本文主要是介绍深入理解Istio服务网格(一)数据平面Envoy,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、服务网格概述(service mesh)
在传统的微服务架构中,服务间的调用,业务代码需要考虑认证、熔断、服务发现等非业务能力,在某种程度上,表现出了一定的耦合性
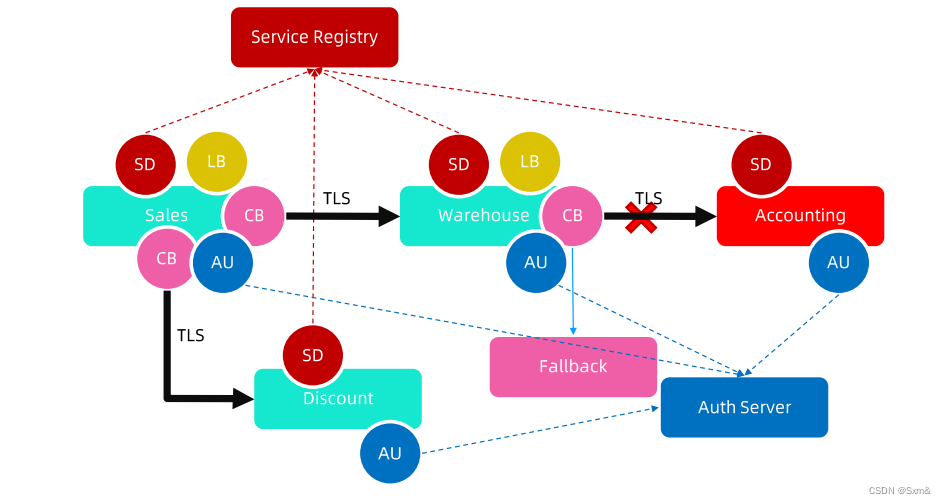
服务网格追求高级别的服务流量治理能力,认证、熔断、服务发现这些能力更多的是平台测的能力。将业务测和平台测能力解耦,开发人员只关心业务测的能力。每个服务实例都有一个代理,服务的入站流量、出站流量都先经过代理,代理不进行业务处理,只做流量转发,因此,传统微服务架构,服务到服务间的调用,转成了proxy到proxy的调用。
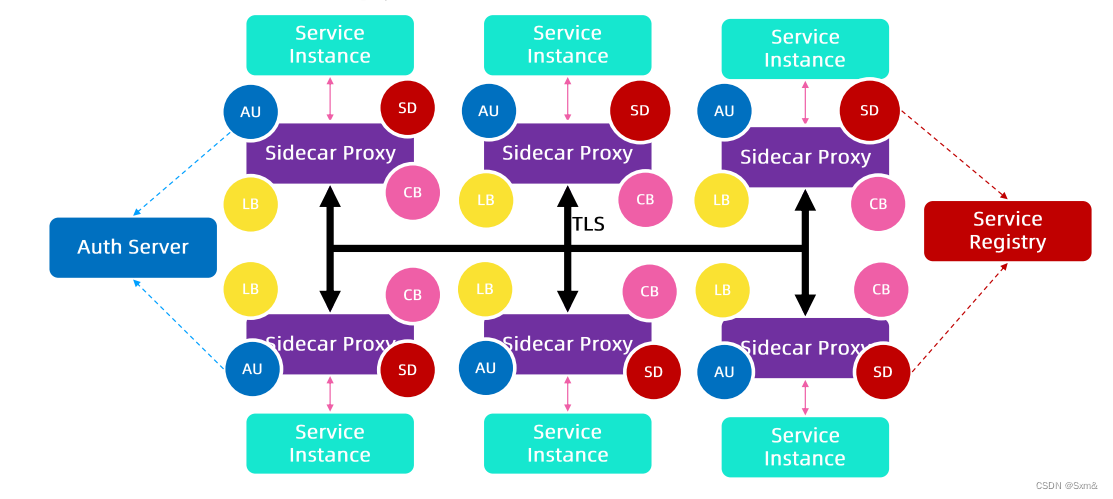
Proxy通常是一种反向代理软件,有强大的流量转发能力。我们前面讲kube-proxy做负载均衡,是利用Linux内核配置iptables规则,做的L4负载均衡,实际上是能力比较弱的负载均衡。由于所有的流量都经过Proxy,基于此,很容易做到监控、熔断、重试、超时处理、负载均衡、认证等能力。
二、Istio架构
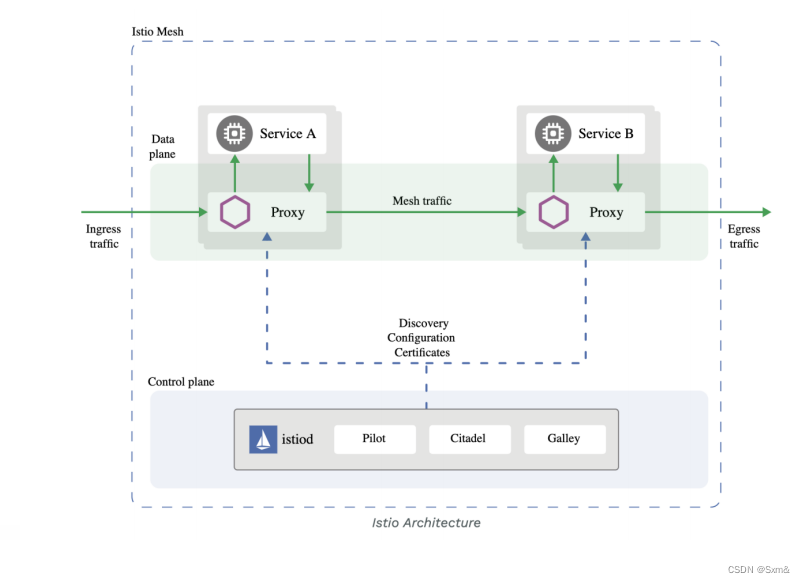
基于Istio的流量治理,控制平面是其istiod组件,而这个proxy角色就是反向代理软件Envoy。istiod负责生成并下发Envoy的配置。通过丰富的路由规则,对流量行为进行细粒度的控制。
三、Envoy
3.1 优势
Envoy在L4和L7都提供了丰富的Filter能力,并且还提供一组可以通过控制平面管理的API(XDS API)。云原生是一个动态的系统,pod的ip并不是固定的,传统的基于静态配置文件加载的方式并不适用。因此Envoy的API可配置性具有很大的优势,控制平面监听到配置需要变更时,控制平面可以主动下发envoy配置,而envoy不需要重新启动,支持hot reload。
3.2 Envoy典型配置
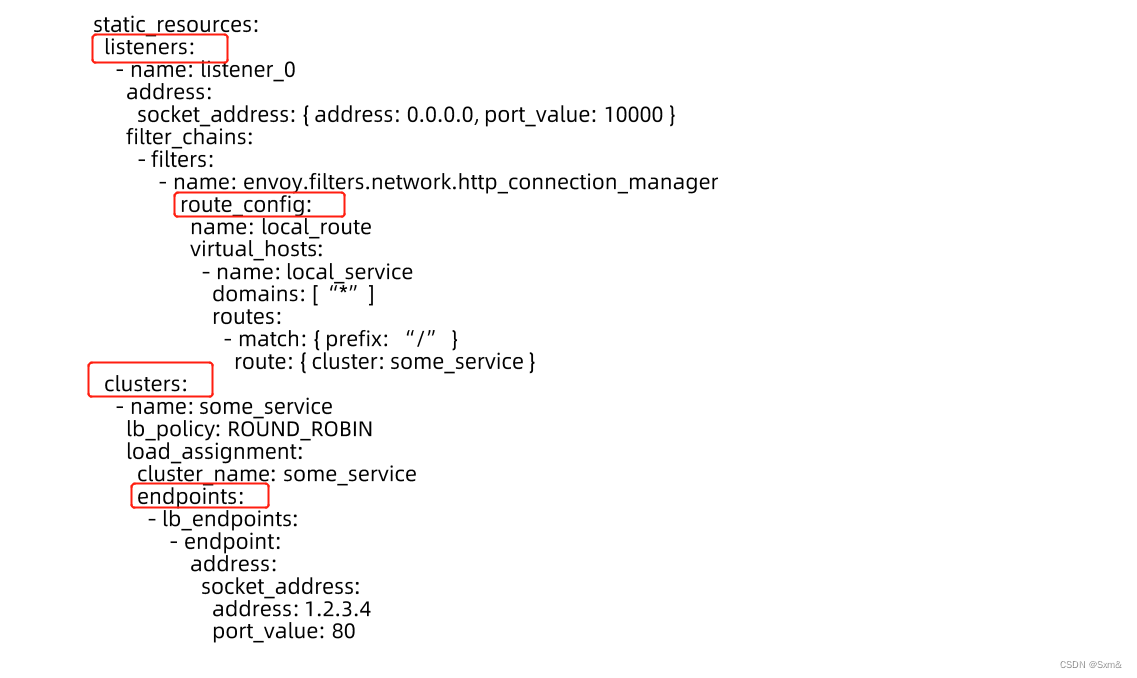
listener定义了本机监听ip和端口,route_config配置了转发规则,cluster对应的是service,endpoint对应的是转发的pod。
3.3 Envoy架构

Main Thread通过XDS API接收控制平面下发的配置,然后将listener、route_config、cluster等各配置项下发至Worker Thread,Worker Thread负责真正接收处理请求流量。
3.4 发布应用
1、创建envoy的配置configmap
kubectl create configmap envoy-config --from-file=envoy.yaml
envoy.yaml:
