本文主要是介绍卷积神经网络(CNN)使用PyTorch实现卷积神经网络对CIFAR-10数据集进行图片分类(代码➕注释),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、CNN概述
二、CNN网络结构
三、CNN常见名词
四、使用PyTorch实现卷积神经网络对CIFAR-10数据集进行图片分类
一、CNN概述
卷积神经网络 ( Convolutional Neural Network,CNN) 作为人工神经网络中一种常见的深度学习架构,该网络是受到生物自然视觉认知机制启发而来,是一种特殊的多层前馈神经网络, CNN 是由简单的神经网络改进而来,使用卷积层和池化层替代全连接层结构,卷积层能够有效地将图像中的各种特征提取出并生成特征图。广泛应用于图像识别、图像分类等领域 ,具有良好的扩展性和鲁棒性,截至目前,CNN 的深度呈不断增加的趋势。
CNN在图像分类识别中要做的事情是:给定一张图片,图片中是牛还是马不知道,是什么牛也不知道,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是牛的话,那是什么牛?
【1】鲁棒性也称作健壮性(英语:Robustness):一个系统或组织有抵御或克服不利条件的能力。鲁棒性则常被用来描述可以面对复杂适应系统的能力,需要更全面的对系统进行考虑。
二、CNN网络结构

1)输入层(Input layer),众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量。
2)卷积层:是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features,每一个feature就像是一个小图,对图像和滤波矩阵做内积(逐个元素相乘再求和)的操作就是所谓的“卷积”操作,也是卷积神经网络的名字来源。
【1】卷积:滤波器filter与数据窗口做内积(在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据)
3)池化pool层:保留主要的特征,进一步删减冗余参数,提高特征提取效率。池化,简言之,即取区域平均或最大。
5)全连接层:就是把特征整合到一起(高度提纯特征),方便交给最后的分类器或者回归。
三、CNN常见名词
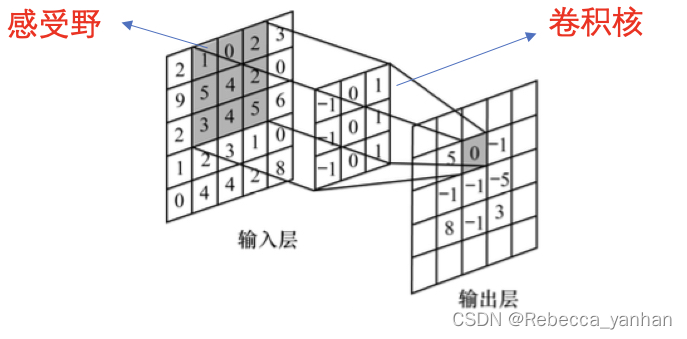
1)感受野:某一个输出层的一个元素对应输入层的区域大小,被称为感受野,即输出层的一个元素在输入层上的映射区域。
2)激活函数:常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。
四、使用PyTorch实现卷积神经网络对CIFAR-10数据集进行图片分类
主要步骤是:
1. 加载和预处理CIFAR-10数据集
2. 定义卷积神经网络 ConvNet 模型
3. 定义交叉熵损失函数和SGD优化器
4. 训练模型50个epoch
5. 打印训练损失并完成训练
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt# 训练数据
transform = transforms.Compose([transforms.ToTensor(), # 转为tensortransforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 归一化trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True) # 测试数据
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 卷积神经网络定义
class ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x))) # 2层卷积池化x = self.pool(F.relu(self.conv2(x))) # 2层卷积池化x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xmodel = ConvNet()
criterion = nn.CrossEntropyLoss() # 损失函数定义
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # 优化器定义# 训练网络
for epoch in range(50): # 50个epochrunning_loss = 0.0for i, data in enumerate(trainloader, 0): # 遍历训练集inputs, labels = dataoptimizer.zero_grad() # 梯度清零outputs = model(inputs) # 神经网络前向传播loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数running_loss += loss.item() # 累加损失loss = running_loss/len(trainset) # 打印Lossprint(f'Epoch {epoch+1}, Loss: {loss}') print('Finished Training')这篇关于卷积神经网络(CNN)使用PyTorch实现卷积神经网络对CIFAR-10数据集进行图片分类(代码➕注释)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






