本文主要是介绍ShardingSphere 5.x 系列【5】Spring Boot 3.1 集成Sharding Sphere-JDBC并实现读写分离,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
有道无术,术尚可求,有术无道,止于术。
本系列Spring Boot 版本 3.1.0
本系列ShardingSphere 版本 5.4.0
源码地址:https://gitee.com/pearl-organization/study-sharding-sphere-demo

文章目录
- 1. 概述
- 2. 使用限制
- 3. 案例演示
- 3.1 一主双从
- 3.2 项目搭建
- 3.3 配置
- 3.4 测试
- 4. 负载均衡算法
- 4.1 轮询
- 4.2 随机
- 4.3 权重
- 4.4 自定义
1. 概述
读写分离是一种数据库部署架构,将数据库拆分为读库和写库,写库负责处理事务性的增删改操作,读库负责处理查询操作,适用于查询多,写入少的应用系统。读写分离将查询请求均匀的分散到多个从库中,可以提升数据库的吞吐量,可以提高系统的可用性,当宕机一台数据库不影响系统的正常运行。
读写分离的实现基于数据的的主从部署架构,一主多从读写分离部署示例:
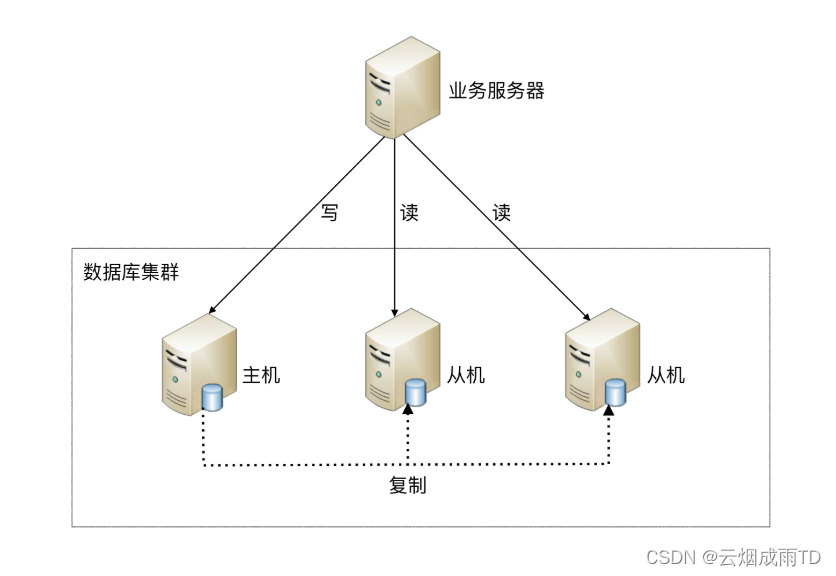
同时读写分离也带来了一些问题:
- 数据一致性:多个主库之间的数据一致性,以及主库与从库之间的数据一致性
- 复杂性:开发和运维操作变得更加复杂
2. 使用限制
ShardingSphere提供了读写分离功能管理主从数据库,实现透明化的读写分离功能,让用户像使用一个数据库一样使用主从架构的数据库,并提供了多种负载均衡策略,用于将查询请求转发至不同从库。
使用限制:
- 目前仅支持一主多从
- 不处理主库和从库的数据同步
- 不处理主库和从库的数据同步延迟导致的数据不一致
- 不支持主库多写
- 不处理主从库间的事务一致性,主从模型中,事务中的数据读写均用主库
3. 案例演示
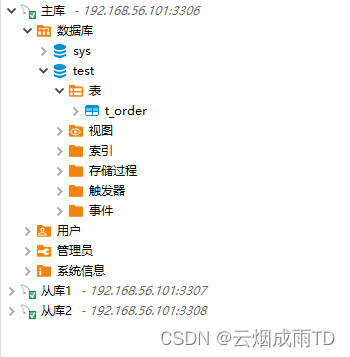
3.1 一主双从
使用MySql搭建一主双从,并同步一张用于测试的订单表:
3.2 项目搭建
创建一个Spring Boot基础工程,并引入相关依赖。
Parent:
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.0</version><relativePath/> <!-- lookup parent from repository --></parent>
Spring Boot基础依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
Mybatis Plus:
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-spring-boot3-starter</artifactId><version>3.5.5</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency>
ShardingSphere在5.3.0及之后的版本,考虑到维护兼容成本,更加专心于自身功能迭代,移除了Spring Boot Starter,所以只能引入 ShardingSphere-JDBC核心包:
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core</artifactId><version>5.4.0</version></dependency><!--java.lang.ClassNotFoundException: com.sun.xml.internal.bind.v2.ContextFactory--><dependency><groupId>org.glassfish.jaxb</groupId><artifactId>jaxb-runtime</artifactId><version>2.3.8</version></dependency>
最后使用代码工具生成订单相关业务代码:
3.3 配置
