本文主要是介绍【神经网络并行训练(上)】基于MapReduce的并行算法的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
最近看了一些基于MapReduce的神经网络并行训练方面的论文,老师让我自己去实现一下,更深入的体会其中的原理。
MapReduce是基于java语言的框架,于是一开始想用java写深度学习代码。但是dl4j框架实在太难用了,而且网络上的深度学习教程都是基于python的,所以最终还是决定用python去实现基于MapReduce框架的神经网络。如果行不通的话,后面再考虑用java实现神经网络。
目前大致的学习步骤如下:
1、Ubuntu下安装Python3
参考链接:ubuntu下安装python3
2、Python实现最简单的MapReduce例子,如Wordcount
参考链接1:用Python模拟MapReduce分布式计算
参考链接2:用python写MapReduce函数——以WordCount为例
3、在Hadoop上运行Python
参考链接1:在Hadoop上运行Python脚本
参考链接2:Writing An Hadoop MapReduce Program In Python
4、Pycharm(linux)+Hadoop+Spark(环境搭建)
参考链接1:Pycharm(linux)+Hadoop+Spark(环境搭建)
参考链接2:PyCharm搭建Spark开发环境 + 第一个pyspark程序
参考链接3:Spark下使用python写wordCount
参考链接4:Ubuntu 16.04 + PyCharm + spark 运行环境配置
5、Spark实现BP算法并行化
6、复现论文代码
一、Ubuntu下安装Python3
输入python -V查看版本,发现python命令不可用
root@ubuntu:/# python -VCommand 'python' not found, did you mean:command 'python3' from deb python3command 'python' from deb python-is-python3
进入/usr/bin,输入ls -l | grep python,发现python3链接到python3.8
root@ubuntu:/usr/bin# ls -l | grep python
lrwxrwxrwx 1 root root 23 Jun 2 03:49 pdb3.8 -> ../lib/python3.8/pdb.py
lrwxrwxrwx 1 root root 31 Sep 23 2020 py3versions -> ../share/python3/py3versions.py
lrwxrwxrwx 1 root root 9 Sep 23 2020 python3 -> python3.8
-rwxr-xr-x 1 root root 5490352 Jun 2 03:49 python3.8
lrwxrwxrwx 1 root root 33 Jun 2 03:49 python3.8-config -> x86_64-linux-gnu-python3.8-config
lrwxrwxrwx 1 root root 16 Mar 13 2020 python3-config -> python3.8-config
-rwxr-xr-x 1 root root 384 Mar 27 2020 python3-futurize
-rwxr-xr-x 1 root root 388 Mar 27 2020 python3-pasteurize
-rwxr-xr-x 1 root root 3241 Jun 2 03:49 x86_64-linux-gnu-python3.8-config
lrwxrwxrwx 1 root root 33 Mar 13 2020 x86_64-linux-gnu-python3-config -> x86_64-linux-gnu-python3.8-config
输入python3 -V,发现Ubuntu自带python3,并且版本为3.8.10
root@ubuntu:/# python3 -V
Python 3.8.10
输入pip3 -V查看版本
root@ubuntu:/# pip3 -V
pip 20.0.2 from /usr/lib/python3/dist-packages/pip (python 3.8)
输入pip3 list查看包
root@ubuntu:/# pip3 list
Package Version
---------------------- --------------------
apturl 0.5.2
bcrypt 3.1.7
blinker 1.4
Brlapi 0.7.0
certifi 2019.11.28
chardet 3.0.4
Click 7.0
colorama 0.4.3
command-not-found 0.3
cryptography 2.8
至此,说明Ubuntu具备python3环境。
二、实现WordCount
1、本地执行Python的MapReduce任务
1)代码
mapper.py文件
#!/usr/bin/env python3
import sys
for line in sys.stdin:line = line.strip()words = line.split()for word in words:print("%s\t%s" % (word, 1))
reducer.py文件
#!/usr/bin/env python3
from operator import itemgetter
import syscurrent_word = None
current_count = 0
word = Nonefor line in sys.stdin:line = line.strip()word, count = line.split('\t', 1)#word, count = line.split()try:count = int(count)except ValueError: #count如果不是数字的话,直接忽略掉continueif current_word == word:current_count += countelse:if current_word:print("%s\t%s" % (current_word, current_count))current_count = countcurrent_word = wordif word == current_word: #不要忘记最后的输出print("%s\t%s" % (current_word, current_count))
注意#!/usr/bin/env python3,因为本机没有配置环境变量,python命令不生效,所以这里必须写python3
2)在本地测试代码
在/opt/PycharmProjects/MapReduce/WordCount文件夹下
为了保险起见可以先赋予运行权限
root@ubuntu:/opt/PycharmProjects/MapReduce/WordCount# chmod +x mapper.py
root@ubuntu:/opt/PycharmProjects/MapReduce/WordCount# chmod +x reducer.py
测试mapper.py程序
root@ubuntu:/opt/PycharmProjects/MapReduce/WordCount# echo "aa bb cc dd aa cc" | python3 mapper.py
aa 1
bb 1
cc 1
dd 1
aa 1
cc 1
测试reducer.py程序
root@ubuntu:/opt/PycharmProjects/MapReduce/WordCount# echo "foo foo quux labs foo bar quux" | python3 mapper.py | sort -k1,1 | python3 reducer.py
bar 1
foo 3
labs 1
quux 2
2、在Hadoop集群上执行Python的MapReduce任务
方法一、Hadoop Streaming
Hadoop Streaming提供了一个便于进行MapReduce编程的工具包,使用它可以基于一些可执行命令、脚本语言或其他编程语言来实现Mapper和 Reducer,从而充分利用Hadoop并行计算框架的优势和能力,来处理大数据。
(1)下载文本文件
root@ubuntu:/home/wuwenjing/Downloads/dataset/guteberg# wget http://www.gutenberg.org/files/5000/5000-8.txt
root@ubuntu:/home/wuwenjing/Downloads/dataset/guteberg# wget http://www.gutenberg.org/cache/epub/20417/pg20417.txt
(2)在HDFS上创建文件夹,把这两本书传到HDFS上
root@ubuntu:/hadoop/hadoop-2.9.2/sbin# hdfs dfs -mkdir /user/MapReduce/input
root@ubuntu:/hadoop/hadoop-2.9.2/sbin# hdfs dfs -put /home/wuwenjing/Downloads/dataset/gutenberg/*.txt /user/MapReduce/input
(3)寻找streaming的jar文件存放地址,找到share文件夹中的hadoop-straming*.jar文件
root@ubuntu:/hadoop# find ./ -name "*streaming*.jar"
./hadoop-2.9.2/share/hadoop/tools/lib/hadoop-streaming-2.9.2.jar
./hadoop-2.9.2/share/hadoop/tools/sources/hadoop-streaming-2.9.2-sources.jar
./hadoop-2.9.2/share/hadoop/tools/sources/hadoop-streaming-2.9.2-test-sources.jar
(4)由于通过streaming接口运行的脚本太长了,因此直接建立一个shell名称为run.sh来运行:
root@ubuntu:/hadoop/hadoop-2.9.2# vim run.sh
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar \
-file /opt/PycharmProjects/MapReduce/WordCount/mapper.py -mapper /opt/PycharmProjects/MapReduce/WordCount/mapper.py \
-file /opt/PycharmProjects/MapReduce/WordCount/reducer.py -reducer /opt/PycharmProjects/MapReduce/WordCount/reducer.py \
-input /user/MapReduce/input/*.txt -output /user/MapReduce/output
root@ubuntu:/hadoop/hadoop-2.9.2# source run.sh
这里报错,报错信息如下:
21/08/30 23:24:34 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.
