深度学习
建立神经网络,蛋速度慢
1.2.7 DST的深入学习
对话状态应该包含持续对话所需要的各种信息
DST问题:依据最新的系统和动作,更新对话状态
1.2.8 DPO的深入学习
系统如何做出反馈动作
作为序列决策过程进行优化:增强学习
1.2.9 自然语言生成NLG的深入学习
基于模版:已经为您预定{time}的电影(movie_name)
基于语法规则
生成模型方法
1.2.10 其他类型的Task-Bot
Microsoft:End-to-End Task-Completion Neural Dialogue Systems

2 Rasa的学习
本节介绍如何在Rasa框架下创建聊天机器人。目的是让学生发现和学习如何使用Rasa包在Python环境下创建聊天机器人。
2.1 安装与初始化一个MoodBot
实验室中提到的安装Rasa的命令是:
python3 -m pip install rasa --user
安装完成后,可以通过下面的命令创建一个基于Rasa的MoodBot示例项目:
rasa init
需要基本的命令帮助(例如训练、测试、运行机器人等),可以直接输入rasa命令或者参考它的在线文档:[Rasa文档](https://rasa.com/docs/rasa/)。
特别是关于NLU训练、域(domains)、配置和动作(actions)的概念部分,这些都是学习如何根据自己的需求定制聊天机器人的有用资源。
2.2 文件分析
在你的`rasa'目录下的文件夹中,有三个主要的文件:
2.2.1 credentials.yml
credentials.yml:这个文件包含访问各种社交网络来测试聊天机器人的密钥。这些社交网络可能包括Facebook Messenger、Slack等,通过这些密钥,你的聊天机器人可以接入并在这些平台上进行交互。
# This file contains the credentials for the voice & chat platforms
# which your bot is using.
# https://rasa.com/docs/rasa/messaging-and-voice-channelsrest:
# # you don't need to provide anything here - this channel doesn't
# # require any credentials#facebook:
# verify: "<verify>"
# secret: "<your secret>"
# page-access-token: "<your page access token>"#slack:
# slack_token: "<your slack token>"
# slack_channel: "<the slack channel>"
# slack_signing_secret: "<your slack signing secret>"#socketio:
# user_message_evt: <event name for user message>
# bot_message_evt: <event name for bot messages>
# session_persistence: <true/false>#mattermost:
# url: "https://<mattermost instance>/api/v4"
# token: "<bot token>"
# webhook_url: "<callback URL>"# This entry is needed if you are using Rasa Enterprise. The entry represents credentials
# for the Rasa Enterprise "channel", i.e. Talk to your bot and Share with guest testers.
rasa:url: "http://localhost:5002/api"
Rasa聊天机器人的credentials.yml配置文件,该文件用于设置不同通讯平台的认证信息。Rasa可以通过这些信息与各种社交媒体和消息传递平台进行交互,比如REST API、Facebook Messenger、Slack、Socket.IO、Mattermost等。这里列出了几个平台的配置示例
下面是每个部分的作用:
rest: 这是一个简单的REST API,不需要特别的认证信息,您的机器人可以通过HTTP请求接收和发送消息。
facebook: 如果您想通过Facebook Messenger使您的机器人能够交流,您需要填写验证令牌、秘密密钥和页面访问令牌。
slack: 对于Slack集成,您需要提供Slack令牌、频道和签名秘密。
socketio: 如果您使用的是Socket.IO,您需要定义用户消息和机器人消息的事件名称,以及是否持久化会话。
mattermost: 类似于Slack,如果您使用Mattermost,您需要提供Mattermost实例的URL、机器人令牌和回调URL。
最后,如果您使用的是Rasa企业版,您还需要配置Rasa通道,这样您的机器人就可以与Rasa企业版的API进行通信。
要激活这些通道,您需要取消注释相关部分,并填写相应的认证信息。请确保在实际部署机器人时,不要将敏感的认证信息泄露到公共代码仓库或不安全的地方。在本地测试时,可以使用默认的`http://localhost:5002/api`路径作为Rasa企业通道的URL。
2.2.2 config.yml
这个配置文件是用于配置和训练一个Rasa聊天机器人的。Rasa是一个开源的机器学习框架,用于构建对话式AI和聊天机器人。这个文件包括几个主要部分:
# The config recipe.
# https://rasa.com/docs/rasa/model-configuration/
recipe: default.v1# The assistant project unique identifier
# This default value must be replaced with a unique assistant name within your deployment
assistant_id: 20240207-103316-skinny-actuary# Configuration for Rasa NLU.
