主库专题

MySQL主从复制主库binlog dump线程源码分析
在之前的文章《mysql主从复制io线程源码分析》,我们分析了MySQL从库的io线程工作的主要过程,大致回顾一下,如下: 连接主库发送COM_REGISTER_SLAVE命令注册从库发送COM_BINLOG_DUMP_GTID命令请求拉取binlog 下面将结合源码,分析一下主库接收到从库io线程发送过来的命令后,是如何具体处理的。 MySQL源码版本:5.7.19 原文地址: htt

oracle12c到19c adg搭建(六)切换后12c备库服务器安装19c软件在19c主库升级数据字典后尝试同步
一、安装19c软件 参考文章oracle12c到19c adg搭建(三)oracle19c数据库软件安装 二、原主库尝试通过19c软件启动数据库 2.1复制12c的相关参数文件和密码文件到19c目录 注意:密码文件需要从已切换主库19c传过来 [oracle@o12u19p ~]$ cd /u01/app/oracle/product/12.1.0.2/dbhome_1/dbs/

书生笔记-mysql主库dump线程
《深入理解mysql主从原理32讲》学习笔记 每一个mysql的从库slave都会对于一个 dump线程,如上图的 Binlog Dump GTID . 实际上在启动之前还会和从库的IO线程进行多次的语句交互,然后注册从库,最后才是进行DUMP线程的启动。这些内容会在后续的IO线程中讲解,这里主要讨论的是POSITION MODE模式和GTID AUTO_POSITION MODE模式下的

ADG主库归档丢失,备库测试
ADG主库上归档丢失恢复备库测试模拟了下在主库上丢失归档导致备库出现gap,无需重建恢复备库的情况1制造gap主库ALTER system SET log_archive_dest_state_2 = 'defer';一些dml操作alter system switch logfile;备库此时的mrp是等待log状态SQL> select process,client_process

mysql主库delete一个没主键的表导致从库延迟很久问题处理
一 问题描述 发现线上环境一个从库出现延迟,延迟了2天了,还没追上主库。 查看当前运行的sql及事务,发现这个sql语句是在delete一个没主键的表。 二 问题模拟 这里在测试环境复现下这个问题。 2.1 在主库造数据 use baidd; CREATE TABLE test2(id INT primary key AUTO_INCREMENT); INSERT INTO t

07 | 哨兵机制:主库挂了,如何不间断服务?
文章目录 Redis核心技术与实战基础篇07 | 哨兵机制:主库挂了,如何不间断服务?哨兵机制的基本流程主观下线和客观下线如何选定新主库? Redis核心技术与实战 基础篇 07 | 哨兵机制:主库挂了,如何不间断服务? 如果主库发生故障,直接会影响到从库的同步,因为从库没有相应的主库可以进行数据复制操作。而且,如果客户端发送的都是读操作请求,那还可以由从库继续提供
Oracle Data Guard 主库报--RFS Possible network disconnect with primary database
检查Data Guard 主库,发现log有如下信息: Wed Oct 13 17:05:11 2010 RFS: Possible network disconnect with primary database RFS: Destination database mount ID mismatch [0x4b1b0155:0x4b1b40c1] RFS: client in
Oracle Data Guard 主库 归档文件 删除策略
对于Oracle Data Guard 的Maximum Availability和 Maximum Performance 两种模式下的主库归档文件的删除,必须是在归档文件在备库应用以后才可以删除。 对于Maximum Protection 模式,这种模式的日志是同时写到主库和备库的,所以这种模式下的主库删除归档,没有限制。 可以直接删除。
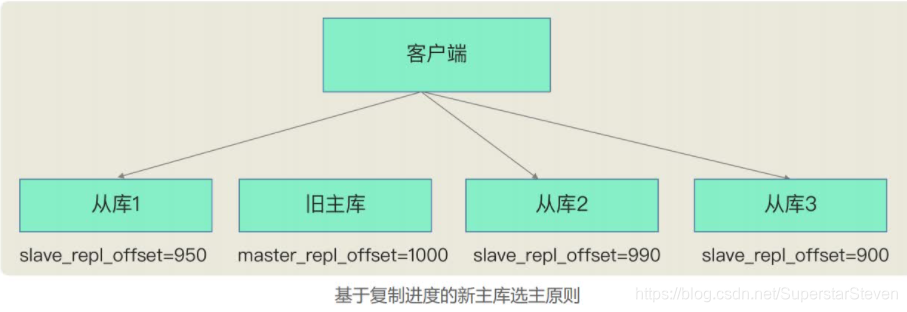
06 | 哨兵机制: 主库挂了, 如何不间断服务
哨兵模式主从数据同步 1. 前言2.哨兵机制的基本流程3.如何选定新主库 1. 前言 无论是写服务中断,还是从库无法进行数据同步,都是不能接受的。所以,如果主库挂了,我们就需要运行一个新主库,比如说把一个从库切换为主库,把它当成主库。这就涉及到三个问题: 主库真的挂了吗?该选择哪个从库作为主库?怎么把新主库的相关信息通知给从库和客户端呢? 这就要提到哨兵机制了