21/08/30 23:24:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
packageJobJar: [/opt/PycharmProjects/MapReduce/WordCount/mapper.py, /opt/PycharmProjects/MapReduce/WordCount/reducer.py] [] /tmp/streamjob4294615261368991400.jar tmpDir=null
21/08/30 23:24:35 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
21/08/30 23:24:35 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
21/08/30 23:24:35 INFO jvm.JvmMetrics: Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized
21/08/30 23:24:35 INFO mapred.FileInputFormat: Total input files to process : 2
21/08/30 23:24:35 INFO mapreduce.JobSubmitter: number of splits:2
21/08/30 23:24:36 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1574514939_0001
21/08/30 23:24:36 INFO mapred.LocalDistributedCacheManager: Localized file:/opt/PycharmProjects/MapReduce/WordCount/mapper.py as file:/hadoop/hadoop-2.9.2/tmp/mapred/local/1630391076183/mapper.py
21/08/30 23:24:36 INFO mapred.LocalDistributedCacheManager: Localized file:/opt/PycharmProjects/MapReduce/WordCount/reducer.py as file:/hadoop/hadoop-2.9.2/tmp/mapred/local/1630391076184/reducer.py
21/08/30 23:24:36 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
21/08/30 23:24:36 INFO mapreduce.Job: Running job: job_local1574514939_0001
21/08/30 23:24:36 INFO mapred.LocalJobRunner: OutputCommitter set in config null
21/08/30 23:24:36 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapred.FileOutputCommitter
21/08/30 23:24:36 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/08/30 23:24:36 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
21/08/30 23:24:36 INFO mapred.LocalJobRunner: Waiting for map tasks
21/08/30 23:24:36 INFO mapred.LocalJobRunner: Starting task: attempt_local1574514939_0001_m_000000_0
21/08/30 23:24:36 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/08/30 23:24:36 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
21/08/30 23:24:36 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
21/08/30 23:24:36 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/MapReduce/input/5000-8.txt:0+1428843
21/08/30 23:24:36 INFO mapred.MapTask: numReduceTasks: 1
21/08/30 23:24:36 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
21/08/30 23:24:36 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
21/08/30 23:24:36 INFO mapred.MapTask: soft limit at 83886080
21/08/30 23:24:36 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
21/08/30 23:24:36 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
21/08/30 23:24:36 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
21/08/30 23:24:36 INFO streaming.PipeMapRed: PipeMapRed exec [/hadoop/hadoop-2.9.2/sbin/./mapper.py]
21/08/30 23:24:36 INFO Configuration.deprecation: mapred.work.output.dir is deprecated. Instead, use mapreduce.task.output.dir
21/08/30 23:24:36 INFO Configuration.deprecation: map.input.start is deprecated. Instead, use mapreduce.map.input.start
21/08/30 23:24:36 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
21/08/30 23:24:36 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
21/08/30 23:24:36 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
21/08/30 23:24:36 INFO Configuration.deprecation: mapred.local.dir is deprecated. Instead, use mapreduce.cluster.local.dir
21/08/30 23:24:36 INFO Configuration.deprecation: map.input.file is deprecated. Instead, use mapreduce.map.input.file
21/08/30 23:24:36 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
21/08/30 23:24:36 INFO Configuration.deprecation: map.input.length is deprecated. Instead, use mapreduce.map.input.length
21/08/30 23:24:36 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
21/08/30 23:24:36 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name
21/08/30 23:24:36 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
21/08/30 23:24:36 INFO streaming.PipeMapRed: R/W/S=1/0/0 in:NA [rec/s] out:NA [rec/s]
21/08/30 23:24:36 INFO streaming.PipeMapRed: R/W/S=10/0/0 in:NA [rec/s] out:NA [rec/s]
21/08/30 23:24:36 INFO streaming.PipeMapRed: R/W/S=100/0/0 in:NA [rec/s] out:NA [rec/s]
21/08/30 23:24:36 INFO streaming.PipeMapRed: R/W/S=1000/0/0 in:NA [rec/s] out:NA [rec/s]
21/08/30 23:24:36 INFO streaming.PipeMapRed: Records R/W=2820/1
Traceback (most recent call last):File "/hadoop/hadoop-2.9.2/sbin/./mapper.py", line 3, in <module>for line in sys.stdin:File "/usr/lib/python3.8/codecs.py", line 322, in decode(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xdc in position 2092: invalid continuation byte
21/08/30 23:24:36 INFO streaming.PipeMapRed: MRErrorThread done
21/08/30 23:24:36 INFO streaming.PipeMapRed: R/W/S=2820/5129/0 in:NA [rec/s] out:NA [rec/s]
minRecWrittenToEnableSkip_=9223372036854775807 HOST=null
USER=wuwenjing
HADOOP_USER=null
last tool output: |Books, 1ed 1-Have 1ement 111|java.io.IOException: Broken pipeat java.io.FileOutputStream.writeBytes(Native Method)at java.io.FileOutputStream.write(FileOutputStream.java:326)at java.io.BufferedOutputStream.write(BufferedOutputStream.java:122)at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)at java.io.BufferedOutputStream.write(BufferedOutputStream.java:126)at java.io.DataOutputStream.write(DataOutputStream.java:107)at org.apache.hadoop.streaming.io.TextInputWriter.writeUTF8(TextInputWriter.java:72)at org.apache.hadoop.streaming.io.TextInputWriter.writeValue(TextInputWriter.java:51)at org.apache.hadoop.streaming.PipeMapper.map(PipeMapper.java:106)at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54)at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:459)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:270)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
21/08/30 23:24:36 WARN streaming.PipeMapRed: java.io.IOException: Stream closed
21/08/30 23:24:36 INFO streaming.PipeMapRed: PipeMapRed failed!
