本文主要是介绍点云transformer算法: FlatFormer 论文阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码:
https://github.com/mit-han-lab/flatformer
论文:
https://arxiv.org/abs/2301.08739
[FlatFormer.pdf]
Flatformer是对点云检测中的 backbone3d部分的改进工作,主要在探究怎么高效的对点云应用transformer
具体的工作如下:
一个缩写:**PCTs 即point cloud transformers**
首先作者分析了点云transformer速度慢的原因(第三章):
最简单粗暴的是全局PCTs, 即对点云使用transformer的方式就是将每个点作为一个token,然后对一个pcd中所有点做multihead attention
比如一个pcd有10万个点,那就是10万个点做multihead attention计算,会很慢,复杂度为O(N2D),N是点数,D是每个点的特征通道数。作者分析了下,当点数到32k时,在NVIDIA A6000 GPU耗时就达到了1s,可见有多慢: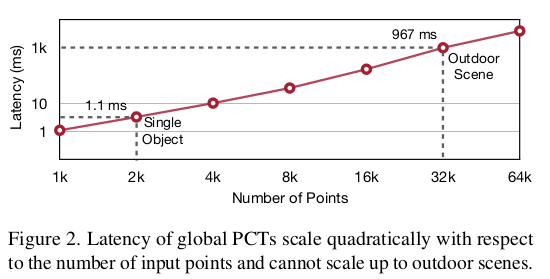
然后,为了降低耗时,有人提出了局部PCTs, 即对全局一共N个点,每个点都选择它附近的K个点做multihead attention计算,复杂度就变成了O(NK2*D),N是点数,D是每个点的特征通道数,K是一个点附近点点数。然而,局部PCTs在邻居点准备方面存在显著的开销。由于点云的稀疏性和不规则性,涉及两个主要步骤:
- 找到每个点的邻居。
- 将数据从N×D格式重构为应用MHSA所需的N×K×D格式。
这些步骤很慢,需要大量时间。例如,在VoTr模型中,为Waymo上的单个场景准备邻居的步骤需要22毫秒(即总运行时间的36%),这已经比整个CenterPoint模型更慢。对于Point Transformer(PT)模型,准备邻居的成本可能占运行时间的高达70%。局部PCTs的单个层中的此开销可能超过CenterPoint模型的总运行时间。
然后又有人提出了窗口PCTs,
SST(Swin Transformer in Point Cloud)是一种基于窗口的点云变换器,受到了Swin Transformers在各种视觉识别任务中取得的巨大成功的启发。其中,SST是代表性的工作之一。它首先将点云投影到鸟瞰空间(bird’s-eye-view, BEV),然后将BEV空间分割为形状相同且不重叠的窗口,并在每个窗口内应用MHSA(multihead attention)。与Swin Transformer类似,SST使用窗口移动来实现窗口之间的信息交换。
与图像不同,点云在空间中是稀疏且非均匀分布的。因此,每个窗口中的点数不同,并且可以相差两个数量级。由于普通的MHSA核心无法有效支持可变序列长度,SST将大小相似的窗口分批处理,并在每批中将所有窗口填充到批中的最大组大小(即填充到相同的长度)。然后,它单独在每个批次中应用MHSA。在实践中,这种填充引入了Waymo上1.7倍的计算开销。更糟糕的是,将点分配到相等的窗口还引入了显著的延迟开销:在Waymo上,每个场景需要18毫秒,甚至比CenterPoint模型的总运行时间还要慢。综上所述,填充和分区的开销使得SST不太适合硬件。
最后,作者基于上面这些问题,提出了自己模型(第四章): Flatformer
作者的核心工作可以用下面这个图来展现: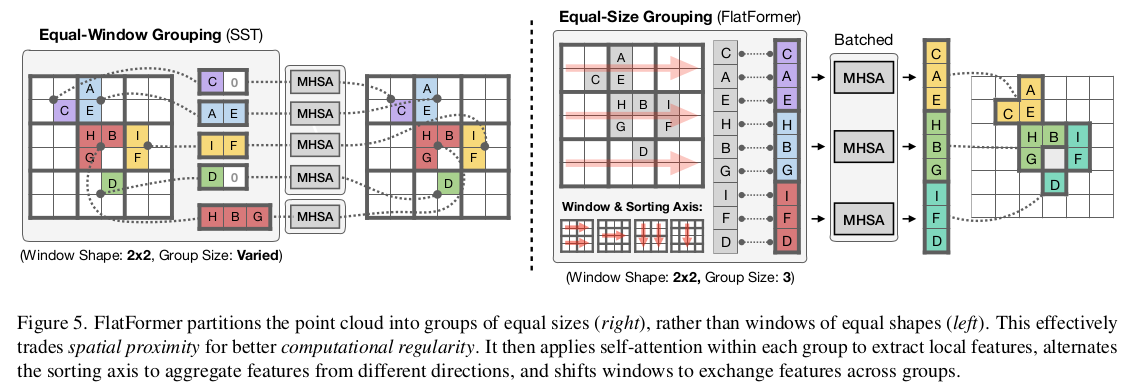
FlatFormer的基本构建块是Flattened Window Attention(FWA)。
我们只要看上面这个图的右半部分就行了,左半部分是作者用来做对对比的不好的方案
如图5r所示,FWA采用基于窗口的排序来展平点云,并将其分割为等大小的组,而不是等形状的窗口。这自然解决了组大小不平衡的问题,并避免了填充和分区的开销。
FWA然后在组内应用自注意力来提取局部特征,交替排序轴以聚合来自不同方向的特征,并移动窗口以在组之间交换特征。最后,作者提供了FWA的一个实现,进一步提高了其效率并减少了开销。
这篇关于点云transformer算法: FlatFormer 论文阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