ShardingSphere-JDBC在5.3.0及之后的版本不再提供Spring Boot Starter,所以配置方面有较大的变化,目前只支持Java API和YAML 进行配置。
ShardingSphere 提供了 JDBC 驱动,首先需要在application.yml中配置ShardingSphereDriver 。
server:port: 8080
spring:datasource:# 配置 DataSource Driverdriver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver# 指定 YAML 配置文件url: jdbc:shardingsphere:classpath:readwrite-splitting-config.yml # 读写分离配置文件
application.yml同级目录下创建readwrite-splitting-config.yml续写分离配置文件,在该文件中,首先添加数据源配置:
# 数据源配置
dataSources:# 主库write_ds: # 逻辑名称dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.56.101:3306/testusername: rootpassword: "root"# 从库1read_ds_0:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.56.101:3307/testusername: rootpassword: "root"# 从库2read_ds_1:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.56.101:3308/testusername: rootpassword: "root"
然后添加读写分离规则、从库负载均衡相关配置:
# 规则配置
rules:# 读写分离配置- !READWRITE_SPLITTINGdataSources: # 数据源readwrite_ds: # 读写分离逻辑数据源名称writeDataSourceName: write_ds # 写库数据源名称readDataSourceNames: # 读库数据源名称,多个从数据源用逗号分隔- read_ds_0- read_ds_1transactionalReadQueryStrategy: PRIMARY # 事务内读请求的路由策略,可选值:PRIMARY(路由至主库)、FIXED(同一事务内路由至固定数据源)、DYNAMIC(同一事务内路由至非固定数据源)。默认值:DYNAMICloadBalancerName: read # 负载均衡自定义算法名称# 负载均衡算法loadBalancers:read: # 自定义的算法名称type: RANDOM # 负载均衡算法类型
props:# 是否打印 SQLsql-show: true
3.4 测试
添加查询、新增测试访问接口:
@RestController
@RequestMapping("/order")
@RequiredArgsConstructor
public class OrderController {private final OrderService orderService;@GetMapping("/list")public List<OrderEntity> list() {return orderService.list();}@GetMapping("/save")public Object save() {OrderEntity orderEntity=new OrderEntity();orderEntity.setPhone(18888888888L);orderEntity.setAddress("湖南长沙");orderEntity.setOrderTime(LocalDateTime.now());orderEntity.setProductId(1L);orderEntity.setOrderTime(LocalDateTime.now());orderEntity.setId(IdUtil.getSnowflakeNextId());orderService.save(orderEntity);return "操作成功";}
}
启动项目,多次访问新增接口,可以看到都是走的主库:
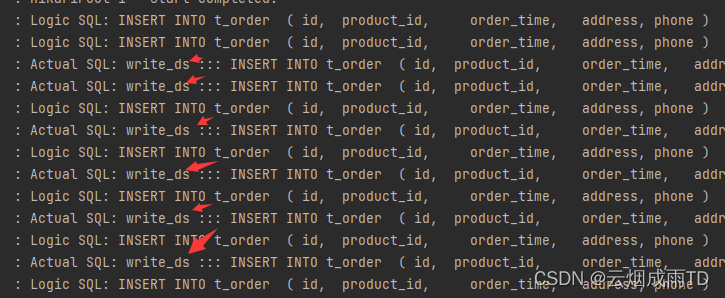
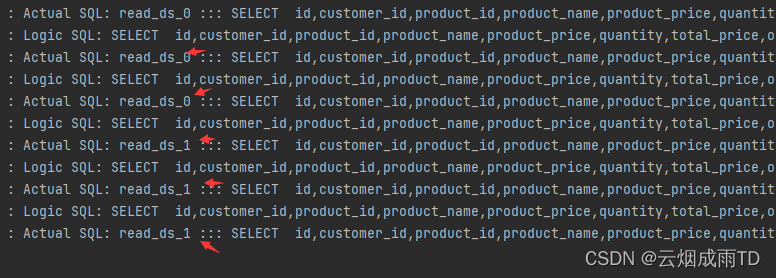
多次访问查询接口,可以看到都是走的从库:
4. 负载均衡算法
负载均衡(Load Balancing)用于将工作负载分配到多个计算资源,以提高性能、可靠性、可扩展性。读写分离环境下,对于多台从库的访问策略,ShardingSphere内置了多种负载均衡算法,满足用户绝大多数业务场景的需要。
4.1 轮询
按顺序轮流对读库进行访问。
# 规则配置
rules:# 读写分离配置- !READWRITE_SPLITTINGdataSources: # 数据源readwrite_ds: # 读写分离逻辑数据源名称writeDataSourceName: write_ds # 写库数据源名称readDataSourceNames: # 读库数据源名称,多个从数据源用逗号分隔- read_ds_0- read_ds_1transactionalReadQueryStrategy: PRIMARY # 事务内读请求的路由策略,可选值:PRIMARY(路由至主库)、FIXED(同一事务内路由至固定数据源)、DYNAMIC(同一事务内路由至非固定数据源)。默认值:DYNAMICloadBalancerName: read # 负载均衡自定义算法名称# 负载均衡算法loadBalancers:read: # 自定义的算法名称type: ROUND_ROBIN # 负载均衡算法类型
4.2 随机
随机选取一台读库进行访问。
# 规则配置
rules:# 读写分离配置- !READWRITE_SPLITTINGdataSources: # 数据源readwrite_ds: # 读写分离逻辑数据源名称writeDataSourceName: write_ds # 写库数据源名称readDataSourceNames: # 读库数据源名称,多个从数据源用逗号分隔- read_ds_0- read_ds_1transactionalReadQueryStrategy: PRIMARY # 事务内读请求的路由策略,可选值:PRIMARY(路由至主库)、FIXED(同一事务内路由至固定数据源)、DYNAMIC(同一事务内路由至非固定数据源)。默认值:DYNAMICloadBalancerName: read # 负载均衡自定义算法名称# 负载均衡算法loadBalancers:read: # 自定义的算法名称type: RANDOM # 负载均衡算法类型
4.3 权重
给读库分配权重,权重高的优先访问。
# 规则配置
rules:# 读写分离配置- !READWRITE_SPLITTINGdataSources: # 数据源readwrite_ds: # 读写分离逻辑数据源名称writeDataSourceName: write_ds # 写库数据源名称readDataSourceNames: # 读库数据源名称,多个从数据源用逗号分隔- read_ds_0- read_ds_1transactionalReadQueryStrategy: PRIMARY # 事务内读请求的路由策略,可选值:PRIMARY(路由至主库)、FIXED(同一事务内路由至固定数据源)、DYNAMIC(同一事务内路由至非固定数据源)。默认值:DYNAMICloadBalancerName: read # 负载均衡自定义算法名称# 负载均衡算法loadBalancers:read: # 自定义的算法名称type: WEIGHT # 负载均衡算法类型# 属性props:# 属性名使用读库名称,参数填写读库对应的权重值。权重参数范围最小值 > 0,合计 <= Double.MAX_VALUE。# 读库名称: 权重read_ds_0: 9read_ds_1: 1
4.4 自定义
考虑到业务场景的复杂性,提供基于SPI 接口实现符合自己业务需要的负载均衡算法。
ShardingSphere提供了读库负载均衡算法接口ReadQueryLoadBalanceAlgorithm,用户根据自定的算法返回一个可访问的读库。