java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:325)at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:538)at org.apache.hadoop.streaming.PipeMapper.map(PipeMapper.java:120)at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54)at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:459)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:270)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
21/08/30 23:24:36 WARN streaming.PipeMapRed: java.io.IOException: Stream closed
21/08/30 23:24:36 INFO streaming.PipeMapRed: PipeMapRed failed!
java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:325)at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:538)at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:130)at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:459)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:270)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
21/08/30 23:24:36 INFO mapred.LocalJobRunner: Starting task: attempt_local1574514939_0001_m_000001_0
21/08/30 23:24:36 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/08/30 23:24:36 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
21/08/30 23:24:36 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
21/08/30 23:24:36 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/MapReduce/input/pg20417.txt:0+674570
21/08/30 23:24:36 INFO mapred.MapTask: numReduceTasks: 1
21/08/30 23:24:36 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
21/08/30 23:24:36 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
21/08/30 23:24:36 INFO mapred.MapTask: soft limit at 83886080
21/08/30 23:24:36 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
21/08/30 23:24:36 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
21/08/30 23:24:36 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
21/08/30 23:24:36 INFO streaming.PipeMapRed: PipeMapRed exec [/hadoop/hadoop-2.9.2/sbin/./mapper.py]
21/08/30 23:24:36 INFO mapred.LineRecordReader: Found UTF-8 BOM and skipped it
21/08/30 23:24:36 INFO streaming.PipeMapRed: R/W/S=1/0/0 in:NA [rec/s] out:NA [rec/s]
21/08/30 23:24:36 INFO streaming.PipeMapRed: R/W/S=10/0/0 in:NA [rec/s] out:NA [rec/s]
21/08/30 23:24:37 INFO streaming.PipeMapRed: R/W/S=100/0/0 in:NA [rec/s] out:NA [rec/s]
21/08/30 23:24:37 INFO streaming.PipeMapRed: R/W/S=1000/0/0 in:NA [rec/s] out:NA [rec/s]
21/08/30 23:24:37 INFO streaming.PipeMapRed: Records R/W=2788/1
21/08/30 23:24:37 INFO streaming.PipeMapRed: R/W/S=10000/49444/0 in:NA [rec/s] out:NA [rec/s]
21/08/30 23:24:37 INFO streaming.PipeMapRed: MRErrorThread done
21/08/30 23:24:37 INFO streaming.PipeMapRed: mapRedFinished
21/08/30 23:24:37 INFO mapred.LocalJobRunner:
21/08/30 23:24:37 INFO mapred.MapTask: Starting flush of map output
21/08/30 23:24:37 INFO mapred.MapTask: Spilling map output
21/08/30 23:24:37 INFO mapred.MapTask: bufstart = 0; bufend = 866856; bufvoid = 104857600
21/08/30 23:24:37 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 25775024(103100096); length = 439373/6553600
21/08/30 23:24:37 INFO mapred.MapTask: Finished spill 0
21/08/30 23:24:37 INFO mapred.Task: Task:attempt_local1574514939_0001_m_000001_0 is done. And is in the process of committing
21/08/30 23:24:37 INFO mapred.LocalJobRunner: Records R/W=2788/1
21/08/30 23:24:37 INFO mapred.Task: Task 'attempt_local1574514939_0001_m_000001_0' done.
21/08/30 23:24:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local1574514939_0001_m_000001_0
21/08/30 23:24:37 INFO mapred.LocalJobRunner: map task executor complete.
21/08/30 23:24:37 WARN mapred.LocalJobRunner: job_local1574514939_0001
java.lang.Exception: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:491)at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:551)
Caused by: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:325)at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:538)at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:130)at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:459)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:270)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
21/08/30 23:24:37 INFO mapreduce.Job: Job job_local1574514939_0001 running in uber mode : false
21/08/30 23:24:37 INFO mapreduce.Job: map 100% reduce 0%
21/08/30 23:24:37 INFO mapreduce.Job: Job job_local1574514939_0001 failed with state FAILED due to: NA
21/08/30 23:24:37 INFO mapreduce.Job: Counters: 22File System CountersFILE: Number of bytes read=2069FILE: Number of bytes written=1568742FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=809738HDFS: Number of bytes written=0HDFS: Number of read operations=7HDFS: Number of large read operations=0HDFS: Number of write operations=1Map-Reduce FrameworkMap input records=12760Map output records=109844Map output bytes=866856Map output materialized bytes=1086550Input split bytes=106Combine input records=0Spilled Records=109844Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=0Total committed heap usage (bytes)=357564416File Input Format Counters Bytes Read=674570
21/08/30 23:24:37 ERROR streaming.StreamJob: Job not successful!