# https://rasa.com/docs/rasa/nlu/components/
language: enpipeline: null
# # No configuration for the NLU pipeline was provided. The following default pipeline was used to train your model.
# # If you'd like to customize it, uncomment and adjust the pipeline.
# # See https://rasa.com/docs/rasa/tuning-your-model for more information.
# - name: WhitespaceTokenizer
# - name: RegexFeaturizer
# - name: LexicalSyntacticFeaturizer
# - name: CountVectorsFeaturizer
# - name: CountVectorsFeaturizer
# analyzer: char_wb
# min_ngram: 1
# max_ngram: 4
# - name: DIETClassifier
# epochs: 100
# constrain_similarities: true
# - name: EntitySynonymMapper
# - name: ResponseSelector
# epochs: 100
# constrain_similarities: true
# - name: FallbackClassifier
# threshold: 0.3
# ambiguity_threshold: 0.1# Configuration for Rasa Core.
# https://rasa.com/docs/rasa/core/policies/
policies: null
# # No configuration for policies was provided. The following default policies were used to train your model.
# # If you'd like to customize them, uncomment and adjust the policies.
# # See https://rasa.com/docs/rasa/policies for more information.
# - name: MemoizationPolicy
# - name: RulePolicy
# - name: UnexpecTEDIntentPolicy
# max_history: 5
# epochs: 100
# - name: TEDPolicy
# max_history: 5
# epochs: 100
# constrain_similarities: true
recipe: default.v1:这指定了Rasa使用的训练配方。`default.v1`是Rasa提供的默认配方。
assistant_id:20240207-103316-skinny-actuary - 这是聊天机器人项目的唯一标识符。在部署中,这个默认值需要替换为一个独一无二的助手名称。
language: en:这指定了机器人用于理解和生成语言的语言代码。这里的`en`代表英语。
pipeline:这部分用于配置Rasa NLU(自然语言理解)的处理流水线。这里没有提供具体配置,而是使用了Rasa的默认流水线。如果你想自定义流水线,可以取消注释并调整下面的配置。这个流水线包括文本的分词、特征提取、意图识别和实体抽取等步骤。
policies:这部分用于配置Rasa Core的决策策略,这些策略决定了机器人如何根据用户的输入选择回应。同样,这里没有提供具体配置,而是使用了默认的策略。如果你想自定义策略,可以取消注释并调整下面的配置。这些策略包括对话管理的规则、意图预测的模型等。
总之,这个配置文件为Rasa聊天机器人的训练提供了基础的设置,包括使用的语言、处理流水线和对话策略。你可以根据需要修改这个文件来定制你的聊天机器人。
2.2.3 domain.yml
domain.yml 文件是 Rasa 项目中的一个重要文件,包含了聊天机器人的所有关键数据。其中包括意图(intents)、动作(actions)、动作的响应(responses to actions),以及在比 Moodbot 更复杂的其他机器人中可能还包括插槽(slots)和模板(templates)等内容。
2.2.3.1 意图(Intents)
意图代表用户消息背后的意图或目标。例如,如果用户请求帮助,相应的意图可能是 `help`。
2.2.3.2 动作(Actions)
动作是机器人的响应或行为。这可以包括发送消息、执行操作或查询外部API等。
2.2.3.3 动作的响应(Responses to Actions)
这些是机器人在执行动作后将发送给用户的消息或响应。它们可以是简单的文本消息,也可以是涉及自定义模板等更复杂的响应。
2.2.3.4 插槽(Slots)
插槽是机器人需要从用户那里收集的信息片段,以完成任务。例如,如果机器人正在帮助用户预订航班,它可能需要插槽来存储出发城市、目的地城市和出行日期等信息。
2.2.3.5 模板(Templates)
模板是预定义的响应,机器人可以使用它们来生成消息。这些可以包括用于动态内容(如插槽值或从用户消息中提取的实体)的占位符。
domain.yml文件充当了组织和管理机器人功能的中心枢纽。它有助于定义机器人的行为并指导其与用户的交互。
2.2.4 data/nlu.yml
在这个文件夹里我们找到了与所有意图相对应的句子,例如
version: "3.1"nlu:
- intent: greetexamples: |- hey- hello- hi- hello there- good morning- good evening- moin- hey there- let's go- hey dude- goodmorning- goodevening- good afternoon- intent: goodbyeexamples: |- cu- good by- cee you later- good night- bye- goodbye- have a nice day- see you around- bye bye- see you later- intent: affirmexamples: |- yes- y- indeed- of course- that sounds good- correct- intent: denyexamples: |- no- n- never- I don't think so- don't like that- no way- not really- intent: mood_greatexamples: |- perfect- great- amazing- feeling like a king- wonderful- I am feeling very good- I am great- I am amazing- I am going to save the world- super stoked- extremely good- so so perfect- so good- so perfect- intent: mood_unhappyexamples: |- my day was horrible- I am sad- I don't feel very well- I am disappointed- super sad- I'm so sad- sad- very sad- unhappy- not good- not very good- extremly sad- so saad- so sad- intent: bot_challengeexamples: |- are you a bot?- are you a human?- am I talking to a bot?- am I talking to a human?- intent: GetInfo_winlossRecordexamples: |- I need to know the record of [Manchester City](team).- I'm wondering what record right now does [West Ham](team) have?- How is [Watford](team) doing?- What is [AFC Bournemouth](team) record right now?- I am looking for information about the soccer team called[Burnley](team).- I want to know the record of [Aston Villa](team).