public interface ReadQueryLoadBalanceAlgorithm extends ShardingSphereAlgorithm {/**** @param name 读写分离逻辑数据源名称* @param writeDataSourceName 写库数据源名称* @param readDataSourceNames 读库数据源名称集合* @return 命中的读库名称*/String getDataSource(String name, String writeDataSourceName, List<String> readDataSourceNames) {}
实现ReadQueryLoadBalanceAlgorithm接口,自定义一个负载均衡算法:
public final class CustomReadQueryLoadBalanceAlgorithm implements ReadQueryLoadBalanceAlgorithm {/*** 配置类中的props属性* # 负载均衡算法* loadBalancers:* read: # 自定义的算法名称* type: CUSTOM # 负载均衡算法类型* # 属性* props:* # 属性名使用读库名称,参数填写读库对应的权重值。权重参数范围最小值 > 0,合计 <= Double.MAX_VALUE。* # 读库名称: 权重* read_ds_0: 9* read_ds_1: 1*/private Properties props;// 将配置类props属性赋值给当前对象 public void init(Properties props) {this.props = props;}public String getDataSource(String name, String writeDataSourceName, List<String> readDataSourceNames) {// 自定义算法逻辑(这里演示,直接返回第一个)return readDataSourceNames.get(0);}/*** 声明算法类型*/public String getType() {return "CUSTOM";}/*** 是否是默认*/public boolean isDefault() {return false;}public Properties getProps() {return props;}public void setProps(Properties props) {this.props = props;}
}
在resources目录下创建META-INF\services文件夹,并创建文件,名称为org.apache.shardingsphere.readwritesplitting.spi.ReadQueryLoadBalanceAlgorithm,文件内容为自定义算法类全限定类名:
com.pearl.shardingsphere.rw.algorithm.CustomReadQueryLoadBalanceAlgorithm
配置类修改算法类型为自定义:
# 规则配置
rules:# 读写分离配置- !READWRITE_SPLITTINGdataSources: # 数据源readwrite_ds: # 读写分离逻辑数据源名称writeDataSourceName: write_ds # 写库数据源名称readDataSourceNames: # 读库数据源名称,多个从数据源用逗号分隔- read_ds_0- read_ds_1transactionalReadQueryStrategy: PRIMARY # 事务内读请求的路由策略,可选值:PRIMARY(路由至主库)、FIXED(同一事务内路由至固定数据源)、DYNAMIC(同一事务内路由至非固定数据源)。默认值:DYNAMICloadBalancerName: read # 负载均衡自定义算法名称# 负载均衡算法loadBalancers:read: # 自定义的算法名称type: CUSTOM # 负载均衡算法类型
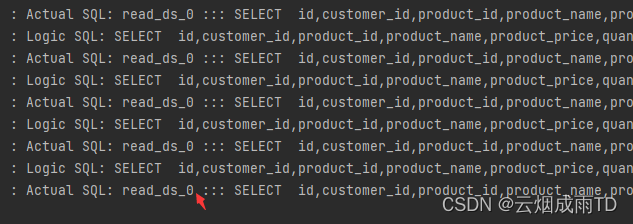
访问查询接口,看到使用的都是第一个读库,说明自定义算法生效:
这篇关于ShardingSphere 5.x 系列【5】Spring Boot 3.1 集成Sharding Sphere-JDBC并实现读写分离的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