Streaming Command Failed!仔细看了一下,最早的错误出现在这里:
Traceback (most recent call last):File "/hadoop/hadoop-2.9.2/sbin/./mapper.py", line 3, in <module>for line in sys.stdin:File "/usr/lib/python3.8/codecs.py", line 322, in decode(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xdc in position 2092: invalid continuation byte
貌似是因为编码问题
于是我自己创建了一个test.txt上传到HDFS
运行成功
root@ubuntu:/hadoop/hadoop-2.9.2/sbin# hdfs dfs -cat /user/MapReduce/output/*
21/08/31 00:02:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
a 1
hello 2
map 4
reduce 3
world 1
方法二、mrjob库
转载自https://www.jianshu.com/p/70bd81b2956f
mrjob是一个Python库,实现了Hadoop的MapReduce操作。它封装了Hadoop streaming,可以让人用全Python的脚本实现Hadoop计算。它甚至可以让人在没有Hadoop环境下完成测试,并允许用户将mapper和reducer写进一个类里。简直是神器!
(1)代码
from mrjob.job import MRJobclass MRWordCount(MRJob):def mapper(self, _, line):for word in line.split():yield(word, 1)def reducer(self, word, counts):yield(word, sum(counts))if __name__ == '__main__':MRWordCount.run()
(2)提供输入文件地址,在命令行运行代码
root@ubuntu:/opt/PycharmProjects/Hadoop/WordCount# python3 wordcount.py /home/wuwenjing/Downloads/test.txt
No configs found; falling back on auto-configuration
No configs specified for inline runner
Creating temp directory /tmp/wordcount.wuwenjing.20210902.050430.575802
Running step 1 of 1...
job output is in /tmp/wordcount.wuwenjing.20210902.050430.575802/output
Streaming final output from /tmp/wordcount.wuwenjing.20210902.050430.575802/output...
"reduce" 3
"world" 1
"a" 1
"hello" 2
"map" 4
Removing temp directory /tmp/wordcount.wuwenjing.20210902.050430.575802...
就这样好了?我们都不需要配置Hadoop环境吗?答案是不需要,这就是mrjob的强大之处,帮你模拟了Hadoop的MR计算方式。
(3)更多选项
-r inline: 默认选项,单线程Python运行
-r local: 多进程
-r hadoop: 运行在Hadoop上
尝试了一下-r hadoop发现有报错:
root@ubuntu:/opt/PycharmProjects/Hadoop/WordCount# python3 wordcount.py /home/wuwenjing/Downloads/test.txt -r hadoop
No configs found; falling back on auto-configuration
No configs specified for hadoop runner
Looking for hadoop binary in /hadoop/hadoop-2.9.2/bin...
Found hadoop binary: /hadoop/hadoop-2.9.2/bin/hadoop
Using Hadoop version 2.9.2
Looking for Hadoop streaming jar in /hadoop/hadoop-2.9.2...
Found Hadoop streaming jar: /hadoop/hadoop-2.9.2/share/hadoop/tools/lib/hadoop-streaming-2.9.2.jar
Creating temp directory /tmp/wordcount.wuwenjing.20210902.051554.258159
uploading working dir files to hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.051554.258159/files/wd...
Copying other local files to hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.051554.258159/files/
Running step 1 of 1...Unable to load native-hadoop library for your platform... using builtin-java classes where applicablesession.id is deprecated. Instead, use dfs.metrics.session-idInitializing JVM Metrics with processName=JobTracker, sessionId=Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initializedCleaning up the staging area file:/hadoop/hadoop-2.9.2/tmp/mapred/staging/root345655877/.staging/job_local345655877_0001Error launching job , bad input path : File does not exist: /hadoop/hadoop-2.9.2/tmp/mapred/staging/root345655877/.staging/job_local345655877_0001/files/mrjob.zip#mrjob.zipStreaming Command Failed!
Attempting to fetch counters from logs...
Can't fetch history log; missing job ID
No counters found
Scanning logs for probable cause of failure...
Can't fetch history log; missing job ID
Can't fetch task logs; missing application ID
Step 1 of 1 failed: Command '['/hadoop/hadoop-2.9.2/bin/hadoop', 'jar', '/hadoop/hadoop-2.9.2/share/hadoop/tools/lib/hadoop-streaming-2.9.2.jar', '-files', 'hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.051554.258159/files/wd/mrjob.zip#mrjob.zip,hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.051554.258159/files/wd/setup-wrapper.sh#setup-wrapper.sh,hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.051554.258159/files/wd/wordcount.py#wordcount.py', '-input', 'hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.051554.258159/files/test.txt', '-output', 'hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.051554.258159/output', '-mapper', '/bin/sh -ex setup-wrapper.sh python3 wordcount.py --step-num=0 --mapper', '-reducer', '/bin/sh -ex setup-wrapper.sh python3 wordcount.py --step-num=0 --reducer']' returned non-zero exit status 512.
