本文主要是介绍缓存淘汰算法之LRU LFU 和 redis简单的讲解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
缓存淘汰算法之LRU LFU 和 redis简单的讲解
晨讲人:尤恩
缓存机制是什么?有哪些?
- 堆内存当中的字符串常量池。
- “abc” 先在字符串常量池中查找,如果有,直接拿来用。如果没有则新建,然后再放入字符串常量池。
- 堆内存当中的整数型常量池。
- [-128 ~ 127] 一共256个Integer类型的引用,放在整数型常量池中。没有超出这个范围的话,直接从常量池中取。
- 连接池(Connection Cache)
- 这里所说的连接池中的连接是java语言连接数据库的连接对象:java.sql.Connection对象。
- JVM是一个进程。MySQL数据库是一个进程。进程和进程之间建立连接,打开通道是很费劲的。是很耗费资源的。怎么办?可以提前先创建好N个Connection连接对象,将连接对象放到一个集合当中,我们把这个放有Connection对象的集合称为连接池。每一次用户连接的时候不需要再新建连接对象,省去了新建的环节,直接从连接池中获取连接对象,大大提升访问效率。
- 连接池
- 最小连接数
- 最大连接数
- 连接池可以提高用户的访问效率。当然也可以保证数据库的安全性。
- 线程池
- Tomcat服务器本身就是支持多线程的。
- Tomcat服务器是在用户发送一次请求,就新建一个Thread线程对象吗?
- 答:当然不是,实际上是在Tomcat服务器启动的时候,会先创建好N多个线程Thread对象,然后将线程对象放到集合当中,称为线程池。用户发送请求过来之后,需要有一个对应的线程来处理这个请求,这个时候线程对象就会直接从线程池中拿,效率比较高。
- 所有的WEB服务器,或者应用服务器,都是支持多线程的,都有线程池机制。
- 向ServletContext应用域中存储数据,也等于是将数据存放到缓存cache当中了。
- !!!今日内容 redis
什么是Redis?
Redis(Remote Dictionary Server)是一款基于内存的开源键值对存储数据库,它支持多种数据结构,例如字符串、哈希表、列表、集合和有序集合等。Redis 注重性能,使用 C 语言编写并且所有的操作都发生在内存中,因此它非常快速。
Redis以内存作为数据存储介质,所以读写数据的效率极高,远远超过数据库。以设置和获取一个256字节字符串为例,它的读取速度可高达110000次/s,写速度高达81000次/s。
-
举个例子叭!
拿大型网站来举个例子,比如a网站首页一天有100万人访问,其中有一个板块为推荐新闻。要是直接从数据库查询,那么一天就要多消耗100万次数据库请求。上面已经说过,Redis支持丰富的数据类型,所以这完全可以用Redis来完成,将这种热点数据存到Redis(内存)中,要用的时候,直接从内存取,极大的提高了速度和节约了服务器的开销。
总之,Redis的应用是非常广泛的,而且极有价值,真是服务器中的一件利器,所以从现在开始,我们就来一步步学好它。
Redis中的LRU(最长时间)算法
LRU算法全称是:Least Recently Used,即:检查最近最少使用的数据。这个算法通常使用在内存淘汰策略中,用于将不常用的数据转移出内存,将空间腾给最近更常用的“热点数据”。
一般来讲,LRU将访问数据的顺序或时间和数据本身维护在一个容器当中。当访问一个数据时:
- 若该数据不在容器中,则设置该数据的优先级为最高并放入容器中。
- 若该数据在容器当中,则更新该数据的优先级至最高。
当数据的总量达到上限后,则移除容器中优先级最低的数据。下图是一个简单的LRU原理示意图:
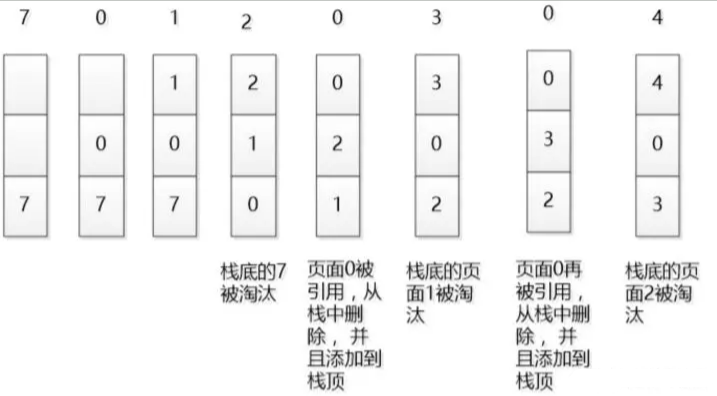