举例说明:
nlu:
- intent: greetexamples: |- hey- hello- hi- hello there- good morning- good evening- moin- hey there- let's go- hey dude- goodmorning- goodevening- good afternoon这段代码是一个Rasa NLU(Natural Language Understanding)的配置文件,用于定义意图(intent)以及它们的示例(examples)。这个配置文件中定义了一个名为"greet"的意图,该意图用于识别用户打招呼的消息。示例中包括了一些常见的打招呼方式,比如"hey"、"hello"、"hi"等等。
- intent: GetInfo_winlossRecordexamples: |- I need to know the record of [Manchester City](team).- I'm wondering what record right now does [West Ham](team) have?- How is [Watford](team) doing?- What is [AFC Bournemouth](team) record right now?- I am looking for information about the soccer team called[Burnley](team).- I want to know the record of [Aston Villa](team).这段代码定义了一个名为"GetInfo_winlossRecord"的意图,用于识别用户想要获取足球球队战绩信息的消息。示例中包括了一些询问特定足球球队战绩的例子,每个例子都包含了一个"team"实体,用于指定感兴趣的球队名称。
2.2.5 data/stories.yml
这是 rasa 最具创新性的部分:您可以给出可能发生的讨论场景,而不是定义一个讨论有限状态自动机。用多个讨论发生的场景来代替有限状态机。例如:
version: "3.1"stories:- story: happy pathsteps:- intent: greet- action: utter_greet- intent: mood_great- action: utter_happy- story: sad path 1steps:- intent: greet- action: utter_greet- intent: mood_unhappy- action: utter_cheer_up- action: utter_did_that_help- intent: affirm- action: utter_happy- story: sad path 2steps:- intent: greet- action: utter_greet- intent: mood_unhappy- action: utter_cheer_up- action: utter_did_that_help- intent: deny- action: utter_goodbye- story: GetInfo winlossRecordsteps:- intent: GetInfo_winlossRecord- action: action_winlossRecord举例说明:
- story: happy pathsteps:- intent: greet- action: utter_greet- intent: mood_great- action: utter_happy这段代码定义了一个名为"happy path"的故事,描述了用户的一种顺利的对话路径。故事包括了以下步骤:
a.用户发送了一个打招呼的意图(greet)。
b.系统执行了一个回复动作(action),输出了一个问候语(utter_greet)。
c.用户表达了愉快的心情(mood_great)。
d.系统再次执行了一个回复动作,输出了一个愉快的回复(utter_happy)。
这个故事描述了一种典型的对话流程,用户首先打招呼,然后表达了愉快的心情,系统随后作出了相应的回应。
我们可以看到被识别的意图,然后是行动。我们进入了一个循环:识别意图、行动、用户反应、再一次意图,如此循环。
2.3 训练与测试
rasa trainrasa shell2.4 闲聊与问答(Chitchat and FAQs)
3. Rasa chatbot多人开发项目
3.1 项目要求
3.1.1 总体要求
a. 使用Rasa开源框架:
- 建议(但不强制)使用Rasa框架来开发聊天机器人。
b. 超越Rasa默认功能
- 应用在学习过程中了解到的技术和原则。
- 至少采用一种基于知识的技术,如本体论、逻辑推理、词网、同义词等。
- 至少采用一种基于学习的技术,如频率方法、统计机器学习、深度学习等。
- 至少采用一种基于语法的技术,如句法分析、正则表达式、词形还原、形态分析等。
3.1.2 5人分工示例
- 一个人负责整体Rasa流水线的设置、组件集成和测试;
- 一个人负责对话逻辑、意图、自然语言理解(NLU)、故事等的设计和实现;
