本文主要是介绍靠近用户侧和数据,算网融合实现极致协同,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

游弋自如的生产力,在边缘。
IMMENSE、36氪|作者
1846年1月,纽约。
一行长短不一的电码顺着通讯线路飞往130公里开外的费城,这是华尔街的巨头们首次使用电报传输讯息,更具有金钱意味的是,电力通讯的成功,彰显着电力从那一刻起开始成为新的生产力,无数新经济的可能性将会接踵而至。
在那之后的50年中,电力不断得以普及,美国的重工业开始替代轻工业,电气、石油、化学等新兴产业也诞生于电力的基础上。
近200年后的今天,算力成为新的生产力,算法成为新的生产关系,生产资料即是数据。
但,正如电力花费了50年才走进人类生活,算力离无处不在也还有一定距离,最根本的原因在于:算力,是不够用的。
当下对于科技的最佳畅想中,进入元宇宙是必然。更有专家称:“当前这种状况与20世纪90年代初期的互联网一模一样。如果我们不能积极参与其中,就可能错过元宇宙最佳机遇期。”
而想要在元宇宙中开一场演唱会、打一场沙滩排球,或是看一场画展,都对算力提出了天翻地覆的要求。有业内人士曾估算,如果将现在的算力提升1000倍,才有可能达成《头号玩家》中的丝滑之感。
那么,在有限的算力下,如何最大化发挥?让算力不只存在于巨星的闪耀,而是变为繁星之境呢?

01 跳动的算力,边缘把握的脉搏
“我希望,对神经系统所作的更深入的数学研讨,会影响我们对数学自身各个方面的理解。”计算机之父冯·诺依曼在1958年出版的《计算机与人脑》一书中如此写道。
当我们思考“需要怎样的算力基础设施”这个问题时,不妨和冯·诺依曼一样,同样回归计算的生物学本源,将计算机与神经系统类比,来获得灵感。
就像我们用眼睛、耳朵和双手去感受世界,并对外界环境做出反应一样,在数智经济时代,海量、多类型的数据,在工业、医疗、交通等丰富的场景中产生,同时也需要对这些数据进行智能分析,快速完成智能决策以指导生产实践。
中国信息通信研究院在2022年发布的《中国算力发展指数白皮书》中指出,2016-2021年我国算力规模平均每年增长46%,对中国经济社会和产业能级的带动是大势之向。
面向庞大的数据处理,若选择将海量、需实时处理的数据传回云计算中心,不仅会产生高昂的带宽成本,还会因远距离的传输造成极大时延,从而影响终端的决策速度和体验。
为了寻找解决方案,可以参考人体神经系统在面对危险场景时,做出敏捷反应的应对模式。在数万年的进化之旅过后,人体给出的“危机处理方案”是遵循“就近”原则。
设想一下,手指被针扎到的瞬间,短暂的1秒内,我们是先缩回手,而后才感觉到疼痛。这是因为“缩手反射”作为简单的非条件反射,是由脊髓发出指令的,不需经过大脑皮层的深度信息加工。这样就大大提升了我们面对可能的危险时,做出反应的效率,从而提升存活概率。
同理,边缘算力也正是在以低延时、低成本,实现边端敏捷作业、业务快速迭代的需求下产生的。由此诞生的边缘云,最大的特征即是“就近”,即靠近用户侧和靠近数据。