如果我们按照7 0 1 2 0 3 0 4的顺序来访问数据,且数据的总量上限为3,则如上图所示,LRU算法会依次淘汰7 1 2这三个数据。
Redis中的LFU(最少次)算法
LFU算法:least frequently used,最近最不经常使用算法
对于每个条目,维护其使用次数 cnt、最近使用时间 time。
cache容量为 n,即最多存储n个条目。
那么当我需要插入新条目并且cache已经满了的时候,需要删除一个之前的条目。
删除的策略是:优先删除使用次数cnt最小的那个条目*,因为它最近最不经常使用,所以删除它。***
如果使用次数cnt最小值为min_cnt,这个min_cnt对应的条目有多个,那么在这些条目中删除最近使用时间time最早的那个条目(举个栗子:a资源和b资源都使用了两次,但a资源在5s的时候最后一次使用,b资源在7s的时候最后一次使用,那么删除a,因为b资源更晚被使用,所以b资源相比a资源来说,更有理由继续被使用,即时间局部性原理)。
类似LRU算法的想法,利用哈希表+链表。
链表是负责按时间先后排序的。哈希表是负责O(1)时间查找key对应节点的。
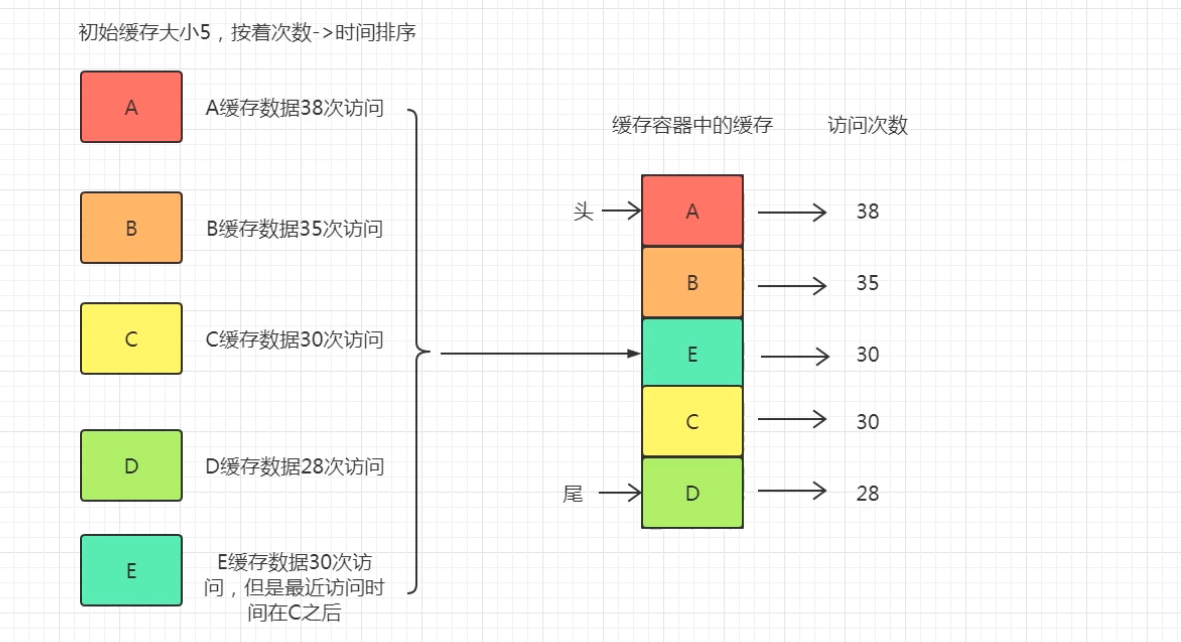
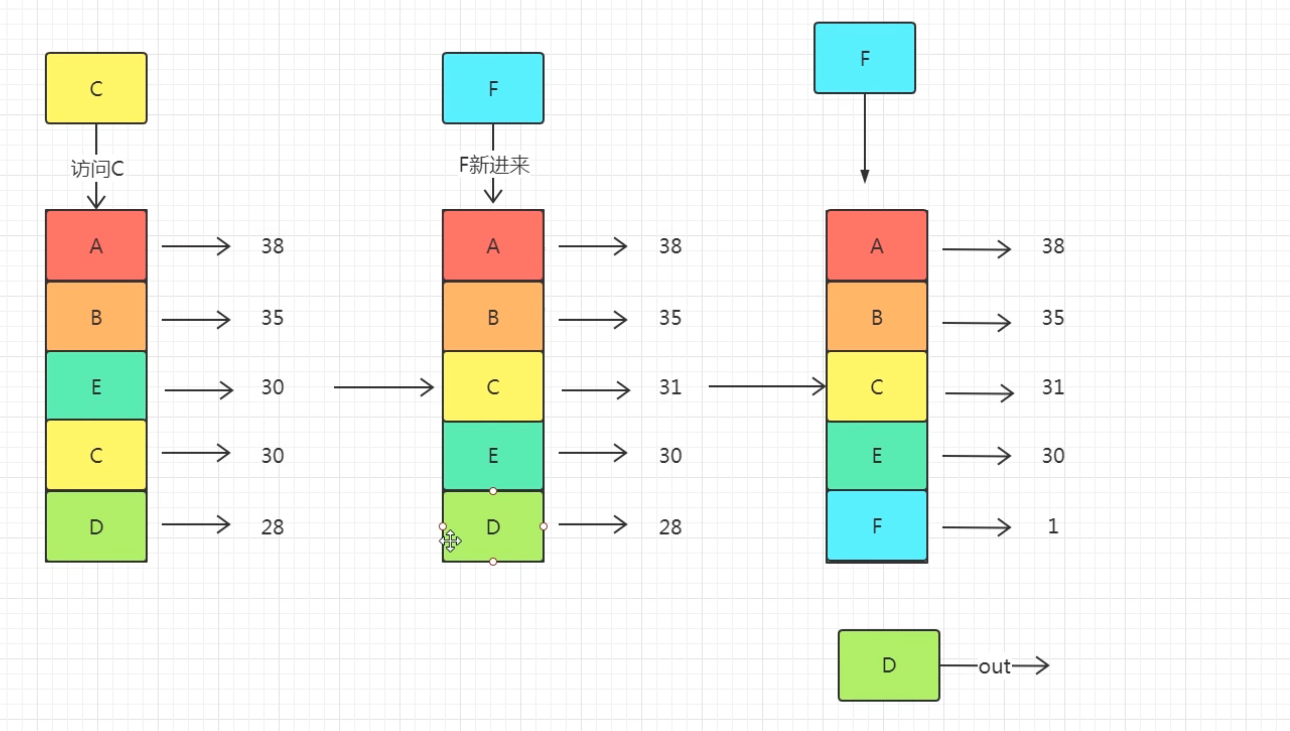
LRU和LFU的区别
LRU和LFU都是内存管理的页面置换算法。
LRU:最近最少使用(最长时间)淘汰算法(Least Recently Used)。LRU是淘汰最长时间没有被使用的页面。
LFU:最不经常使用(最少次)淘汰算法(Least Frequently Used)。LFU是淘汰一段时间内,使用次数最少的
- LRU算法适合:较大的文件比如游戏客户端(最近加载的地图文件);
- LFU算法适合:较小的文件和零碎的文件比如系统文件、应用程序文件 ;
- LRU消耗CPU资源较少,LFU消耗CPU资源较多。
操作系统之页面置换算法
/*
FIFO: 简单的先进先出,用队列模拟即可 prio 表示入队时间(小值先出)
LRU: 淘汰最久没有被访问的页面 prio 表示上一次入队的时间(小值先出)
LFU: 淘汰最少访问次数的页面 prio 表示被访问的次数
NRU: 四类 prio表示状态类数第0类:没有被访问,没有被修改。00第1类:没有被访问,已被修改。 01第2类:已被访问,没有被修改。 10第3类:已被访问,已被修改 11
*/#include<bits/stdc++.h>
#define xcx(x) printf("ojbk %d\n",x)
using namespace std ;
const int PAGE_NUM = 20 ;
const int MEM_SIZE = 3 ;
const double NRU_LIMIT = 3 ;
bool in_mem[ PAGE_NUM+1 ] ;
struct page{int val, prio, pos ; // val:页数 pos:占内存位置page () {}page ( int val , int prio , int pos ) {this->val = val ;this->prio = prio ;this->pos = pos ;}
};bool operator < ( const page &l , const page &r ) {if ( l.prio== r.prio ) {return l.pos < r.pos ;}return l.prio > r.prio ;
}
vector< int > CreatSeq ( int n ) { // 随机生成长度为 n 的访问序列vector< int > ret ;for( int i=0; i<n; i++ ) {ret.push_back( rand()%PAGE_NUM+1 ) ;}return ret ;
}