- 一个人负责基于知识的组件的设计和实现;
- 一个人负责基于学习的组件的设计和实现;
- 一个人负责基于语法的组件的设计和实现。
3.1.3 对于知识、学习、语法组件的理解
在您的聊天机器人项目中,团队成员将根据不同的技术专长分工。这里提到的“基于知识的组件”、“基于学习的组件”和“基于语法的组件”分别指的是:
3.1.3.1 基于知识的组件(Knowledge-based Component)
这指的是利用预先定义的知识体系(如本体论、逻辑推理结构、词网、同义词数据库等)来增强聊天机器人的理解和响应能力。设计和实现这样的组件涉及到构建一个知识库或使用现有的知识库,使得聊天机器人可以参照这些知识来理解用户的意图和提供信息。
在Rasa中,你可以通过自定义actions和slots来实现基于知识的组件。自定义actions允许你编写Python代码来访问外部知识库或服务,比如图数据库、SQL数据库或者其他API,从而在对话中使用这些知识。
可以使用Rasa的Entity Extraction来识别对话中的关键信息,并用这些信息查询知识库,从而提供有针对性的回答。
通过这种方式,你的聊天机器人可以使用逻辑推理和结构化的知识(如本体论)来处理用户的询问。
3.1.3.2 基于学习的组件(Learning-based Component)
这涉及到使用机器学习方法来使聊天机器人从数据中学习。这可能包括频率方法、统计学习模型或深度学习模型。这样的组件可能负责识别用户意图、文本分类、情感分析等,通常需要大量的数据来训练模型。
Rasa使用机器学习来训练模型,理解用户的意图(intent recognition)和提取实体(entity extraction)。
它支持多种类型的机器学习模型,包括预先训练好的模型和你可以自定义训练的模型。这些模型用于处理自然语言理解(NLU)和对话管理(Dialogue Management)。
Rasa允许使用自定义的机器学习管道和策略,你可以在这里加入深度学习或其他统计机器学习算法。
3.1.3.3 基于语法的组件(Grammar-based Component)
这指的是使用语言学的方法来解析和生成语言。这可能涉及句法分析(分析句子结构)、使用正则表达式(用于模式匹配)、词形还原(将词汇还原为基本形式)、形态分析(分析词汇的形态结构)等技术。这样的组件用于提升聊天机器人处理语言的精确性。
每个组件都有其在聊天机器人中的独特作用,三者合作能够使得机器人更加智能和高效。例如,基于知识的组件可以提供准确的专业信息,基于学习的组件可以从用户对话中学习并提高对话质量,而基于语法的组件可以确保语言的正确性和流畅性。
项目要求强调了除了技术实现之外,设计理念的重要性。你的聊天机器人需要基于理论知识构建,同时还需要注意合规性和道德问题。在项目过程中,团队成员之间的协作和分工也是非常重要的。
虽然Rasa主要侧重于机器学习方法,但你仍然可以使用正则表达式和其他语法分析技术来改善对话流程。
例如,可以在NLU组件中使用RegexFeaturizer来改善实体识别的性能,或者用于识别和验证特定的数据格式(如日期和时间)。
对于词形还原和形态分析,可以在数据预处理阶段或通过自定义组件来实现。这可能需要与其他工具或库集成,比如Spacy或NLTK。
通过结合这些技术,你可以创建一个更加强大和灵活的聊天机器人,能够理解和回应用户的需求。记住,在设计和实现这些组件时,确保它们符合你的项目需求和规定的聊天机器人的应用领域。
3.2 有益的建议
对于使用Rasa框架进行聊天机器人项目,以下是一些有益的建议:
3.2.1 使用规则或故事指导对话流程
规则(Rules): 它们是硬性的限制,可以保证聊天机器人的行为是确定的。当你需要确保在某些情况下机器人始终给出特定的响应时,使用规则。
故事(Stories): 它们通过机器学习的方式来约束聊天机器人的行为,具有概率性。故事是对话的样本路径,通过这些样本路径,Rasa的机器学习模型可以学习在不同情况下采取的行动。
3.2.2 使用表单进行槽位填充
使用Rasa的表单(Forms)功能,可以更有效地从用户那里逐步收集数据。当你需要多个信息片段才能执行任务或响应时,表单可以确保机器人不遗漏任何必要的信息。
3.2.3 更改默认管道
考虑使用更强大的NLP管道,比如SpacyNLP,它使用词向量来理解语言,这可以提高实体识别和意图分类的准确性。
3.2.4 使用同义词和词形还原处理变化
同义词可以帮助机器人理解不同的词汇表示相同的概念(如“aubergine”和“eggplant”)。
词形还原能够将单词变回其基础形式(比如将复数“apples”还原为单数“apple”),从而简化处理流程并增加机器人理解不同语言形式的能力。
在项目开发过程中,这些技巧可以帮助你更好地设计对话流程,提高聊天机器人的性能,并处理自然语言的复杂性。同时,始终记得定期测试你的机器人,并根据反馈不断迭代改进。
3.3 代码成果
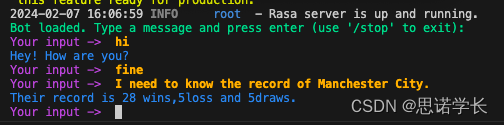
通过API获取足球球队在某赛季的比赛成绩。
这篇关于自然语言处理(NLP)——使用Rasa创建聊天机器人的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





