本文主要是介绍第97讲:MHA高可用集群模拟主库故障以及修复过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.分析主库故障后哪一个从库会切换为主库
- 2.模拟主库故障观察剩余从库的状态
- 2.1.模拟主库故障
- 2.3.当前主从架构
- 3.修复故障的主库
- 3.1.修复主库
- 3.2.当前主从架构
- 3.3.恢复MHA
1.分析主库故障后哪一个从库会切换为主库
在模拟MHA高可用集群主库故障之前,我们先来分析一下,主库故障后,谁会切换为新主库。
Manager组件选举新主库的过程:
Manager组件选举新主库有三种算法:
- 当主库故障后,如果配置文件中有声明哪个节点强制为主库,该节点会强制提升为新的主库。
- 当主库故障后,判断剩余从库谁的数据最新(根据Position或者GTID来判断),谁复制主库的数据最多,最多的节点提升为新主库。
- 当主库故障后,如果剩余从库的Position或者GTID都一一致,也就意味着剩余从库复制的数据都一样多,那么此时就会根据配置文件中的书写顺序,从上到下,最上面的那个节点会成为新主库。
我们并没有在MHA中配置强制主库的参数,因此第一个算法不会生效,根据所有从库的信息来看,和主库的数据是一模一样的,不存在数据差异,因此第二个算法也不会生效,而在MHA的配置文件中,是根据主从从节点的顺序来书写的,mysql-1、mysql-2、mysql-3,根据第三个算法,那么当主库故障后,mysql-2这个节点的从库会提升为主库。
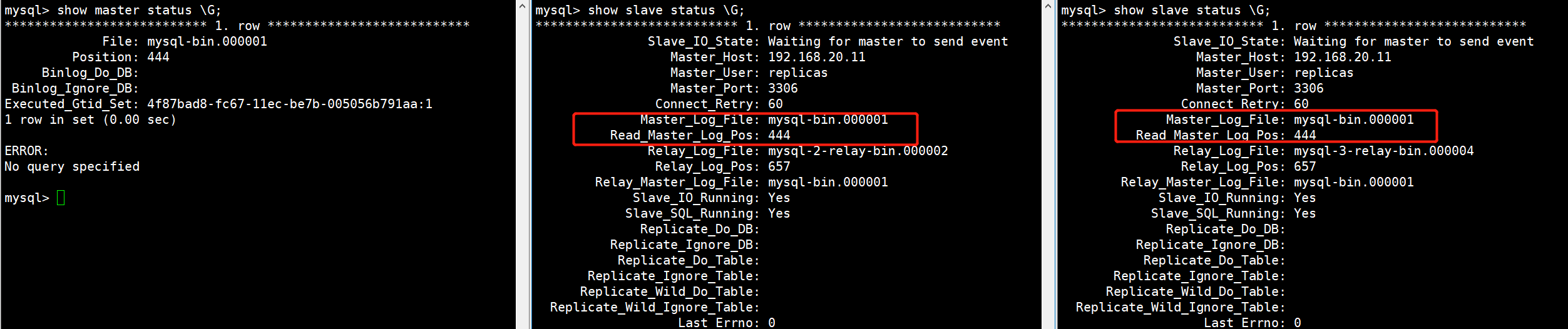
