本文主要是介绍使用mmrotate对自定义数据集进行检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里写自定义目录标题
- 安装
- 虚拟环境创建与准备
- 安装mmrotate
- 自定义数据集
- 标注数据与格式转换
- 数据集划分与大图像切片
- 训练与测试
- 修改配置文件
- 执行训练
- 进行测试
- 鸣谢
安装
mmrotate是一个自带工作目录的python工具箱,个人觉得,在不熟悉的情况下,还是每次使用时都git一个新的下来为好。
虚拟环境创建与准备
首先,确保自身已经安装了Anaconda,然后执行以下命令以创建名为openmmlab的虚拟环境:
conda create -n openmmlab python=3.10
随后,进入虚拟环境:
conda activate openmmlab
之后,去pytorch官网下载gpu版本的pytorch,其中package选择使用conda。

本人要执行的命令就是:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
CUDA不必追求最新版本,适合自身硬件环境即可
安装mmrotate
首先,在openmmlab环境中安装基础库:
pip install -U openmim
mim install mmcv-full
mim install mmdet\<3.0.0
随后,安装mmrotate,因为本人进行的是旋转框检测,所以需要对mmrotate进行开发和参数重写,因此不直接采用pip install mmrotate这种安装,而是采用以下:
git clone https://github.com/open-mmlab/mmrotate.git
cd mmrotate
pip install -v -e .
自定义数据集
标注数据与格式转换
采用labelme将标注成四边形,生成json文件。本检测中mmrotate使用DOTA数据集格式,因此需要进行一次格式转换,转换为如下的DOTA数据集格式并存储于txt文件内:
x1, y1, x2, y2, x3, y3, x4, y4, object_classname, difficult
x1, y1, x2, y2, x3, y3, x4, y4, object_classname, difficult
...
其中x1,y1为第一个点的坐标,x2,y2为第二个点的坐标,以此类推。object_classname 为类别名,中间不要有空格,difficult为难度,一般0或1即可,有些情况下会出现2。
关于DOTA的格式转换,我参考了这篇博客,在此对转换过程略过。
通过labelme标注产生的x1等数字可能是浮点数,这并不会影响检测效果。
数据集划分与大图像切片
由于我采用的是几个遥感图像场景,尺度非常之大,而数量又很少,因此在进行进一步操作前,先手动将其中几景划分为train集,几景划分为test集,分别放在不同的文件夹内。
在/tools/data/dota/split/split_configs/目录下找到ss_train.py、ss_val.py,主要修改img_dirs、ann_dirs,sizes,save_dir,save_ext这几个参数
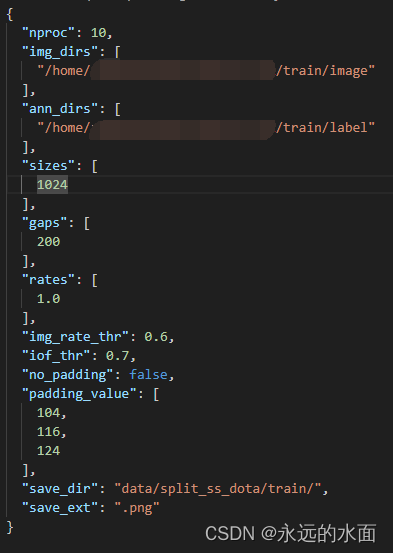
随后,执行以下命令以完成数据集切片:
python tools/data/dota/split/img_split.py --base_json tools/data/dota/split/split_configs/ss_train.json
# AND
python tools/data/dota/split/img_split.py --base_json tools/data/dota/split/split_configs/ss_val.json
切片完成后的数据集的样本数会非常大,但是对于大场景,尤其是遥感影像来说,很多切片内都是空白的,直接将其输入到model里进行训练未免效率过于低下,因此对数据集做一次精简,排除无标签的数据:
import os
directory = '/path/to/your/train/annfiles'
for filename in os.listdir(directory):if filename.endswith('.txt'):filepath = os.path.join(directory, filename)if os.path.isfile(filepath):with open(filepath, 'r') as file:# 使用 seek 和 tell 来判断文件是否有内容initial_position = file.tell()file.seek(0)content = file.read(1) # 只读取一个字节file.seek(initial_position) # 回到初始位置,不影响后续操作# 如果内容为空或只有一个换行符(有些空文件可能含有一个换行符)if not content or content == '\n':# 要对空文件执行的操作if os.path.exists(filepath) and os.path.isfile(filepath):try:os.remove(filepath)print(f"成功删除文件: {filepath}")except Exception as e:print(f"删除文件时发生错误: {e}")else:print(f"文件 {filepath} 不存在或不是普通文件,无法删除")filepath2=filepath.replace('annfiles','images').replace('.txt','.png')if os.path.exists(filepath2) and os.path.isfile(filepath2):try:os.remove(filepath2)print(f"成功删除文件: {filepath2}")except Exception as e:print(f"删除文件时发生错误: {e}")else:print(f"文件 {filepath2} 不存在或不是普通文件,无法删除")
训练与测试
修改配置文件
具体来说,有以下几处地方需要修改:
- 在train.py中将config改为–config,然后添加default值,指向configs/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90.py:
parser.add_argument('--config', default='configs/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90.py',help='train config file path')
- 在train.py中将work-dir改为–work-dir,然后添加default值,指向run
parser.add_argument('--work-dir', default='run',help='the dir to save logs and models')
- 在rotated_faster_rcnn_r50_fpn_1x_dota_le90.py中将numclass改为自己数据集的种类数
- 在mmrotate/datasets/dota.py中修改自己的类别的名字,仅一个类时,末尾需要加逗号
- 在configs/base/datasets/dotav1.py中修改数据路径,其中test数据集无需annfiles
- 在/home/zanyinkai/mmrotate/configs/base/schedules/schedule_1x.py中修改自己的epoch等参数
执行训练
python tools/train.py
进行测试
python tools/test.py --show_dir 'work_dir/vis'
鸣谢
本人在进行mmrotate时,参考了以下内容:
基于MMRotate训练自定义数据集 做旋转目标检测 2022-3-30
MMRotate文档
这篇关于使用mmrotate对自定义数据集进行检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






