本文主要是介绍支持向量回归_基于支持向量回归的区域化流量历时曲线分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


题目:
Regional Analysis of Flow Duration Curves through Support Vector Regression
作者:
Mehdi Vafakhah1, Saeid Khosrobeigi1
单位:
Watershed Management Engineering, Faculty of Natural Resources, Tarbiat Modares University, Noor 46417-76489, Iran
刊物/年份:
Water Resources Management / 2019
文案:史虹键
排版:史虹键
校核:丁光旭
基于支持向量回归的区域化流量历时曲线分析

研究背景
流量历时曲线(FDC)显示了特定时间段内日流量大小和频率之间的关系,被广泛应用于水资源管理。然而世界上大量的流域都缺少观测资料,这种情况导致需要使用区域化方法来估计未测量河流流域的FDC。人工智能方法作为资料较少流域FDC预测的有效技术被广泛应用,目前还没有研究使用SVR(支持向量回归)进行区域化FDC分析。因此,有必要对SVR在这一领域的能力进行评估。
研究目的
文章的研究主要有两个目的:
a .利用SVR(支持向量回归)、ANN(人工神经网络)和NLR(非线性回归)方法建立区域化FDC模型;
b .比较这些方法对于区域化FDC分析的性能。
研究方法
研究选取伊朗中部纳马克湖流域的33个站点,主要数据是从伊朗水资源管理公司获得的逐日流量数据,所选河流没有明显的人为干扰(图1)。
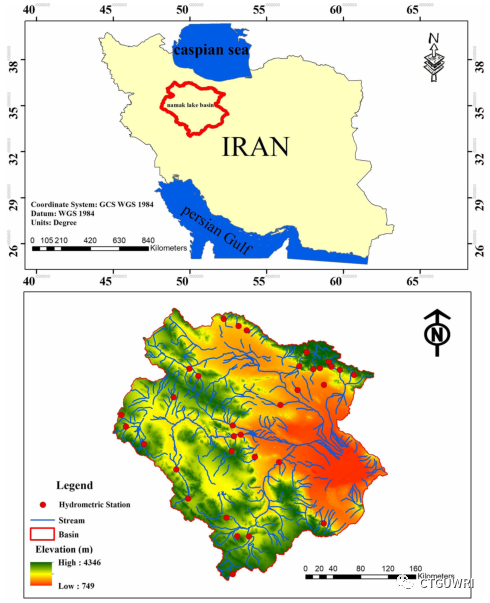
图1、研究地区
研究方法可以简单概括为如下4步:
(1)计算每个站点的年FDC;
(2)将每年的逐日流量升序排列,绘制每个有序观测值与其相应的超过概率的对比图;