在模拟故障之前,一定要保证MHA是运行的,否则不会切换主从。
2.模拟主库故障观察剩余从库的状态
2.1.模拟主库故障
1)模拟主库故障
[root@mysql-1 ~]# systemctl stop mysqld
2)观察mysql-2中的从库是否会成为新主库
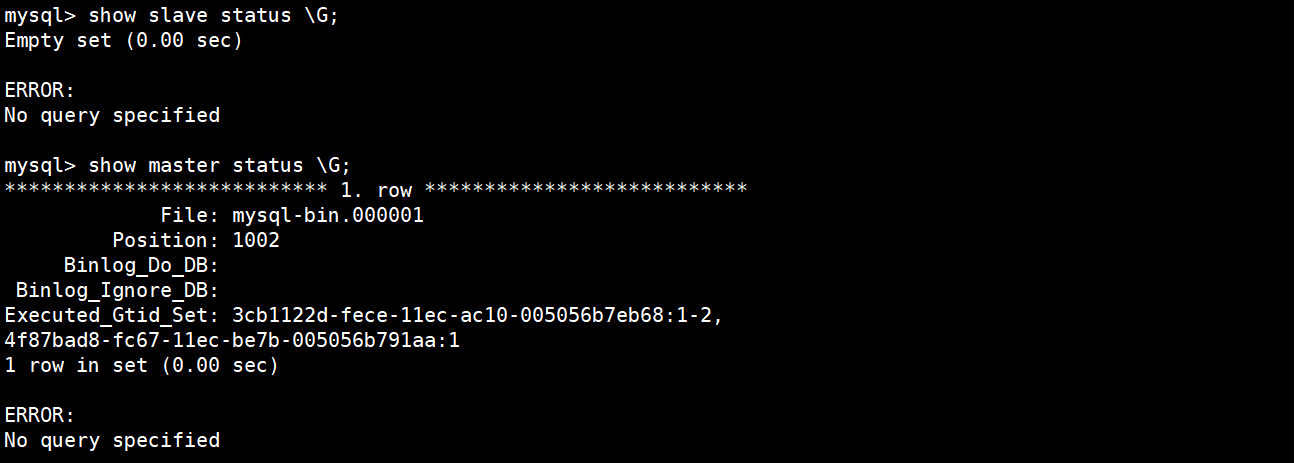
mysql-2中的从库已经成为新的主库了,当查看slave的状态时,没有任何输出,就表示它是主库。
[root@mysql-2 ~]# mysql -uroot -p123456
mysql> show slave status \G;
Empty set (0.00 sec)ERROR:
No query specified
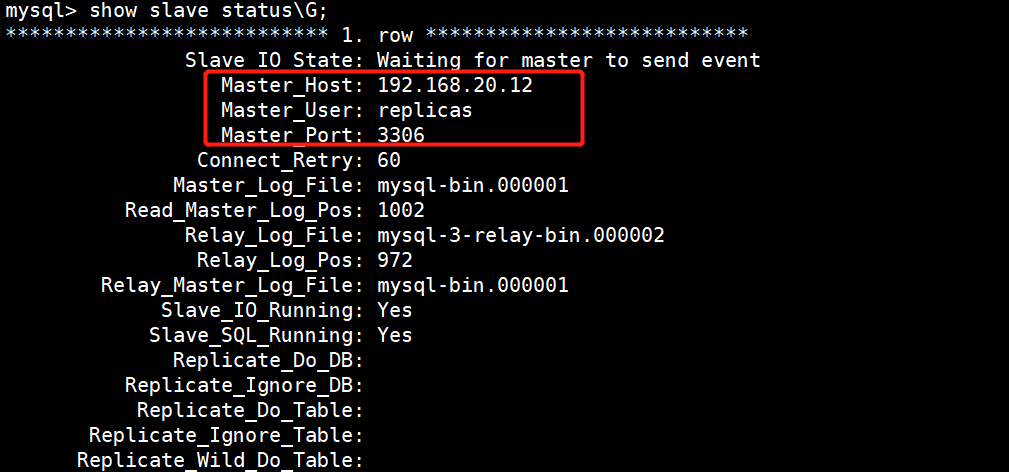
3)观察mysql-3从库的状态信息
此时mysql-3上的从库已经开始复制mysql-2这个新主库了,MHA故障切换成功,保障了高可用
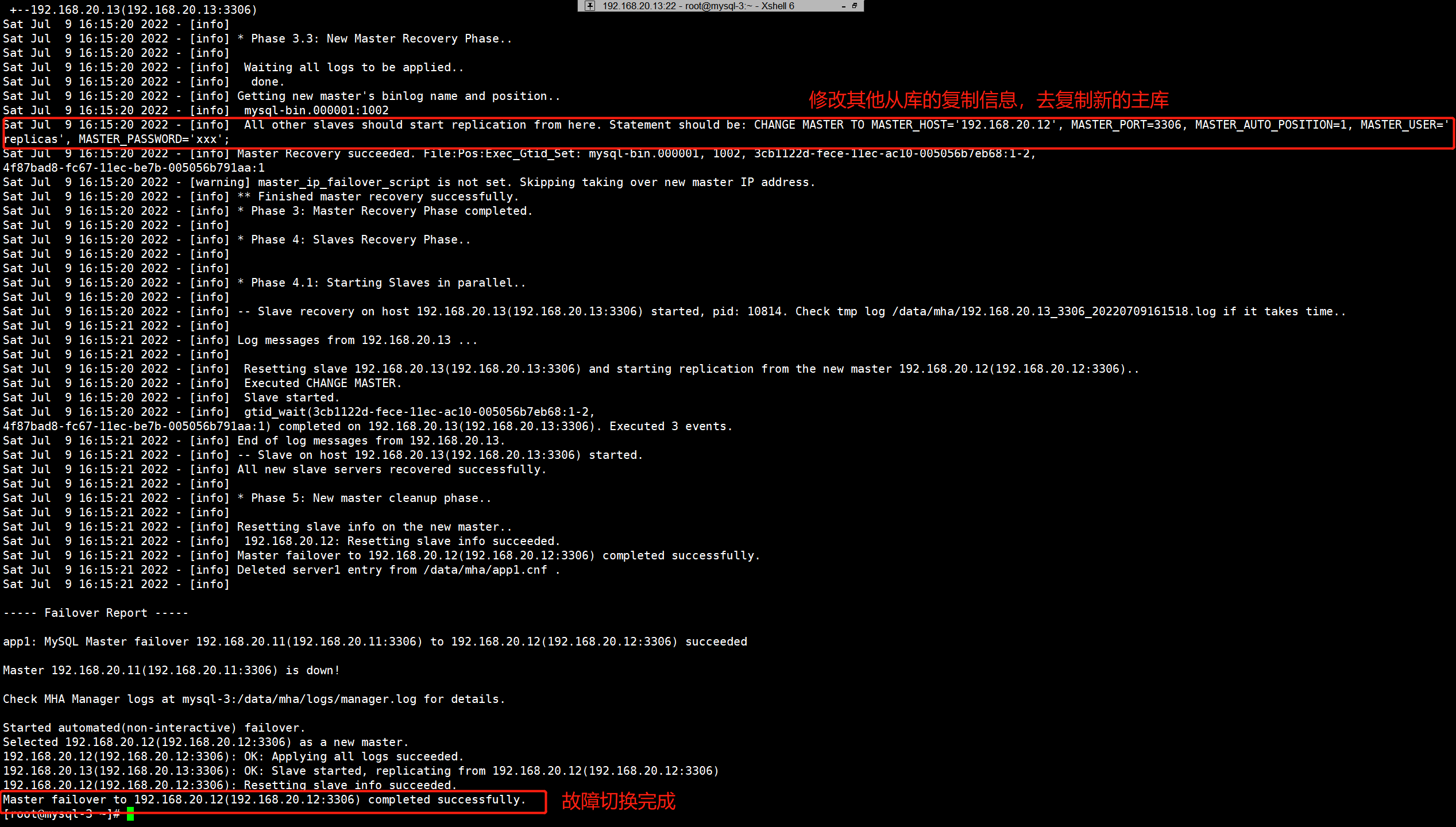
故障切换完成后,MHA会自动自杀,一次性高可用故障切换。

故障切换的过程可以在MHA的日志中看到。
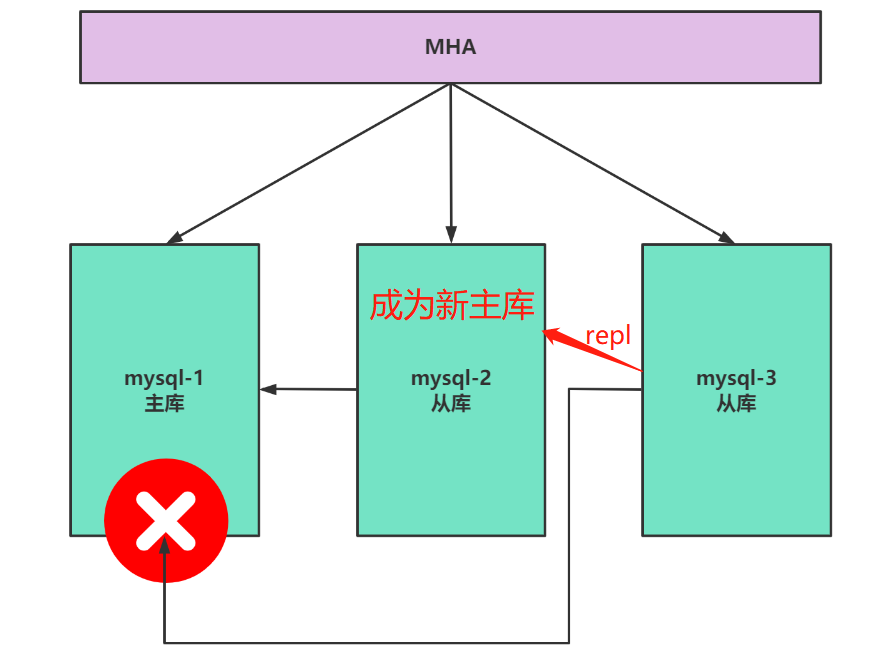
2.3.当前主从架构
主库已经故障,mysql-2成为了新主库,mysql-3复制mysql-2的数据。
3.修复故障的主库
3.1.修复主库
