本文主要是介绍Python北理工mooc爬虫笔记之requests库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
request.get()函数原型

request对象的属性方法

r.text与r.content的区别
r.text是程序根据猜测的响应内容编码方式来编写的,也就是r.encoding,这个编码方式是从返回信息中的headers中获取到的,如果headers中没有,那么则默认为ISO-8859-1,而r.apparent_encoding是从网页html文件中信息解析出来的编码,一般来说使用r.text获取网页的信息,如果r.text出现乱码,才会使用r.content.decoding("r.apparent_encoding")来读取网页信息
Requests库的异常


爬取网页的通用代码框架
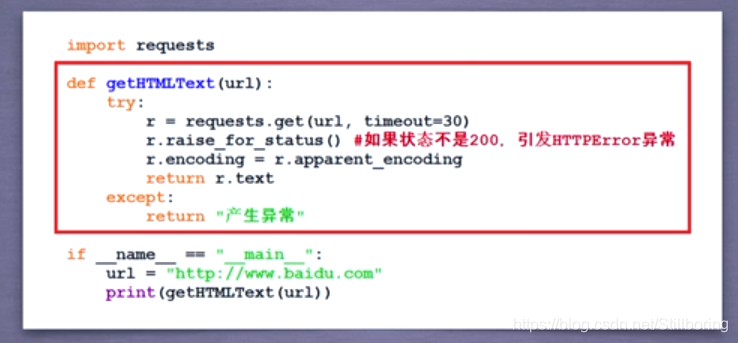
Request库的基本方法

http协议

其中URL格式为

URL举例

HTTP对资源的操作种类

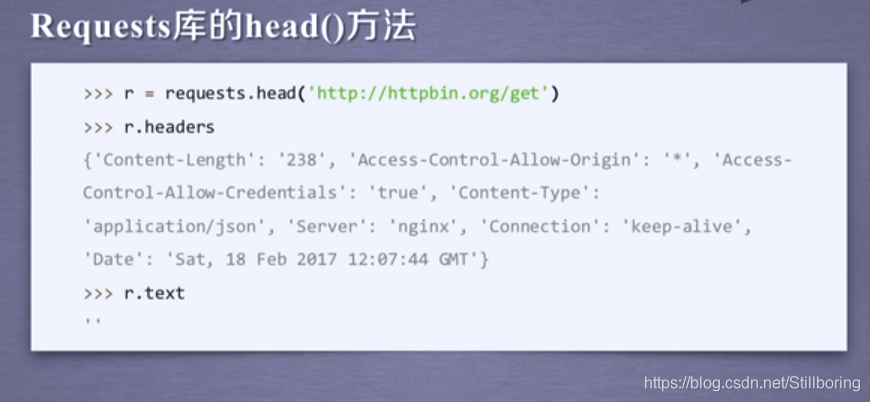
补充:当我们发现我们要访问的资源很大时,让服务器返回信息需要花费很大的代价时,我们可以使用head让服务器返回资源的头部信息。
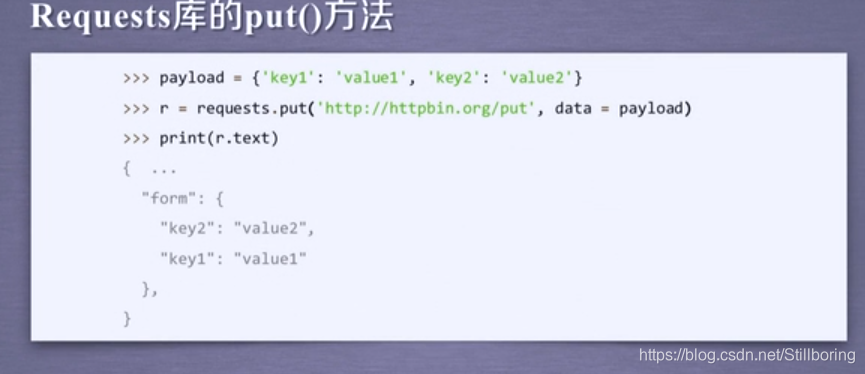
PATCH和PUT的区别

Request库的head()方法
Request库中的post()方法


Requests库的put方法
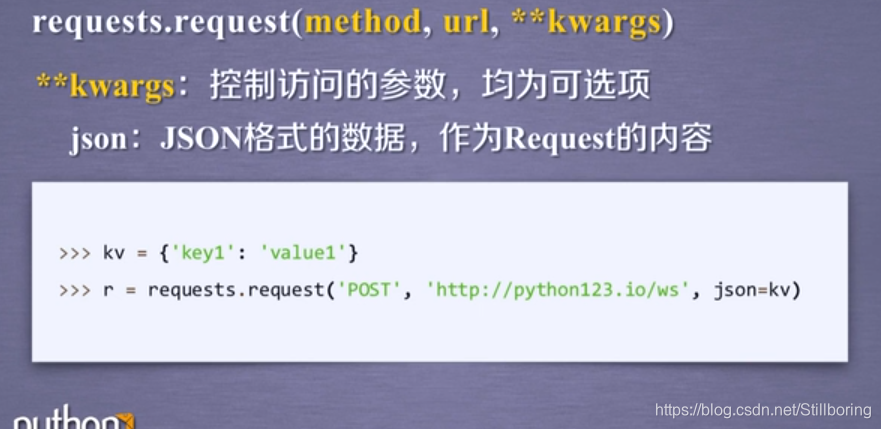
requests.request函数的原型


可以使用requests.request('GET',url)也可以使用requests.get(url),后者是将前者封装起来的方法
13个参数
1.params

我们提交的键值对会放在url链接里
2.data

这时候我们的键值对会放在url链接对应的数据域里存储
3.json
html最经常使用的数据格式
4.headers
对应向某个http发起请求时的头字段,可以在请求时附加headers来伪装爬虫

5和6.cookies和auth

7.files

8.timeout

9.proxies

剩下的参数为

requests.get函数

requests.head()函数

requests.post()函数

requests.delete()函数

为什么这些函数会把requests.request里的kwargs参数提到外面来呢?是因为提到外面的都是常用的,便于我们直接赋值
这篇关于Python北理工mooc爬虫笔记之requests库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