(3)按照相对历时百分比将数据划分为5组,分别为Q2/Q10/Q20/Q50/Q90,例如90代表相对历时百分比为90%;
(4)建立SVR,ANN,NLR模型,比较对于区域化FDC分析的性能。
主要研究结果
表1 、NLR模型测试集和验证集的 对比结果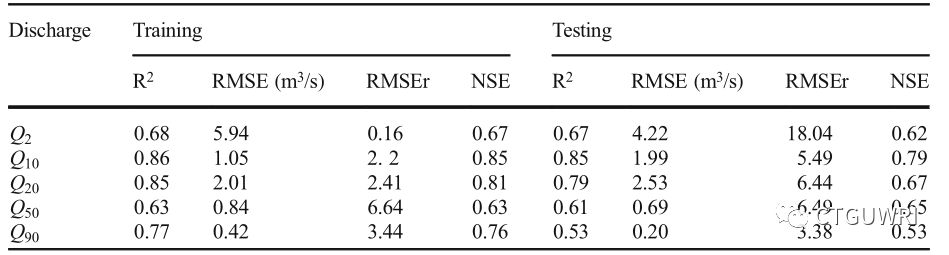
表2、ANN模型测试集和验证集的对比结果
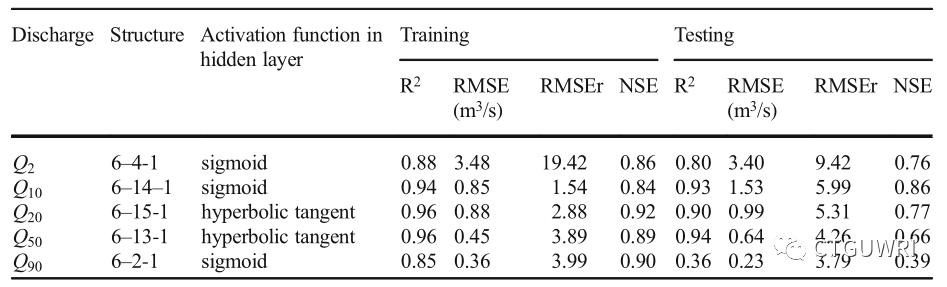
表3、SVR模型测试集和验证集的对比结果
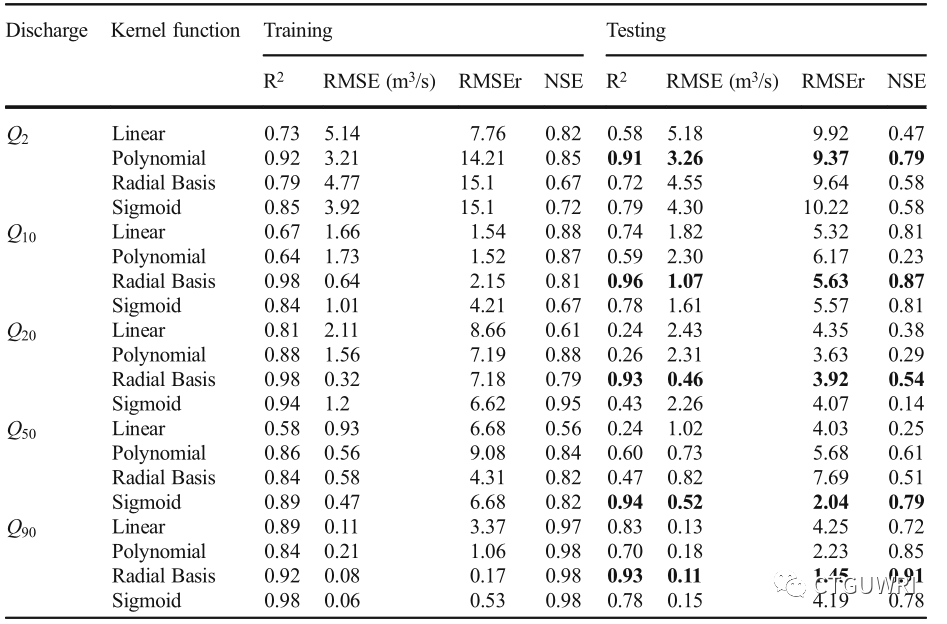
如表1、2、3所示,在5组数据中,在R2值方面SVR模型相较于ANN和NLR具有更好的结果;另一方面,除Q20(NSE=0.54)之外,SVR模型的NSE值均在0.75 - 0.85之间 ,SVR总体质量高于ANN模型;NLR模型的NSE值明显低于SVR和ANN模型;SVR模型在所有分组中性能表现均较好,并且RBF(Radial Basis)核函数更能反映实际情况。
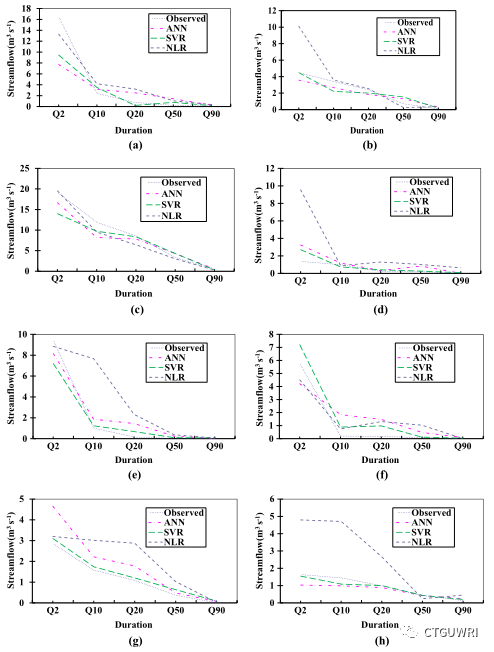
图2、NLR,ANN和SVR在测试期内为8所水文站提供的区域化FDC
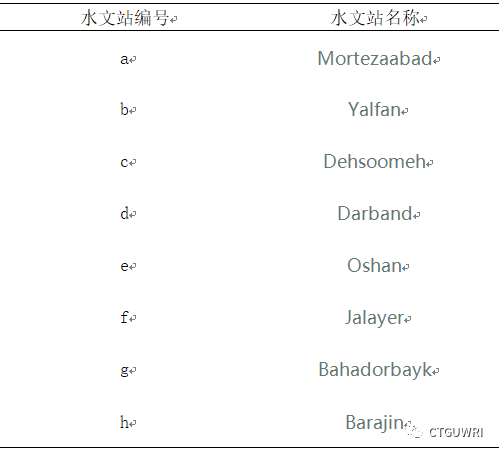
表4、图2中使用的8所水文站编号及名称
如图2所示,NLR高估了6所水文站的FDC;ANN高估了4所水文站的FDC;而SVR中仅有2所水文站有一定偏差,其余6所相对重合。
研究结论
(1)SVR模型在区域化FDC分析中比ANN和RNN具有更好的性能;
(2)SVR的RBF核函数更能反映实际情况。
原文链接
http://dx.doi.org/10.1029/2018WR024620

你在看这篇文章吗
这篇关于支持向量回归_基于支持向量回归的区域化流量历时曲线分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