具体而言,“边缘”是物、⼈与⽹络数字世界连接的物理位置,它是数字化转型以及⼈、物和企业之间新交互的关键推动因素。当前,边缘计算已呈快速发展之势,它满⾜了对靠近边缘处理数据的⽇益增⻓的需求。
与集中式云计算不同,边缘云可提供弹性扩展的云服务能力,具有快速响应、低延迟和轻量计算等特点,目前成为公有云、专属云、私有云解决方案之后,云计算生态下不可或缺的新拼图。
据权威机构IDC《中国边缘云市场跟踪研究》报告显示,2021年中国边缘云市场规模总计达50.4亿元人民币,其中,边缘公有云服务细分市场占比超过50%。2022上半年,中国边缘云总体市场规模达到30.7亿元人民币,同比增长50.8%,而边缘公有云增速更是高达56.2%。
在迅猛直上的边缘云市场,透过IDC最新数据,可以看到头部玩家聚集,其中,在最核心的公有云服务市场,阿里云边缘云持续占据国内第一,作为一股云上新势力,正在发挥不可小觑的能量。
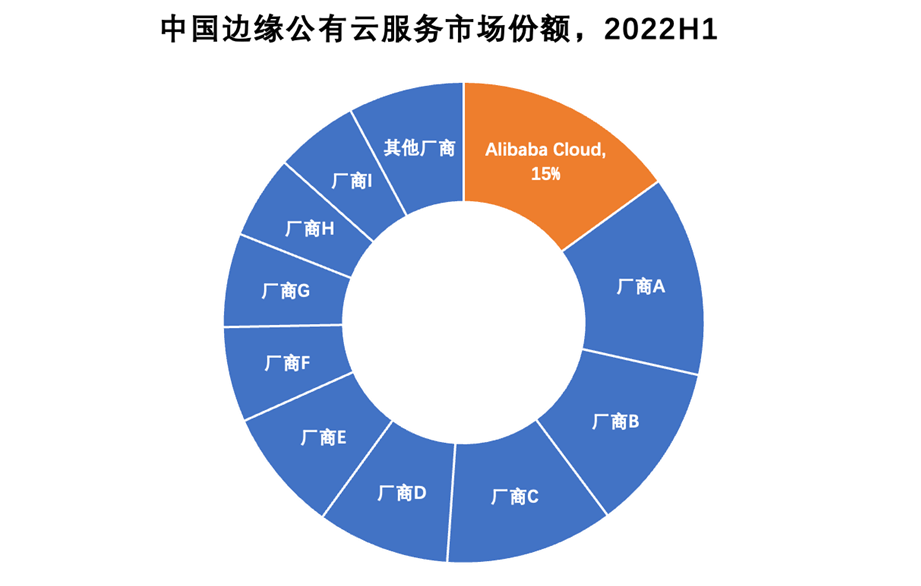
数据来源:《中国边缘云市场跟踪研究,2022H1》
IDC Future Scape也提出预测,到2026年,50%中国企业的CIO将要求云和电信合作伙伴提供安全的云到边缘连接解决方案,可见其未来之势。
02 边缘云织网,算力捕鱼
算力向各行各业渗透的过程,如果只是针对单一企业的需求进行点状渗透,则远远达不到基础设施建设的长效作用。
对于数据来说,如果各个场景节点各自为战、就会变为数据孤岛。而将每一个节点串联成网,才能产生更标准的通用模板,也可以实现更大范围的复用。
边缘计算的核心就是要做到连结和流动,通过数据传输能力、调度能力,合理统筹云边资源,把算力流动起来,再根据场景新需求和工作负载的计算复杂度,分配算力节点,就可以让算力更为精准的满足不同节点的需求,数据也不再是凝固的结点。
而要实现上述的“流动”,关键在于打造算力网络。具体来说,是通过网络贯穿数据生命周期,实现数据与算力的匹配,从而形成一张满足“分发”与“计算”的网,实现边缘与中心、边缘与客户端之间的有效协同,做到算力高效释放、算力灵活调度和边缘最优服务。
如此之上,需要一张“算网”。
在边缘结点算力建设上,阿里云在全球提供500余个强有力的全节点,具备边缘云多态计算、融合存储、边缘数据库等所有云能力,通过合计170万核的通用算力CPU核,和400P FLOPS的异构算力核,来满足边缘场景的算力需求。

在网络及算网融合技术上,阿里云基于全球3200多个边缘节点打造了通信级的全球实时传输网络GRTN。
“算”和“网”双重布局的高效算力网络,带来了两方面的显性优势:
其一,基于树网结合的动态网络,真正实现了延时的极致之巅。
一般情况下,传统网络分发的延迟大约是5-6秒,而GRTN在国内的传输延迟约是100毫秒,延时下降了95%以上,极大提升了响应能力。这背后,是阿里云GRTN升级了分发体系,将传统CDN树状结构中的一级网络、二级网络汇聚后再做分层,相当于从原来的层级网络变为对等网络,再根据当前流或任务,生成最优的传输路径,从而形成树状和网状结合的动态网络。
其二,基于全分布式下沉,真正将运力与算力达到极致融合。
GRTN是基于全分布式下沉的,既有中心也有本地和边缘节点,再加上现场计算或一些融合的资源,阿里云把这些都纳入GRTN管理起来,并按需调用。
不同类型资源按照不同的特性可以划分为中心云资源、边缘云资源和多云融合资源。将不同的异构资源融合,适配不同的业务和场景,从而达到用整个分布式的所有资源构建起一张网,提供传输、计算服务。
具体实践中,GRTN可以在一张网中完成传输和计算任务。当GRTN遇到实时计算流需求时,可以按照用户定义的触发条件,在流节点附近有资源的容器纳管平台,进行匹配计算,处理之后再推回到本节点,完成接下来的分发。
这一高效机制,离不开阿里云分布式容器平台的底座,它能够弹性、可扩展地实现中心、边缘等多个节点的异构资源纳管,并辅以算子的托管和触发条件自定义控制。基于此,才有了GRTN可实现Serverless标准的集算子发布、托管、触发、升级于一体的分布式计算平台。
正所谓,边缘的网络是边缘存在的根本,而算力场景在边缘发生、在云边之间协同。
03 繁星之境,普惠之光
从商业的本质来说,无论技术应用多前瞻、数据指标多光鲜,如果无法为更大公约数的企业、用户使用,都只是象牙塔里面的一纸理论。
普惠的最大感知,游走于大众之端。
阿里云边缘云服务的冬奥会、淘宝天猫为例,大量H5页面渲染的计算工作从源站SSR服务器剥离出来,前置到了边缘节点上。简单来说,即是客户端请求到达边缘,由边缘节点渲染拼接出完整的Web页面并返回给客户端加载。由于边缘节点非常靠近客户端,极大缩短了网络链路,边缘渲染让H5页面加载耗时降低50%以上,直线提升了用户的流畅感官体验。
更重要的是,冬奥会、淘宝天猫这类在全球范围开展的业务,单一的SSR源站很难确保全球每个区域的访问都有好的网络质量,那么将渲染服务前置到全球覆盖的边缘节点,可保障每个区域的用户体验。
业务的革新之象,是普惠的开端。
过去,由于缺乏全域的算力覆盖和多形态的算力支持,很多创新场景受限于能力和成本,最终空有创意而难以落地。而如今,边缘的强大算力可以完成终端算力上移或云上算力大量下移,支持更多创新场景走上良性发展的轨道。
阿里云边缘云基于算力和网络基础设施的能力延展,结合自有飞天操作系统的技术积累,在边缘,云网融合的能力得到极大沉淀。算网融合,在边缘结点之间,在边缘和中心Region之间、在边缘和客户端之间,实现极致协同。恰恰基于此,企业能更好地满足场景化的用户需求,做自如的算力流动,而这种流动的灵活性同样促进了创新场景的层出不穷。
音视频、云游戏、云渲染、自动驾驶等场景尤为典型、生长也更为显著。近几年,边缘云尤其激发了新锐的云游戏的应用,仅2021一年,阿里云边缘云所带动的云游戏并发峰值就提升了十倍多,也驱动更多用户涌入到云游戏行业而不断革新。与此同时,在自动驾驶领域,阿里云边缘云所打造的车云协同能力,通过异构资源多节点部署,实现车机和终端就近接入时延小于20ms,破解行业之困。