解决办法:
参考链接:https://www.codeleading.com/article/50152823491/
在master和各个节点执行以下操作:
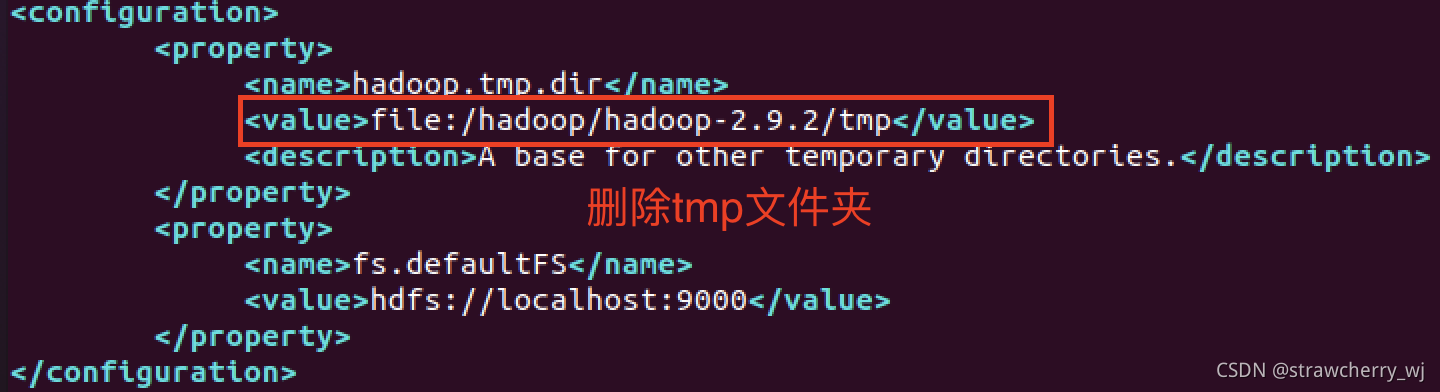
core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:///usr/local/hadoop/hadoop_data</value><description>A base for other temporary directories.</description></property>
</configuration>
hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>hadoop.tmp.dir</name><value>file:///usr/local/hadoop/hadoop_data</value><description>A base for other temporary directories.</description></property>
</configuration>
mapred-site.xml
<configuration><property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
</configuration>
yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>128</value><description>Minimum limit of memory to allocate to each container request at the Resource Manager.</description></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value><description>Maximum limit of memory to allocate to each container request at the Resource Manager.</description></property><property><name>yarn.scheduler.minimum-allocation-vcores</name><value>1</value><description>The minimum allocation for every container request at the RM, in terms of virtual CPU cores. Requests lower than this won't take effect, and the specified value will get allocated the minimum.</description></property><property><name>yarn.scheduler.maximum-allocation-vcores</name><value>2</value><description>The maximum allocation for every container request at the RM, in terms of virtual CPU cores. Requests higher than this won't take effect, and will get capped to this value.</description></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value><description>Physical memory, in MB, to be made available to running containers</description></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>4</value><description>Number of CPU cores that can be allocated for containers.</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>shuffle service that needs to be set for Map Reduce to run </description></property>
</configuration>
(修改完这些文件,我深刻怀疑当时搭建伪分布式Hadoop的时候对于这些文件的配置有问题,甚至当时都没有配置yarn-site.xml文件,很有可能是因为配置文件问题导致无法运行mrjob)
然后执行hadoop namenode -format格式化namenode HDFS
在格式化之前,要注意删除core-site.xml和hdfs-site.xml中指定的data文件夹下面的数据,否则NameNode节点会出错
参考链接:https://www.cnblogs.com/zhf123/p/12033601.html

执行start-all.sh启动Hadoop
再次执行mrjob任务,运行成功
root@ubuntu:/opt/PycharmProjects/Hadoop/WordCount# python3 wordcount.py -r hadoop hdfs:///user/MapReduce/test.txt
No configs found; falling back on auto-configuration
No configs specified for hadoop runner
Looking for hadoop binary in /hadoop/hadoop-2.9.2/bin...
Found hadoop binary: /hadoop/hadoop-2.9.2/bin/hadoop
Using Hadoop version 2.9.2
Looking for Hadoop streaming jar in /hadoop/hadoop-2.9.2...
Found Hadoop streaming jar: /hadoop/hadoop-2.9.2/share/hadoop/tools/lib/hadoop-streaming-2.9.2.jar
Creating temp directory /tmp/wordcount.wuwenjing.20210902.074416.286765
uploading working dir files to hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.074416.286765/files/wd...
Copying other local files to hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.074416.286765/files/
Running step 1 of 1...packageJobJar: [/tmp/hadoop-unjar418446383398387806/] [] /tmp/streamjob7937605966187792125.jar tmpDir=nullConnecting to ResourceManager at /0.0.0.0:8032Connecting to ResourceManager at /0.0.0.0:8032Total input files to process : 1number of splits:2yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabledSubmitting tokens for job: job_1630568492464_0001Submitted application application_1630568492464_0001The url to track the job: http://ubuntu:8088/proxy/application_1630568492464_0001/Running job: job_1630568492464_0001Job job_1630568492464_0001 running in uber mode : falsemap 0% reduce 0%map 100% reduce 0%map 100% reduce 100%Job job_1630568492464_0001 completed successfullyOutput directory: hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.074416.286765/output
Counters: 49File Input Format Counters Bytes Read=102File Output Format Counters Bytes Written=45File System CountersFILE: Number of bytes read=129FILE: Number of bytes written=608687FILE: Number of large read operations=0FILE: Number of read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=296HDFS: Number of bytes written=45HDFS: Number of large read operations=0HDFS: Number of read operations=9HDFS: Number of write operations=2Job Counters Data-local map tasks=2Launched map tasks=2Launched reduce tasks=1Total megabyte-milliseconds taken by all map tasks=51970048Total megabyte-milliseconds taken by all reduce tasks=5447680Total time spent by all map tasks (ms)=50752Total time spent by all maps in occupied slots (ms)=406016Total time spent by all reduce tasks (ms)=5320Total time spent by all reduces in occupied slots (ms)=42560Total vcore-milliseconds taken by all map tasks=50752Total vcore-milliseconds taken by all reduce tasks=5320Map-Reduce FrameworkCPU time spent (ms)=6660Combine input records=0Combine output records=0Failed Shuffles=0GC time elapsed (ms)=1554Input split bytes=194Map input records=11Map output bytes=101Map output materialized bytes=135Map output records=11Merged Map outputs=2Physical memory (bytes) snapshot=736129024Reduce input groups=5Reduce input records=11Reduce output records=5Reduce shuffle bytes=135Shuffled Maps =2Spilled Records=22Total committed heap usage (bytes)=491257856Virtual memory (bytes) snapshot=5856010240Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0
job output is in hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.074416.286765/output
Streaming final output from hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.074416.286765/output...
"a" 1
"hello" 2
"map" 4
"reduce" 3
"world" 1
Removing HDFS temp directory hdfs:///user/wuwenjing/tmp/mrjob/wordcount.wuwenjing.20210902.074416.286765...
Removing temp directory /tmp/wordcount.wuwenjing.20210902.074416.286765...