第97讲:MHA高可用集群模拟主库故障以及修复过程
文章目录 1.分析主库故障后哪一个从库会切换为主库2.模拟主库故障观察剩余从库的状态2.1.模拟主库故障2.3.当前主从架构 3.修复故障的主库3.1.修复主库3.2.当前主从架构3.3.恢复MHA 1.分析主库故障后哪一个从库会切换为主库 在模拟MHA高可用集群主库故障之前,我们先来分析一下,主库故障后,谁会切换为新主库。 Manager组件选举新主库的过程: Mana

记录Pgpool主库down的一次紧急修复过程
由于检测高可用,强制处理,导致Pgpool的主库二进制文件损坏,发现PG_XLOG和PG_LOG存在大I属性,无法读写,从备节点SCP一份库文件也是如此。 第一次修复,尝试新装PostgreSQL,然后再pg_dump从备节点把库数据导出下来,然后再灌到新库中,后续再加入到Pgpool集群 测试成功,但是客户反馈无法通过web登录,可以打开界面,故从DBA角度判断是数据不一致导致的,后续系统运
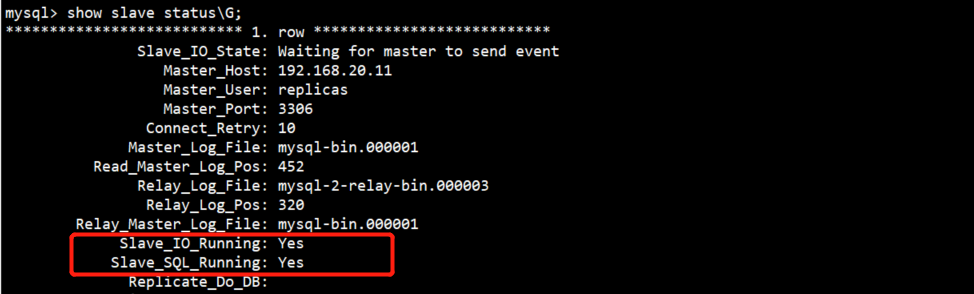
第91讲:MySQL主从复制集群主库与从库状态信息的含义
文章目录 1.主从复制集群正常状态信息2.从库状态信息中重要参数的含义 1.主从复制集群正常状态信息 通过以下命令查看主库的状态信息。 mysql> show processlist; 在主库中查询当前数据库中的进程,看到Master has sent all binlog to slave; waiting for more updates这个信息时,就表示主库一切正常
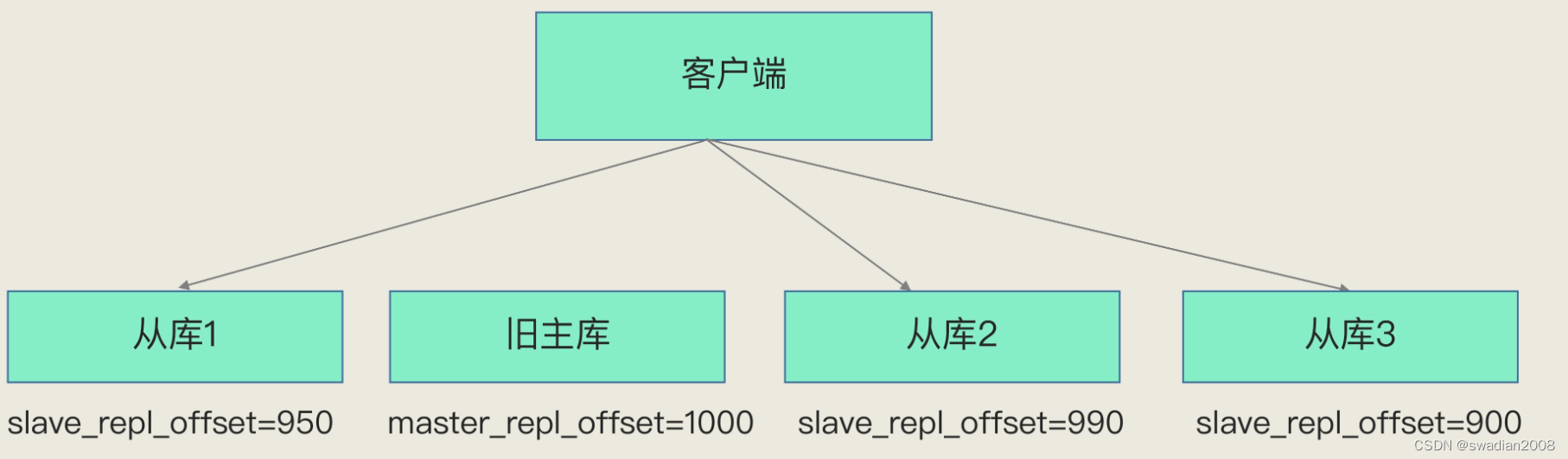
Redis 主库挂了,如何不间断服务?
目录 1、哨兵机制的基本流程 2、主观下线和客观下线 3、如何选定新的主库? 总结 // 你只管前行,剩下的交给时间 在 reids 主从库集群模式下,如果从库发生故障了,客户端可以继续向主库或其他从库发送请求,进行相关的操作,但是如果主库发生故障了,那就直接会影响到从库的同步,因为从库没有相应的主库可以进行数据复制操作了。// 没有主库,从库无
27讲主库出问题了,从库怎么办
在前面的第24、25和26篇文章中,我和你介绍了MySQL主备复制的基础结构,但这些都是一主一备的结构。 大多数的互联网应用场景都是读多写少,因此你负责的业务,在发展过程中很可能先会遇到读性能的问题。而在数据库层解决读性能问题,就要涉及到接下来两篇文章要讨论的架构:一主多从。 今天这篇文章,我们就先聊聊一主多从的切换正确性。然后,我们在下一篇文章中再聊聊解决一主多从的查询逻辑正确性的方法。