void Init ( vector< vector<int> > &ret , vector< bool > &is_miss , const vector< int > &seq ) {vector< int > e( MEM_SIZE ) ;memset( in_mem, false, sizeof(in_mem) ) ;is_miss.clear() ; ret.clear() ;for( int i=0; i<seq.size(); i++ ) {is_miss.push_back( 0 ) ;ret.push_back( e ) ;}
}
vector< vector<int> > FIFO ( const vector< int > &seq , vector< bool > &is_miss ) {vector< vector<int> > ret ;Init( ret , is_miss , seq ) ;queue< page > q ;bool is_full = false ;int num = 0, mem_pos[ MEM_SIZE ] = {0} ;for( int i=0; i<seq.size(); i++ ) {if ( in_mem[seq[i]] == false ) { // 不在memis_miss[i] = true ;if ( is_full == true ) { // mem已满,淘汰page temp = q.front() ;q.pop() ; in_mem[ temp.val ] = false ;q.push( page( seq[i], i+1, temp.pos ) ); in_mem[ seq[i] ] = true ;mem_pos[temp.pos] = seq[i] ;}else { // mem未满,添加q.push( page( seq[i], i+1, num ) );in_mem[ seq[i] ] = true ;mem_pos[ num++ ] = seq[i] ;if ( num >= MEM_SIZE ) is_full = true ;}}///存储当前状态for( int j=0; j<MEM_SIZE; j++ ) {ret[i][j] = mem_pos[j] ;}}return ret;
}
vector< vector<int> > LRU ( const vector< int > &seq , vector< bool > &is_miss ) {vector< vector<int> > ret ;Init( ret , is_miss , seq ) ;vector< page > q ;bool is_full = false ;int num = 0, mem_pos[ MEM_SIZE ] = {0} ;for( int i=0; i<seq.size(); i++ ) {if ( in_mem[seq[i]] == false ) { // 不在 memis_miss[i] = true ;if ( is_full == true ) { // mem已满,淘汰page temp = q[0] ;q[0] = page( seq[i], i+1, temp.pos ) ;in_mem[ temp.val ] = false ; in_mem[ seq[i] ] = true ;mem_pos[temp.pos] = seq[i] ;}else { // mem未满,添加q.push_back( page( seq[i], i+1, num ) );in_mem[ seq[i] ] = true ;mem_pos[ num++ ] = seq[i] ;if ( num >= MEM_SIZE ) is_full = true ;}}else { // 在 memfor( int i=0; i<q.size(); i++ ) {if ( q[i].val == seq[i] ) {q[i].prio = i ;}}}sort( q.begin() , q.end() ) ;///存储当前状态for( int j=0; j<MEM_SIZE; j++ ) {ret[i][j] = mem_pos[j] ;}}return ret;