三、基于MapReduce的梯度下降算法
本地实现
github链接:https://github.com/pderichai/large-scale-classification

数据集可以在上面的github链接下载到
直接下载下来的源码是用python2写的,有些地方因为python2、python3版本问题报错,所以我对其进行了修改,修改后的代码如下:
run.py文件:
主函数,传入网络、训练集、测试集的文件地址作为参数即可
from collections import defaultdict
import argparse
import glob
import importlib
import imp
import multiprocessing
import numpy as np
import os
import random
import resource
import sys
import itertoolstry:import simplejson as json
except:import json
import logginglogger = logging.getLogger(__name__)
logging.basicConfig(level=logging.DEBUG)def chunks(iterable, size=10):iterator = iter(iterable)for first in iterator:yield list(itertools.chain([first], itertools.islice(iterator, size - 1)))def isolated_batch_call(f, arguments):"""Calls the function f in a separate process and returns list of results"""def lf(q):ret = f(*arguments)q.put(list(ret))q = multiprocessing.Queue()p = multiprocessing.Process(target=lf, args=(q,))p.start()ret = q.get()p.join()return retdef mapreduce(input, mapper, reducer, batch_size=50, log=False):"""Python function that runs a worst-case map reduce framework on the provided dataArgs:input -- list or generator of (key, value) tuplemapper -- function that takes (key, value) pair as input and returns iterable key-value pairsreducer -- function that takes key + list of values and outputs (key, value) pairlog -- whether log messages should be generated (default: False)Returns list of (key, value pairs)"""# Set initial random seedrandom.seed(0)# Run mappersif log: logger.info("Starting mapping phase!")d = defaultdict(list)for pairs_generator in chunks(input, batch_size):pairs = list(pairs_generator)k, v = None, [x[1] for x in pairs]if log: logger.debug(" Running mapper for '%s' key with value '%s'...", k, v)for k2, v2 in isolated_batch_call(mapper, (k, v)):if log: logger.debug(" Mapper produced (%s, %s) pair...", k2, v2)if not isinstance(k2, (str, int, float)):raise Exception("Keys must be strings, ints or floats (provided '%s')!" % k2)d[k2].append(v2)if log: logger.info("Finished mapping phase!")# Random permutations of both keys and values.keys = d.keys()random.shuffle(keys)for k in keys:random.shuffle(d[k])# Run reducersif log: logger.info("Starting reducing phase!")res = []if len(keys) > 1:raise Exception("Only one distinct key expected from mappers.")k = list(keys)[0]v = d[k]r = isolated_batch_call(reducer, (k, v))if log: logger.debug(" Reducer produced %s", r)logger.info("Finished reducing phase!")return rdef yield_pattern(path):"""Yield lines from each file in specified folder"""for i in glob.iglob(path):if os.path.isfile(i):with open(i, "r") as fin:for line in fin:yield None, line'''def import_from_file(f):"""Import code from the specified file"""#print(f)#mod = imp.new_module("mod")mod = importlib.import_module(f)#exec f in mod.__dict__#exec_(f,mod.__dict__)return mod'''
def import_from_file(f):mod = imp.new_module("mod")mod.__file__ = "mod"mod.__package__ = ''code = compile(f,'','exec')exec(code, mod.__dict__)return moddef evaluate(weights, test_data, transform):logger.info("Evaluating the solution")accuracy, total = 0, 0instances = transform(test_data[:, 1:])labels = test_data[:, 0].ravel()if not instances.shape[1] == weights.shape[1]:logging.error("Shapes of weight vector and transformed ""data don't match")logging.error("%s %s", instances.shape, weights.shape)sys.exit(-3)for features, label in zip(instances, labels):if label * np.inner(weights, features) > 0:accuracy += 1total += 1return float(accuracy) / totaldef run(sourcestring, input_pattern, test_file, batch, log):mod = import_from_file(sourcestring)input = yield_pattern(input_pattern)#print(mod)output = mapreduce(input, mod.mapper, mod.reducer, batch, log)weights = np.array(output)print(weights)if weights.shape[0] > 1:logging.error("Incorrect format from reducer")sys.exit(-2)test_data = np.loadtxt(test_file, delimiter=" ")return evaluate(weights, test_data, mod.transform)def main():parser = argparse.ArgumentParser(description=__doc__,formatter_class=argparse.RawDescriptionHelpFormatter)parser.add_argument('train_file', help='File with the training instances')parser.add_argument('test_file', help='File with the test instances')parser.add_argument('source_file', help='.py file with mapper and reducer function')parser.add_argument('--log', '-l', help='Enable logging for debugging', action='store_true')train_file = "/Users/wuwenjing/Downloads/large-scale-classification-master/data/handout_train.txt"test_file = "/Users/wuwenjing/Downloads/large-scale-classification-master/data/handout_test.txt"source_file = "/Users/wuwenjing/Downloads/large-scale-classification-master/parallel_stochastic_gradient_descent.py"args = parser.parse_args([train_file, test_file, source_file])print(args)BATCH = 5000with open(args.source_file, "r") as fin:source = fin.read()print(run(source, args.train_file, args.test_file, BATCH, args.log))if __name__ == "__main__":main()
parallel_stochastic_gradient_descent.py文件:
存放网络模型,被run.py调用
import numpy as np# constants
# m is the dimension of the transformed feature vector
m = 3000
# number of iterations of PEGASOS
iterations = 300000
# regularization constant
lambda_val = 1e-6
# standard deviation of p in RFF
sigma = 10# transforms X into m-dimensional feature vectors using RFF and RBF kernel