pg 模拟主库down机之pg_kaboom
为了测试pg模拟down机,可使用插件pg_kaboom:GitHub - pgguru/pg_kaboom: Devious SQL-based SQL tools to crash your PostgreSQL server $ git clone git@github.com:CrunchyData/pg_kaboom.git$ cd pg_kaboom$ make PG_C

MYSQL主从同步错误(1)主库删除数据导致主从失败的二般解决办法
做MYCAT实验时候,从master主库删掉一行数据,然后又把从库数据也手动删掉了。发现主从同步失效了。在从库看了下状态 mysql> show slave status \G 其中比较关键的三行: Slave_IO_Running: Yes Slave_SQL_Running: No Last_Error: Could not execute Delete_rows even
【故障处理】DG环境主库丢失归档情况下数据文件的恢复
【故障处理】DG环境主库丢失归档情况下数据文件的恢复 1 BLOG文档结构图 2 前言部分 2.1 导读和注意事项 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,~O(∩_∩)O~: ① BBED的编译 ② BBED修改文件头让其跳过归档从而可以ONLINE(重点) ③ OS命名格式转换为ASM的命名格式 ④ DG环境中备库丢失数据文件的
MySQL 8.0 主从复制重建流程(从主库数据文件备份恢复)
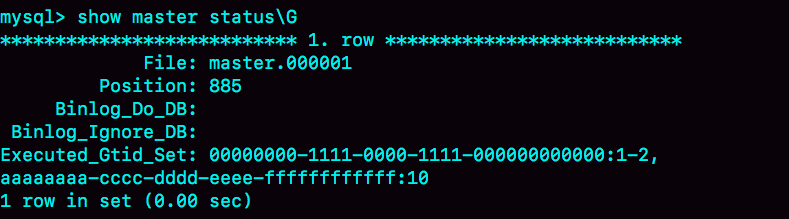
一、需求描述 MySQL主从复制2台数据库已经存在,因为差异太大的原因,所以需要将主库的数据文件备份在从库进行恢复,重新设置主从复制的关系。 二、准备工作 在开始之前我们需要有主库下面的文件 1.主库MySQL数据目录的备份压缩文件 20231105013714.tar.gz 2.备份时主库bin log日志文件的位置,可以通过SHOW MASTER STATUS;查看 三、设置流
rman 增量恢复 dg gap后 主库添加新数据文件
1) On the standby database, 关闭 (MRP) SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL; 2) On the STANDBY DATABASE, 获取备库最小scn值,用作主库增量备份点 : col MIN(CHECKPOINT_CHANGE#) for 999999
Oracle Data Guard_ 主库添加或删除在线重做日志文件
8.3.5 Adding or Dropping Online Redo Log Files 8.3.5 添加或删除现在重做日志文件 Changing the size and number of the online redo log files is sometimes done to tune the database. You can add or drop online
Oracle Data Guard_ 主库重命名数据文件
8.3.4 Renaming a Datafile in the Primary Database 8.3.4 在主库中重命令数据文件(即手动在备库修改相等的变化) When you rename one or more datafiles in the primary database, the change is not propagated to the standby d
Oracle Data Guard_ 主库删除表空间
8.3.2 Dropping Tablespaces and Deleting Datafiles 8.3.2 删除表空间和删除数据文件 When you delete one or more datafiles or drop one or more tablespaces in the primary database, you also need to delete the
Oracle Data Guard_ 主库添加数据文件或创建表空间
8.3 Managing Primary Database Events That Affect the Standby Database 8.3 管理主库能影响备库的事件 To prevent possible problems, you must be aware of events on the primary database that affect a standby