}
vector< vector<int> > LFU ( const vector< int > &seq , vector< bool > &is_miss ) {vector< vector<int> > ret ;Init( ret , is_miss , seq ) ;vector< page > q ;bool is_full = false ;int num = 0, mem_pos[ MEM_SIZE ] = {0} ;for( int i=0; i<seq.size(); i++ ) {if ( in_mem[seq[i]] == false ) { // 不在 memis_miss[i] = true ;if ( is_full == true ) { // mem已满,淘汰page temp = q[0] ;q[0] = page( seq[i], 1, temp.pos ) ;in_mem[ temp.val ] = false ; in_mem[ seq[i] ] = true ;mem_pos[temp.pos] = seq[i] ;}else { // mem未满,添加q.push_back( page( seq[i], 1, num ) );in_mem[ seq[i] ] = true ;mem_pos[ num++ ] = seq[i] ;if ( num >= MEM_SIZE ) is_full = true ;}}else { // 在 memfor( int i=0; i<q.size(); i++ ) {if ( q[i].val == seq[i] ) {q[i].prio++ ;break ;}}}sort( q.begin() , q.end() ) ;///存储当前状态for( int j=0; j<MEM_SIZE; j++ ) {ret[i][j] = mem_pos[j] ;}}return ret;
}
vector< vector<int> > NRU ( const vector< int > &seq , vector< bool > &is_miss ) {double T_start, T_end ;T_start = clock() ;vector< vector<int> > ret ;Init( ret , is_miss , seq ) ;vector< page > q ;bool is_full = false ;int num = 0, mem_pos[ MEM_SIZE ] = {0} , prio[ PAGE_NUM ] = {0} ;for( int i=0; i<seq.size(); i++ ) {if ( in_mem[seq[i]] == false ) { // 不在 memis_miss[i] = true ;if ( is_full == true ) { // mem已满,淘汰page temp = q[0] ; in_mem[ temp.val ] = false ;q[0] = page( seq[i], 0, temp.pos ) ; in_mem[ seq[i] ] = true ;prio[ seq[i] ] |= 1 ; // 视为修改mem_pos[temp.pos] = seq[i] ;}else { // mem未满,添加q.push_back( page( seq[i], 0, num ) );prio[ seq[i] ] |= 2 ; // 视为访问in_mem[ seq[i] ] = true ;mem_pos[ num ] = seq[i] ;num++;if ( num >= MEM_SIZE ) is_full = true ;}}else { // 在 memprio[ seq[i] ] |= 2 ; // 视为访问}if ( clock() - T_start > NRU_LIMIT ) { // 更新T_start = clock() ;for( int i=0; i<PAGE_NUM; i++ ) {prio[i] &= 1 ;}}for( int i=0; i<q.size(); i++ ) {q[i].prio = prio[ q[i].val ] ;}sort( q.begin() , q.end() ) ;///存储当前状态for( int j=0; j<MEM_SIZE; j++ ) {ret[i][j] = mem_pos[j] ;}}return ret;
}
void PrintTable ( const vector< vector<int> > &ans , const vector< bool > &is_miss , string type ) {int num = 0 ;printf( "%s\n", type.c_str() ) ;for( int i=0; i<MEM_SIZE ; i++ ) {printf( "\tmem unit %d :\t", i ) ;for( int j=0; j<ans.size(); j++ ) {if ( ans[j][i] != 0 ) {printf( "%3d", ans[j][i] ) ;}else {printf( " " ) ;}}printf( "\n" ) ;}printf( "\tis miss :\t") ;for( int i=0; i<is_miss.size(); i++ ) {if ( is_miss[i] == true ) {num++ ;printf( " Y" ) ;}else {printf( " N" ) ;}}printf( "\n miss num : %d \n", num ) ;
}
const string type[4] = { "FIFO", "LRU", "LFU", "NRU" };int main() {vector< int > seq = CreatSeq( 19 ) ;printf( "page seq:\t" ) ;for( int i=0; i<seq.size(); i++ ) {printf( "%3d", seq[i] ) ;}printf( "\n" ) ;vector< bool > is_miss ;
///FIFO:vector< vector < int > > ans_FIFO = FIFO( seq , is_miss ) ;PrintTable( ans_FIFO , is_miss , type[0] ) ;
///LRU:vector< vector < int > > ans_LRU = LRU( seq , is_miss ) ;PrintTable( ans_LRU , is_miss , type[1] ) ;
///LFU:vector< vector < int > > ans_LFU = LFU( seq , is_miss ) ;PrintTable( ans_LFU , is_miss , type[2] ) ;
///NRU:vector< vector < int > > ans_NRU = NRU( seq , is_miss ) ;PrintTable( ans_NRU , is_miss , type[3] ) ;return 0;}运行结果:

这篇关于缓存淘汰算法之LRU LFU 和 redis简单的讲解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