# Make sure this function works for both 1D and 2D NumPy arrays.
def transform(X):np.random.seed(0)b = np.random.rand(m) * 2 * np.piif X.ndim == 1:w = np.random.multivariate_normal(np.zeros(X.size), sigma**2 * np.identity(X.size), m)else:w = np.random.multivariate_normal(np.zeros(X.shape[1]), sigma**2 * np.identity(X.shape[1]), m)transformed = (2.0 / m)**0.5 * np.cos(np.dot(X, np.transpose(w)) + b)# feature normalizationtransformed = (transformed - np.mean(transformed, 0)) / np.std(transformed, 0)return transformed# key: None
# value: one line of input file
def mapper(key, value):# 2D NumPy array containing the original feature vectorsfeatures = np.zeros([len(value), len(value[0].split()) - 1])# 1D NumPy array containing the classifications of the training dataclassifications = np.zeros(len(value))# populate features and classificationsfor i in range(len(value)):tokens = value[i].split()classifications[i] = tokens[0]features[i] = tokens[1:]# project features into higher dimensional spacefeatures = transform(features)# PEGASOSw = np.zeros(m)for i in range(1, iterations):w = update_weights(w, features, classifications, i)yield 0, w# weight vector update of PEGASOS
def update_weights(w, features, classifications, t):i = int(np.random.uniform(0, features.shape[0]))learning_rate = 1 / (lambda_val * t)new_w = (1 - learning_rate * lambda_val) * w + learning_rate * hinge_loss_gradient(w, features[i], classifications[i])# optional projection step#new_w = min(1, ((1 / lambda_val**0.5) / np.linalg.norm(new_w))) * new_wreturn new_w# calculate the gradient of the hinge loss function
def hinge_loss_gradient(w, x, y):if np.dot(w, x) * y >= 1:return 0else:return y * xdef reducer(key, values):cumulative_weights = np.zeros(m)for w in values:cumulative_weights += w# yield the average of the weightsyield cumulative_weights / len(values)
本来是打算在虚拟机运行的,奈何虚拟机太渣,pycharm一跑就闪退
在本机运行成功

四、Pycharm+Hadoop+Spark环境搭建
1、安装spark
由于我已经搭建了hadoop伪分布式,现在只要安装spark就可以了
(1)Apache Spark官网下载安装包:http://spark.apache.org/downloads.html
(2)解压到某文件夹,我这里是创建了一个/spark文件夹
mkdir /spark
tar -zxvf spark-3.1.2-bin-without-hadoop.tgz -C /spark
(3)环境变量配置
vim /etc/profile
#spark
export SPARK_HOME=/spark/spark-3.1.2-bin-without-hadoop
export PATH=${PATH}:${SPARK_HOME}/bin
#pyspark
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
本系统python安装在/usr/bin/python3,这里的PYSPARK_PYTHON填写可执行python的地址/usr/bin/python3,如果指定软连接了python3,可以直接使用python3。
source /etc/profile
(4)spark文件配置
cd /spark/spark-3.1.2-bin-without-hadoop/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export SPARK_DIST_CLASSPATH=$(/hadoop/hadoop-2.9.2/bin/hadoop classpath)