从革新到落地,直面而来的一定是成本。
边缘云通过云边协同部署,将数据分发和上传处理终结在边缘,大幅缩短数据搬运的距离,真正实现了对业务综合成本的优化。
以支付宝App为例,每次的App启动都伴随着一次版本同步的请求,这类逻辑简单但并发巨大的请求,往往需要数百台服务器支撑,并且需要根据各类大促活动做好资源的扩缩容管理以保障业务正常。而现在,这类超高并发但逻辑简单的API服务往往直接部署在边缘节点,阿里云遍布全球的3200个边缘节点有充足的计算和存储资源,且具有天然的弹性,能保障所有的请求分到有计算资源的边缘节点进行处理,而无需人工扩容服务器集群,同时也极大减少了往返中心服务器的请求和流量,用普惠的边缘算力和流量的云-边-端架构,可降低80%的计算和流量成本。
成本、革新、体验,这一切让算力不再高高居上,而有了平凡的视角和支力。
在云计算基础设施服务方面,阿里云边缘云基于统一的飞天底座,提供一云多芯、一云多态的云计算架构,从中心向边缘辐射,让算力无处不在。
据IDC最新数据,2021-2026年边缘云市场年均复合增长率达到40%以上,除了基于边缘云资源的传输与分发体系,越来越多边云协同场景的出现、以及传统行业用户对“即服务”模式接受程度的提高,正在持续为市场注入活力。
与此同时,来自Gartner的《Competitive Landscape: Hyperscale Edge Solu-tion Providers》报告也提出最新预测,“到2025年,超过70%的组织将为其⾄少⼀个边缘计算系统,部署超⼤规模云边缘解决⽅案,并会结合其云部署,这比例远⾼于2022年的不到15%。”
不得不说,边缘云蓄势待发,中国的边缘云技术也已经走在了世界的最前沿。而阿里云边缘云的规模升级,也代表着中国边缘云行业的缩影。
未来,由“边缘”创造的万象新生,如繁星之境,不可估量。

04 结语
1882年,美国的第一座发电站珍珠街电站开始运行,爱迪生点亮了84个用户的400盏白炽灯。直到1887年,美国直流发电站数量达到121座,电力,才真正成为主要生产力。
大型应用是生产力得以变动的基础,而被刺激的泛在需求让这成为可能。供给和需求之间,一直以来都是相互促进的关系,今天持续流动于我们身边的算力,也是如此。
毫无疑问,更多新应用场景将会涌现、边缘侧的需求也将不断演进,这都促动着边缘云技术的进化和赛道的拓延。算力网络的搭建并非朝夕之间,在供给和需求的不断打磨中,算力真正广泛应用也还有很长的路要走,而阿里云作为先头部队引领的探索方向,正在为算力成为生产力,按下加速键。

当人类优渥于一种状态,总有想象力来冲破平衡。Cloud Imagine《云想之力》是阿里云联合36氪共同打造的系列报道,旨在探索云计算大背景下爆发的应用场景和新兴技术,以想象的高维碰撞之力,窥探“云”上的无限空间。穿梭回近200年前,在超大应用、大型基础设施的助力下,电力成为主要生产力大约花费了近50年,这一次,当算力成为主要生产力,无数算力网络之下的点点繁星,早已蓄势待发。
这篇关于靠近用户侧和数据,算网融合实现极致协同的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





