本文主要是介绍(Scikit-Learn)特征工程:分类特征,文本特征,衍生特征,缺省值填充,管道特征,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
特征工程
(1)分类特征
浏览房屋数据的时候,除了看到“房价” (price)和“面积”(rooms)之类的数值特征,还会有“地点”(neighborhood)信息,数 据可能像这样:
data = [{'price': 850000, 'rooms': 4, 'neighborhood': 'Queen Anne'},{'price': 700000, 'rooms': 3, 'neighborhood': 'Fremont'},{'price': 650000, 'rooms': 3, 'neighborhood': 'Wallingford'},{'price': 600000, 'rooms': 2, 'neighborhood': 'Fremont'}]
你可能会把分类特征用映射关系编码成整数: {‘Queen Anne’: 1, ‘Fremont’: 2, ‘Wallingford’: 3};
但是,在 Scikit-Learn 中这么做并不是一个好办法:这个程序包的所有模块都有一个基本 假设,那就是数值特征可以反映代数量(algebraic quantities)。因此,这样映射编码可能 会让人觉得存在 Queen Anne < Fremont < Wallingford,甚至还有 Wallingford - Queen Anne = Fremont,这显然是没有意义的
常用的解决方法是独热编码。它可以有效增加额外的列,让 0 和 1 出现在 对应的列分别表示每个分类值有或无。当你的数据是像上面那样的字典列表时,用 ScikitLearn 的 DictVectorizer 类就可以实现:
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False, dtype=int)
vec.fit_transform(data)

如果要看每一列的含义,可以用下面的代码查看特征名称:
vec.get_feature_names()

但这种方法也有一个显著的缺陷:如果你的分类特征有许多枚举值,那么数据集的维度就 会急剧增加。然而,由于被编码的数据中有许多 0,因此用稀疏矩阵表示会非常高效:
vec = DictVectorizer(sparse=True, dtype=int)
vec.fit_transform(data)

(2)文本特征
单词统计:给你几个文本,让你统计每个词出现的次数,然后放到表格中
用 Scikit-Learn 的 CountVectorizer 更是可以轻松实现:
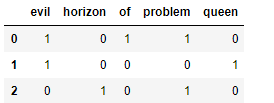
sample = ['problem of evil','evil queen','horizon problem']
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
X = vec.fit_transform(sample)
X

结果是一个稀疏矩阵,里面记录了每个短语中每个单词的出现次数。
用带列标签的DataFrame 来表示这个稀疏矩阵
import pandas as pd
pd.DataFrame(X.toarray(),columns=vec.get_feature_names())
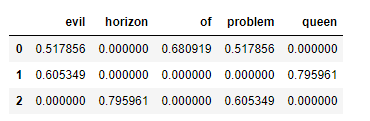
不过这种统计方法也有一些问题:原始的单词统计会让一些常用词聚集太高的权重,在分 类算法中这样并不合理。解决这个问题的方法就是通过 TF–IDF(term frequency–inverse document frequency,词频逆文档频率),通过单词在文档中出现的频率来衡量其权重。
TF-IDF的值与词在各个文档中的常见程度成反比
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer()
X = vec.fit_transform(sample)
pd.DataFrame(X.toarray(),columns=vec.get_feature_names())
(3)衍生特征
一种有用的特征是输入特征经过数学变换衍生出来的新特征。
将一个线性回归转换成多项式回归时,并不是通过改变模型来实现,而是通过改变输入数据!
下面的数据显然不能用一条直线描述
%matplotlib inline
import numpy as np
import matplotlib.pyplot as pltx = np.array([1,2,3,4,5])
y = np.array([4,2,1,3,7])
plt.scatter(x,y)

用 LinearRegression 拟合出一条直线,并获得直线的最优解
from sklearn.linear_model import LinearRegression
X = x[:, np.newaxis]
model = LinearRegression().fit(X,y)
yfit = model.predict(X)
plt.scatter(x,y)
plt.plot(x,yfit)

对数据进行变换,并增加额外的特征来提升模型的复杂度。例如,可以在数据中增加多项式特征:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=3, include_bias=False)
X2 = poly.fit_transform(X)
X2

在衍生特征矩阵中,第 1 列表示 x,第 2 列表示 x2,第 3 列表示 x3。通过对这个扩展的输 入矩阵计算线性回归,就可以获得更接近原始数据的结果了
model = LinearRegression().fit(X2,y)
yfit = model.predict(X2)
plt.scatter(x,y)
plt.plot(x,yfit)

(4)缺失值填充
有如下一个数据集, NaN 通常用来表示缺失值。
from numpy import nan
X = np.array([[ nan, 0, 3 ],
[ 3, 7, 9 ],
[ 3, 5, 2 ],
[ 4, nan, 6 ],
[ 8, 8, 1 ]])
y = np.array([14, 16, -1, 8, -5])
对于一般的缺省值填充方法,如均值、中位数、众数, Scikit-Learn 有 Imputer 类可以实现
from sklearn.preprocessing import Imputer
imp = Imputer(strategy='mean') #均值代替
X2 = imp.fit_transform(X)
X2

(5)特征管道
如果经常需要手动应用前文介绍的任意一种方法,你很快就会感到厌倦,尤其是当你需要 将多个步骤串起来使用时。你要不断的对数据进行处理,不断的fit_transform…
可以通过定义一个管道对象(即一个对数据的执行序列流水线),之后模型会按照序列的顺序,依次执行序列中的操作 例如,我们可能需要对一些数据做如下操作。
(1) 用均值填充缺失值。
(2) 将衍生特征转换为二次方。
(3) 拟合线性回归模型。
from sklearn.pipeline import make_pipeline
model = make_pipeline(Imputer(strategy='mean'),PolynomialFeatures(degree=2),LinearRegression())
model.fit(X,y)#X带有缺省值
print(y)
print(model.predict(X))
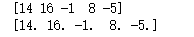
这篇关于(Scikit-Learn)特征工程:分类特征,文本特征,衍生特征,缺省值填充,管道特征的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