#有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。
export JAVA_HOME=/java/jdk1.8.0_261
export HADOOP_HOME=/hadoop/hadoop-2.9.2
export HADOOP_CONF_DIR=/hadoop/hadoop-2.9.2/etc/hadoop
#export SCALA_HOME=/usr/local/apps/scala
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=512M
(5)启动hadoop、spark并查看jps
cd /hadoop/hadoop-2.9.2/sbin
./start-all.sh
cd /spark/spark-3.1.2-bin-without-hadoop/sbin
./start-all.sh
jps
12644 Jps
9223 NodeManager
12503 SparkSubmit
8951 SecondaryNameNode
8584 NameNode
9577 Master
8749 DataNode
9086 ResourceManager
9711 Worker
2、在pycharm上配置spark环境
(1)点击pycharm右上角的“Add Configuration”或通过菜单栏“run”下拉点击选择“Edit Configuration”,在新弹出的窗口左上角点击”+”号(“+ Python”),命名为Spark。
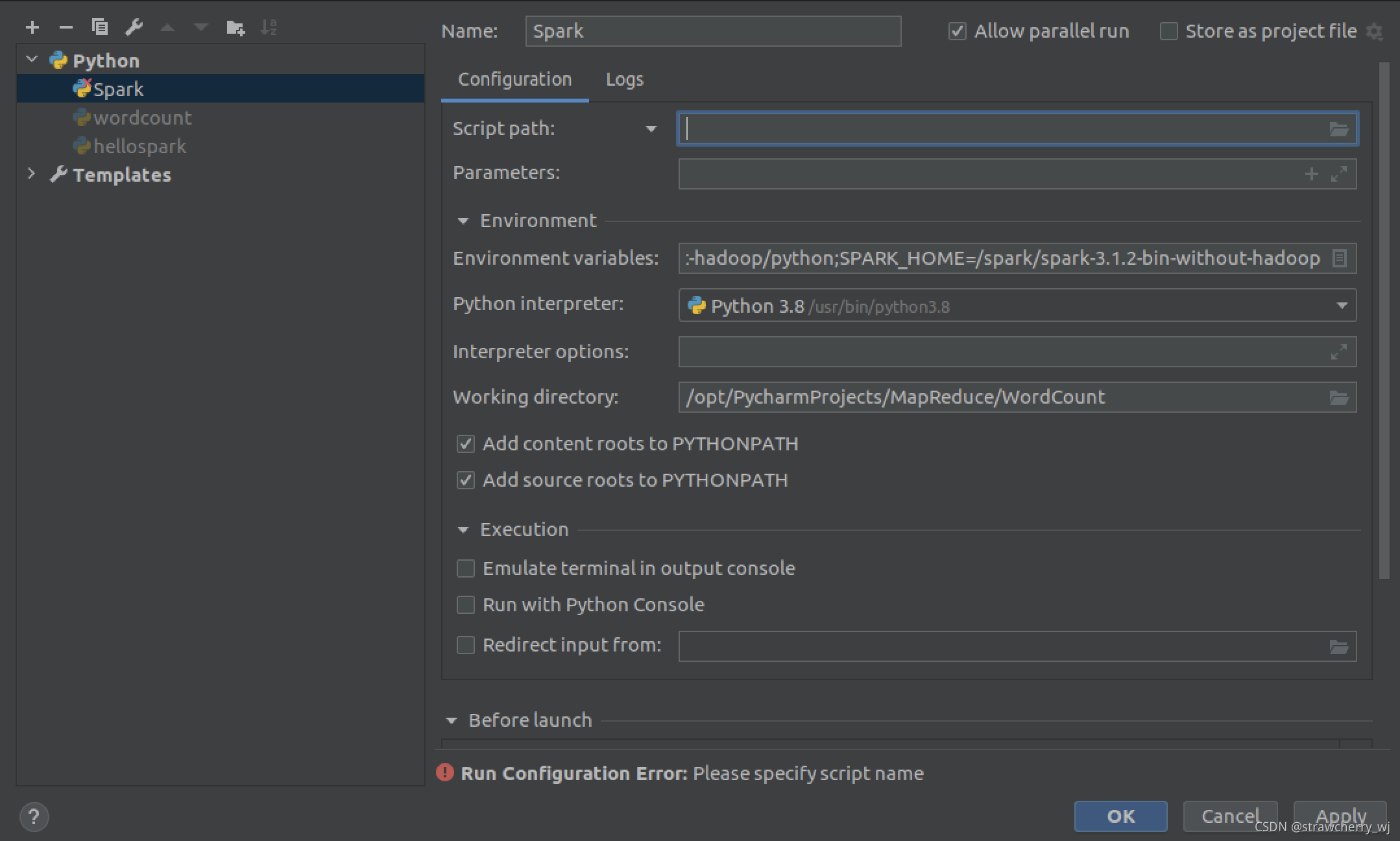
(2)“Add Configuration”配置页面下方出现Run Configuration Error: Please specify script name的问题,在script path中加入一个脚本的绝对路径,就可以正常运行所有的.py脚本文件了。
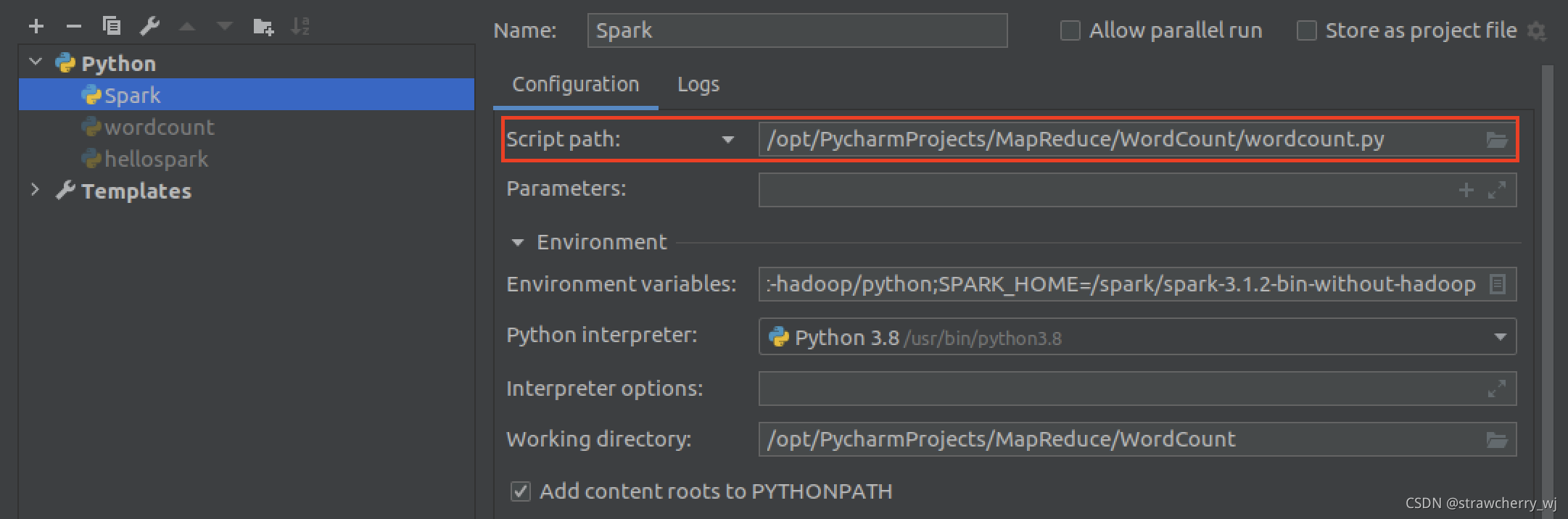
(3)接着在“Environment variables”一栏点击右边按钮进行环境变量配置。
配置spark和pyspark环境变量,命名为SPARK_HOME和SPARKPYTHON,值分别为Spark安装的路径以及pyspark的路径
SPARK_HOME=/spark/spark-3.1.2-bin-without-hadoop
PYSPARK_PYTHON=/spark/spark-3.1.2-bin-without-hadoop/python
点击OK,完成环境配置。

(4)导入相关的库(pyspark模块)
A.点击菜单栏”File”–>”Setting”–>”Project Structure”中点击右上角”Add Content Root”
进入spark安装目录下的python/lib中导入两个压缩包
点击OK,完成配置。

B.安装py4j
pip install py4j
(5)使用Pycharm运行pyspark程序:
ex1.创建wordcount.py程序文件输入以下代码:
#-*- coding:utf8-*-import os
os.environ['JAVA_HOME'] = '/java/jdk1.8.0_261'
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf=conf)
inputFile = "hdfs://localhost:9000/user/MapReduce/test.txt" # 读取hdfs文件
textFile = sc.textFile(inputFile)
wordCount = textFile.flatMap(lambda line : line.split(" ")).map(lambda word : (word, 1)).reduceByKey(lambda a, b : a + b)
wordCount.foreach(print)
运行成功

ex2.创建lettercount.py程序文件输入以下代码:
from pyspark import SparkContextsc = SparkContext()logData = sc.textFile("hdfs://localhost:9000/user/MapReduce/test.txt").cache()numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
运行成功

如果运行时出现Cannot run program “/spark/spark-3.1.2-bin-without-hadoop/python”: error=13, Permission denied的问题
本系统python安装在/usr/bin/python3,如果指定了python3的软连接,可以直接使用python3。
修改Environment Variables:
export PYSPARK_PYTHON=/usr/bin/python3

参考链接:https://blog.csdn.net/yhchj/article/details/105923358
五、Spark上实现BP算法并行化
目前已实现:
本地MapReduce实现SGD
Spark实现WordCount
目标任务:
Spark上MapReduce实现SGD
总结:
Python实现MapReduce框架,无法做到在Hadoop上数据并行运行模型,只能从HDFS上取数据
在spark上使用Python编程,代码多一点,且可以做到数据并行训练
这篇关于【神经网络并行训练(上)】基于MapReduce的并行算法的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