当我们得知主库故障,并且顺利进行故障切换,使从库成为主库,重新设置了主从关系,保证业务的高可用之后,我们就需要去修复主库了,MHA已经将mysql-2这个从库提升为新的主库了,我们也不需要去改变现有的主从关系,直接让恢复的主库复制现有的主库即可,避免破坏现有主从关系,导致业务中断。
MHA切换主库,就好比某个皇帝(大明战神 明堡宗)御驾亲征,最后被俘虏了(主库故障),他的弟弟临危受命当了皇帝(mysql-2成为了新主),结果哥哥重新回来后(主库修复),居然夺门,废了弟弟的皇位(想重新成为主),实在不地道了。
1)修复主库
[root@mysql-1 ~]# systemctl start mysqld
2)配置故障的主库复制新主库mysql-2
关于复制参数,我们可以从mha的日志中获取。
[root@mysql-3 ~]# grep 'CHANGE MASTER TO' /data/mha/logs/manager.log
Sat Jul 9 16:15:20 2022 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.20.12', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='replicas', MASTER_PASSWORD='xxx';
配置故障主库复制新主库。
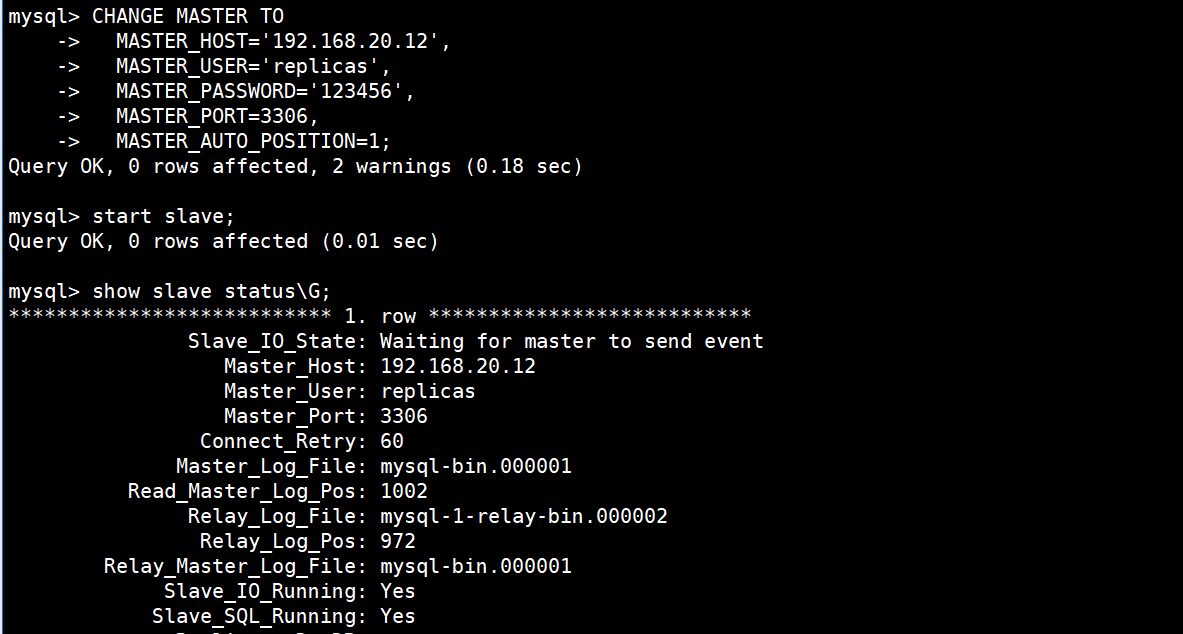
mysql> CHANGE MASTER TOMASTER_HOST='192.168.20.12',MASTER_USER='replicas',MASTER_PASSWORD='123456',MASTER_PORT=3306,MASTER_AUTO_POSITION=1;
mysql> start slave;
故障的主库已经成功的修复完成,并且已经成为mysql-2新主库的从库。
3.2.当前主从架构
mysql-2是主库,mysql-1是故障主库,恢复后成为了mysql-2的从库。

3.3.恢复MHA
MHA在完成一次故障切换后,会自动杀死自己,因此我们需要去恢复MHA,首先将故障的主库重新添加到配置文件中,因为MHA切换时会将故障的节点从配置文件中删除,然后再启动MHA即可。
1)将故障的主库重新加入到配置文件中
[root@mysql-3 ~]# vim /data/mha/app1.cnf
[server1]
hostname=192.168.20.11
port=3306
2)启动MHA
[root@mysql-3 ~]# nohup masterha_manager --conf=/data/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /data/mha/logs/manager.log 2>&1 &
3)查看状态
[root@mysql-3 ~]# masterha_check_status --conf=/data/mha/app1.cnf
app1 (pid:11050) is running(0:PING_OK), master:192.168.20.12
这篇关于第97讲:MHA高可用集群模拟主库故障以及修复过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