admin:address:socket_address: { address: 127.0.0.1, port_value: 9901 }static_resources:listeners:- name: listener_0address:socket_address: { address: 0.0.0.0, port_value: 10000 }filter_chains:- filters:- name: envoy.filters.network.http_connection_managertyped_config:"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManagerstat_prefix: ingress_httpcodec_type: AUTOroute_config:name: local_routevirtual_hosts:- name: local_servicedomains: ["*"]routes:- match: { prefix: "/" }route: { cluster: some_service }http_filters:- name: envoy.filters.http.routerclusters:- name: some_serviceconnect_timeout: 0.25stype: LOGICAL_DNSlb_policy: ROUND_ROBINload_assignment:cluster_name: some_serviceendpoints:- lb_endpoints:- endpoint:address:socket_address:address: httpserver-svcport_value: 80
2、部署envoy,并将configmap mount进去
envoy-deploy.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:labels:run: envoyname: envoy
spec:replicas: 1selector:matchLabels:run: envoytemplate:metadata:labels:run: envoyspec:containers:- image: envoyproxy/envoy:v1.21.5name: envoyvolumeMounts:- name: envoy-configmountPath: "/etc/envoy"readOnly: truevolumes:- name: envoy-configconfigMap:name: envoy-config
3、通过envoy访问应用

这篇关于深入理解Istio服务网格(一)数据平面Envoy的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









